

L'auteur de ce document de discussion, Wang Yulin, est un doctorant direct en 2019 au Département d'automatisation de l'Université Tsinghua. Il a étudié sous la direction de l'académicien Wu Cheng et du professeur agrégé Huang Gao. vision par ordinateur, etc. Il a publié des articles de discussion en tant que premier auteur dans des revues et des conférences telles que TPAMI, NeurIPS, ICLR, ICCV, CVPR, ECCV, etc. Il a reçu la bourse Baidu, la bourse Microsoft, le prix académique émergent CCF-CV, la bourse ByteDance et d'autres distinctions. . Page d'accueil personnelle : wyl.cool.
Cet article présente principalement un article qui vient d'être accepté par IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) : EfficientTrain++ : Generalized Curriculum Learning for Efficient Visual Backbone Training.

Ces dernières années, la « mise à l'échelle » a été l'un des protagonistes de la recherche en vision par ordinateur . Avec l'augmentation de la taille du modèle et de l'échelle des données de formation, l'avancement des algorithmes d'apprentissage et l'application généralisée des technologies de régularisation et d'amélioration des données, les réseaux visuels de base obtenus grâce à une formation à grande échelle (comme Vision Transformer et MAE formés sur ImageNet1K/22K, DINOv2, etc.) a atteint des performances époustouflantes dans de nombreuses tâches visuelles importantes telles que la reconnaissance visuelle, la détection de cibles et la segmentation sémantique.
Cependant, la « mise à l'échelle » entraîne souvent des surcharges élevées de formation des modèles prohibitives, ce qui entrave considérablement le développement ultérieur et l'application industrielle des modèles de vision de base.
Pour résoudre ce problème, l'équipe de recherche de l'Université Tsinghua a proposé un algorithme d'apprentissage généralisé du curriculum : EfficientTrain++. L'idée centrale est de promouvoir le paradigme traditionnel d'apprentissage des cours consistant à « sélectionner et utiliser les données de facile à difficile, et à entraîner progressivement le modèle » vers « ne pas filtrer les dimensions des données, toujours utiliser toutes les données de formation, mais révéler progressivement chaque fonctionnalité au cours du processus de formation. " Caractéristiques ou modèles (modèles) de facile à difficile de chaque échantillon de données. "
EfficientTrain++ présente plusieurs points forts importants :
Ensuite, jetons un coup d’œil aux détails de l’étude.
Ces dernières années, le développement vigoureux de modèles de fondation à grande échelle a favorisé les progrès de l'intelligence artificielle et de l'apprentissage profond. Dans le domaine de la vision par ordinateur, des travaux représentatifs tels que Vision Transformer (ViT), CLIP, SAM et DINOv2 ont prouvé que l'augmentation de la taille des réseaux neuronaux et des données d'entraînement peut considérablement étendre des tâches visuelles importantes telles que la cognition, la détection et la segmentation. . limites de performances.
Cependant, les grands modèles de base ont souvent des frais de formation élevés. La figure 1 donne deux exemples typiques. En prenant comme exemple huit GPU NVIDIA V100 ou plus performants, il faudrait des années, voire des décennies, pour terminer une seule session de formation pour GPT-3 et ViT-G. Des coûts de formation aussi élevés représentent une dépense énorme, difficile à assumer tant pour le monde universitaire que pour l’industrie. Souvent, seules quelques institutions de haut niveau consomment de grandes quantités de ressources pour faire progresser l’apprentissage profond. Par conséquent, un problème urgent à résoudre est le suivant : comment améliorer efficacement l’efficacité de la formation des modèles d’apprentissage profond à grande échelle ?
 Exemple de figure 1 : surcharge de formation élevée des grands modèles de base d'apprentissage en profondeur
Exemple de figure 1 : surcharge de formation élevée des grands modèles de base d'apprentissage en profondeur
Pour les modèles de vision par ordinateur, une idée classique est l'apprentissage du programme, comme le montre la figure 2, c'est-à-dire l'imitation des humains. Un programme progressif et hautement structuré Processus d'apprentissage.Au cours du processus de formation du modèle, nous commençons par les données de formation « les plus simples » et introduisons progressivement les données de facile à difficile.
 Figure 2 Paradigme d'apprentissage du curriculum classique (Source de l'image : "A Survey on Curriculum Learning", TPAMI'22)
Figure 2 Paradigme d'apprentissage du curriculum classique (Source de l'image : "A Survey on Curriculum Learning", TPAMI'22)
Cependant, malgré la motivation naturelle, l'apprentissage du curriculum n'a pas été appliqué à grande échelle pour former fondements visuels La principale raison de la méthode générale du modèle est qu'il existe deux principaux goulots d'étranglement, comme le montre la figure 3. Premièrement, concevoir un programme de formation (curriculum) efficace n’est pas facile. La distinction entre les échantillons « simples » et « difficiles » nécessite souvent l'aide de modèles de pré-entraînement supplémentaires, la conception d'algorithmes AutoML plus complexes, l'introduction de l'apprentissage par renforcement, etc., et a une faible polyvalence. Deuxièmement, la modélisation de l’apprentissage lui-même est quelque peu déraisonnable. Les données visuelles dans la distribution naturelle présentent souvent un degré élevé de diversité. Un exemple est donné ci-dessous dans la figure 3 (images de perroquets sélectionnées au hasard dans ImageNet). Les données d'entraînement du modèle contiennent un grand nombre de perroquets avec des mouvements différents, des perroquets à différentes distances des perroquets. caméra, les perroquets de différentes perspectives et horizons, ainsi que les diverses interactions entre les perroquets et les personnes ou les objets, etc., il est en fait une méthode relativement grossière de distinguer des données aussi diverses uniquement par des indicateurs unidimensionnels de « simples » et de « difficiles ». " et des méthodes de modélisation farfelues.
 Figure 3 Deux principaux goulots d'étranglement qui entravent l'application à grande échelle de l'apprentissage du cours dans la formation de modèles visuels de base
Figure 3 Deux principaux goulots d'étranglement qui entravent l'application à grande échelle de l'apprentissage du cours dans la formation de modèles visuels de base
Inspiré par les défis ci-dessus, cet article propose un paradigme d'apprentissage de programme généralisé. L'idée principale est de « examiner et utiliser les données du plus facile au plus difficile et former progressivement le modèle ». Le paradigme d'apprentissage traditionnel des cours est étendu. à "Pas de filtrage des dimensions des données, toutes les données d'entraînement sont toujours utilisées, mais les caractéristiques ou les modèles de facile à difficile de chaque échantillon de données sont progressivement révélés au cours du processus d'entraînement", ce qui évite efficacement les limitations et les conceptions sous-optimales causées par le Le paradigme de filtrage des données est éliminé, comme le montre la figure 4.
 Figure 4 Apprentissage du curriculum traditionnel (dimension échantillon) vs apprentissage du curriculum généralisé (dimension caractéristique)
Figure 4 Apprentissage du curriculum traditionnel (dimension échantillon) vs apprentissage du curriculum généralisé (dimension caractéristique)
La proposition de ce paradigme est principalement basée sur un phénomène intéressant : Dans le processus de formation d'un modèle visuel naturel , bien que le modèle puisse toujours obtenir toutes les informations contenues dans les données à tout moment, mais le modèle apprendra toujours naturellement à reconnaître certaines caractéristiques discriminantes (modèles) plus simples contenues dans les données, puis apprendra progressivement à reconnaître des discriminants plus difficiles sur ce point. base. Caractéristiques . De plus, cette règle est relativement universelle, et des caractéristiques discriminantes « relativement simples » peuvent être facilement trouvées à la fois dans le domaine fréquentiel et dans le domaine spatial. Cet article a conçu une série d’expériences intéressantes pour démontrer les résultats ci-dessus, comme décrit ci-dessous. Du point de vue du domaine fréquentiel, les « caractéristiques basse fréquence » sont « relativement simples » par rapport au modèle. Dans la figure 5, l'auteur de cet article a formé un modèle DeiT-S à l'aide des données de formation standard ImageNet-1K et a utilisé des filtres passe-bas avec différentes bandes passantes pour filtrer l'ensemble de vérification, en conservant uniquement les composantes basse fréquence de l'image de vérification. et rapporte sur cette base. La précision de DeiT-S sur les données de vérification filtrées passe-bas pendant le processus de formation. La courbe de la précision obtenue par rapport au processus de formation est représentée sur le côté droit de la figure 5. Nous pouvons observer un phénomène intéressant : dans les premiers stades de la formation, l'utilisation uniquement de données de validation filtrées passe-bas ne réduit pas significativement la précision, et le point de séparation entre la courbe et la précision normale de l'ensemble de validation augmente avec le filtre. la bande passante augmente et se déplace progressivement vers la droite. Ce phénomène montre que bien que le modèle ait toujours accès aux parties basse et haute fréquence des données d'entraînement, son processus d'apprentissage commence naturellement par se concentrer uniquement sur les informations basse fréquence, et la capacité d'identifier les caractéristiques à haute fréquence est progressivement acquise. plus tard dans la formation (ce phénomène Pour plus de preuves, veuillez vous référer au texte original). Cette découverte soulève une question intéressante : pouvons-nous concevoir un programme de formation (curriculum) qui ne commence que pour le modèle ? Fournir une entrée visuelle des informations à basse fréquence dans un premier temps, puis introduire progressivement des informations à haute fréquence ? La figure 6 étudie l'idée d'effectuer un filtrage passe-bas sur les données d'entraînement uniquement pendant une première phase d'entraînement d'une durée spécifique, laissant le reste du processus d'entraînement inchangé. Il ressort des résultats que, bien que l'amélioration finale des performances soit limitée, il est intéressant de noter que la précision finale du modèle peut être préservée dans une large mesure même lorsque seules des composantes basse fréquence sont fournies au modèle pendant une période considérable. phase de formation précoce, ce qui coïncide également avec l'observation de la figure 5 selon laquelle « le modèle se concentre principalement sur l'apprentissage de l'identification des caractéristiques basse fréquence dans les premières étapes de la formation ». Cette découverte a inspiré l'auteur de cet article à réfléchir à l'efficacité de la formation : étant donné que le modèle n'a besoin que de composants basse fréquence dans les données dans les premiers stades de la formation, et que les composants basse fréquence contiennent moins d'informations que les données d'origine. , le modèle peut-il traiter l'entrée d'origine à un rythme plus rapide qu'apprendre efficacement à partir de composants basse fréquence uniquement avec un coût de calcul inférieur ? En fait, cette idée est tout à fait réalisable. Comme le montre le côté gauche de la figure 7, l'auteur de cet article introduit une opération de recadrage dans le spectre de Fourier de l'image pour recadrer la partie basse fréquence et la retracer dans l'espace des pixels. Cette opération de recadrage basse fréquence préserve avec précision toutes les informations basse fréquence tout en réduisant la taille de l'image d'entrée, de sorte que le coût de calcul du modèle apprenant à partir de l'entrée peut être réduit de façon exponentielle. Si vous utilisez cette opération de recadrage à basse fréquence pour traiter l'entrée du modèle dans les premières étapes de la formation, vous pouvez économiser considérablement le coût global de la formation, mais n'obtiendrez presque aucune perte de performances puisque les informations nécessaires à l'apprentissage du modèle sont conservé au maximum Le modèle final, les résultats expérimentaux sont présentés dans le coin inférieur droit de la figure 7. En plus des opérations dans le domaine fréquentiel, du point de vue de la transformation du domaine spatial, le modèle peut également être trouvé dans termes de fonctionnalités "relativement simples". Par exemple, les informations d'image naturelles contenues dans une entrée visuelle brute qui n'ont pas fait l'objet d'une forte amélioration des données ou d'un traitement de distorsion sont souvent « plus simples » pour le modèle et plus faciles à apprendre pour le modèle car elles sont dérivées de distributions du monde réel, et plus encore. les informations, l'invariance, etc. introduites par les techniques de prétraitement telles que l'amélioration des données sont souvent difficiles à apprendre pour le modèle (un exemple typique est donné sur le côté gauche de la figure 8). En fait, des recherches existantes ont également observé que l'augmentation des données joue principalement un rôle dans les étapes ultérieures de l'entraînement (comme "Improving Auto-Augment via Augmentation-Wise Weight Sharing", NeurIPS'20). Dans cette dimension, afin de réaliser le paradigme de l'apprentissage de cours généralisé, cela peut être facilement réalisé en modifiant simplement l'intensité de l'augmentation des données pour fournir au modèle uniquement des informations d'image naturelles qui sont plus faciles à apprendre dans les données d'entraînement dans le premières étapes de la formation. Le côté droit de la figure 8 utilise RandAugment comme exemple représentatif pour vérifier cette idée. RandAugment contient une série de transformations courantes d'amélioration des données spatiales (telles que la rotation aléatoire, la modification de la netteté, la transformation affine, la modification de l'exposition, etc.). On peut observer que l'entraînement du modèle à partir d'une augmentation de données plus faible peut améliorer efficacement les performances finales du modèle, et cette technique est compatible avec le recadrage basse fréquence. Jusqu'à présent, cet article a proposé le cadre de base et les hypothèses de l'apprentissage de cours généralisé. , et en révélant Deux phénomènes clés dans le domaine fréquentiel et le domaine spatial prouvent la rationalité et l'efficacité de l'apprentissage généralisé des cours. Sur cette base, cet article complète une série de travaux systématiques, répertoriés ci-dessous. En raison du manque d’espace, veuillez vous référer à l’article original pour plus de détails sur la recherche. Le plan d'apprentissage du cours généralisé EfficientTrain++ finalement obtenu dans cet article est présenté dans la figure 9. EfficientTrain++ ajuste dynamiquement la bande passante du recadrage basse fréquence du domaine fréquentiel et l'intensité de l'amélioration des données du domaine spatial en fonction du pourcentage de consommation de la surcharge de calcul totale de la formation du modèle. Il convient de noter qu'en tant que méthode plug-and-play, EfficientTrain++ peut être directement appliqué à une variété de réseaux visuels de base et à divers scénarios de formation de modèles sans ajustement ni recherche d'hyperparamètres supplémentaires, et que l'effet est relativement stable. . En tant que méthode plug-and-play, EfficientTrain++ réduit la surcharge réelle de formation de divers réseaux visuels de base d'environ 1,5 fois sur ImageNet-1K sans perdre ni améliorer les performances. Le gain d'EfficientTrain++ est universel pour différents budgets de frais généraux de formation Avec strictement les mêmes performances, DeiT/Swin fonctionne mieux. sur ImageNet Le taux d'accélération de la formation sur -1K est d'environ 2 à 3 fois. EfficientTrain++ peut atteindre une accélération de pré-entraînement 2 à 3 fois sans perte de performances sur ImageNet-22k. Pour les modèles plus petits, EfficientTrain++ peut obtenir des améliorations significatives de la limite supérieure des performances. EfficientTrain++ est également efficace pour les algorithmes d'apprentissage auto-supervisés (tels que MAE). EfficientTrain++ Le modèle entraîné ne perd pas non plus de performances sur les tâches en aval telles que la détection de cibles, la segmentation d'instance et la segmentation sémantique.  Figure 5 Du point de vue du domaine fréquentiel, le modèle a naturellement tendance à apprendre d'abord à identifier les caractéristiques basse fréquence
Figure 5 Du point de vue du domaine fréquentiel, le modèle a naturellement tendance à apprendre d'abord à identifier les caractéristiques basse fréquence  Figure 6 Fournir uniquement des composants basse fréquence au modèle pendant une longue période d'entraînement précoce n'affectera pas de manière significative les performances finales
Figure 6 Fournir uniquement des composants basse fréquence au modèle pendant une longue période d'entraînement précoce n'affectera pas de manière significative les performances finales Figure 7 Recadrage basse fréquence : faire en sorte que le modèle apprenne efficacement uniquement à partir d'informations basse fréquence
Figure 7 Recadrage basse fréquence : faire en sorte que le modèle apprenne efficacement uniquement à partir d'informations basse fréquence Figure 8 Trouver les fonctionnalités « plus faciles à apprendre » du modèle du point de vue de l'espace aérien : une perspective d'amélioration des données
Figure 8 Trouver les fonctionnalités « plus faciles à apprendre » du modèle du point de vue de l'espace aérien : une perspective d'amélioration des données
 Figure 9 Plan d'apprentissage de cours généralisé unifié et intégré : EfficientTrain++
Figure 9 Plan d'apprentissage de cours généralisé unifié et intégré : EfficientTrain++ III. Résultats expérimentaux
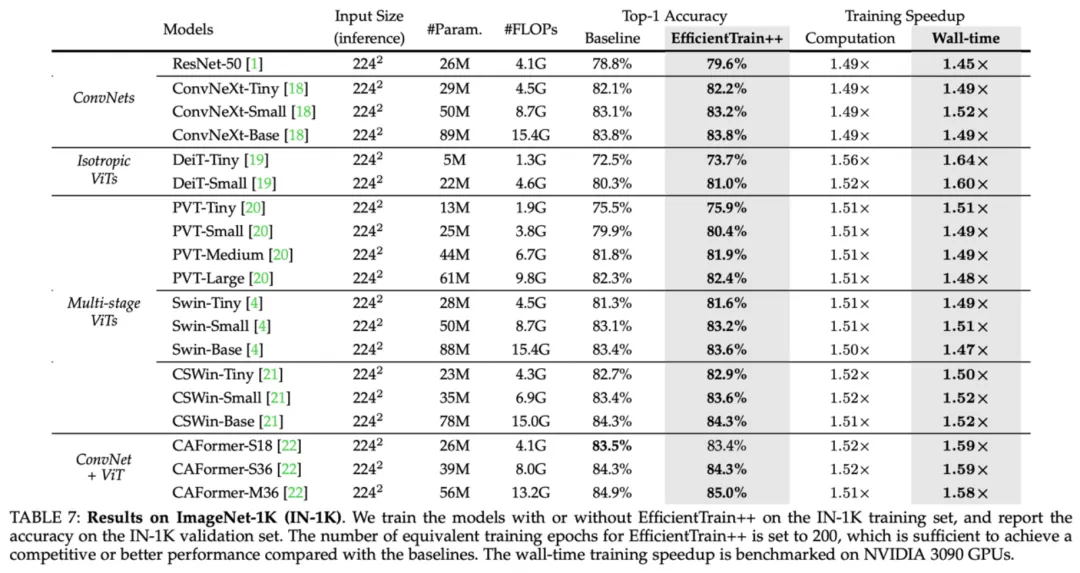 Figure 10 Résultats expérimentaux ImageNet-1K : performances d'EfficientTrain++ sur une variété de réseaux visuels de base
Figure 10 Résultats expérimentaux ImageNet-1K : performances d'EfficientTrain++ sur une variété de réseaux visuels de base  Figure 11 Résultats expérimentaux ImageNet-1K : performances d'EfficientTrain++ sous différents budgets de frais généraux de formation
Figure 11 Résultats expérimentaux ImageNet-1K : performances d'EfficientTrain++ sous différents budgets de frais généraux de formation  Figure 12 Résultats expérimentaux ImageNet-22K : performances d'EfficientTrain++ sur des données d'entraînement à plus grande échelle
Figure 12 Résultats expérimentaux ImageNet-22K : performances d'EfficientTrain++ sur des données d'entraînement à plus grande échelle Figure 13 Résultats expérimentaux ImageNet-1K : EfficientTrain++ peut améliorer considérablement la limite supérieure des performances des modèles plus petits
Figure 13 Résultats expérimentaux ImageNet-1K : EfficientTrain++ peut améliorer considérablement la limite supérieure des performances des modèles plus petits  Figure 14 EfficientTrain++ peut être appliqué à l'apprentissage auto-supervisé (tel que MAE)
Figure 14 EfficientTrain++ peut être appliqué à l'apprentissage auto-supervisé (tel que MAE)  Figure 15 Détection de cible COCO, segmentation d'instance COCO et résultats expérimentaux de segmentation sémantique ADE20K
Figure 15 Détection de cible COCO, segmentation d'instance COCO et résultats expérimentaux de segmentation sémantique ADE20K
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 ppt en mot
ppt en mot
 Comment augmenter le nombre de fans de Douyin rapidement et efficacement
Comment augmenter le nombre de fans de Douyin rapidement et efficacement
 Comment acheter des pièces fil
Comment acheter des pièces fil
 Comment utiliser debug.exe
Comment utiliser debug.exe
 Quelles sont les principales technologies de pare-feux ?
Quelles sont les principales technologies de pare-feux ?
 Solution d'erreur httpsstatus500
Solution d'erreur httpsstatus500
 Ripple a-t-il toujours une valeur d'investissement ?
Ripple a-t-il toujours une valeur d'investissement ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



