
 Périphériques technologiques
IA
Nouveau travail de l'équipe d'Andrew Ng : apprentissage contextuel multimodal et multi-échantillons, s'adaptant rapidement à de nouvelles tâches sans réglage fin.
Périphériques technologiques
IA
Nouveau travail de l'équipe d'Andrew Ng : apprentissage contextuel multimodal et multi-échantillons, s'adaptant rapidement à de nouvelles tâches sans réglage fin.
Nouveau travail de l'équipe d'Andrew Ng : apprentissage contextuel multimodal et multi-échantillons, s'adaptant rapidement à de nouvelles tâches sans réglage fin.


La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com

Adresse papier : https://arxiv.org/abs/2405.09798 Adresse code : https://github.com/stanfordmlgroup/ManyICL

En termes d'ensembles de données, l'équipe de recherche a mené des expériences sur 10 ensembles de données couvrant différents domaines (y compris l'imagerie naturelle, l'imagerie médicale, l'imagerie de télédétection et l'imagerie moléculaire, etc.) et des tâches (y compris la classification multi-étiquettes, la classification multi-étiquettes). et classification à grain fin) Expérimentation approfondie.
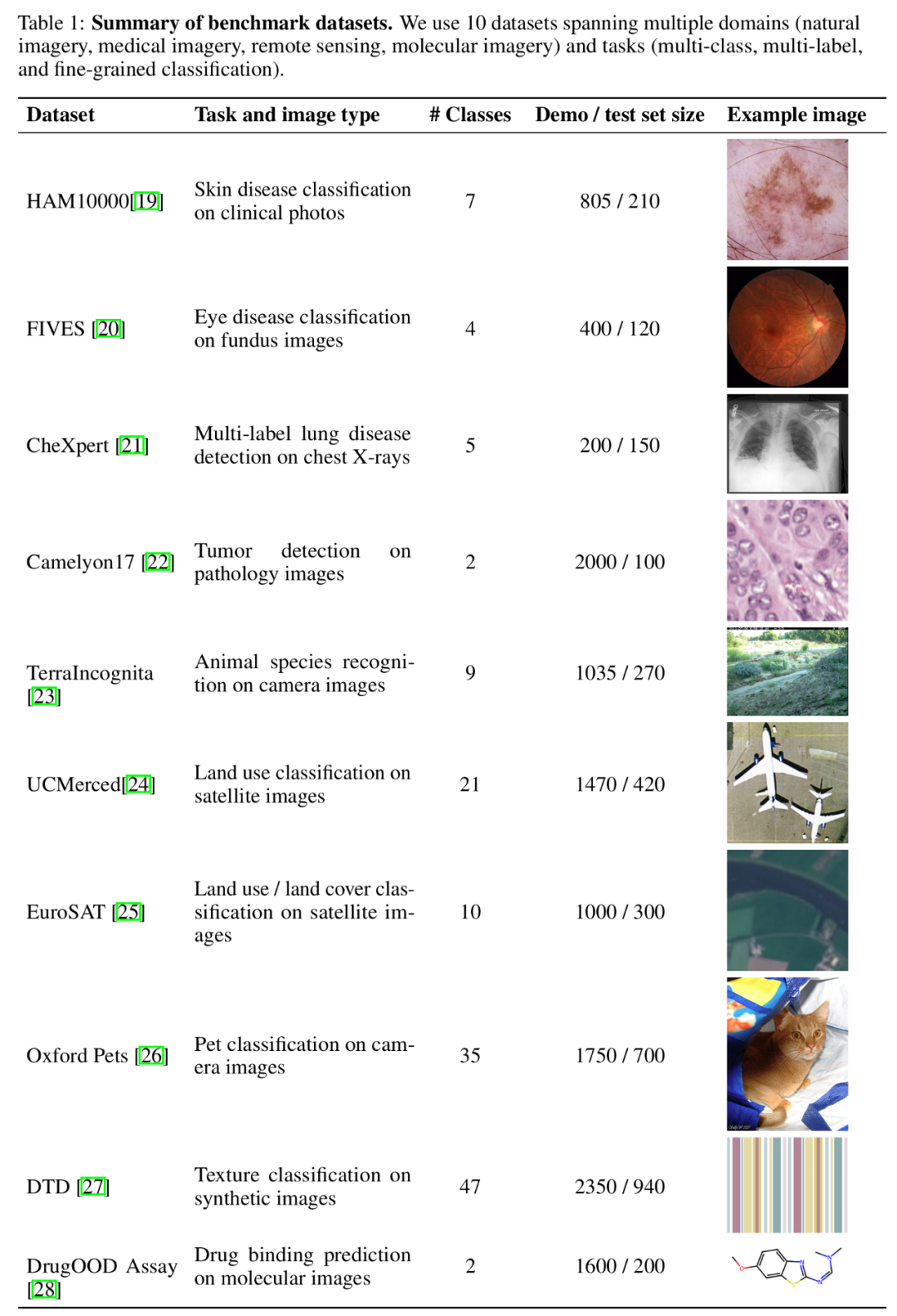
Résumé de l'ensemble de données de référence.
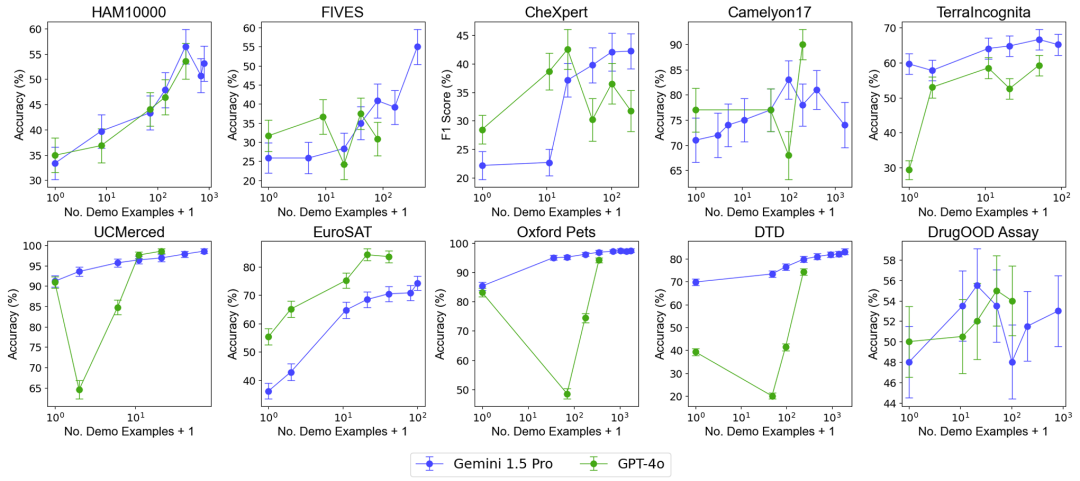
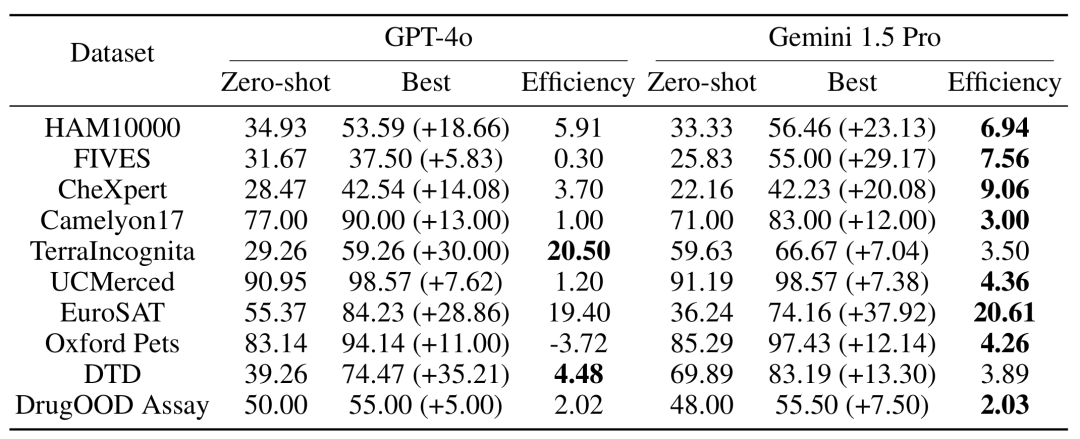
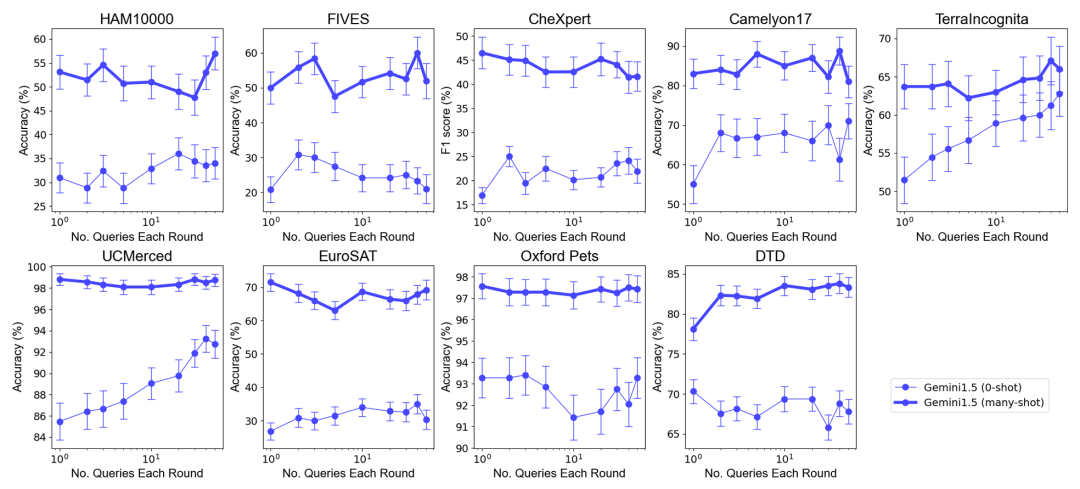
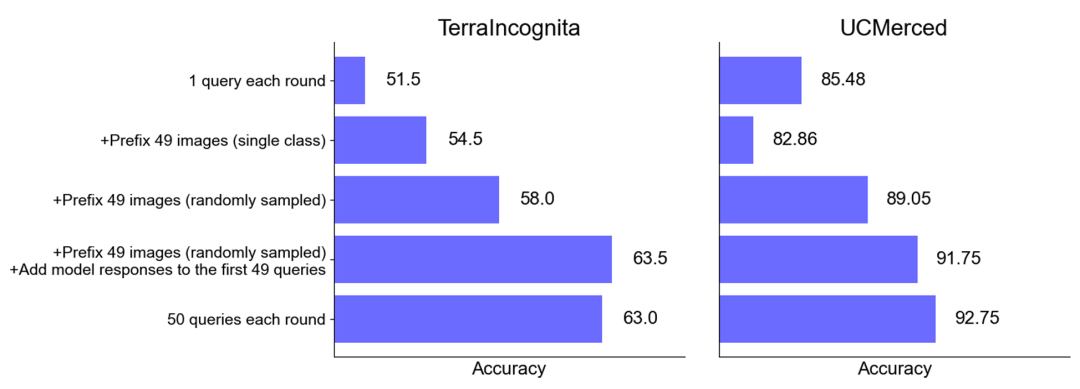 Conclusion
Conclusion
Deuxièmement, le traitement par lots des requêtes peut réduire le coût d'inférence et la latence tout en obtenant des performances de modèle similaires, voire meilleures, montrant un grand potentiel dans les applications pratiques. 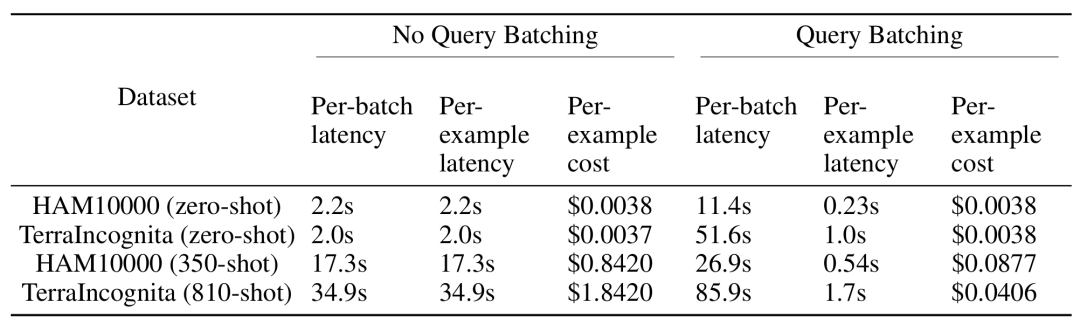
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Kimi : En une seule phrase, un PPT est prêt en seulement dix secondes. PPT est tellement ennuyeux ! Pour tenir une réunion, vous devez avoir un PPT ; pour rédiger un rapport hebdomadaire, vous devez avoir un PPT ; pour solliciter des investissements, vous devez présenter un PPT ; même pour accuser quelqu'un de tricherie, vous devez envoyer un PPT ; L'université ressemble plus à une spécialisation PPT. Vous regardez le PPT en classe et faites le PPT après les cours. Peut-être que lorsque Dennis Austin a inventé le PPT il y a 37 ans, il ne s'attendait pas à ce qu'un jour le PPT devienne aussi répandu. Parler de notre dure expérience de création de PPT nous fait monter les larmes aux yeux. "Il m'a fallu trois mois pour réaliser un PPT de plus de 20 pages, et je l'ai révisé des dizaines de fois. J'avais envie de vomir quand j'ai vu le PPT." "À mon apogée, je faisais cinq PPT par jour, et même ma respiration." était PPT." Si vous avez une réunion impromptue, vous devriez le faire
 Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
La diffusion permet non seulement de mieux imiter, mais aussi de « créer ». Le modèle de diffusion (DiffusionModel) est un modèle de génération d'images. Par rapport aux algorithmes bien connus tels que GAN et VAE dans le domaine de l’IA, le modèle de diffusion adopte une approche différente. Son idée principale est un processus consistant à ajouter d’abord du bruit à l’image, puis à la débruiter progressivement. Comment débruiter et restaurer l’image originale est la partie centrale de l’algorithme. L'algorithme final est capable de générer une image à partir d'une image bruitée aléatoirement. Ces dernières années, la croissance phénoménale de l’IA générative a permis de nombreuses applications passionnantes dans la génération de texte en image, la génération de vidéos, et bien plus encore. Le principe de base de ces outils génératifs est le concept de diffusion, un mécanisme d'échantillonnage spécial qui surmonte les limites des méthodes précédentes.
 Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tôt le matin du 20 juin, heure de Pékin, CVPR2024, la plus grande conférence internationale sur la vision par ordinateur qui s'est tenue à Seattle, a officiellement annoncé le meilleur article et d'autres récompenses. Cette année, un total de 10 articles ont remporté des prix, dont 2 meilleurs articles et 2 meilleurs articles étudiants. De plus, il y a eu 2 nominations pour les meilleurs articles et 4 nominations pour les meilleurs articles étudiants. La conférence la plus importante dans le domaine de la vision par ordinateur (CV) est la CVPR, qui attire chaque année un grand nombre d'instituts de recherche et d'universités. Selon les statistiques, un total de 11 532 articles ont été soumis cette année, dont 2 719 ont été acceptés, avec un taux d'acceptation de 23,6 %. Selon l'analyse statistique des données CVPR2024 du Georgia Institute of Technology, du point de vue des sujets de recherche, le plus grand nombre d'articles est la synthèse et la génération d'images et de vidéos (Imageandvideosyn
 Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Nous savons que le LLM est formé sur des clusters informatiques à grande échelle utilisant des données massives. Ce site a présenté de nombreuses méthodes et technologies utilisées pour aider et améliorer le processus de formation LLM. Aujourd'hui, ce que nous souhaitons partager est un article qui approfondit la technologie sous-jacente et présente comment transformer un ensemble de « bare metals » sans même un système d'exploitation en un cluster informatique pour la formation LLM. Cet article provient d'Imbue, une startup d'IA qui s'efforce d'atteindre une intelligence générale en comprenant comment les machines pensent. Bien sûr, transformer un tas de « bare metal » sans système d'exploitation en un cluster informatique pour la formation LLM n'est pas un processus facile, plein d'exploration et d'essais et d'erreurs, mais Imbue a finalement réussi à former un LLM avec 70 milliards de paramètres et dans. le processus s'accumule
 Guide d'installation de PyCharm Community Edition : maîtrisez rapidement toutes les étapes
Jan 27, 2024 am 09:10 AM
Guide d'installation de PyCharm Community Edition : maîtrisez rapidement toutes les étapes
Jan 27, 2024 am 09:10 AM
Démarrage rapide avec PyCharm Community Edition : Tutoriel d'installation détaillé Analyse complète Introduction : PyCharm est un puissant environnement de développement intégré (IDE) Python qui fournit un ensemble complet d'outils pour aider les développeurs à écrire du code Python plus efficacement. Cet article présentera en détail comment installer PyCharm Community Edition et fournira des exemples de code spécifiques pour aider les débutants à démarrer rapidement. Étape 1 : Téléchargez et installez PyCharm Community Edition Pour utiliser PyCharm, vous devez d'abord le télécharger depuis son site officiel
 L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
Rédacteur du Machine Power Report : Yang Wen La vague d’intelligence artificielle représentée par les grands modèles et l’AIGC a discrètement changé notre façon de vivre et de travailler, mais la plupart des gens ne savent toujours pas comment l’utiliser. C'est pourquoi nous avons lancé la rubrique « AI in Use » pour présenter en détail comment utiliser l'IA à travers des cas d'utilisation de l'intelligence artificielle intuitifs, intéressants et concis et stimuler la réflexion de chacun. Nous invitons également les lecteurs à soumettre des cas d'utilisation innovants et pratiques. Lien vidéo : https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Récemment, le vlog de la vie d'une fille vivant seule est devenu populaire sur Xiaohongshu. Une animation de style illustration, associée à quelques mots de guérison, peut être facilement récupérée en quelques jours seulement.
 A lire absolument pour les débutants en technique : Analyse des niveaux de difficulté du langage C et Python
Mar 22, 2024 am 10:21 AM
A lire absolument pour les débutants en technique : Analyse des niveaux de difficulté du langage C et Python
Mar 22, 2024 am 10:21 AM
Titre : Une lecture incontournable pour les débutants en technique : Analyse des difficultés du langage C et de Python, nécessitant des exemples de code spécifiques. À l'ère numérique d'aujourd'hui, la technologie de programmation est devenue une capacité de plus en plus importante. Que vous souhaitiez travailler dans des domaines tels que le développement de logiciels, l'analyse de données, l'intelligence artificielle ou simplement apprendre la programmation par intérêt, choisir un langage de programmation adapté est la première étape. Parmi les nombreux langages de programmation, le langage C et Python sont deux langages de programmation largement utilisés, chacun ayant ses propres caractéristiques. Cet article analysera les niveaux de difficulté du langage C et Python
 Compte à rebours des 12 points faibles de RAG, l'architecte senior de NVIDIA enseigne les solutions
Jul 11, 2024 pm 01:53 PM
Compte à rebours des 12 points faibles de RAG, l'architecte senior de NVIDIA enseigne les solutions
Jul 11, 2024 pm 01:53 PM
La génération augmentée par récupération (RAG) est une technique qui utilise la récupération pour améliorer les modèles de langage. Plus précisément, avant qu'un modèle de langage ne génère une réponse, il récupère les informations pertinentes à partir d'une vaste base de données de documents, puis utilise ces informations pour guider le processus de génération. Cette technologie peut considérablement améliorer l'exactitude et la pertinence du contenu, atténuer efficacement le problème des hallucinations, augmenter la vitesse de mise à jour des connaissances et améliorer la traçabilité de la génération de contenu. RAG est sans aucun doute l’un des domaines de recherche les plus passionnants en matière d’intelligence artificielle. Pour plus de détails sur RAG, veuillez vous référer à l'article de la rubrique de ce site "Quelles sont les nouveautés de RAG, spécialisée dans le rattrapage des défauts des grands modèles ?" Cette revue l'explique clairement. Mais RAG n'est pas parfait et les utilisateurs rencontrent souvent des « problèmes » lorsqu'ils l'utilisent. Récemment, la solution avancée d'IA générative de NVIDIA
