
 Périphériques technologiques
IA
YOLOv10 est là ! Véritable détection de cible de bout en bout en temps réel
Périphériques technologiques
IA
YOLOv10 est là ! Véritable détection de cible de bout en bout en temps réel
YOLOv10 est là ! Véritable détection de cible de bout en bout en temps réel

Au cours des dernières années, YOLO est devenu un paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de son équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont mené une exploration approfondie de la conception structurelle, des objectifs d’optimisation, des stratégies d’amélioration des données, etc. des YOLO et ont réalisé des progrès significatifs. Cependant, le recours au post-traitement à la suppression non maximale (NMS) entrave le déploiement de bout en bout des YOLO et a un impact négatif sur la latence d'inférence. De plus, la conception de divers composants dans les YOLO manque d'un examen complet et approfondi, ce qui entraîne une redondance informatique importante et limite les performances du modèle. Cela se traduit par une efficacité sous-optimale et un énorme potentiel d’amélioration des performances. Dans ce travail, nous visons à faire progresser davantage la limite performance-efficacité des YOLO à la fois en termes de post-traitement et d'architecture de modèle. À cette fin, nous proposons d’abord une double allocation persistante pour la formation des YOLO sans NMS, qui apporte simultanément des performances compétitives et une faible latence d’inférence. En outre, nous introduisons une stratégie complète de conception de modèles axée sur l’efficacité et la précision pour les YOLO. Nous avons entièrement optimisé chaque composant des YOLO du point de vue de l'efficacité et de la précision, ce qui réduit considérablement les frais de calcul et améliore les capacités du modèle. Le résultat de nos efforts est une nouvelle génération de la série YOLO conçue pour la détection d'objets de bout en bout en temps réel, appelée YOLOv10. Des expériences approfondies montrent que YOLOv10 atteint des performances et une efficacité de pointe à différentes échelles de modèle. Par exemple, sur l'ensemble de données COCO, notre YOLOv10-S est 1,8 fois plus rapide que RT-DETR-R18 sous un AP similaire, tout en réduisant les paramètres et les opérations en virgule flottante (FLOP) de 2,8 fois. Par rapport à YOLOv9-C, YOLOv10-B réduit la latence de 46 % et réduit les paramètres de 25 % pour les mêmes performances. Lien du code : https://github.com/THU-MIG/yolov10.
Quelles améliorations y a-t-il dans YOLOv10 ?
Résolvez d'abord le problème de prédiction redondante en post-traitement en proposant une stratégie persistante de double allocation pour les YOLO sans NMS. Cette stratégie comprend l'attribution de doubles étiquettes et des métriques de correspondance cohérentes. Cela permet au modèle d'obtenir une supervision riche et harmonieuse pendant la formation tout en éliminant le besoin de NMS pendant l'inférence, obtenant ainsi des performances compétitives tout en maintenant une efficacité élevée.
Cette fois, une stratégie complète de conception de modèle axée sur l'efficacité et la précision est proposée pour l'architecture du modèle, et chaque composant des YOLO est examiné de manière approfondie. En termes d'efficacité, des têtes de classification légères, un sous-échantillonnage découplé des canaux spatiaux et des conceptions de blocs guidés par classement sont proposés pour réduire la redondance informatique évidente et obtenir une architecture plus efficace.
En termes de précision, de grandes convolutions du noyau sont explorées et des modules d'auto-attention partielle efficaces sont proposés pour améliorer les capacités du modèle et exploiter le potentiel d'amélioration des performances à faible coût.
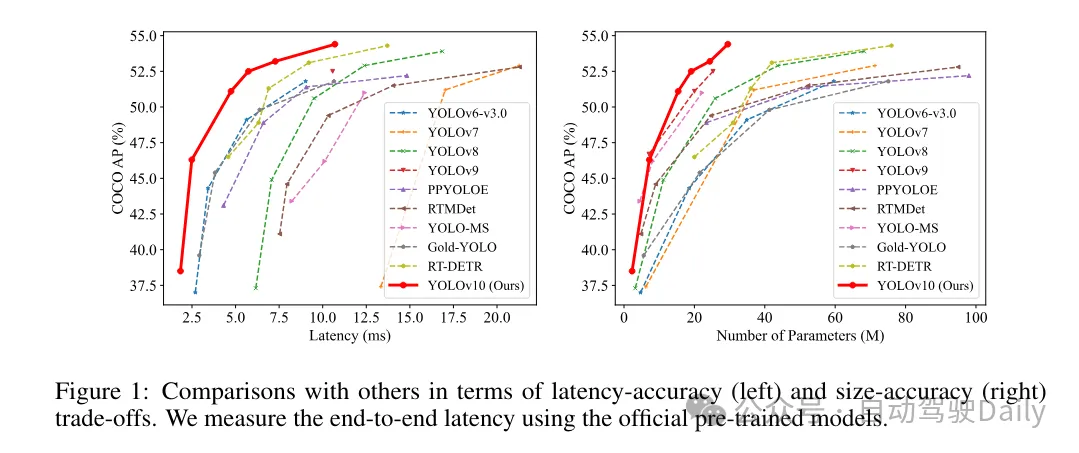
Sur la base de ces méthodes, l'auteur a implémenté avec succès une série de détecteurs de bout en bout en temps réel avec différentes tailles de modèles, à savoir YOLOv10-N/S/M/B/L/X. Des expériences approfondies sur des tests de détection d'objets standard montrent que YOLOv10 démontre la capacité à surpasser les modèles de pointe précédents en termes de compromis entre précision de calcul et différentes tailles de modèle. Comme le montre la figure 1, avec des performances similaires, YOLOv10-S/X est respectivement 1,8 fois/1,3 fois plus rapide que RT-DETR R18/R101. Par rapport à YOLOv9-C, YOLOv10-B atteint une réduction de latence de 46 % pour les mêmes performances. De plus, YOLOv10 présente une efficacité d'utilisation des paramètres extrêmement élevée. YOLOv10-L/X est 0,3 AP et 0,5 AP supérieur à YOLOv8-L/X avec le nombre de paramètres réduit de 1,8 fois et 2,3 fois respectivement. YOLOv10-M atteint un AP similaire à YOLOv9-M/YOLO-MS tout en réduisant le nombre de paramètres de 23 % et 31 % respectivement.
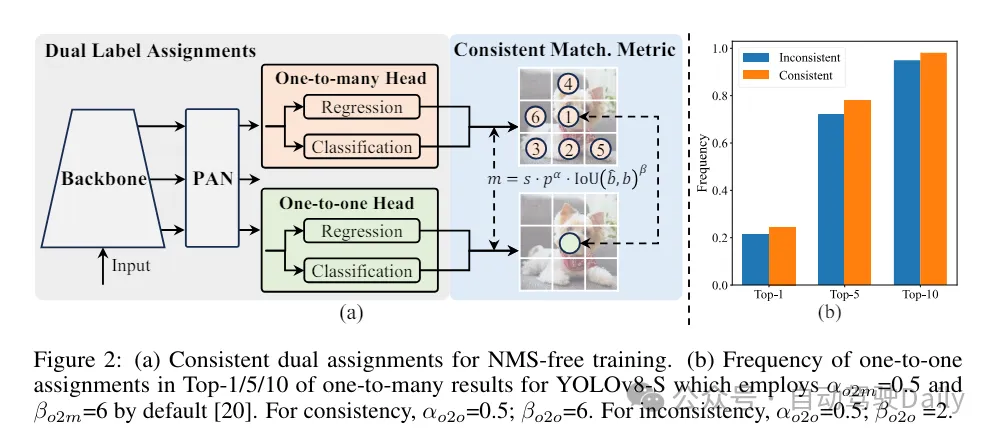
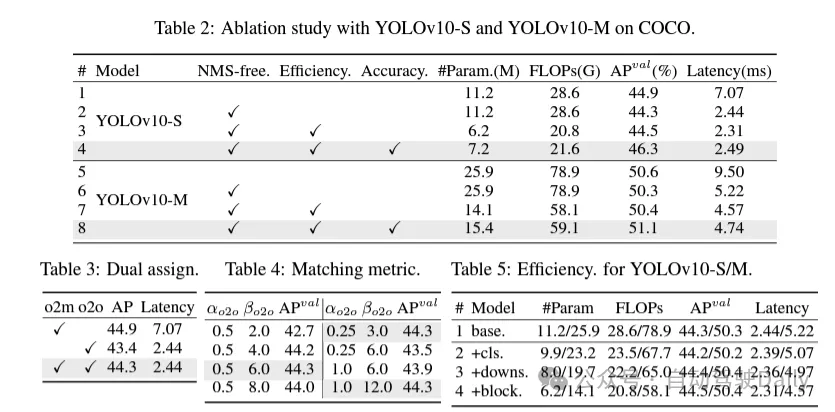
Pendant le processus de formation, les YOLO utilisent généralement TAL (Task Assignment Learning) pour attribuer plusieurs échantillons à chaque instance. L'adoption d'une méthode d'allocation un-à-plusieurs génère des signaux de supervision riches, ce qui permet d'optimiser et d'obtenir des performances plus élevées. Cependant, cela oblige également les YOLO à s'appuyer sur le post-traitement NMS (suppression non maximale), ce qui entraîne une efficacité d'inférence sous-optimale au moment du déploiement. Alors que des travaux antérieurs ont exploré des approches de correspondance un-à-un pour supprimer les prédictions redondantes, ils ajoutent souvent une surcharge d'inférence supplémentaire ou entraînent des performances sous-optimales. Dans ce travail, nous proposons une stratégie de formation sans NMS qui utilise l'attribution de doubles étiquettes et des mesures de correspondance cohérentes, permettant d'obtenir une efficacité élevée et des performances compétitives. Grâce à cette stratégie, nos YOLO n'ont plus besoin de NMS en formation, atteignant ainsi une efficacité élevée et des performances compétitives.
Conception de modèles axée sur l'efficacité. Les composants de YOLO incluent la tige, les couches de sous-échantillonnage, les étapes avec les éléments de base et la tête. Le coût de calcul de la partie principale est très faible, nous effectuons donc une conception de modèle axée sur l'efficacité pour les trois autres parties.
(1) En-tête de classification léger. Dans YOLO, la tête de classification et la tête de régression ont généralement la même architecture. Cependant, ils présentent des différences significatives en termes de temps de calcul. Par exemple, dans YOLOv8-S, le nombre de FLOP et de paramètres de la tête de classification (5,95G/1,51M de FLOP et de paramètres) et de la tête de régression (2,34G/0,64M) sont 2,5 fois et 2,4 fois celui de la régression. tête respectivement. Cependant, en analysant l'impact des erreurs de classification et des erreurs de régression (voir tableau 6), nous avons constaté que la tête de régression est plus importante pour les performances de YOLO. Par conséquent, nous pouvons réduire la surcharge liée aux en-têtes de classification sans nous soucier des problèmes de performances. Par conséquent, nous adoptons simplement une architecture de tête de classification légère, composée de deux convolutions séparables en profondeur avec une taille de noyau de 3 × 3, suivies d'un noyau 1 × 1. Grâce aux améliorations ci-dessus, nous pouvons simplifier l'architecture de la tête de classification légère, qui se compose de deux convolutions séparables en profondeur avec une taille de noyau de convolution de 3 × 3, suivies d'un noyau de convolution 1 × 1. Cette architecture simplifiée peut réaliser des fonctions de classification avec une charge de calcul et un nombre de paramètres réduits.
(2) Sous-échantillonnage découplé des canaux spatiaux. YOLO utilise généralement une convolution standard 3 × 3 régulière avec une foulée de 2, tout en implémentant un sous-échantillonnage spatial (de H × W à H/2 × W/2) et une transformation de canal (de C à 2C). Cela introduit un coût de calcul et un nombre de paramètres non négligeables. Au lieu de cela, nous proposons de découpler les opérations de réduction d’espace et d’augmentation de canal pour obtenir un sous-échantillonnage plus efficace. Plus précisément, la convolution ponctuelle est d'abord utilisée pour moduler les dimensions du canal, puis la convolution en profondeur est utilisée pour le sous-échantillonnage spatial. Cela réduit le coût de calcul et le nombre de paramètres à . Dans le même temps, il maximise la rétention des informations lors du sous-échantillonnage, réduisant ainsi la latence tout en maintenant des performances compétitives.
(3) Conception de modules basée sur des conseils de classement. Les YOLO utilisent généralement les mêmes éléments de base pour toutes les étapes, comme le bloc de goulot d'étranglement dans YOLOv8. Pour examiner en profondeur cette conception isomorphe des YOLO, nous utilisons le rang intrinsèque pour analyser la redondance de chaque étape. Plus précisément, le rang numérique de la dernière convolution dans le dernier bloc de base de chaque étape est calculé, ce qui compte le nombre de valeurs singulières supérieures à un seuil. La figure 3 (a) montre les résultats de YOLOv8, montrant que les étapes profondes et les grands modèles sont plus susceptibles de présenter davantage de redondance. Cette observation suggère que le simple fait d’appliquer la même conception de bloc à toutes les étapes n’est pas optimal pour obtenir le meilleur compromis capacité-efficacité. Pour résoudre ce problème, un schéma de conception de modules basé sur le rang est proposé, qui vise à réduire la complexité des étapes qui s'avèrent redondantes grâce à une conception architecturale compacte.
Nous introduisons d'abord une structure de bloc inversé compact (CIB) qui adopte une convolution en profondeur bon marché pour le mélange spatial et une convolution ponctuelle rentable pour le mélange de canaux, comme le montre la figure 3 (b). Il peut servir d’élément de base efficace, par exemple intégré dans les structures ELAN (Figure 3(b)). Ensuite, une stratégie d’allocation de modules basée sur le classement est préconisée pour atteindre une efficacité optimale tout en maintenant un pouvoir compétitif. Plus précisément, étant donné un modèle, classez toutes les étapes selon l'ordre croissant de leur rang intrinsèque. Examinez plus en détail les changements de performances après le remplacement des blocs de base de l'étage principal par CIB. S'il n'y a pas de dégradation des performances par rapport au modèle donné, on passe à l'étape suivante avec remplacement, sinon on arrête le processus. En conséquence, nous pouvons mettre en œuvre des conceptions de blocs compacts adaptatifs à différentes étapes et tailles de modèles, obtenant ainsi une plus grande efficacité sans compromettre les performances.
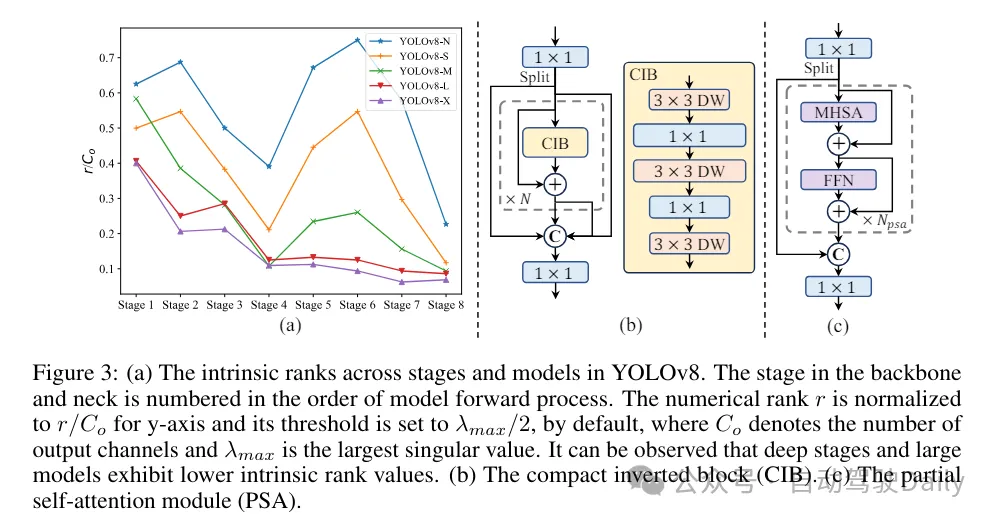
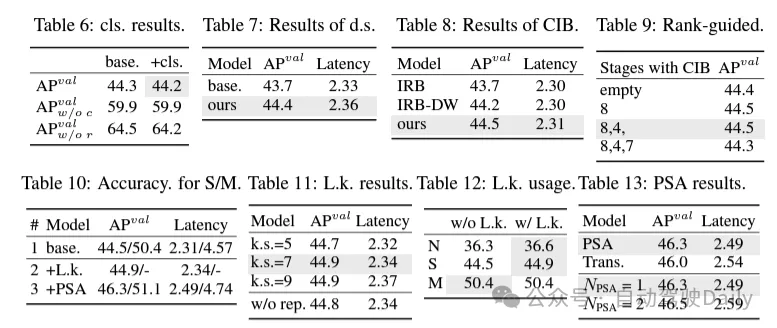
Basé sur une conception de modèle axée sur la précision. L'article explore en outre les mécanismes de convolution et d'auto-attention à grand noyau pour parvenir à une conception basée sur la précision, dans le but d'améliorer les performances à un coût minimal.
(1) Grande convolution du noyau. L'adoption de convolutions profondes à grand noyau est un moyen efficace d'élargir le champ de réception et d'améliorer les capacités du modèle. Cependant, le simple fait de les exploiter à toutes les étapes peut introduire une contamination dans les éléments peu profonds utilisés pour détecter les petits objets, tout en introduisant également une surcharge et une latence d'E/S significatives dans l'étape haute résolution. Par conséquent, les auteurs proposent d’utiliser des convolutions profondes à grand noyau dans le bloc d’informations inter-étages (CIB) de l’étage profond. Ici, la taille du noyau de la deuxième convolution en profondeur 3 × 3 dans CIB est augmentée à 7 × 7. De plus, une technologie de reparamétrage structurel est adoptée pour introduire une autre branche de convolution de profondeur 3 × 3 afin d'atténuer le problème d'optimisation sans augmenter la surcharge d'inférence. De plus, à mesure que la taille du modèle augmente, son champ de réception s'étend naturellement et les avantages de l'utilisation de grandes convolutions de noyau diminuent progressivement. Par conséquent, les convolutions à grand noyau ne sont utilisées qu’à petite échelle.
(2) Auto-attention partielle (PSA). Le mécanisme d’auto-attention est largement utilisé dans diverses tâches visuelles en raison de ses excellentes capacités de modélisation globale. Cependant, il présente une complexité informatique et une empreinte mémoire élevées. Afin de résoudre ce problème, compte tenu de la redondance omniprésente des têtes d'attention, l'auteur propose une conception efficace de module d'auto-attention partielle (PSA), comme le montre la figure 3. (c). Plus précisément, les fonctionnalités sont divisées uniformément en deux parties par canaux après convolution 1 × 1. Seule une partie des fonctionnalités est entrée dans le bloc NPSA composé d'un module d'auto-attention multi-têtes (MHSA) et d'un réseau à action directe (FFN). Ensuite, les deux parties des fonctionnalités sont épissées et fusionnées par convolution 1×1. De plus, définissez les dimensions des requêtes et des clés dans MHSA sur la moitié des valeurs et remplacez LayerNorm par BatchNorm pour une inférence rapide. Le PSA n'est placé qu'après l'étape 4 avec la résolution la plus basse pour éviter une surcharge excessive causée par la complexité informatique quadratique de l'auto-attention. De cette manière, les capacités d'apprentissage de la représentation globale peuvent être intégrées aux YOLO à faible coût de calcul, améliorant ainsi considérablement les capacités du modèle et les performances.
Comparaison expérimentale
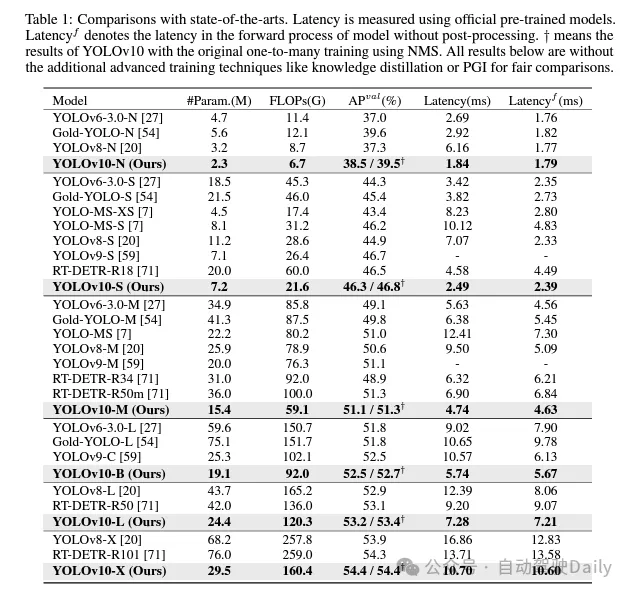
Je ne vais pas trop entrer dans l'introduction ici, juste les résultats ! ! ! La latence est réduite et les performances continuent d'augmenter.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Que signifie de bout en bout ?
Sep 27, 2021 pm 12:10 PM
Que signifie de bout en bout ?
Sep 27, 2021 pm 12:10 PM
De bout en bout fait référence à la « connectivité réseau ». Pour qu'un réseau communique, une connexion doit être établie. Peu importe la distance ou le nombre de machines situées entre les deux, une connexion doit être établie entre les deux extrémités. Une fois la connexion établie, on dit qu'elle est de bout en bout. -connexion de bout en bout, c'est-à-dire que la connexion de bout en bout est un lien logique.
 Annotation de cadre de délimitation redondant multi-grille pour une détection précise des objets
Jun 01, 2024 pm 09:46 PM
Annotation de cadre de délimitation redondant multi-grille pour une détection précise des objets
Jun 01, 2024 pm 09:46 PM
1. Introduction Actuellement, les principaux détecteurs d'objets sont des réseaux à deux étages ou à un étage basés sur le réseau de classificateurs de base réutilisé du Deep CNN. YOLOv3 est l'un de ces détecteurs à un étage de pointe bien connus qui reçoit une image d'entrée et la divise en une matrice de grille de taille égale. Les cellules de grille avec des centres cibles sont chargées de détecter des cibles spécifiques. Ce que je partage aujourd'hui est une nouvelle méthode mathématique qui alloue plusieurs grilles à chaque cible pour obtenir une prédiction précise et précise du cadre de délimitation. Les chercheurs ont également proposé une amélioration efficace des données par copier-coller hors ligne pour la détection des cibles. La méthode nouvellement proposée surpasse considérablement certains détecteurs d’objets de pointe actuels et promet de meilleures performances. 2. Le réseau de détection de cibles en arrière-plan est conçu pour utiliser
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 Nouveau SOTA pour la détection de cibles : YOLOv9 sort et la nouvelle architecture redonne vie à la convolution traditionnelle
Feb 23, 2024 pm 12:49 PM
Nouveau SOTA pour la détection de cibles : YOLOv9 sort et la nouvelle architecture redonne vie à la convolution traditionnelle
Feb 23, 2024 pm 12:49 PM
Dans le domaine de la détection de cibles, YOLOv9 continue de progresser dans le processus de mise en œuvre en adoptant de nouvelles architectures et méthodes, il améliore efficacement l'utilisation des paramètres de la convolution traditionnelle, ce qui rend ses performances bien supérieures à celles des produits de la génération précédente. Plus d'un an après la sortie officielle de YOLOv8 en janvier 2023, YOLOv9 est enfin là ! Depuis que Joseph Redmon, Ali Farhadi et d’autres ont proposé le modèle YOLO de première génération en 2015, les chercheurs dans le domaine de la détection de cibles l’ont mis à jour et itéré à plusieurs reprises. YOLO est un système de prédiction basé sur des informations globales d'images et les performances de son modèle sont continuellement améliorées. En améliorant continuellement les algorithmes et les technologies, les chercheurs ont obtenu des résultats remarquables, rendant YOLO de plus en plus puissant dans les tâches de détection de cibles.
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Comment utiliser C++ pour un suivi d'image et une détection de cible hautes performances ?
Aug 26, 2023 pm 03:25 PM
Comment utiliser C++ pour un suivi d'image et une détection de cible hautes performances ?
Aug 26, 2023 pm 03:25 PM
Comment utiliser C++ pour un suivi d'image et une détection de cible hautes performances ? Résumé : Avec le développement rapide de l’intelligence artificielle et de la technologie de vision par ordinateur, le suivi d’images et la détection de cibles sont devenus des domaines de recherche importants. Cet article présentera comment obtenir un suivi d'image et une détection de cible hautes performances à l'aide du langage C++ et de certaines bibliothèques open source, et fournira des exemples de code. Introduction : Le suivi d'images et la détection d'objets sont deux tâches importantes dans le domaine de la vision par ordinateur. Ils sont largement utilisés dans de nombreux domaines, comme la vidéosurveillance, la conduite autonome, les systèmes de transport intelligents, etc. pour
 Plusieurs SOTA ! OV-Uni3DETR : Améliorer la généralisabilité de la détection 3D à travers les catégories, scènes et modalités (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
Plusieurs SOTA ! OV-Uni3DETR : Améliorer la généralisabilité de la détection 3D à travers les catégories, scènes et modalités (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
Cet article traite du domaine de la détection d'objets 3D, en particulier de la détection d'objets 3D pour Open-Vocabulary. Dans les tâches traditionnelles de détection d'objets 3D, les systèmes doivent prédire l'emplacement des objets dans des scènes réelles, des cadres de délimitation 3D et des étiquettes de catégories sémantiques, qui s'appuient généralement sur des nuages de points ou des images RVB. Bien que la technologie de détection d’objets 2D fonctionne bien en raison de son omniprésence et de sa rapidité, des recherches pertinentes montrent que le développement de la détection universelle 3D est à la traîne en comparaison. Actuellement, la plupart des méthodes de détection d'objets 3D reposent encore sur un apprentissage entièrement supervisé et sont limitées par des données entièrement annotées dans des modes de saisie spécifiques, et ne peuvent reconnaître que les catégories qui émergent au cours de l'entraînement, que ce soit dans des scènes intérieures ou extérieures. Cet article souligne que les défis auxquels est confrontée la détection universelle de cibles 3D sont principalement
 Exemple de vision par ordinateur en Python : détection d'objets
Jun 10, 2023 am 11:36 AM
Exemple de vision par ordinateur en Python : détection d'objets
Jun 10, 2023 am 11:36 AM
Avec le développement de l’intelligence artificielle, la technologie de vision par ordinateur est devenue l’un des centres d’attention des gens. En tant que langage de programmation efficace et facile à apprendre, Python a été largement reconnu et promu dans le domaine de la vision par ordinateur. Cet article se concentrera sur un exemple de vision par ordinateur en Python : la détection d'objets. Qu'est-ce que la détection d'objets ? La détection d'objets est une technologie clé dans le domaine de la vision par ordinateur. Son objectif est d'identifier l'emplacement et la taille d'un objet spécifique dans une image ou une vidéo. Par rapport à la classification d'images, la détection de cibles nécessite non seulement l'identification des images
