
 Périphériques technologiques
IA
En mettant la Terre entière dans un réseau neuronal, l'équipe de l'Université de Beihang a lancé un modèle mondial de génération d'images de télédétection
Périphériques technologiques
IA
En mettant la Terre entière dans un réseau neuronal, l'équipe de l'Université de Beihang a lancé un modèle mondial de génération d'images de télédétection
En mettant la Terre entière dans un réseau neuronal, l'équipe de l'Université de Beihang a lancé un modèle mondial de génération d'images de télédétection

L'équipe de recherche de l'Université Beihang a utilisé un modèle de diffusion pour « reproduire » la Terre ?
À n'importe quel endroit dans le monde, le modèle peut générer des images de télédétection de plusieurs résolutions, créant ainsi des « scènes parallèles » riches et diverses.
Et les caractéristiques géographiques complexes telles que le terrain, le climat, la végétation, etc. sont toutes prises en compte.

Inspirée par Google Earth, l’équipe de recherche de l’Université de Beihang a « chargé » des images de télédétection satellitaire de la Terre entière dans un réseau neuronal profond depuis une perspective aérienne.
Sur la base d'un tel réseau, l'équipe a construit MetaEarth, un modèle global de génération visuelle descendante.
MetaEarth possède 600 millions de paramètres et peut générer des images de télédétection avec de multiples résolutions, illimitées et couvrant n'importe quel emplacement géographique dans le monde.

Un modèle mondial de génération d'images de télédétection
Par rapport aux recherches précédentes, la construction d'un modèle mondial de génération visuelle de base est plus difficile et de nombreuses difficultés ont été surmontées au cours du processus.
La capacité du modèle est un défi car la Terre présente un large éventail de caractéristiques géographiques telles que des villes, des forêts, des déserts, des océans, des glaciers et des champs de neige, qui doivent être comprises et représentées par le modèle.
Même le même type de caractéristiques artificielles présentera d'énormes différences sous différentes latitudes, climats et environnements culturels, ce qui impose des exigences élevées sur la capacité du modèle généré.
MetaEarth a réussi à résoudre cette difficulté et à générer des scènes haute résolution et à grande échelle dans différents endroits et reliefs.
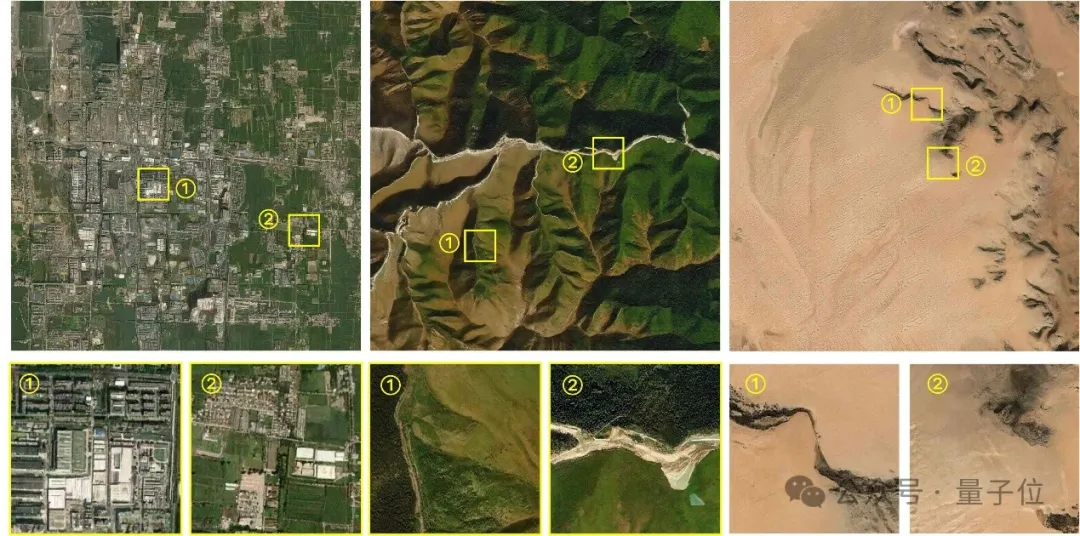
De plus, générer des images de télédétection avec une résolution contrôlable est également un défi.
Parce que dans le processus d'imagerie d'image aérienne, l'affichage des caractéristiques du sol est grandement affecté par la résolution. Il existe des différences évidentes sous différentes résolutions d'image, il est difficile de générer avec précision à la résolution spécifiée (mètre/pixel) . Capacité.
Lorsque MetaEarth génère des images de différentes résolutions, elle peut présenter avec précision et raisonnablement les caractéristiques des objets au sol, et les corrélations entre les différentes résolutions sont également cartographiées avec précision.

Enfin, il y a le défi de la génération d'images illimitées - contrairement aux images naturelles quotidiennes, les images de télédétection ont les caractéristiques d'une largeur ultra-large et la longueur des côtés peut atteindre des dizaines de milliers de pixels. méthodes pour générer des images continues et illimitées de n’importe quelle taille.
Mais la scène continue et illimitée générée par MetaEarth évite ce défaut, et vous pouvez voir que l'image se déplace très facilement lorsque la « lentille » est traduite.

De plus, MetaEarth a de fortes performances de généralisation et peut générer en cascade des images multi-résolution en utilisant des scènes inconnues comme entrée conditionnelle.
Par exemple, en saisissant la « Planète Pandora » générée par GPT4-V comme condition initiale dans le modèle, MetaEarth est toujours capable de générer des images avec une répartition raisonnable des objets au sol et des détails réalistes.

Les résultats de la vérification des missions en aval montrent que MetaEarth, en tant que tout nouveau moteur de données, devrait fournir un environnement virtuel et un support de données de formation pour diverses missions en aval dans le domaine de l'observation de la Terre.
Au cours de l'expérience, l'auteur a choisi la tâche de base de classification des images de télédétection pour vérification. Les résultats montrent qu'avec l'aide d'images de haute qualité générées par MetaEarth, la précision de la classification des tâches en aval a été considérablement améliorée.
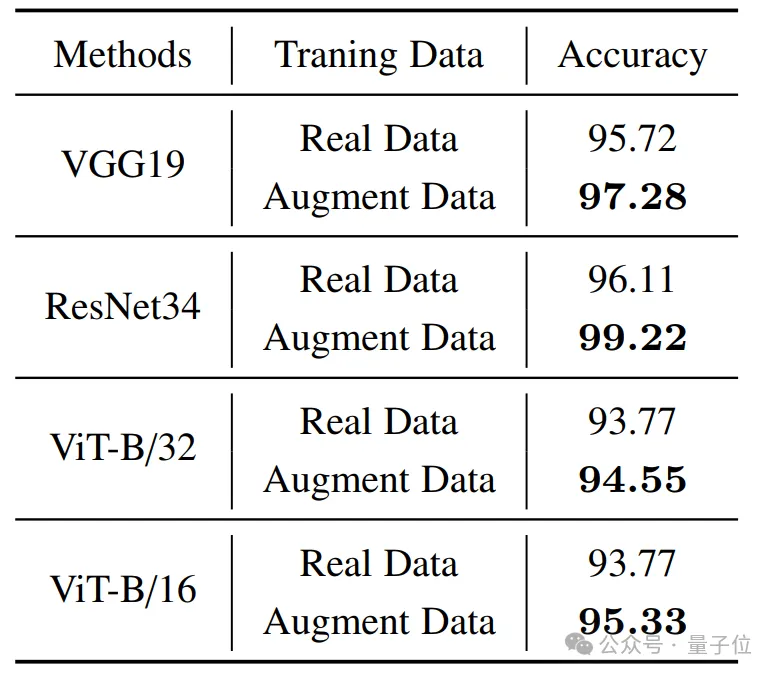
L'auteur estime que MetaEarth devrait fournir un environnement virtuel réaliste pour les plates-formes de systèmes aériens sans pilote telles que les satellites, et est largement utilisé dans l'urbanisme, la surveillance environnementale, la gestion des catastrophes, l'optimisation agricole et d'autres domaines
Dans ; En plus de servir de moteur de données, MetaEarth présente également un grand potentiel dans la construction de modèles mondiaux génératifs, offrant ainsi de nouvelles possibilités pour les recherches futures. .
Alors, comment MetaEarth y parvient-elle ?
Le modèle de diffusion de 600 millions de paramètres « reproduit » la Terre
MetaEarth est construit sur la base du modèle de diffusion probabiliste et a une échelle de paramètres de plus de 600 millions.
Pour soutenir la formation des modèles, l'équipe a collecté un vaste ensemble de données d'images de télédétection, contenant des images de plusieurs résolutions spatiales et leurs informations géographiques (latitude, longitude et résolution) couvrant la plupart des régions du monde.
Dans cette étude, les auteurs proposent un cadre de génération en cascade automatique guidé par résolution.
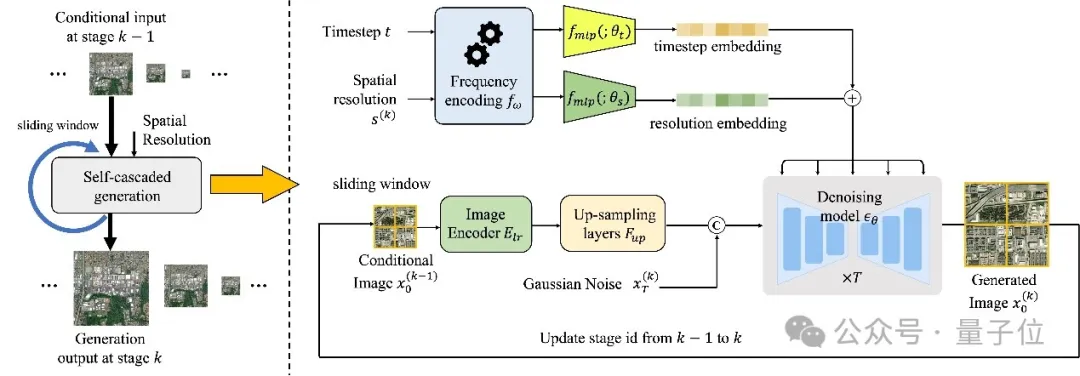
△Le cadre global de MetaEarth
Dans ce cadre, un seul modèle peut être utilisé pour réaliser une génération d'images multi-résolution pour un emplacement géographique donné, et créer des « images parallèles » riches et diverses à chaque niveau de résolution. Scènes".
Plus précisément, il s'agit d'un réseau de débruitage structuré par codec qui combine l'image conditionnelle basse résolution et le codage de résolution spatiale avec l'intégration du pas de temps du processus de débruitage pour prédire le bruit à chaque pas de temps, mettre en œuvre la génération d'images.
Afin de générer des images illimitées de n'importe quelle taille, l'auteur a également conçu une méthode de génération de fenêtre coulissante et une stratégie d'échantillonnage de bruit économes en mémoire.
Cette stratégie divise l'image générée en blocs d'images superposés comme condition et utilise une stratégie d'échantillonnage de bruit spécifique pour générer un contenu similaire dans les zones partagées des blocs d'images adjacents, évitant ainsi les espaces d'épissage.
De plus, cette stratégie d'échantillonnage du bruit permet également au modèle de consommer moins de ressources de mémoire vidéo lors de la génération d'images illimitées de toute taille.
Profil de l'équipe
L'auteur de cette étude est issu du "Laboratoire d'apprentissage, de vision et de télédétection, LEVIR Lab" (Laboratoire d'apprentissage, de vision et de télédétection, LEVIR Lab) de l'Université de Beihang. Le laboratoire est dirigé par le professeur. Shi Zhenwei, un jeune chercheur national distingué.
Le professeur Zou Zhengxia, ancien doctorant du professeur Shi Zhenwei, boursier postdoctoral à l'Université du Michigan et membre actuel du laboratoire, est l'auteur correspondant de cet article.
Adresse papier : https://www.php.cn/link/31bb2feb402ac789507479daf9713b00
Page d'accueil du projet : https://www.php.cn/link/a0098fd07 db76 92267fca4f4169c9ba2
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
