
 Périphériques technologiques
IA
Le nouveau travail de LeCun : modèle du monde en couches, contrôle de robot humanoïde basé sur les données
Périphériques technologiques
IA
Le nouveau travail de LeCun : modèle du monde en couches, contrôle de robot humanoïde basé sur les données
Le nouveau travail de LeCun : modèle du monde en couches, contrôle de robot humanoïde basé sur les données

Avec les grands modèles comme bénédiction intelligente, les robots humanoïdes sont devenus une nouvelle tendance.
Le robot du film de science-fiction "je peux dire que je ne suis pas un humain" semble se rapprocher.
Cependant, penser et agir comme des humains reste un problème d'ingénierie difficile pour les robots, en particulier les robots humanoïdes.
Prenons comme exemple un simple apprentissage de la marche. L'utilisation de l'apprentissage par renforcement pour s'entraîner peut évoluer vers ce qui suit :

Il n'y a aucun problème en théorie (en suivant le mécanisme de récompense), et l'objectif d'y aller. monter les escaliers a été atteint, sauf que le processus est relativement abstrait, il peut ne pas être le même que la plupart des modèles de comportement humain.
La raison pour laquelle il est difficile pour les robots d'agir « naturellement » comme les humains est due à la nature de haute dimension de l'espace d'observation et d'action, et à l'instabilité inhérente à la forme bipède.
À cet égard, un travail auquel LeCun a participé a donné une nouvelle solution basée sur les données.

Adresse en papier: https://arxiv.org/pdf/2405.18418
project Introduction: https://nicklashanansen.com/rlpuppeteer
look à l'efficacité d'abord:

En comparant l'effet de droite, la nouvelle méthode a entraîné des comportements plus proches des humains. Bien qu'elle ait une signification un peu "zombie", le niveau d'abstraction a été considérablement réduit, du moins dans la limite des capacités de. la plupart des humains.
Bien sûr, certains internautes venus semer le trouble ont déclaré : "Celui d'avant avait l'air plus intéressant."

Dans ce travail, les chercheurs explorent une approche de contrôle humanoïde visuel du corps entier, hautement basée sur les données, basée sur l'apprentissage par renforcement sans aucune hypothèse simplificatrice, conception de récompense ou primitive de compétence.
L'auteur a proposé un modèle mondial hiérarchique pour former deux agents, de haut niveau et de bas niveau. L'agent de haut niveau génère des commandes basées sur des observations visuelles que l'agent de bas niveau doit exécuter.
Code source ouvert : https://github.com/nicklashansen/puppeteer
Ce modèle, nommé Puppeteer, utilise un robot humanoïde simulé à 56 DoF pour générer des performances élevées dans 8 tâches Stratégies de contrôle des performances tout en synthétisant les mouvements naturels de type humain et la capacité de traverser des terrains difficiles.

Modèle du monde hiérarchique contrôlé de haute dimension
L'apprentissage et la formation d'agents polyvalents dans le monde physique ont toujours été l'un des objectifs de la recherche dans le domaine de l'IA.
Les robots humanoïdes peuvent effectuer diverses tâches en intégrant le contrôle et la perception de l'ensemble du corps, ils se distinguent donc comme des plates-formes multifonctionnelles.
Mais le coût de l'imitation d'animaux avancés comme nous reste très élevé.
Par exemple, dans l'image ci-dessous, afin d'éviter d'entrer dans les fosses, le robot humanoïde doit détecter avec précision la position et la longueur de l'espace au sol venant en sens inverse, et en même temps coordonner soigneusement les mouvements de tout son corps afin que il a suffisamment d’élan et de portée pour franchir chaque écart.

Puppeteer est une méthode RL basée sur les données et basée sur le modèle mondial hiérarchique JEPA proposé par LeCun en 2022.
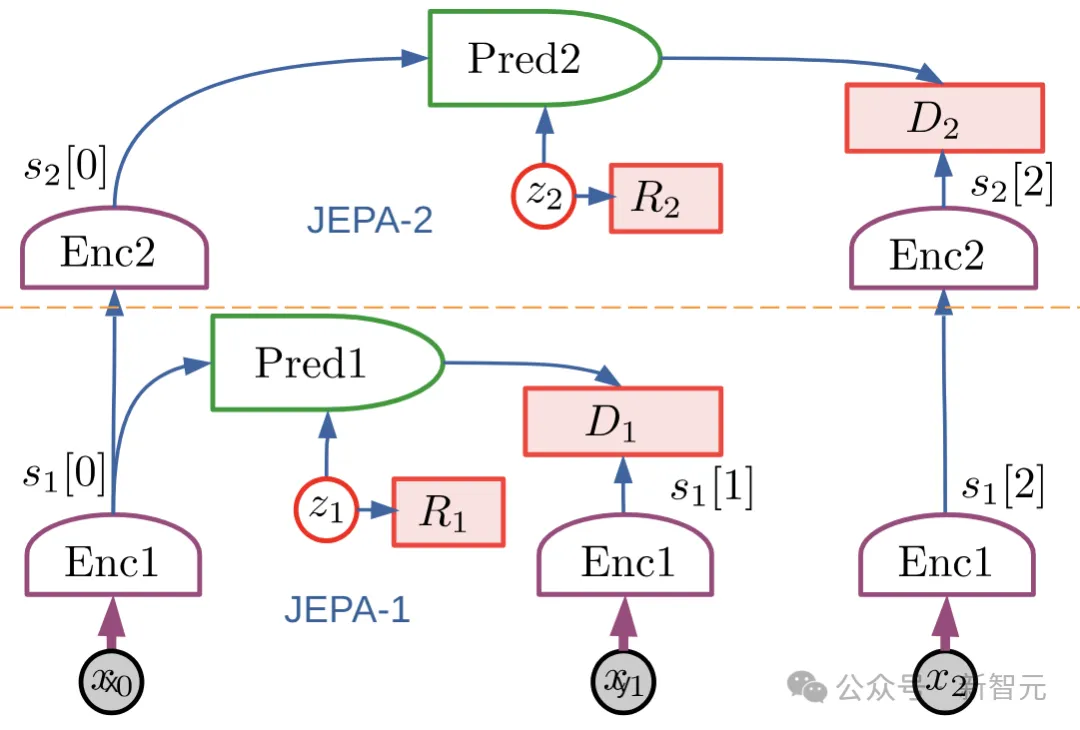
Il se compose de deux agents différents : l'un est responsable de la perception et du suivi, en suivant le mouvement de référence via un contrôle au niveau des articulations ; l'autre "marionnette visuelle" (marionnettiste) apprend à effectuer des tâches en aval en synthétisant un mouvement de référence de faible dimension, qui est l'ancien support de suivi.
Puppeteer utilise l'algorithme RL basé sur un modèle-TD-MPC2 pour former indépendamment deux agents en deux étapes différentes.
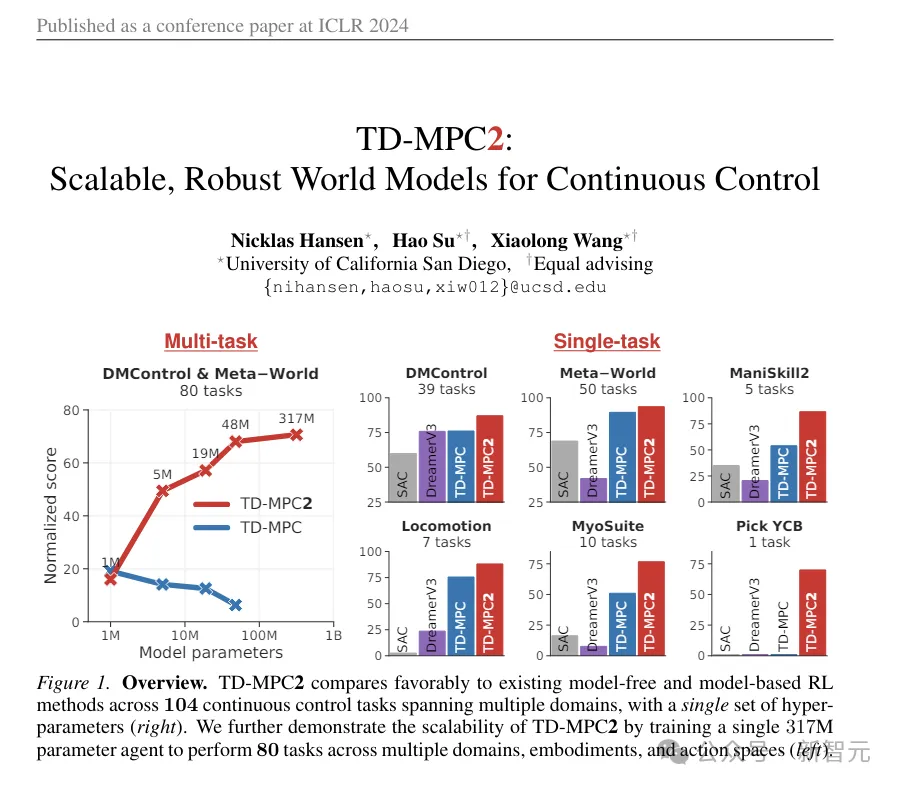
(ps : Ce TD-MPC2 est l'image animée utilisée à titre de comparaison au début de l'article. Bien qu'elle semble un peu abstraite, il s'agit en fait du SOTA précédent, publié dans l'ICLR de cette année, et le premier travail est également le premier travail de cet article.)
Dans la première étape, le modèle mondial de suivi est d'abord pré-entraîné, en utilisant des données de capture de mouvement humain préexistantes comme référence pour convertir le mouvement en actions physiquement exécutables. . Cet agent peut être enregistré et réutilisé dans toutes les tâches en aval.
Dans la deuxième étape, un modèle de monde de marionnettes est formé, qui prend des observations visuelles en entrée et intègre le mouvement de référence fourni par un autre agent en sortie selon la tâche en aval spécifiée.
Ce cadre semble très simple : les deux modèles mondiaux sont algorithmiquement identiques, seulement différents en entrée/sortie, et sont formés à l'aide de RL sans aucune autre cloche et sifflet.
Différent des paramètres RL hiérarchiques traditionnels, "Puppet" affiche les positions géométriques des articulations effectrices terminales plutôt que l'intégration de la cible.
Cela rend l'agent responsable du suivi facile à partager et à généraliser entre les tâches, économisant ainsi de l'espace informatique global.
Méthode de recherche
Les chercheurs ont modélisé le contrôle humanoïde visuel du corps entier comme un problème d'apprentissage par renforcement contrôlé par un processus de décision de Markov (MDP), basé sur le tuple (S, A, T, R, γ , Δ) sont des caractéristiques,
où S est l'état, A est l'action, T est la fonction de transition d'environnement, R est la fonction de récompense scalaire, γ est le facteur d'actualisation et Δ est la condition de terminaison.
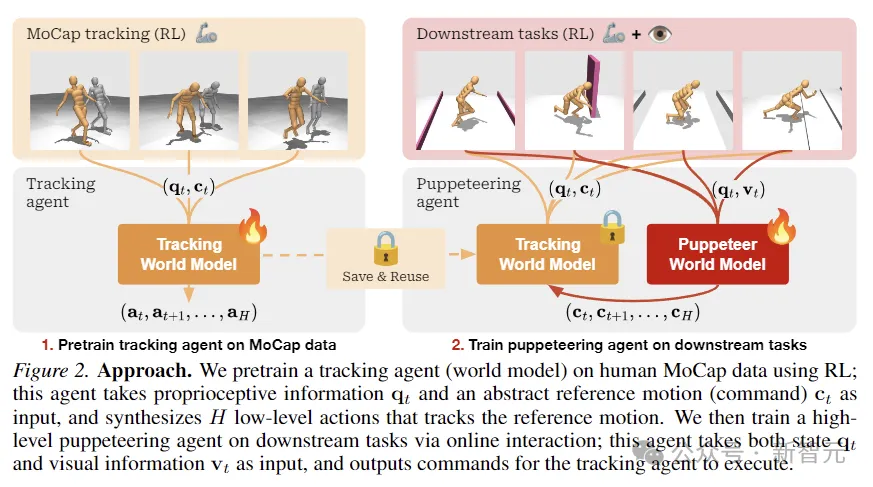
Comme le montre la figure ci-dessus, les chercheurs ont utilisé RL pour pré-entraîner l'agent de suivi sur les données MoCap humaines, qui ont été utilisées pour obtenir des informations proprioceptives et une entrée de mouvement de référence abstraite, et synthétiser des actions de bas niveau pour suivre le mouvement de référence.
Ensuite, grâce à l'interaction en ligne, l'agent marionnette avancé responsable des tâches en aval est formé. La marionnette accepte l'entrée d'informations d'état et visuelles et émet des commandes que l'agent de suivi doit exécuter.
TD-MPC2
TD-MPC2 apprend un modèle mondial latent sans décodeur à partir des interactions environnementales et utilise le modèle appris pour la planification.
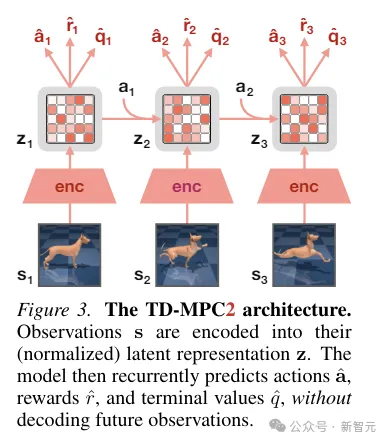
Tous les composants du modèle mondial sont appris de bout en bout en utilisant une combinaison de prédiction d'intégration conjointe, de prédiction de récompense et de perte de différence temporelle sans décoder les observations originales.
Pendant l'inférence, TD-MPC2 suit le cadre Model Predictive Control (MPC), en utilisant Model Predictive Path Integral (MPPI) comme optimiseur sans dérivé (basé sur l'échantillonnage) pour l'optimisation de trajectoire locale.
Afin d'accélérer la planification, TD-MPC2 apprend également à l'avance une stratégie sans modèle pour pré-démarrer le programme d'échantillonnage.
Les deux agents sont algorithmiquement identiques et tous deux sont constitués des 6 composants suivants :

Expérience
Pour évaluer l'efficacité de la méthode, les chercheurs ont proposé une nouvelle La suite de tâches utilise un 56 simulé -Robot humanoïde à degré de liberté pour le contrôle visuel de tout le corps. Il contient un total de 8 tâches difficiles. Les méthodes utilisées pour la comparaison incluent SAC, DreamerV3 et TD-MPC2.
Les 8 tâches sont présentées dans la figure ci-dessous, dont 5 tâches de mouvement du corps entier liées à la condition visuelle et 3 autres tâches sans entrée visuelle.
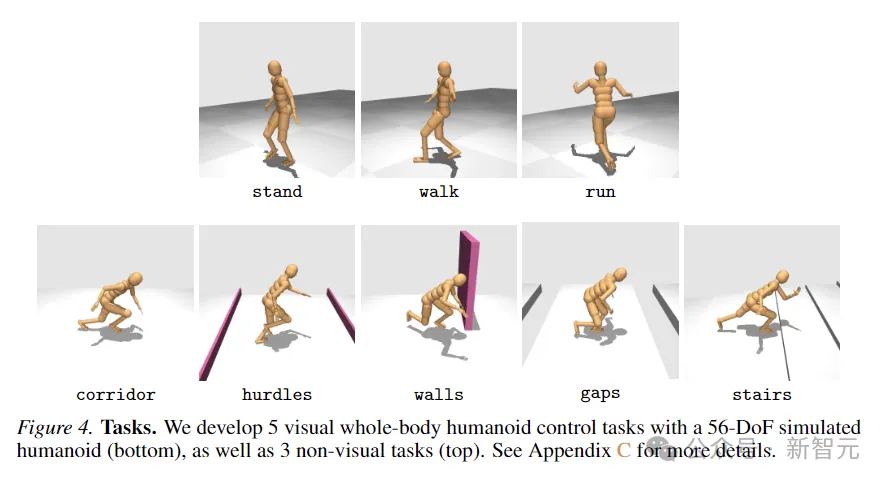
Les quêtes sont conçues avec un haut degré d'aléatoire et incluent courir dans des couloirs, sauter par-dessus des obstacles et des interstices, monter des escaliers et contourner les murs.
Les cinq tâches de contrôle visuel utilisent toutes une fonction de récompense proportionnelle à la vitesse d'avancement linéaire, tandis que les tâches non visuelles récompensent le déplacement dans n'importe quelle direction.
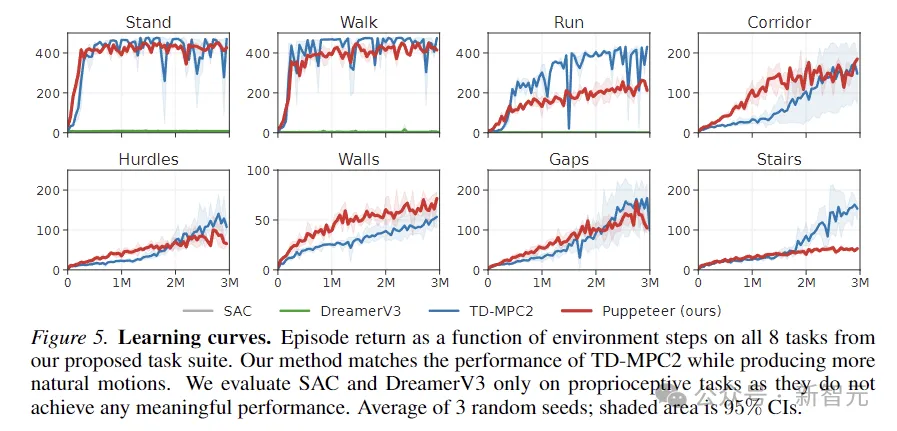
L'image ci-dessus représente la courbe d'apprentissage. Les résultats montrent que SAC et DreamerV3 sont incapables d'atteindre des performances significatives sur ces tâches.
TD-MPC2 fonctionne à égalité avec notre méthode en termes de récompenses, mais produit un comportement non naturel (voir les actions abstraites dans l'image ci-dessous).

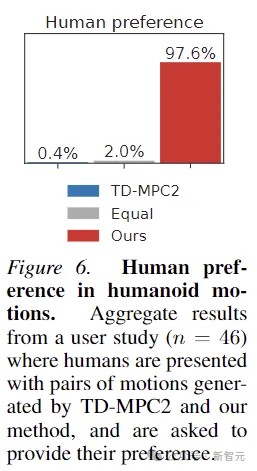
De plus, afin de prouver que les mouvements générés par Puppeteer sont effectivement plus "naturels", cet article a également mené une expérience de préférence humaine. Le test sur 46 participants a montré que les humains aiment généralement le. mouvements générés par cette méthode.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment utiliser la bibliothèque Chrono en C?
Apr 28, 2025 pm 10:18 PM
Comment utiliser la bibliothèque Chrono en C?
Apr 28, 2025 pm 10:18 PM
L'utilisation de la bibliothèque Chrono en C peut vous permettre de contrôler plus précisément les intervalles de temps et de temps. Explorons le charme de cette bibliothèque. La bibliothèque Chrono de C fait partie de la bibliothèque standard, qui fournit une façon moderne de gérer les intervalles de temps et de temps. Pour les programmeurs qui ont souffert de temps et ctime, Chrono est sans aucun doute une aubaine. Il améliore non seulement la lisibilité et la maintenabilité du code, mais offre également une précision et une flexibilité plus élevées. Commençons par les bases. La bibliothèque Chrono comprend principalement les composants clés suivants: std :: chrono :: system_clock: représente l'horloge système, utilisée pour obtenir l'heure actuelle. std :: chron
 Decryption Gate.io Strategy Medgrade: Comment redéfinir la gestion des actifs cryptographiques dans Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Medgrade: Comment redéfinir la gestion des actifs cryptographiques dans Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0 redéfinit la gestion des actifs cryptographiques grâce à une architecture innovante et à des percées de performance. 1) Il résout trois principaux points de douleur: les silos d'actifs, la désintégration du revenu et le paradoxe de la sécurité et de la commodité. 2) Grâce à des pôles d'actifs intelligents, à la gestion des risques dynamiques et aux moteurs d'amélioration du rendement, la vitesse de transfert croisée, le taux de rendement moyen et la vitesse de réponse aux incidents de sécurité sont améliorés. 3) Fournir aux utilisateurs la visualisation des actifs, l'automatisation des politiques et l'intégration de la gouvernance, réalisant la reconstruction de la valeur utilisateur. 4) Grâce à la collaboration écologique et à l'innovation de la conformité, l'efficacité globale de la plate-forme a été améliorée. 5) À l'avenir, les pools d'assurance-contrat intelligents, l'intégration du marché des prévisions et l'allocation d'actifs axés sur l'IA seront lancés pour continuer à diriger le développement de l'industrie.
 Recommandés plates-formes fiables de trading de devises numériques. Top 10 des échanges de devises numériques dans le monde. 2025
Apr 28, 2025 pm 04:30 PM
Recommandés plates-formes fiables de trading de devises numériques. Top 10 des échanges de devises numériques dans le monde. 2025
Apr 28, 2025 pm 04:30 PM
Plate-forme de trading de devises numériques fiables recommandées: 1. Okx, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. Kucoin, 7. Bitfinex, 8. Gemini, 9. Bitstamp, 10. Poloniex, ces plates-formes sont connu
 Comment mesurer les performances du fil en C?
Apr 28, 2025 pm 10:21 PM
Comment mesurer les performances du fil en C?
Apr 28, 2025 pm 10:21 PM
La mesure des performances du thread en C peut utiliser les outils de synchronisation, les outils d'analyse des performances et les minuteries personnalisées dans la bibliothèque standard. 1. Utilisez la bibliothèque pour mesurer le temps d'exécution. 2. Utilisez le GPROF pour l'analyse des performances. Les étapes incluent l'ajout de l'option -pg pendant la compilation, l'exécution du programme pour générer un fichier gmon.out et la génération d'un rapport de performances. 3. Utilisez le module Callgrind de Valgrind pour effectuer une analyse plus détaillée. Les étapes incluent l'exécution du programme pour générer le fichier callgrind.out et la visualisation des résultats à l'aide de Kcachegrind. 4. Les minuteries personnalisées peuvent mesurer de manière flexible le temps d'exécution d'un segment de code spécifique. Ces méthodes aident à bien comprendre les performances du thread et à optimiser le code.
 Laquelle des dix principales plateformes de trading de devises au monde est la dernière version des dix principales plateformes de trading de devises
Apr 28, 2025 pm 08:09 PM
Laquelle des dix principales plateformes de trading de devises au monde est la dernière version des dix principales plateformes de trading de devises
Apr 28, 2025 pm 08:09 PM
Les dix principales plates-formes de trading de crypto-monnaie au monde comprennent Binance, Okx, Gate.io, Coinbase, Kraken, Huobi Global, BitFinex, Bittrex, Kucoin et Poloniex, qui fournissent toutes une variété de méthodes de trading et de puissantes mesures de sécurité.
 Quelles sont les dix principales applications de trading de devises virtuelles? Le dernier classement de change de monnaie numérique
Apr 28, 2025 pm 08:03 PM
Quelles sont les dix principales applications de trading de devises virtuelles? Le dernier classement de change de monnaie numérique
Apr 28, 2025 pm 08:03 PM
Les dix premiers échanges de devises numériques tels que Binance, OKX, Gate.io ont amélioré leurs systèmes, des transactions diversifiées efficaces et des mesures de sécurité strictes.
 Quelles sont les principales plateformes de trading de devises? Les 10 meilleurs échanges de devises virtuels virtuels
Apr 28, 2025 pm 08:06 PM
Quelles sont les principales plateformes de trading de devises? Les 10 meilleurs échanges de devises virtuels virtuels
Apr 28, 2025 pm 08:06 PM
Actuellement classé parmi les dix premiers échanges de devises virtuels: 1. Binance, 2. Okx, 3. Gate.io, 4. Coin Library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. Bit Stamp.
 Combien vaut le bitcoin
Apr 28, 2025 pm 07:42 PM
Combien vaut le bitcoin
Apr 28, 2025 pm 07:42 PM
Le prix de Bitcoin varie de 20 000 $ à 30 000 $. 1. Le prix de Bitcoin a radicalement fluctué depuis 2009, atteignant près de 20 000 $ en 2017 et près de 60 000 $ en 2021. 2. Les prix sont affectés par des facteurs tels que la demande du marché, l'offre et l'environnement macroéconomique. 3. Obtenez des prix en temps réel via les échanges, les applications mobiles et les sites Web. 4. Le prix du bitcoin est très volatil, tiré par le sentiment du marché et les facteurs externes. 5. Il a une certaine relation avec les marchés financiers traditionnels et est affecté par les marchés boursiers mondiaux, la force du dollar américain, etc. 6. La tendance à long terme est optimiste, mais les risques doivent être évalués avec prudence.
