Les progrès de la modélisation séquentielle ont eu un impact extrêmement important car ils jouent un rôle important dans un large éventail d'applications, notamment l'apprentissage par renforcement (par exemple, la robotique et la conduite autonome), la classification de séries chronologiques (par exemple, la détection de fraude financière et le diagnostic médical). Au cours des dernières années, l'émergence de Transformer a marqué une avancée majeure dans la modélisation de séquences, principalement due au fait que Transformer fournit une architecture hautes performances capable de tirer parti du traitement parallèle GPU. Cependant, Transformer a une surcharge de calcul élevée lors de l'inférence, principalement en raison de l'expansion quadratique de la mémoire et des exigences informatiques, limitant ainsi son application dans des environnements à faibles ressources (par exemple, les appareils mobiles et embarqués). Bien que des techniques telles que la mise en cache KV puissent être adoptées pour améliorer l'efficacité de l'inférence, Transformer reste très coûteux pour les domaines à faibles ressources en raison de : (1) la mémoire qui augmente linéairement avec le nombre de jetons et (2) la mise en cache de tous les jetons précédents dans le modèle. Ce problème affecte encore plus l'inférence de Transformer dans les environnements avec des contextes longs (c'est-à-dire un grand nombre de jetons). Afin de résoudre ce problème, des chercheurs de l'Institut de recherche en IA de la Banque Royale du Canada Borealis AI et de l'Université de Montréal ont proposé une solution dans l'article « Attention as an RNN ». Il convient de mentionner que nous avons trouvé Yoshua Bengio, lauréat du prix Turing, apparaissant dans la chronique des auteurs.
- Adresse du papier : https://arxiv.org/pdf/2405.13956
- Titre du papier : Attention en tant que RNN
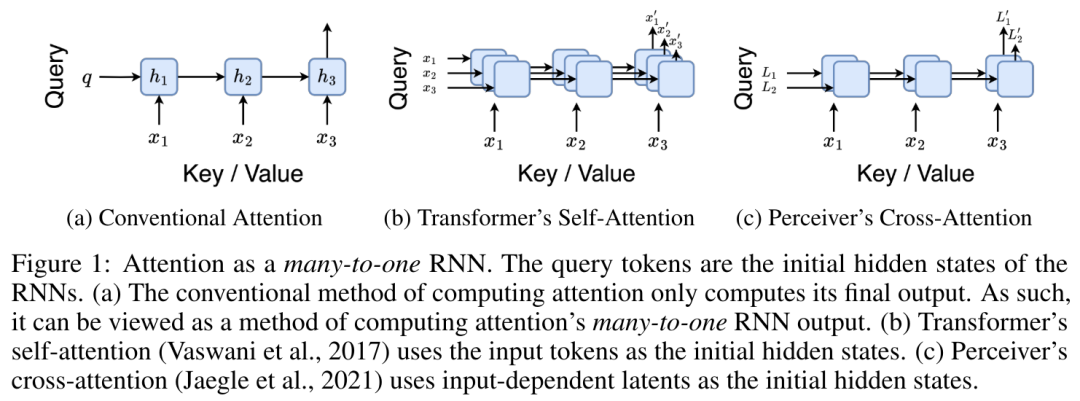
Plus précisément, la recherche L'auteur a d'abord examiné le mécanisme d'attention de Transformer, qui est le composant qui entraîne une augmentation quadratique de la complexité informatique de Transformer. Cette étude montre que le mécanisme d'attention peut être considéré comme un type spécial de réseau neuronal récurrent (RNN), avec la capacité de calculer efficacement les sorties RNN plusieurs-à-un. En tirant parti de la formulation de l’attention RNN, cette étude démontre que les modèles populaires basés sur l’attention tels que Transformer et Perceiver peuvent être considérés comme des variantes du RNN. Cependant, contrairement aux RNN traditionnels tels que LSTM et GRU, les modèles d'attention populaires tels que Transformer et Perceiver peuvent être considérés comme des variantes de RNN. Malheureusement, ils ne peuvent pas être mis à jour efficacement avec de nouveaux jetons. Afin de résoudre ce problème, cette recherche introduit une nouvelle formule d'attention basée sur l'algorithme d'analyse des préfixes parallèles, qui peut calculer efficacement l'attention plusieurs-à-plusieurs (plusieurs-à-plusieurs) à- plusieurs) Sortie RNN pour obtenir des mises à jour efficaces. Sur la base de cette nouvelle formule d'attention, l'étude propose Aaren ([A] attention [a] s un [re] réseau neuronal [n] actuel), un module informatiquement efficace, non seulement pouvant être formé en parallèle comme Transformer , mais peut également être mis à jour aussi efficacement que RNN. Les résultats expérimentaux montrent que les performances d'Aaren sont comparables à celles de Transformer sur 38 ensembles de données couvrant quatre paramètres de données de séquence courants : apprentissage par renforcement, prédiction d'événements, tâches de classification de séries chronologiques et de prédiction de séries chronologiques. Il est également plus efficace en termes de temps et mémoire. Introduction à la méthodeAfin de résoudre les problèmes ci-dessus, l'auteur propose un module efficace basé sur l'attention, qui peut tirer parti du parallélisme GPU et mettre à jour efficacement en même temps. Tout d'abord, les auteurs montrent dans la section 3.1 que l'attention peut être considérée comme un type de RNN avec la capacité particulière de calculer efficacement la sortie de RNN plusieurs-à-un (Figure 1a). En tirant parti de la forme d'attention RNN, les auteurs illustrent en outre que les modèles populaires basés sur l'attention, tels que Transformer (Figure 1b) et Perceiver (Figure 1c), peuvent être considérés comme des RNN. Cependant, contrairement aux RNN traditionnels, ces modèles ne peuvent pas se mettre à jour efficacement sur la base de nouveaux jetons, ce qui limite leur potentiel dans les problèmes séquentiels où les données arrivent sous la forme d'un flux.  Pour résoudre ce problème, l'auteur présente une méthode efficace de calcul de l'attention dans un RNN plusieurs-à-plusieurs basée sur un algorithme d'analyse de préfixes parallèle dans la section 3.2. Sur cette base, l'auteur a présenté Aaren dans la section 3.3 - un module efficace sur le plan informatique qui peut non seulement être formé en parallèle (tout comme Transformer), mais peut également être mis à jour efficacement avec de nouveaux jetons pendant l'inférence, ne nécessitant qu'une mémoire constante (seulement). comme le RNN traditionnel).Considérez l'attention comme un RNN plusieurs-à-unL'attention du vecteur de requête q peut être considérée comme une fonction qui transmet les clés et les valeurs de N jetons de contexte x_1:N Il correspond à une seule sortie o_N = Attention (q, k_1:N, v_1:N). Étant donné s_i = dot (q, k_i), la sortie o_N peut être exprimée comme suit : où le numérateur est et le dénominateur est . En considérant l'attention comme un RNN, et peuvent être calculés de manière itérative par sommation glissante lorsque k = 1,...,.... En pratique, cependant, cette implémentation est instable et souffre de problèmes numériques dus à une représentation de précision limitée et à des exposants potentiellement très petits ou très grands (c'est-à-dire exp(s)). Afin d'atténuer ce problème, l'auteur utilise le terme maximum cumulé pour réécrire la formule de récursion afin de calculer et . Il est à noter que le résultat final est le même , le calcul de la boucle de m_k est le suivant :
Pour résoudre ce problème, l'auteur présente une méthode efficace de calcul de l'attention dans un RNN plusieurs-à-plusieurs basée sur un algorithme d'analyse de préfixes parallèle dans la section 3.2. Sur cette base, l'auteur a présenté Aaren dans la section 3.3 - un module efficace sur le plan informatique qui peut non seulement être formé en parallèle (tout comme Transformer), mais peut également être mis à jour efficacement avec de nouveaux jetons pendant l'inférence, ne nécessitant qu'une mémoire constante (seulement). comme le RNN traditionnel).Considérez l'attention comme un RNN plusieurs-à-unL'attention du vecteur de requête q peut être considérée comme une fonction qui transmet les clés et les valeurs de N jetons de contexte x_1:N Il correspond à une seule sortie o_N = Attention (q, k_1:N, v_1:N). Étant donné s_i = dot (q, k_i), la sortie o_N peut être exprimée comme suit : où le numérateur est et le dénominateur est . En considérant l'attention comme un RNN, et peuvent être calculés de manière itérative par sommation glissante lorsque k = 1,...,.... En pratique, cependant, cette implémentation est instable et souffre de problèmes numériques dus à une représentation de précision limitée et à des exposants potentiellement très petits ou très grands (c'est-à-dire exp(s)). Afin d'atténuer ce problème, l'auteur utilise le terme maximum cumulé pour réécrire la formule de récursion afin de calculer et . Il est à noter que le résultat final est le même , le calcul de la boucle de m_k est le suivant :
En encapsulant le calcul cyclique de a_k, c_k et m_k à partir de a_(k-1), c_(k-1) et m_(k-1), l'auteur introduit une unité RNN qui peut calculer de manière itérative le résultat de l'attention (Voir Figure 2). L'unité d'attention RNN prend (a_(k-1), c_(k-1), m_(k-1), q) comme entrée et calcule (a_k, c_k, m_k, q). Notez que le vecteur de requête q est passé dans l'unité RNN. L'état caché initial du RNN d'attention est (a_0, c_0, m_0, q) = (0, 0, 0, q). Méthodes pour calculer l'attention : En considérant l'attention comme un RNN, vous pouvez voir différentes façons de calculer l'attention : boucler le calcul jeton par jeton dans la mémoire O (1) (c'est-à-dire le calcul séquentiel) ou le calculer de manière traditionnelle (c'est-à-dire le calcul séquentiel) ; calcul parallèle), nécessitant une mémoire O(N) linéaire. Puisque l'attention peut être considérée comme un RNN, la méthode traditionnelle de calcul de l'attention peut également être considérée comme une méthode efficace de calcul de la sortie du RNN d'attention plusieurs-à-un, c'est-à-dire que la sortie du RNN prend plusieurs jetons de contexte comme entrée, mais à la fin du RNN, un seul jeton est sorti (voir Figure 1a). Enfin, l'attention peut également être calculée comme un RNN qui traite les jetons morceau par morceau, plutôt que de manière entièrement séquentielle ou entièrement en parallèle, ce qui nécessite une mémoire O(b), où b est la taille du morceau. Traitez les modèles d'attention existants comme des RNN. En traitant l’attention comme un RNN, les modèles existants basés sur l’attention peuvent également être considérés comme des variantes du RNN. Par exemple, l'auto-attention du Transformer est un RNN (Figure 1b) et le jeton de contexte est son état caché initial. L’attention croisée du percepteur est un RNN (Figure 1c) dont l’état caché initial est une variable latente dépendante du contexte. En tirant parti des formes RNN de leur mécanisme d'attention, ces modèles existants peuvent calculer efficacement leurs magasins de sortie. Cependant, lorsque les modèles existants basés sur l'attention (tels que les transformateurs) sont considérés comme des RNN, ces modèles manquent de propriétés importantes couramment observées dans les RNN traditionnels (tels que LSTM et GRU). Il convient de noter que LSTM et GRU sont capables de se mettre à jour efficacement avec de nouveaux jetons dans seulement une mémoire et un calcul constants O(1), en revanche, la vue RNN de Transformer (voir Figure 1b) Un nouveau jeton est ajouté comme état initial et un nouveau RNN est ajouté pour traiter le nouveau jeton. Ce nouveau RNN traite tous les jetons précédents, nécessitant un calcul linéaire O(N). Dans Perceiver, en raison de son architecture, les variables latentes (L_i sur la figure 1c) dépendent des entrées, ce qui signifie que leurs valeurs changent lors de la réception de nouveaux jetons. À mesure que l'état caché initial (c'est-à-dire les variables latentes) de son RNN change, Perceiver doit donc recalculer son RNN à partir de zéro, ce qui nécessite une quantité linéaire de calcul de O (NL), où N est le nombre de jetons et L est le nombre de jetons. variables latentes. Considérez l'attention comme un RNN plusieurs-à-plusieursEn réponse à ces limitations, l'auteur propose de développer un modèle basé sur l'attention qui exploite la capacité de la formulation RNN à effectuer des mises à jour efficaces. . À cette fin, l'auteur présente d'abord une méthode de parallélisation efficace pour calculer l'attention sous la forme d'un RNN plusieurs-à-plusieurs, c'est-à-dire une méthode de calcul parallèle . À cette fin, les auteurs utilisent l'algorithme d'analyse parallèle des préfixes (voir Algorithme 1), une méthode de calcul parallèle qui calcule N préfixes à partir de N points de données consécutifs via l'opérateur de corrélation ⊕.Cet algorithme peut calculer efficacement Review, où , Afin de calculer efficacement, et peuvent être calculés via un algorithme d'analyse parallèle, puis combinés avec a_k et c_k pour calculer . ⊕ ,. L’entrée de l’algorithme de balayage parallèle est
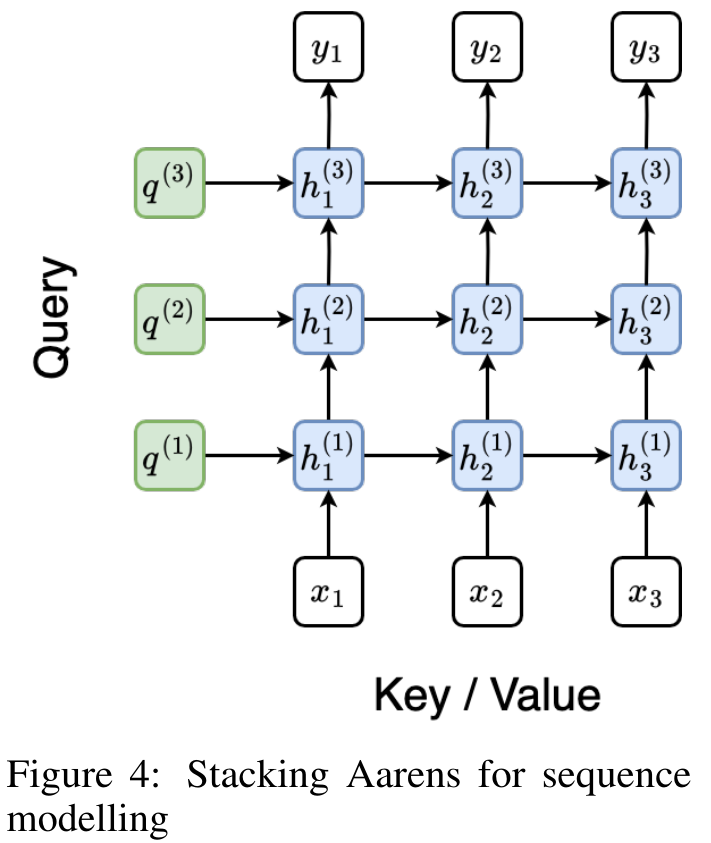
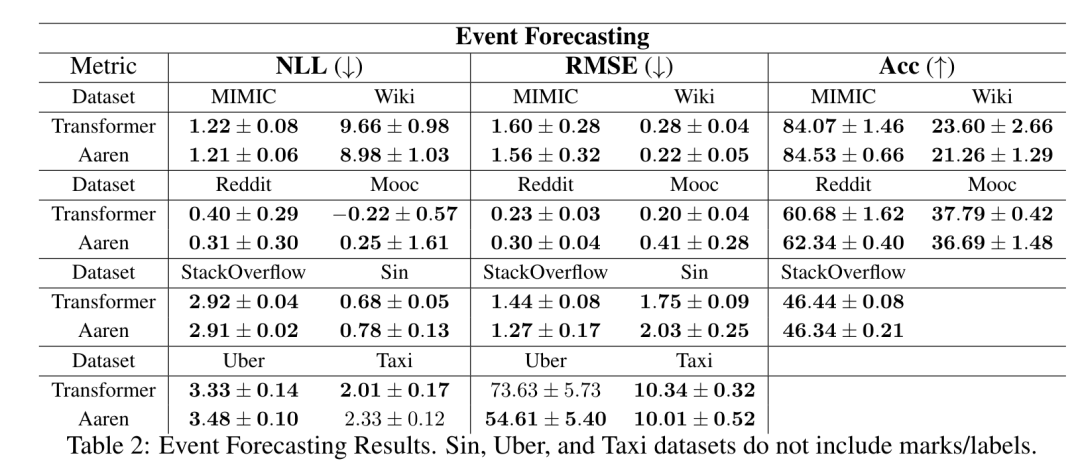
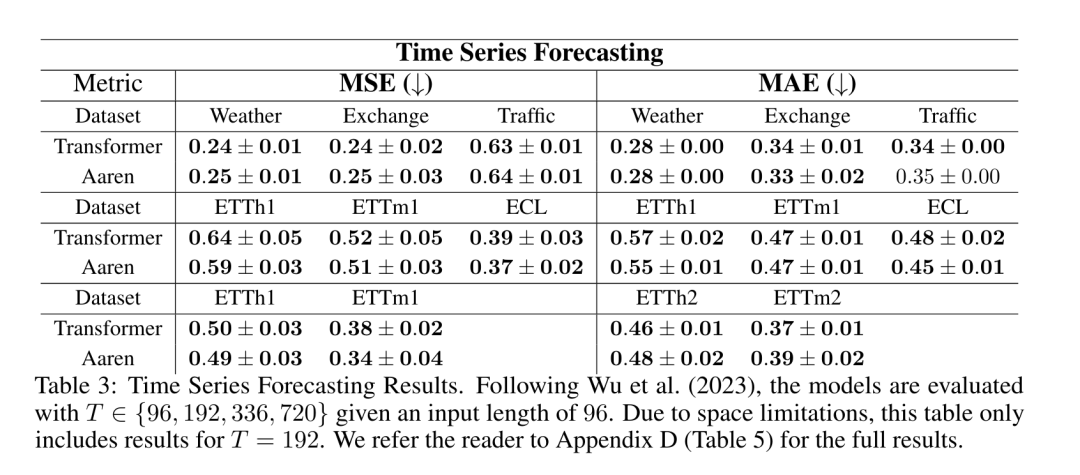
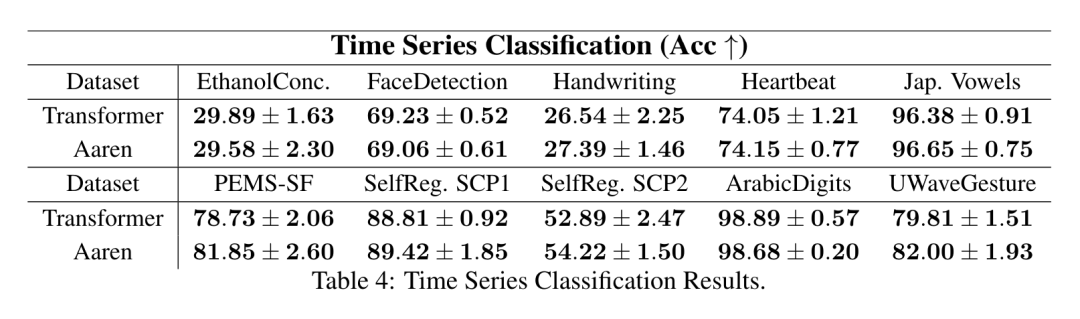
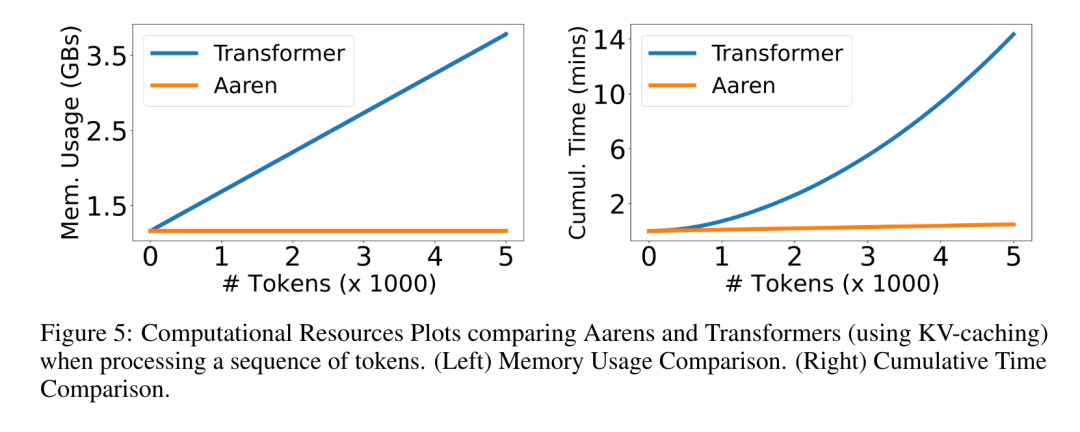
. L'algorithme applique récursivement l'opérateur ⊕ et fonctionne comme suit : , où , . Après avoir terminé l'application récursive de l'opérateur, l'algorithme génère . Aussi connu sous le nom de . En combinant les deux dernières valeurs du tuple de sortie, est récupéré, ce qui donne lieu à une méthode parallèle efficace de calcul de l'attention sous la forme d'un RNN plusieurs-à-plusieurs (Figure 3). Aaren : [A] attention [a] s a [re] current neural [n] réseauL'interface d'Aaren est la même que celle de Transformer, c'est-à-dire N entrées sont mappés sur N sorties, et la ième sortie est l'agrégation de la 1ère à la ième entrée. De plus, Aaren est naturellement empilable et peut calculer des termes de perte distincts pour chaque jeton de séquence. Cependant, contrairement aux Transformers qui utilisent l'auto-attention causale, Aaren utilise la méthode de calcul de l'attention ci-dessus comme un RNN plusieurs-à-plusieurs, ce qui la rend plus efficace. La forme d'Aaren est la suivante : Différent de Transformer, dans Transformer, la requête est l'un des jetons entrés à l'attention, tandis qu'à Aaren, le jeton de requête q est transmis par rétropropagation. au cours du processus de formation Appris. La figure ci-dessous montre un exemple de modèle Aaren empilé. Le jeton de contexte d'entrée du modèle est x_1:3 et la sortie est y_1:3. Il convient de noter que puisque Aaren utilise le mécanisme d’attention sous la forme de RNN, empiler Aarens équivaut également à empiler RNN. Par conséquent, Aarens est également capable de mettre à jour efficacement avec de nouveaux jetons, c'est-à-dire que le calcul itératif de y_k ne nécessite qu'un calcul constant puisqu'il ne dépend que de h_k-1 et x_k. Les modèles basés sur Transformer nécessitent une mémoire linéaire (lors de l'utilisation du cache KV) et doivent stocker tous les jetons précédents, y compris ceux de la couche intermédiaire Transformer, mais les modèles basés sur Aaren ne nécessitent qu'une mémoire constante, Et il n'est pas nécessaire de stocker tous les jetons précédents, ce qui rend Aarens nettement meilleur que Transformer en termes d'efficacité de calcul. Le but de la partie expérimentale est de comparer Aaren et Transformer en termes de performances et de ressources requises (temps et mémoire). Pour une comparaison complète, les auteurs ont effectué des évaluations sur quatre problèmes : l'apprentissage par renforcement, la prédiction d'événements, la prédiction de séries chronologiques et la classification des séries chronologiques. Apprentissage par renforcementL'auteur a d'abord comparé les performances d'Aaren et de Transformer en apprentissage par renforcement. L'apprentissage par renforcement est populaire dans les environnements interactifs tels que la robotique, les moteurs de recommandation et le contrôle du trafic. Les résultats du tableau 1 montrent qu'Aaren fonctionne de manière comparable à Transformer dans les 12 ensembles de données et les 4 environnements. Cependant, contrairement à Transformer, Aaren est également un RNN et peut donc gérer efficacement de nouvelles interactions environnementales en calcul continu, ce qui le rend plus adapté à l'apprentissage par renforcement. Ensuite, l'auteur a comparé les performances d'Aaren et de Transformer en matière de prédiction d'événements. La prédiction d'événements est populaire dans de nombreux contextes du monde réel, tels que la finance (par exemple, les transactions), les soins de santé (par exemple, l'observation des patients) et le commerce électronique (par exemple, les achats). Les résultats du tableau 2 montrent qu'Aaren fonctionne à égalité avec Transformer sur tous les ensembles de données.La capacité d'Aaren à traiter efficacement de nouvelles entrées est particulièrement utile dans les environnements de prédiction d'événements, où les événements se produisent dans des flux irréguliers. Ensuite, l'auteur a comparé les performances d'Aaren et de Transformer en matière de prévision de séries chronologiques. Les modèles de prévision de séries chronologiques sont couramment utilisés dans des domaines liés au climat (comme la météo), à l'énergie (comme l'offre et la demande) et à l'économie (comme les cours boursiers). Les résultats du tableau 3 montrent qu'Aaren fonctionne de manière comparable à Transformer sur tous les ensembles de données. Cependant, contrairement à Transformer, Aaren peut traiter efficacement les données de séries chronologiques, ce qui les rend plus adaptées aux domaines liés aux séries chronologiques. Classification des séries chronologiquesEnsuite, l'auteur a comparé les performances d'Aaren et de Transformer dans la classification des séries chronologiques. La classification des séries chronologiques est courante dans de nombreuses applications importantes, telles que la reconnaissance de formes (par exemple, l'électrocardiogramme), la détection d'anomalies (par exemple, la fraude bancaire) ou la prédiction de pannes (par exemple, les fluctuations du réseau électrique). Comme le montre le tableau 4, Aaren fonctionne à égalité avec Transformer sur tous les ensembles de données. Enfin, l'auteur compare les ressources requises par Aaren et Transformer. Complexité de la mémoire : dans la figure 5 (à gauche), les auteurs comparent l'utilisation de la mémoire d'Aaren et de Transformer (en utilisant le cache KV) au moment de l'inférence. On peut voir qu'avec l'utilisation de la technologie de cache KV, l'utilisation de la mémoire de Transformer augmente de manière linéaire. En revanche, Aaren n’utilise qu’une quantité constante de mémoire, quelle que soit l’augmentation du nombre de jetons, ce qui le rend beaucoup plus efficace. Complexité temporelle : dans la figure 5 (à droite), l'auteur compare le temps cumulé requis pour qu'Aaren et Transformer (en utilisant le cache KV) traitent une séquence de jetons en séquence. Pour Transformer, le montant du calcul cumulé est le carré du nombre de jetons, c'est-à-dire O (1 + 2 + ... + N) = O (N^2). En revanche, l’effort de calcul cumulé d’Aaren est linéaire. Sur la figure, vous pouvez voir que le temps cumulé requis par le modèle donne des résultats similaires. Plus précisément, le temps cumulé requis par Transformer augmente de façon quadratique, tandis que le temps cumulé requis par Aaren augmente de manière linéaire. Nombre de paramètres : En raison de la nécessité d'apprendre l'état caché initial q, le module Aaren nécessite légèrement plus de paramètres que le module Transformer. Cependant, comme q n’est qu’un vecteur, la différence n’est pas significative. Grâce à des mesures empiriques sur des modèles similaires, les auteurs ont découvert que Transformer utilisait 3 152 384 paramètres. En comparaison, l’équivalent Aaren utilise 3 152 896 paramètres, soit une augmentation des paramètres de seulement 0,016 % – un prix négligeable à payer pour la différence significative en termes de complexité de mémoire et de temps. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



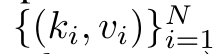 Il correspond à une seule sortie o_N = Attention (q, k_1:N, v_1:N). Étant donné s_i = dot (q, k_i), la sortie o_N peut être exprimée comme suit :
Il correspond à une seule sortie o_N = Attention (q, k_1:N, v_1:N). Étant donné s_i = dot (q, k_i), la sortie o_N peut être exprimée comme suit : 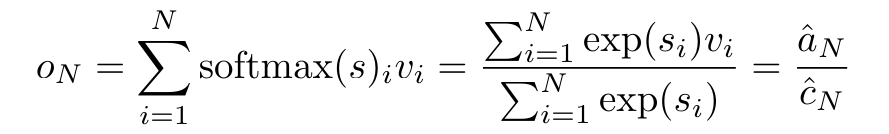
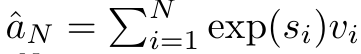 et le dénominateur est
et le dénominateur est 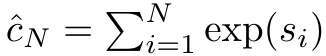 . En considérant l'attention comme un RNN,
. En considérant l'attention comme un RNN, 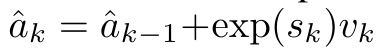 et
et  peuvent être calculés de manière itérative par sommation glissante lorsque k = 1,...,.... En pratique, cependant, cette implémentation est instable et souffre de problèmes numériques dus à une représentation de précision limitée et à des exposants potentiellement très petits ou très grands (c'est-à-dire exp(s)). Afin d'atténuer ce problème, l'auteur utilise le terme maximum cumulé
peuvent être calculés de manière itérative par sommation glissante lorsque k = 1,...,.... En pratique, cependant, cette implémentation est instable et souffre de problèmes numériques dus à une représentation de précision limitée et à des exposants potentiellement très petits ou très grands (c'est-à-dire exp(s)). Afin d'atténuer ce problème, l'auteur utilise le terme maximum cumulé 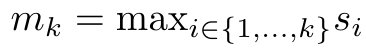 pour réécrire la formule de récursion afin de calculer
pour réécrire la formule de récursion afin de calculer 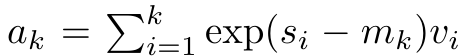 et
et 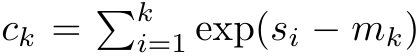 . Il est à noter que le résultat final est le même
. Il est à noter que le résultat final est le même 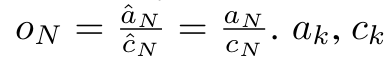 , le calcul de la boucle de m_k est le suivant :
, le calcul de la boucle de m_k est le suivant : 

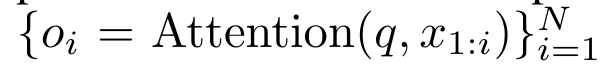 . À cette fin, les auteurs utilisent l'algorithme d'analyse parallèle des préfixes (voir Algorithme 1), une méthode de calcul parallèle qui calcule N préfixes à partir de N points de données consécutifs via l'opérateur de corrélation ⊕.Cet algorithme peut calculer efficacement
. À cette fin, les auteurs utilisent l'algorithme d'analyse parallèle des préfixes (voir Algorithme 1), une méthode de calcul parallèle qui calcule N préfixes à partir de N points de données consécutifs via l'opérateur de corrélation ⊕.Cet algorithme peut calculer efficacement 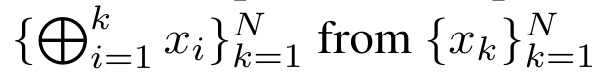

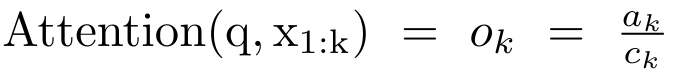 , où
, où 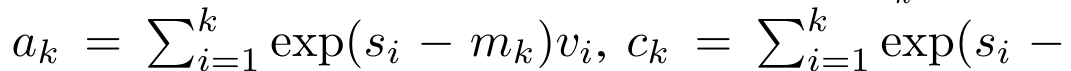
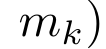 ,
, 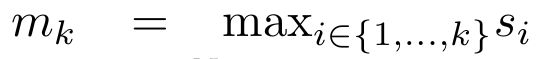 Afin de calculer
Afin de calculer 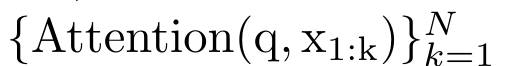 efficacement,
efficacement, 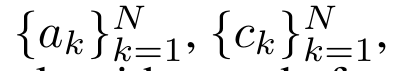 et
et  peuvent être calculés via un algorithme d'analyse parallèle, puis combinés avec a_k et c_k pour calculer
peuvent être calculés via un algorithme d'analyse parallèle, puis combinés avec a_k et c_k pour calculer  . ⊕ ,
. ⊕ ,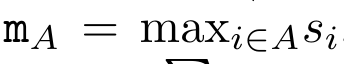 , où
, où 
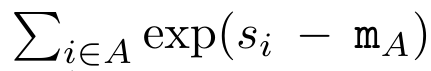 ,
, 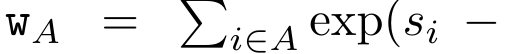
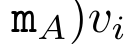 .
. 
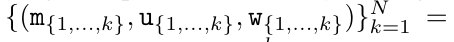
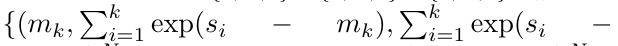
 . Aussi connu sous le nom de
. Aussi connu sous le nom de 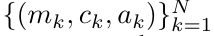 . En combinant les deux dernières valeurs du tuple de sortie,
. En combinant les deux dernières valeurs du tuple de sortie, 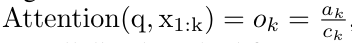 est récupéré, ce qui donne lieu à une méthode parallèle efficace de calcul de l'attention sous la forme d'un RNN plusieurs-à-plusieurs (Figure 3).
est récupéré, ce qui donne lieu à une méthode parallèle efficace de calcul de l'attention sous la forme d'un RNN plusieurs-à-plusieurs (Figure 3). 
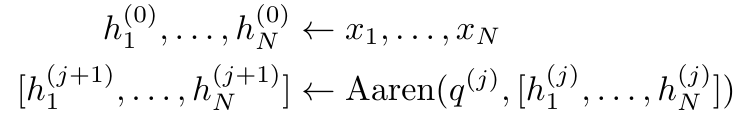

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



