
 Périphériques technologiques
IA
La première action d'Ilya après avoir quitté son emploi : il a aimé ce journal et les internautes se sont précipités pour le lire
Périphériques technologiques
IA
La première action d'Ilya après avoir quitté son emploi : il a aimé ce journal et les internautes se sont précipités pour le lire
La première action d'Ilya après avoir quitté son emploi : il a aimé ce journal et les internautes se sont précipités pour le lire

Depuis qu'Ilya Sutskever a officiellement annoncé sa démission d'OpenAI, sa prochaine décision est devenue le centre de l'attention de tous.
Certaines personnes prêtent même une attention particulière à chacun de ses mouvements.
Non, Ilya a juste aimé ❤️ un nouveau journal -
- et les internautes se sont précipités pour l'aimer :

Le journal vient du MIT, l'auteur a proposé une hypothèse, qui peut être résumé en une phrase comme celle-ci :
Les réseaux de neurones sont entraînés avec différents objectifs sur différentes données et modalités, et ont tendance à former un espace de représentation partagé dans leur espace de représentation .

Ils ont nommé cette spéculation l’Hypothèse de la représentation platonicienne, en référence à l’allégorie de la grotte de Platon et à ses idées sur la nature de la réalité idéale.

La sélection d'Ilya est toujours garantie. Certains internautes l'ont qualifié de meilleur journal qu'ils ont vu cette année après l'avoir lu :

Certains internautes sont vraiment talentueux Après l'avoir lu, ils ont utilisé "Anna" Pour. En résumé, la phrase d'ouverture de "Karenina" : Tous les modèles de langage heureux sont similaires, et chaque modèle de langage malheureux a son propre malheur.

Pour paraphraser le célèbre dicton de Whitehead : tout apprentissage automatique est une note de bas de page de Platon.

Nous avons également jeté un coup d'œil, et le contenu général est le suivant :
L'auteur a analysé la Convergence représentationnelle(Convergence représentationnelle) du système d'IA, c'est-à-dire la représentation des points de données dans différents les modèles de réseaux neuronaux deviennent de plus en plus similaires dans différentes architectures de modèles, objectifs de formation et même modalités de données.
Qu’est-ce qui motive cette convergence ? Cette tendance va-t-elle se poursuivre ? Où est sa destination finale ?
Après une série d'analyses et d'expérimentations, les chercheurs ont émis l'hypothèse que cette convergence avait un point final et un principe directeur : Différents modèles s'efforcent d'obtenir une représentation précise de la réalité.
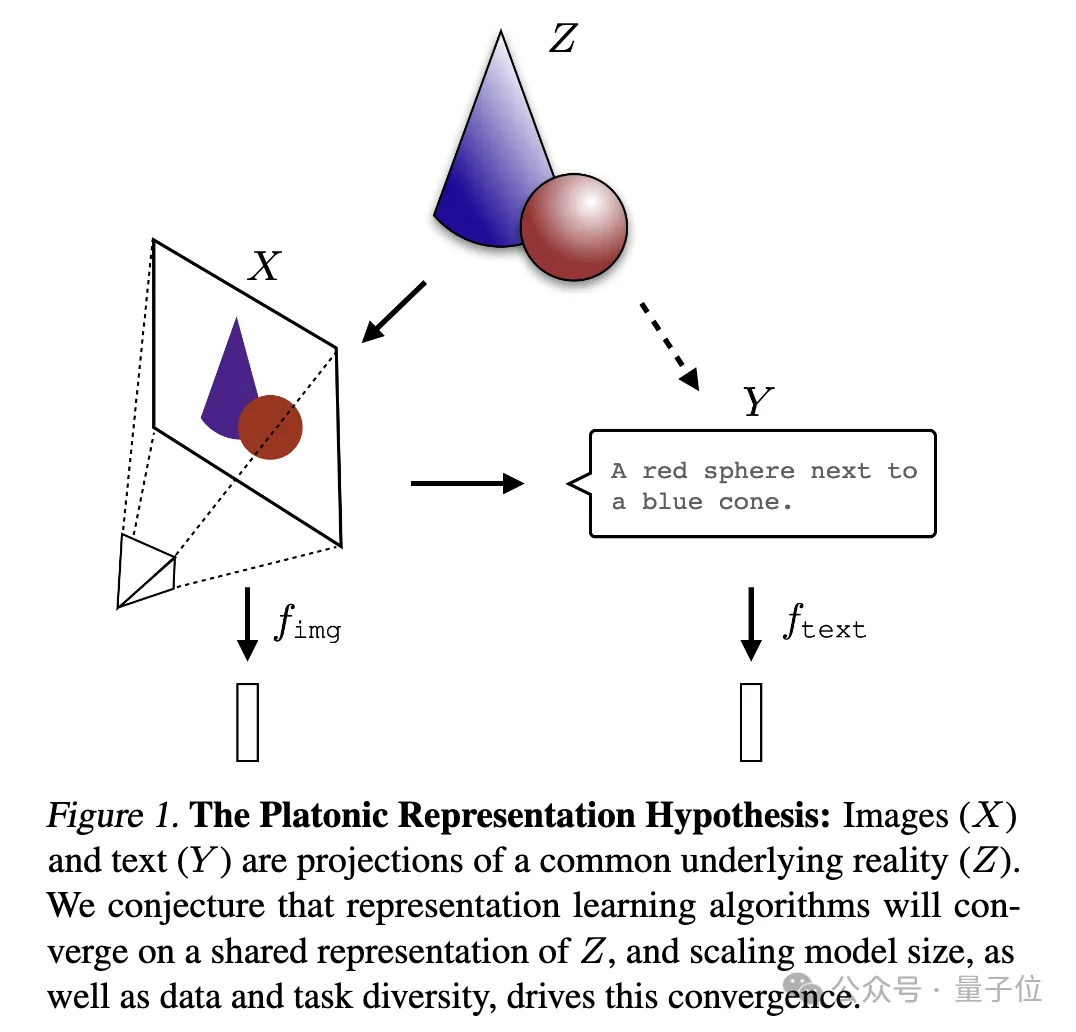
Une image pour expliquer :
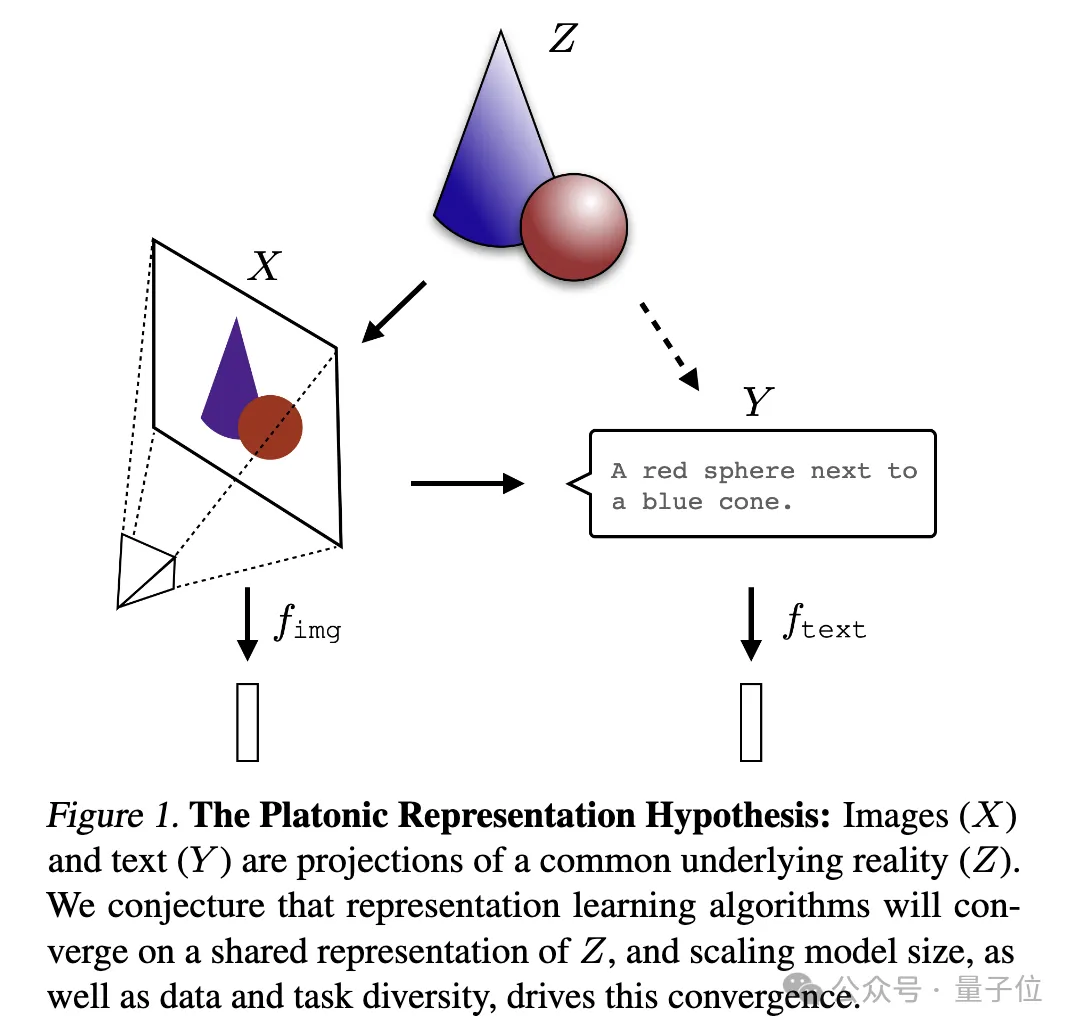
où l'image (X) et le texte (Y) sont des projections différentes d'une réalité sous-jacente commune (Z). Les chercheurs supposent que les algorithmes d’apprentissage des représentations convergeront vers une représentation unifiée de Z, et que l’augmentation de la taille du modèle et la diversité des données et des tâches sont des facteurs clés à l’origine de cette convergence.
Je peux seulement dire que c'est effectivement une question qui intéresse Ilya. Elle est trop profonde et nous ne la comprenons pas très bien. Demandons à l'IA de nous aider à l'interpréter et à la partager avec tout le monde~

. Preuves qui représentent la convergence
Tout d'abord, l'auteur a analysé un grand nombre d'études connexes antérieures, et a également mené des expériences moi-même et produit une série de preuves de convergence, démontrant la convergence, l'échelle et les performances, ainsi que la convergence intermodale de différents modèles.
Ps : Cette recherche se concentre sur la représentation d'intégration vectorielle, c'est-à-dire que les données sont converties en forme vectorielle et que la similarité ou la distance entre les points de données est décrite par la fonction du noyau. Le concept « d'alignement des représentations » dans cet article signifie que si deux méthodes de représentation différentes révèlent des structures de données similaires, alors les deux représentations sont considérées comme alignées.
1. Convergence de différents modèles Les modèles avec des architectures et des objectifs différents ont tendance à être cohérents dans leur représentation sous-jacente.
Le nombre de systèmes construits sur la base de modèles de base pré-entraînés augmente progressivement et certains modèles deviennent l'architecture de base standard pour le multitâche. Cette large applicabilité dans une variété d’applications reflète leur certaine polyvalence dans les méthodes de représentation des données.
Bien que cette tendance suggère que les systèmes d'IA convergent vers un ensemble plus restreint de modèles de base, elle ne prouve pas que différents modèles de base formeront la même représentation.
Cependant, certaines recherches récentes liées à l'assemblage de modèles(assemblage de modèles) ont révélé que les représentations de la couche intermédiaire des modèles de classification d'images peuvent être bien alignées même lorsqu'elles sont entraînées sur différents ensembles de données.
Par exemple, certaines recherches ont révélé que les premières couches de réseaux convolutionnels formés sur les ensembles de données ImageNet et Places365 peuvent être interchangées, indiquant qu'elles ont appris des représentations visuelles initiales similaires. Il existe également des études qui ont découvert un grand nombre de « neurones Rosetta », c'est-à-dire des neurones avec des modèles d'activation très similaires dans différents modèles visuels...
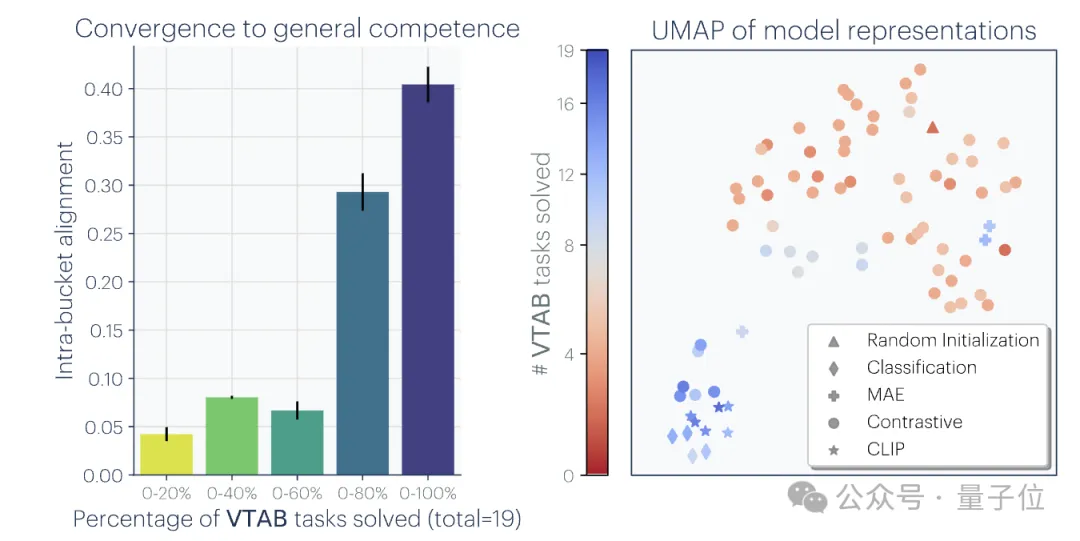
2. Plus la taille et les performances du modèle sont grandes, meilleure est la représentation. Plus l'alignement est élevé.
Les chercheurs ont mesuré l'alignement de 78 modèlesen utilisant la méthode du voisin le plus proche sur l'ensemble de données Places-365 et ont évalué leurs performances en aval sur le benchmark d'adaptation des tâches de vision VTAB.
3. Convergence de la représentation du modèle dans différents modes.
Les chercheurs ont utilisé la méthode du voisin le plus proche pour mesurer l'alignement sur l'ensemble de données d'images Wikipédia WIT. Les résultats révèlent une relation linéaire entre l'alignement langage-visuel et les scores de modélisation du langage, la tendance générale étant que les modèles de langage plus performants s'alignent mieux avec les modèles visuels plus performants.
4. Le modèle et la représentation du cerveau montrent également un certain degré de cohérence, peut-être en raison du fait de faire face à des données et des contraintes de tâches similaires.
En 2014, une étude a révélé que l'activation de la couche intermédiaire du réseau neuronal est fortement corrélée au modèle d'activation de la zone visuelle du cerveau, probablement en raison du fait de faire face à des tâches visuelles et à des contraintes de données similaires. Depuis lors, des études ont en outre montré que l'utilisation de différentes données d'entraînement affecterait l'alignement des représentations du cerveau et du modèle. La recherche psychologique a également montré que la façon dont les humains perçoivent la similitude visuelle est très cohérente avec les modèles de réseaux neuronaux.5. Le degré d'alignement des représentations du modèle est positivement corrélé à la performance des tâches en aval.
Les chercheurs ont utilisé deux tâches en aval pour évaluer les performances du modèle : Hellaswag(raisonnement de bon sens) et GSM8K (mathématiques) . Et utilisez le modèle DINOv2 comme référence pour mesurer l'alignement d'autres modèles de langage avec le modèle visuel.
Les résultats expérimentaux montrent que les modèles de langage plus alignés sur le modèle visuel fonctionnent également mieux sur les tâches Hellaswag et GSM8K. Les résultats de la visualisation montrent qu'il existe une corrélation positive claire entre le degré d'alignement et l'exécution des tâches en aval.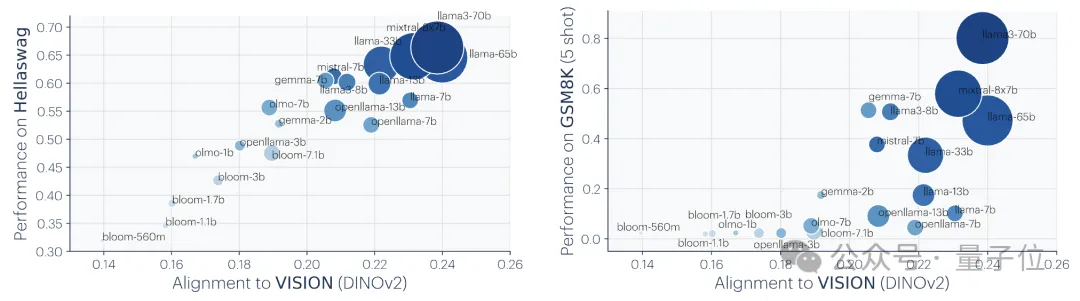

1. Convergence via la généralité des tâches (Convergence via la généralité des tâches)
À mesure que les modèles sont formés pour résoudre davantage de tâches, ils doivent trouver des représentations qui peuvent répondre aux exigences de toutes les tâches : Être compétent Le nombre de représentations pour N tâches est inférieur au nombre de représentations capables d'effectuer M (M
Un principe similaire a déjà été proposé. Le schéma est le suivant :

De plus, les tâches faciles ont plusieurs solutions, tandis que les tâches difficiles ont moins de solutions. Par conséquent, à mesure que la difficulté de la tâche augmente, la représentation du modèle tend à converger vers de meilleures solutions, mais avec moins de solutions.
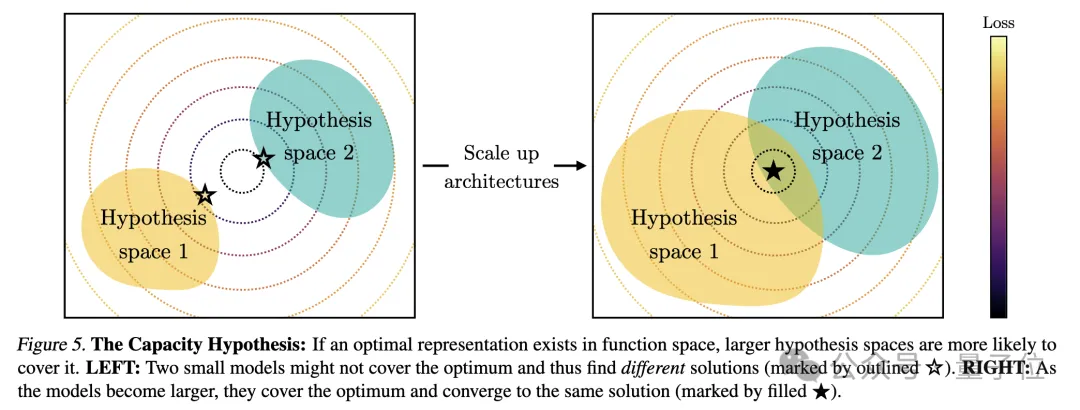
2. La capacité du modèle mène à la convergence (Convergence via la capacité du modèle)
Les chercheurs ont souligné l'hypothèse de capacité S'il existe une représentation globalement optimale, alors sous la condition de données suffisantes, un modèle plus grand sera. plus efficace peut s’approcher de cette solution optimale.
Par conséquent, les modèles plus importants utilisant le même objectif de formation, quelle que soit leur architecture, auront tendance à converger vers cette solution optimale. Lorsque différents objectifs de formation ont des minimums similaires, les modèles plus grands sont plus efficaces pour trouver ces minimums et tendent à proposer des solutions similaires dans les tâches de formation.

Le diagramme est le suivant :
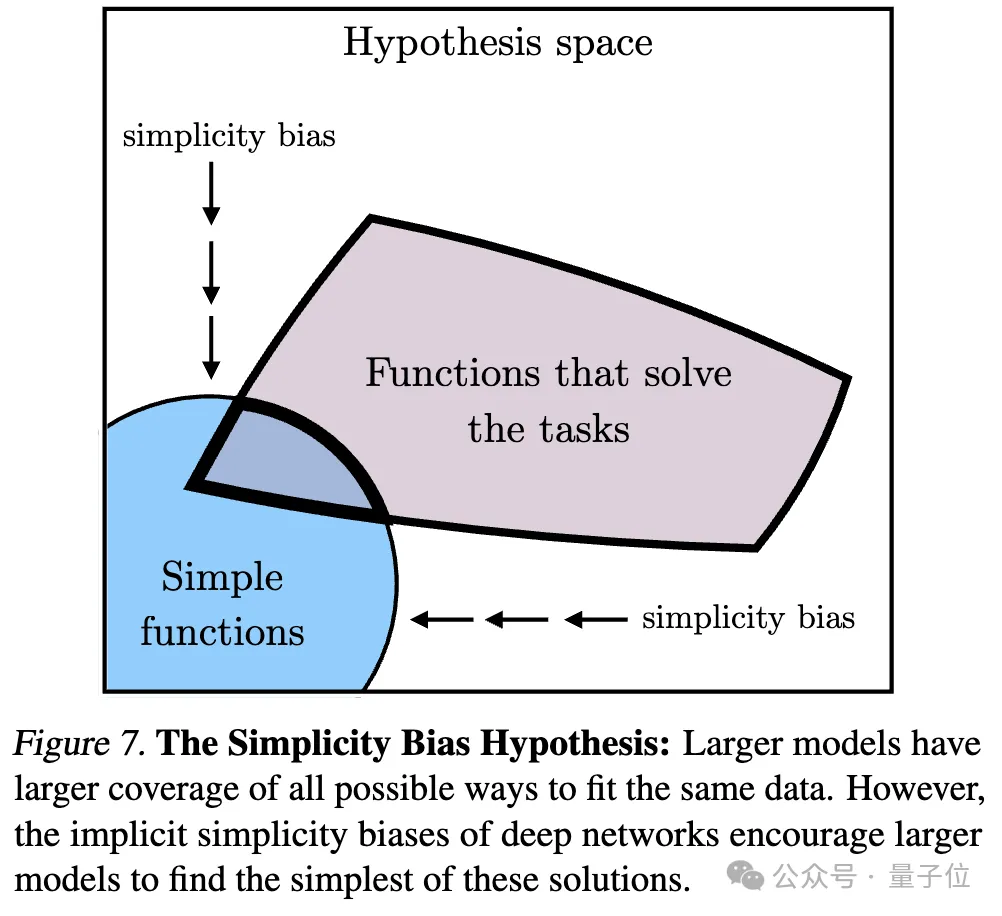
3. Convergence via le biais de simplicité (Convergence via le biais de simplicité)
Concernant la raison de la convergence, les chercheurs ont également proposé une hypothèse. Les réseaux profonds ont tendance à rechercher des ajustements simples aux données. Ce biais de simplicité inhérent fait que les grands modèles ont tendance à être simplifiés dans leur représentation, conduisant à une convergence.

C'est-à-dire que les modèles plus grands ont une couverture plus large et sont capables d'adapter les mêmes données de toutes les manières possibles. Cependant, la préférence implicite des réseaux profonds pour la simplicité encourage les modèles plus vastes à trouver la plus simple de ces solutions.
Le point final de la convergence
Après une série d'analyses et d'expériences, comme mentionné au début, les chercheurs ont proposé l'Hypothèse de la représentation de Platon, spéculant sur le point final de cette convergence.
C'est-à-dire que différents modèles d'IA, bien que formés sur des données et des cibles différentes, leurs espaces de représentation convergent vers un modèle statistique commun qui représente le monde réel qui génère les données que nous observons.
Ils ont d’abord construit un modèle idéalisé de monde à événements discrets. Le monde contient une série d'événements discrets Z, chaque événement est échantillonné à partir d'une distribution inconnue P(Z). Chaque événement peut être observé de différentes manières grâce à la fonction d'observation obs, comme les pixels, les sons, le texte, etc.
Ensuite, l'auteur considère une classe d'algorithmes d'apprentissage contrastif qui tentent d'apprendre une représentation fX telle que le produit scalaire de fX(xa) et fX(xb) se rapproche de xa et ) du rapport du log des chances de au log chances d'être une paire d'échantillons négatifs (échantillonnés au hasard) .

(PMI) de xa et xb La représentation du noyau FX.



Les chercheurs ont testé cette théorie à travers une étude empirique sur la couleur. Que la représentation des couleurs soit apprise à partir des statistiques de cooccurrence de pixels d'images ou de statistiques de cooccurrence de mots de texte, les distances de couleurs résultantes sont similaires à la perception humaine et, à mesure que la taille du modèle augmente, cette similarité devient de plus en plus élevée.
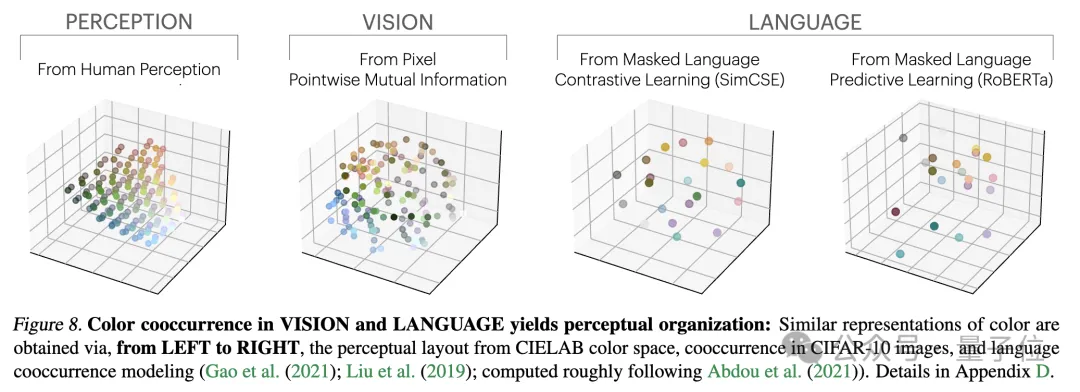
Cela est conforme à l'analyse théorique, c'est-à-dire qu'une plus grande capacité de modèle peut modéliser avec plus de précision les statistiques des données d'observation, obtenant ainsi un noyau PMI plus proche de la représentation idéale des événements.
Quelques réflexions finales
À la fin de l'article, l'auteur résume l'impact potentiel de la convergence des représentations sur le domaine de l'IA et les orientations de recherche futures, ainsi que les limites et exceptions potentielles à l'hypothèse de la représentation platonicienne.
Ils ont souligné qu'à mesure que la taille du modèle augmente, les impacts possibles de la convergence de la représentation incluent, sans s'y limiter :
- Bien que la simple mise à l'échelle puisse améliorer les performances, différentes méthodes présentent des différences en termes d'efficacité de mise à l'échelle.
- S'il existe une représentation platonicienne indépendante des modalités, alors les données de différentes modalités doivent être formées conjointement pour trouver cette représentation partagée. Cela explique pourquoi il est avantageux d'ajouter des données visuelles à la formation du modèle de langage et vice versa.
- La conversion entre représentations alignées devrait être relativement simple, ce qui peut expliquer : la génération conditionnelle est plus facile que la génération inconditionnelle, et la conversion multimodale peut également être réalisée sans données appariées.
- L'augmentation de la taille du modèle peut réduire la tendance des modèles linguistiques à fabriquer du contenu et certains de leurs biais, ce qui leur permettra de refléter plus précisément les biais des données de formation plutôt que de les exacerber.
L'auteur souligne que la prémisse de l'impact ci-dessus est que les données d'entraînement des futurs modèles doivent être suffisamment diverses et sans perte pour véritablement converger vers une représentation qui reflète les lois statistiques du monde réel.
Dans le même temps, l'auteur a également déclaré que les données de différentes modalités peuvent contenir des informations uniques, ce qui peut rendre difficile l'obtention d'une convergence complète des représentations, même si la taille du modèle augmente. De plus, toutes les représentations ne convergent pas actuellement. Par exemple, il n’existe pas de manière standardisée de représenter les États dans le domaine de la robotique. Les chercheurs et les préférences de la communauté peuvent conduire les modèles à converger vers des représentations humaines, ignorant ainsi d’autres formes possibles d’intelligence.
Et les systèmes intelligents conçus spécifiquement pour des tâches spécifiques peuvent ne pas converger vers les mêmes représentations que l'intelligence générale.
Les auteurs soulignent également que les méthodes de mesure de l’alignement des représentations sont controversées et que différentes méthodes de mesure peuvent conduire à des conclusions différentes. Même si les représentations des différents modèles sont similaires, des écarts restent à expliquer, et il est actuellement impossible de déterminer si cet écart est important.
Pour plus de détails et les méthodes d'argumentation, je publierai l'article ici~
Lien papier : https://arxiv.org/abs/2405.07987
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1666
1666
 14
1426
52
1328
25
1273
29
1254
24
14
1426
52
1328
25
1273
29
1254
24

 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
