

Pratique avancée du graphe de connaissances industrielles

1. Introduction au contexte
Tout d'abord, présentons l'historique du développement de la technologie Yunwen.

Yunwen Technology Company...
2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles étudiés auparavant. n'a plus d'importance. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On constate que l’émergence d’une nouvelle technologie ne met pas en échec toutes les anciennes technologies. Il est également possible d’obtenir de meilleurs résultats en intégrant les nouvelles et les anciennes technologies. Nous devons nous appuyer sur les épaules de géants et poursuivre notre expansion.
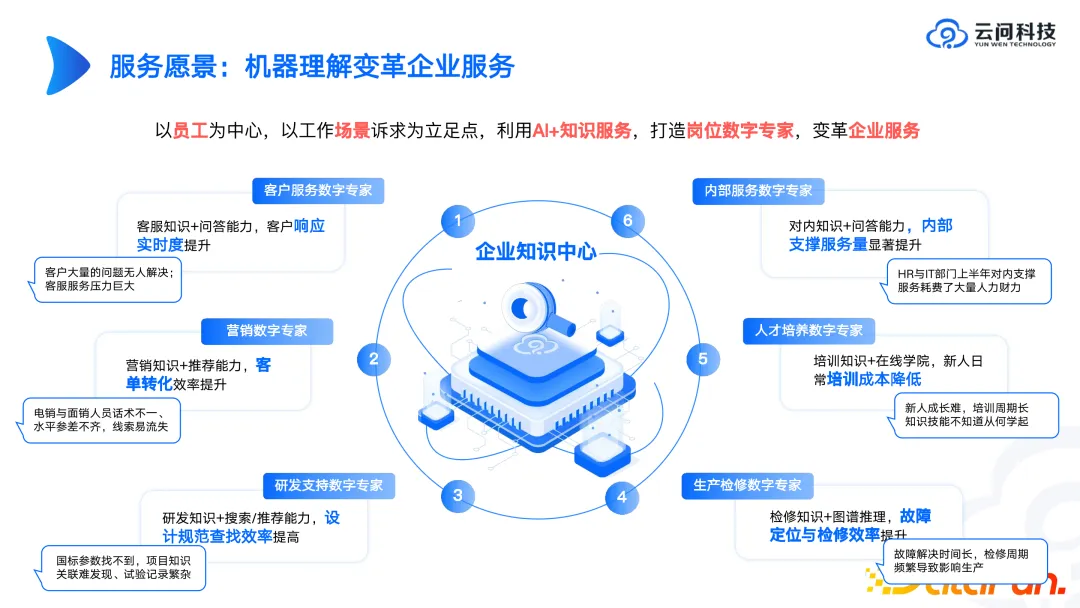
Pourquoi Yunwen Technology se concentre-t-elle sur le centre de connaissances d'entreprise ? Parce que nous avons constaté dans certains cas dans le passé que face à de nombreux scénarios complexes, tels que le contrôle des risques, les tests de dépistage de drogues, etc., il est difficile d'obtenir des résultats idéaux à court terme en laissant directement les grands modèles effectuer ces tâches complexes, et il est difficile de créer une livraison standardisée des produits. Dans les scénarios de gestion des connaissances d'entreprise ou de gestion d'entreprise liés au bureau, une opération d'essai peut être lancée relativement rapidement et des résultats idéaux peuvent être obtenus. Par conséquent, lorsque nous travaillerons cette année avec les entreprises pour créer des modèles de privatisation à grande échelle, nous inclurons la gestion des connaissances d'entreprise, y compris les questions et réponses ou la recherche basée sur la gestion des connaissances d'entreprise, comme sujet clé. Pour les entreprises, la construction de leurs propres centres de connaissances privatisés est très importante.
Pour ces raisons, s'il y a des amis qui souhaitent étudier la direction du graphe des connaissances, notre suggestion est de considérer l'ensemble du cycle de vie des connaissances, de réfléchir aux problèmes à résoudre et au lieu d'atterrissage spécifique. Par exemple, certaines entreprises utilisent des documents existants pour générer du contenu lié aux examens, aux formations et aux entretiens. Bien que ces mots techniques soient si chauds, un tel modèle de privatisation sera plus efficace que GPT3.5 ou GPT4, car dans ce scénario, une certaine scène. la pré-production est terminée. Par conséquent, nous pensons que des modèles plus spécialisés et plus sophistiqués constitueront une tendance majeure dans le développement futur.
2. Formulaire de produit cartographique
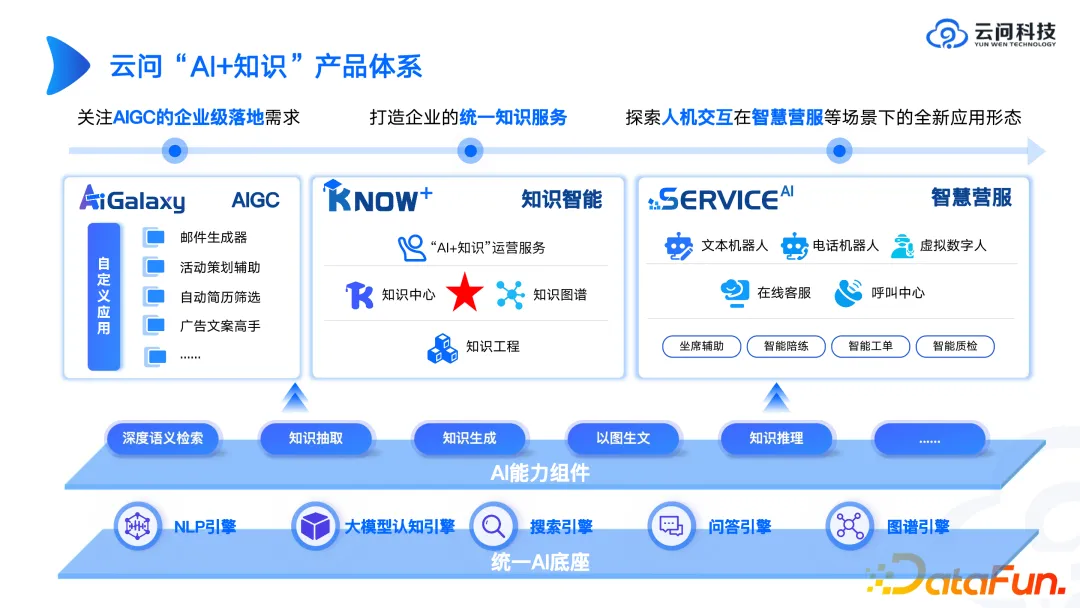
Dans l'arrière-plan ci-dessus, à quoi ressemblera le formulaire de produit cartographique ? Ensuite, nous présenterons à titre d'exemple le système de produits « IA + connaissances » de Yunwen Technology.
Tout d’abord, il doit y avoir une base d’IA unifiée. Cela ne peut pas être réalisé par une seule équipe ou même une seule entreprise. Vous pouvez utiliser des API ou des SDK tiers de moteurs de grands modèles. Dans de nombreux cas, il n'est pas nécessaire de créer une roue à partir de zéro, car il est probable que la roue qui a pris plusieurs mois à construire ne sera pas aussi efficace qu'une roue ouverte. modèle source qui vient de sortir. Par conséquent, pour la partie de base de l'IA, il est recommandé de réfléchir davantage à la manière de combiner des technologies tierces. Si vous la développez vous-même, vous devez bien réfléchir aux avantages. la valeur de la plateforme et prendre en compte les deux.
Concernant les composants de capacités d'IA, à partir de certaines de nos expériences de livraison, nous avons constaté que ces composants de capacités d'IA ont tendance à se vendre mieux que les produits. Parce que de nombreuses entreprises espèrent utiliser des composants construits par des entreprises technologiques professionnelles pour créer leurs propres applications de couche supérieure. À l’ère des grands modèles, vendre des composants capables d’IA équivaut à vendre des pelles, et les mines d’or sont toujours exploitées par les grandes entreprises elles-mêmes.
En termes d'applications de couche supérieure, nous la mettrons en œuvre dans trois directions : la propre application de l'AIGC, l'intelligence des connaissances et les services métiers intelligents. Explorez dans quelle direction il y aurait une plus grande valeur. Le graphe de connaissances est classé par nous comme un maillon central de l'ensemble de l'intelligence des connaissances. Il convient de noter que le graphe de connaissances est le noyau mais pas le seul. Nous avons déjà rencontré de nombreux scénarios. Les clients disposent d'un grand nombre de bases de données relationnelles et d'un grand nombre de documents non structurés. Nous espérons pouvoir intégrer tous ces systèmes de connaissances et actifs de connaissances dans le graphe de connaissances. Le coût pour cela est très élevé. Nous pensons que la future architecture des connaissances devrait être hétérogène. Certaines connaissances se trouvent dans des documents, d'autres dans des bases de données relationnelles et certaines connaissances peuvent provenir de réseaux de graphes. En fin de compte, ce que les grands modèles doivent faire, c'est être basé sur des bases de données multiples. source hétérogène Analyse complète des données structurelles. Par exemple, pour un élément de renseignement, vous pouvez extraire des indicateurs numériques d'une base de données relationnelle, trouver des suggestions dans des documents, rechercher des informations historiques à partir de bons de travail, puis rassembler tout le contenu pour analyse. C'est ainsi que nous pensons à une combinaison de grands modèles et de graphiques de connaissances. Dans une architecture globale, le grand modèle effectue l'analyse finale et le graphe de connaissances aide le grand modèle à trouver plus rapidement et plus précisément les connaissances cachées derrière lui grâce à son système de représentation des connaissances.
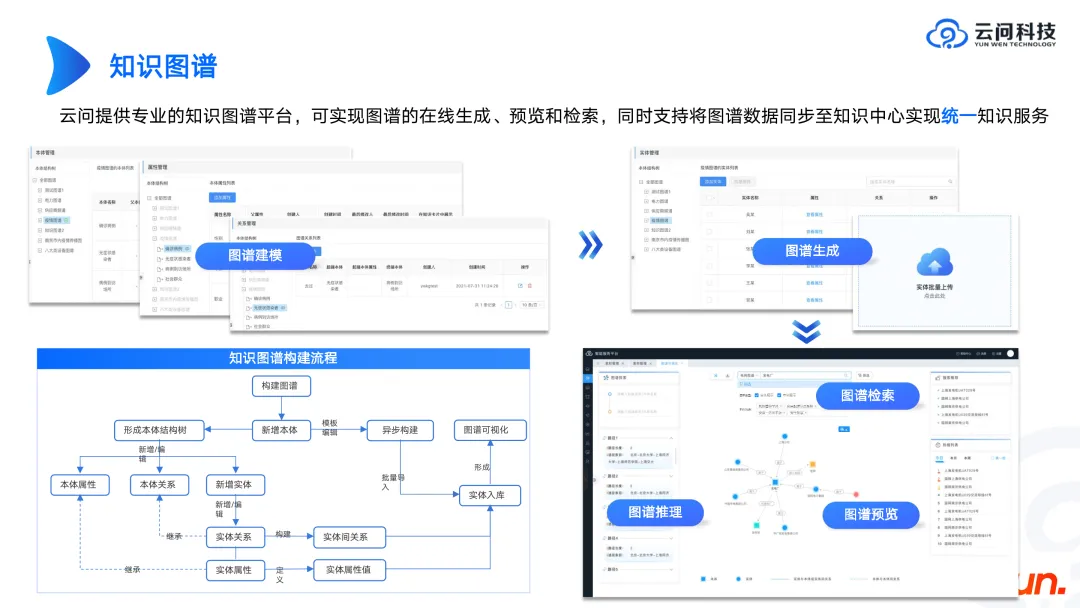
Nous avons déjà discuté de la relation entre le grand modèle et la carte. Voyons ensuite ce dont la carte elle-même a besoin.
Tout d'abord, derrière le graphique se trouve une base de données graphique, telle que l'open source Neo4j, Genius Graph et certaines marques de bases de données nationales. Le graphique de connaissances et la base de données graphique sont deux concepts différents. Créer un produit graphique de connaissances équivaut à encapsuler la couche supérieure de la base de données graphique pour obtenir une modélisation et une visualisation graphiques rapides.
Lorsque vous souhaitez créer un produit de graphe de connaissances, vous pouvez d'abord vous référer à la forme de produit de Neo4j ou aux produits de graphe de connaissances de certains grands fabricants nationaux, afin que vous puissiez comprendre approximativement de quelles fonctions et liens le produit de graphe de connaissances a besoin implémenter. Le plus important est de savoir comment construire un graphe de connaissances. Cela semble être un problème commercial, car différentes entreprises et différents scénarios ont des graphiques différents. En tant que technicien, si vous ne comprenez pas l'électricité, les équipements, l'industrie, etc., il est impossible de construire une cartographie qui satisfasse l'entreprise. Cela nécessite une communication continue avec l’entreprise et des itérations continues pour finalement obtenir un résultat. Le processus de discussion peut en fait revenir à l'essence du schéma et présenter un ensemble de théories ontologiques et de concepts logiques du schéma. Ces contenus sont très importants. Une fois le schéma finalisé, du personnel plus compétent peut être impliqué pour enrichir le contenu et améliorer davantage le produit. Voici quelques-unes de nos expériences jusqu’à présent.

Ce qui suit est une introduction aux caractéristiques globales de la carte. À l’heure actuelle, les graphes de connaissances sont encore principalement basés sur des triplets, sur lesquels sont construites des relations sémantiques multi-granularités et multi-niveaux telles que des entités, des attributs et des relations. Dans le monde industriel, nous rencontrons souvent des problèmes qui ne peuvent pas être résolus par des triplets. De nombreux problèmes surgiront lorsque nous utiliserons des valeurs d'attributs d'entité définies pour décrire le monde physique réel. A ce moment, nous implémenterons les conditions contraintes sous forme de CVT. Par conséquent, lors de la construction d’un graphe de connaissances, chacun doit d’abord démontrer que les triplets peuvent résoudre le problème actuel.
Une chose qui doit être soulignée est que lors de la construction d'une carte, elle doit être construite selon les besoins, car le monde est infini et le contenu des connaissances qu'il contient est également infini. Au début, nous avons souvent l’idée de représenter toutes les entités qui existent dans le monde physique dans notre monde informatique. Le problème est que l’ensemble du schéma construit en fin de compte est trop complexe et n’est pas utile pour les affaires réelles. Par exemple, le fait que la terre tourne autour du soleil, je peux le construire en triple. Mais ce triplet ne peut pas résoudre le problème auquel je suis confronté actuellement, je dois donc construire le triplet selon mes besoins.
Alors comment aborder les questions de bon sens ? De nombreuses questions nécessitent des triples de bon sens. Nous pensons que cela peut être laissé aux grands modèles. Nous espérons également que le graphique des connaissances pourra explorer le professionnalisme et intégrer des connaissances véritablement pertinentes dans le graphique. Ensuite, le grand modèle peut être basé sur le bon sens et combiné avec des connaissances préalables fournies par le graphe de connaissances qui ne peuvent pas être obtenues en champ ouvert pour obtenir de meilleurs résultats.

La construction du graphe de connaissances nécessite que le personnel commercial et le personnel opérationnel conçoivent conjointement, y compris la définition de l'ontologie, des relations, des attributs et des entités, et comment les visualiser. En fin de compte, cela impliquera la question de savoir quel contenu présenter aux utilisateurs en termes de forme de produit. Si l'utilisateur est le consommateur final, seules la recherche visuelle et les questions-réponses doivent être présentées. Car ce type de client ne se soucie pas de la manière dont la carte est construite, qu'elle soit automatisée ou manuelle.
Un autre problème très important est impliqué ici, c'est-à-dire que même dans les scénarios de grands modèles, toutes les cartes ne peuvent pas être construites automatiquement. Le coût de construction d’un graphique est très élevé. Au lieu de dépenser beaucoup d’énergie en modélisation graphique, nous devrions consacrer notre énergie à la consommation. Si vous souhaitez obtenir l’acceptation des entreprises, vous devrez peut-être recourir à une construction manuelle. Par exemple, si un tableau avec un certain format est complexe entre les tableaux, nous pouvons essayer de trouver une référence à l'aide d'un grand modèle. Cela déplace l’énergie de la construction vers la consommation. Par exemple, si un cycle de projet dure 100 jours, nous passons 70 jours à construire la carte et passons les 30 derniers jours à réfléchir aux scénarios d'application de cette carte. Ou encore, parce que le temps de construction initial est prolongé, nous n'avons pas le temps de réfléchir. sur des scénarios de consommation précieux, qui peuvent conduire à de grandes questions. D'après notre expérience, vous devriez consacrer un peu de temps à la construction, ou passer par défaut à la construction manuelle. Passez ensuite beaucoup de temps à réfléchir à la manière de maximiser la valeur de la carte construite.

L'image ci-dessus montre le processus de création d'un graphe de connaissances. Lors de la construction de l’ontologie, nous devons accepter que l’ontologie change, tout comme la structure des tables de la base de données elle-même peut également être mise à jour. Par conséquent, lors de la conception, veillez à prendre en compte sa robustesse et son évolutivité. Par exemple, lorsque nous dressons une carte d’un certain type d’équipement, nous devons considérer l’ensemble du système d’équipement. À l'avenir, vous devrez peut-être rechercher des appareils via ce système, et vous devez également comprendre que d'autres appareils sous ce système n'ont pas encore créé de cartes, qui pourront être créées à l'avenir. Apporter une plus grande valeur aux utilisateurs à travers l’ensemble du grand système.
Une question que l'on entend souvent est la suivante : je peux trouver la réponse via la FAQ ou le grand modèle, pourquoi devrais-je utiliser la carte ? Notre réponse est que si nous associons les connaissances actuelles à la carte, le monde que nous voyons n'est plus unidimensionnel, mais un monde en réseau. C'est une valeur que la carte peut réaliser du côté du consommateur, et qui est difficile à réaliser. avec d'autres technologies. À l'heure actuelle, tout le monde se concentre souvent sur l'ampleur et les algorithmes avancés utilisés, mais en fait, nous devrions penser la construction du graphique du point de vue de la consommation et de la résolution de problèmes.

Maintenant que les grands modèles sont répandus, nous devons envisager la combinaison de grands modèles et de graphiques. On peut considérer que le graphique est l’application de couche supérieure, tandis que le grand modèle est la capacité sous-jacente. Nous pouvons comprendre quelle aide le grand modèle apporte à la carte à partir de différents scénarios.
Lors de la construction du graphique, l'extraction d'informations peut être effectuée à travers certains documents et mots d'invite pour remplacer l'UIE, le NER et d'autres technologies associées d'origine, améliorant ainsi encore la capacité d'extraction. Nous devrions également nous demander si un grand modèle ou un petit modèle est préférable dans le cas d'un entraînement à zéro tir, à quelques tirs et à données suffisantes. Il n’existe pas de réponse unique à ce type de question, et il existe différentes solutions pour différents scénarios et différents ensembles de données. Il s’agit d’une toute nouvelle voie de construction des connaissances. À l’heure actuelle, dans les scénarios zéro tir, les grands modèles ont de meilleures capacités d’extraction. Cependant, une fois que la taille de l’échantillon augmente, le petit modèle présente davantage d’avantages en termes de rapport coût/performance et de vitesse d’inférence.
Du côté des consommateurs, les graphiques sont utilisés pour résoudre des problèmes de raisonnement, tels que des jugements politiques, comme juger si une entreprise peut respecter une certaine politique et si elle peut bénéficier des avantages mentionnés dans la politique. L’approche précédente consistait à porter des jugements à l’aide de graphiques, de règles et d’expressions d’énoncés. L'approche actuelle est similaire à Graph RAG, qui utilise les questions des utilisateurs pour trouver des triples ou des multituples similaires à l'entreprise actuelle, et utilise de grands modèles pour obtenir des réponses et tirer des conclusions. Par conséquent, de nombreux problèmes de raisonnement graphique et de construction de graphiques peuvent être résolus grâce à la technologie des grands modèles.
En termes de stockage de graphiques, la structure des données de la base de données de graphiques et le graphique lui-même sont très importants. Les grands modèles ne peuvent pas gérer de texte long ou l'intégralité du graphique à court terme, le stockage de graphiques est donc une direction très importante. Tout comme la base de données vectorielles, elle deviendra un élément très important du futur écosystème de grands modèles. L'application de couche supérieure décidera si elle doit utiliser ce composant pour résoudre le problème réel.

La visualisation graphique est un problème frontal et doit être conçue en fonction du scénario et du problème à résoudre. Nous espérons également que la technologie pourra être utilisée comme plate-forme intermédiaire pour fournir certaines capacités permettant de répondre à différentes formes d'interaction à l'avenir, telles que les terminaux mobiles, les PC, les appareils portables, etc. Il nous suffit de fournir une structure, et la manière dont le rendu et la présentation du front-end peut être déterminée en fonction des besoins réels. Les grands modèles seraient également un moyen d’invoquer de telles structures. Lorsque le grand modèle ou l'agent peut déterminer comment appeler le graphique en fonction des exigences, la boucle fermée peut être ouverte. Graph doit être capable d'encapsuler de meilleures API pour s'adapter aux appels de diverses applications à l'avenir. Le concept de plateforme intermédiaire est progressivement pris au sérieux. Un service indépendant et découplé peut être plus largement utilisé par toutes les parties.
Par exemple, vous avez parfois besoin de trouver une certaine valeur laissée dans un tableau d'un document. Il est difficile de localiser son emplacement via la recherche ou la technologie des grands modèles si vous utilisez les capacités structurelles du graphique pour présenter le contenu. , vous pouvez obtenir la valeur de cette carte en appelant une interface dans le système applicatif, et présenter le document où elle se trouve, ou les résultats d'analyse du grand modèle. Cette méthode de visualisation est la plus efficace pour les utilisateurs. Il s'agit également de la méthode Copilot actuellement populaire, qui consiste à résoudre conjointement des problèmes en appelant des capacités de carte, de recherche ou d'autres applications, et enfin à utiliser de grands modèles pour générer le « dernier kilomètre » afin d'améliorer l'efficacité.

Maintenant, nous faisons souvent diverses intégrations de bases de connaissances et de graphiques. De nombreux projets de connaissances émergent cette année. Auparavant, les connaissances étaient principalement disponibles pour la recherche et la consommation. Avec l’émergence des grands modèles, tout le monde a découvert que les connaissances peuvent également être fournies aux grands modèles pour être consommées. Ainsi, chacun accorde davantage d’attention à l’apport et à la construction des connaissances. Nous avons nous-mêmes beaucoup de connaissances, et nous avons également besoin d'un système de graphe de connaissances tiers car nos connaissances ne sont pas structurées, et il y aura beaucoup de connaissances très importantes, telles que les bons de travail, les cas de maintenance des équipements, etc., et nous besoin de transférer ces connaissances vers Le contenu structuré est stocké. Ce contenu était auparavant utilisé pour la recherche, mais il peut désormais être utilisé pour SFT sur de grands modèles.
La base de connaissances et le graphique sont naturellement combinables. Lorsqu'ils sont combinés, un ensemble de produits de services de connaissances peut être fourni au monde extérieur. La vitalité de ce produit de services de connaissances est très forte et il y aura une demande de connaissances que ce soit dans les systèmes OA, ERP, MIS ou PRM.
Lors de l'intégration, vous devez accorder une grande attention à la manière de distinguer les connaissances et les données. Les clients fournissent de grandes quantités de données, mais ces données ne constituent peut-être pas des connaissances. Nous devons définir les connaissances du côté de la demande. Par exemple, pour un équipement, ce que nous avons généralement besoin de savoir, comme les fluctuations des données lorsque l'équipement fonctionne, sont toutes des données, et l'heure d'usine de l'équipement, l'heure de la dernière maintenance, etc., sont des connaissances. La manière de définir les connaissances est très importante et doit être construite conjointement avec la participation et les conseils de l'entreprise.
3. Industrial Graph Advanced

Dans le processus de transformation numérique, l'IA et les technologies graphiques seront utilisées dans des scénarios tels que la planification, l'équipement, le marketing et l'analyse. Surtout dans le scénario de répartition, qu'il s'agisse de répartition du trafic, de répartition de l'énergie ou de répartition de la main-d'œuvre, tout s'effectue sous forme de répartition des tâches. Par exemple, en cas d'incendie, combien de personnes, de véhicules, etc. doivent être envoyés. Certaines données pertinentes doivent être interrogées lors de la planification. Le problème actuel n'est souvent pas qu'aucun résultat ne peut être trouvé, mais qu'il y a trop de contenu. est renvoyé, mais aucune information vraiment utile ne peut être donnée. Parce que la consommation de connaissances reste toujours dans la recherche par mots clés, tous les documents contenant le mot « feu » seront affichés. Pour une meilleure présentation, vous pouvez utiliser le graphique. Par exemple, lors de la conception de l'ontologie du « feu », son ontologie supérieure est un désastre. Pour l'entité du « feu », vous pouvez concevoir ses précautions, ses mesures de protection et ses cas d'expérience. Divisez les connaissances à travers ces contenus. De cette façon, lorsque l'utilisateur entre dans « feu », un contexte cartographique pertinent et ce qui doit être fait ensuite seront présentés.
Dans les scénarios liés à la planification, vous devez faire attention à la direction de l'agent. L'agent est très important pour la planification, car la planification elle-même est un scénario multitâche. Les résultats renvoyés par la carte seront plus précis et plus riches.
Il existe également de nombreux scénarios d'application pour les appareils intelligents. Les informations sur l'équipement seront stockées dans différents systèmes. Par exemple, les informations d'usine sont stockées dans les manuels des produits, les informations de maintenance sont stockées dans les bons de travail de maintenance, l'état de fonctionnement est stocké dans le système de gestion de l'équipement et l'état d'inspection est stocké dans le système d'inspection industrielle. . L’un des principaux problèmes auxquels est confrontée l’industrie est qu’il existe trop de systèmes. Si vous souhaitez interroger les informations d'un appareil, vous devez l'interroger à partir de plusieurs systèmes, et les données de ces systèmes ne sont pas connectées les unes aux autres. À l’heure actuelle, il faut un système capable d’ouvrir la connexion, d’associer et de cartographier tout le contenu. Une base de connaissances avec un graphe de connaissances comme noyau peut résoudre ce problème.
Le graphe de connaissances peut inclure ses attributs, champs, sources de champs, etc. associés via une ontologie, et peut décrire et associer les relations séries et parallèles entre divers systèmes à partir du bas. Mais lors de la création de votre graphique, gardez à l’esprit que vous devez concevoir et construire votre graphique en conséquence. Lorsque de nombreuses entreprises créent une carte, elles transfèrent toutes les données du centre de données via la technologie D2R. Cette carte n'a en réalité aucune signification. Lors de la création d'une carte, vous devez tenir compte de la relation entre la carte dynamique et la carte statique.
Il existe également de nombreux scénarios d'application et techniques de conception dans le domaine du marketing intelligent et de l'IA énergétique multi-scénarios, qui ne seront pas abordés ici et pourront l'être plus tard.

Lors de la construction d'un graphique, la conception architecturale est très importante. Comment intégrer des bibliothèques et des processus sous-jacents à la construction et à la consommation de graphiques. Il y a beaucoup de détails à prendre en compte dans la manière dont vous le livrerez en fin de compte. Vous pouvez vous référer aux liens répertoriés dans la figure ci-dessus pour la conception et la pratique.
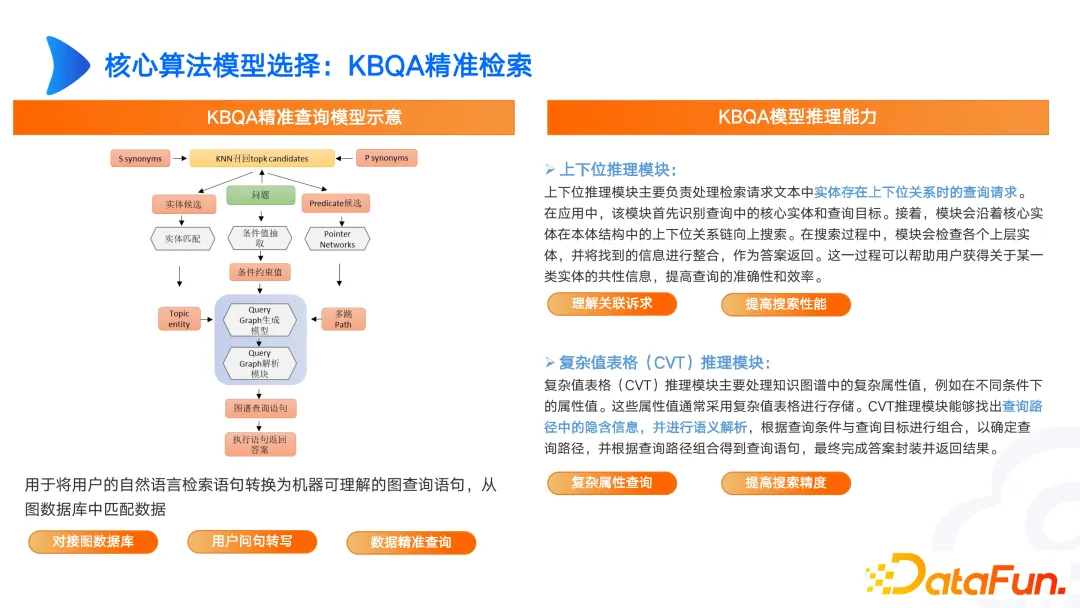
Nous avons également effectué des recherches sur le graphique KBQA, telles que les bits supérieurs et inférieurs, la requête graphique CVT, etc. Par exemple, dans les scénarios médicaux, la fièvre et les maux de tête sont associés à des représentations corporelles anormales. La fièvre ou les maux de tête ne sont pas stockés séparément dans la base de connaissances, ils sont stockés comme des anomalies physiques mineures. Lorsqu’il existe des différences entre les représentations des utilisateurs et les représentations professionnelles, nous pouvons les résoudre grâce au raisonnement supérieur et inférieur CVT.
Le graphique actuellement construit ne peut être qu'un alignement d'entités tel que SPO ou multi-sauts ou TransE. Cependant, dans des scénarios complexes, la CVT doit être mise en œuvre en combinaison avec des positions supérieures et inférieures. Il existe également de nombreux articles qui fonctionnent très bien sur les ensembles de données anglais, mais les résultats sur les ensembles de données chinois ne sont pas idéaux. Par conséquent, nous devons concevoir en fonction de nos propres besoins et itérer continuellement pour obtenir de bons résultats.
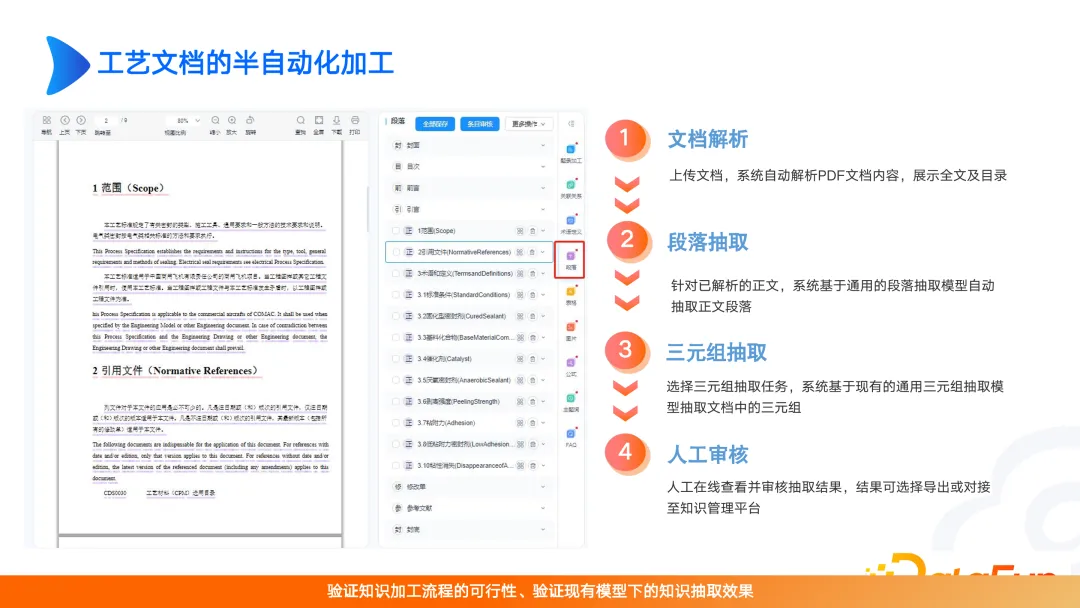
Traitement de documents semi-automatisé, y compris l'analyse des documents, l'extraction de paragraphes, la triple extraction et la révision manuelle. Cette étape de révision manuelle est souvent ignorée, surtout après l'arrivée des grands modèles, les gens accordent moins d'attention à la révision manuelle. En fait, si le traitement et la gouvernance des données sont effectués, l'effet du modèle sera grandement amélioré. Par conséquent, nous devons considérer que le scénario que nous voulons finalement résoudre doit avoir une grande valeur, et nous devons également faire attention à l'endroit où les ressources sont investies, que ce soit dans la construction de la carte ou dans l'optimisation de grands modèles. Sans ces considérations, le produit sera facilement remplacé ou remis en question.

L'image ci-dessus montre un produit de gestion du cycle de vie des appareils de Yunwen Technology. De tels scénarios sont réalisés grâce à des modules intermédiaires légers et à la construction d'applications de couche supérieure dans différents scénarios. La vitalité de ces modules est bien plus vigoureuse que la vitalité du système de graphe de connaissances lui-même. La vente de logiciels autonomes ou uniquement middleware n'est pas adaptée dans le domaine des graphiques, en particulier dans les scénarios industriels. De nombreux problèmes industriels sont très complexes du point de vue du client et ne peuvent être résolus par des schémas ou de grands modèles. Ce que nous devons faire, c'est convaincre les clients de l'effet.

Dans le processus de transformation industrielle intelligente, il existe de nombreux points d'application dans la R&D et la conception, la gestion de la production, la gestion des approvisionnements, le marketing avant-vente et les services complets.

L'image ci-dessus est un exemple de scénario d'application d'une carte d'équipement défectueux. Dans ce scénario, nous n'avons pas inclus tous les éléments du graphique, tels que l'état de fonctionnement de l'équipement et les données simples dans une base de données relationnelle. Nous pensons que pour la maintenance des équipements, nous nous concentrons principalement sur trois types de données. Le premier type est les informations de base de l'équipement, telles que l'heure de sortie de l'usine, le fabricant et la durée de son fonctionnement. le type correspond aux défauts, tels que le nom de la faute, supérieur et subordonné, ces défauts, quels défauts provoqueront, quels types de défauts provoqueront quel type de défauts, etc.; la troisième catégorie concerne les ordres de travail, qui décrivent les défauts survenus sur quel matériel. En connectant ces trois types de données, nous pouvons construire un petit graphique en boucle fermée. À l’avenir, il pourra également être étendu sur la base de données dynamiques. Par conséquent, lors de la création d’un graphique, nous préférons créer un petit et beau graphique avec une scène en boucle fermée. Il ne s'agit pas d'une carte qui recherche uniquement des produits haut de gamme, mais qui ne peut pas répondre aux besoins des consommateurs.
Par conséquent, lors de la création d'un graphe de connaissances industrielles, vous devez partir de scénarios spécifiques et construire le graphe en analysant les exigences de la scène, afin d'obtenir une meilleure mise en œuvre et application.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 Découverte du framework d'inférence de grands modèles NVIDIA : TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Découverte du framework d'inférence de grands modèles NVIDIA : TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Positionnement du produit TensorRT-LLM TensorRT-LLM est une solution d'inférence évolutive développée par NVIDIA pour les grands modèles de langage (LLM). Il crée, compile et exécute des graphiques de calcul basés sur le cadre de compilation d'apprentissage en profondeur TensorRT et s'appuie sur l'implémentation efficace des noyaux dans FastTransformer. De plus, il utilise NCCL pour la communication entre les appareils. Les développeurs peuvent personnaliser les opérateurs pour répondre à des besoins spécifiques en fonction du développement technologique et des différences de demande, comme le développement de GEMM personnalisés basés sur le coutelas. TensorRT-LLM est la solution d'inférence officielle de NVIDIA, engagée à fournir des performances élevées et à améliorer continuellement sa praticité. TensorRT-LL
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Référence GPT-4 ! Le grand modèle Jiutian de China Mobile a passé le double enregistrement
Apr 04, 2024 am 09:31 AM
Référence GPT-4 ! Le grand modèle Jiutian de China Mobile a passé le double enregistrement
Apr 04, 2024 am 09:31 AM
Selon des informations du 4 avril, l'Administration du cyberespace de Chine a récemment publié une liste de grands modèles enregistrés, et le « Grand modèle d'interaction du langage naturel Jiutian » de China Mobile y a été inclus, indiquant que le grand modèle Jiutian AI de China Mobile peut officiellement fournir des informations artificielles génératives. services de renseignement vers le monde extérieur. China Mobile a déclaré qu'il s'agit du premier modèle à grande échelle développé par une entreprise centrale à avoir réussi à la fois le double enregistrement national « Enregistrement du service d'intelligence artificielle générative » et le double enregistrement « Enregistrement de l'algorithme de service de synthèse profonde domestique ». Selon les rapports, le grand modèle d'interaction en langage naturel de Jiutian présente les caractéristiques de capacités, de sécurité et de crédibilité améliorées de l'industrie, et prend en charge la localisation complète. Il a formé plusieurs versions de paramètres telles que 9 milliards, 13,9 milliards, 57 milliards et 100 milliards. et peut être déployé de manière flexible dans le Cloud, la périphérie et la fin sont des situations différentes
 GPT Store ne peut même pas ouvrir ses portes. Comment cette plateforme nationale ose-t-elle emprunter cette voie ? ?
Apr 19, 2024 pm 09:30 PM
GPT Store ne peut même pas ouvrir ses portes. Comment cette plateforme nationale ose-t-elle emprunter cette voie ? ?
Apr 19, 2024 pm 09:30 PM
Attention, cet homme a connecté plus de 1 000 grands modèles, vous permettant de vous brancher et de switcher en toute transparence. Récemment, un flux de travail d'IA visuelle a été lancé : vous offrant une interface intuitive de type glisser-déposer, vous pouvez glisser, tirer et faire glisser pour organiser votre propre flux de travail sur un canevas infini. Comme le dit le proverbe, la guerre coûte cher, et Qubit a appris que dans les 48 heures suivant la mise en ligne de cet AIWorkflow, les utilisateurs avaient déjà configuré des flux de travail personnels avec plus de 100 nœuds. Sans plus tarder, je veux parler aujourd'hui de Dify, une société LLMOps, et de son PDG Zhang Luyu. Zhang Luyu est également le fondateur de Dify. Avant de rejoindre l'entreprise, il avait 11 ans d'expérience dans l'industrie Internet. Je suis engagé dans la conception de produits, je comprends la gestion de projet et j'ai des connaissances uniques sur le SaaS. Plus tard, il
 Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné
Apr 23, 2024 pm 12:13 PM
Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné
Apr 23, 2024 pm 12:13 PM
Si les questions du test sont trop simples, les meilleurs étudiants et les mauvais étudiants peuvent obtenir 90 points, et l'écart ne peut pas être creusé... Avec la sortie plus tard de modèles plus puissants tels que Claude3, Llama3 et même GPT-5, l'industrie est en besoin urgent d'un modèle de référence plus difficile et différencié. LMSYS, l'organisation à l'origine du grand modèle Arena, a lancé la référence de nouvelle génération, Arena-Hard, qui a attiré une large attention. Il existe également la dernière référence pour la force des deux versions affinées des instructions Llama3. Par rapport à MTBench, qui avait des scores similaires auparavant, la discrimination Arena-Hard est passée de 22,6 % à 87,4 %, ce qui est plus fort et plus faible en un coup d'œil. Arena-Hard est construit à partir de données humaines en temps réel provenant de l'arène et a un taux de cohérence de 89,1 % avec les préférences humaines.
 Grâce à la technologie Shengteng AI, le modèle de transport Qinling·Qinchuan aide Xi'an à construire un centre d'innovation en matière de transport intelligent
Oct 15, 2023 am 08:17 AM
Grâce à la technologie Shengteng AI, le modèle de transport Qinling·Qinchuan aide Xi'an à construire un centre d'innovation en matière de transport intelligent
Oct 15, 2023 am 08:17 AM
« Une complexité élevée, une fragmentation élevée et des domaines interdomaines » ont toujours été les principaux problèmes sur la voie de la mise à niveau numérique et intelligente du secteur des transports. Récemment, le « modèle de trafic Qinling·Qinchuan » avec une échelle de paramètres de 100 milliards, construit conjointement par China Science Vision, le gouvernement du district de Xi'an Yanta et le centre informatique d'intelligence artificielle du futur de Xi'an, est orienté vers le domaine des transports intelligents. et fournit des services à Xi'an et ses environs. La région créera un pivot pour l'innovation en matière de transport intelligent. Le « modèle de trafic Qinling·Qinchuan » combine les données écologiques massives du trafic local de Xi'an dans des scénarios ouverts, l'algorithme avancé original développé indépendamment par China Science Vision et la puissante puissance de calcul de l'IA Shengteng du futur centre informatique d'intelligence artificielle de Xi'an pour fournir la surveillance du réseau routier, les scénarios de transport intelligents tels que la commande d'urgence, la gestion de la maintenance et les déplacements publics entraînent des changements numériques et intelligents. La gestion du trafic présente des caractéristiques différentes selon les villes, et le trafic sur différentes routes
