La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Email de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
L'équipe de recherche du Laboratoire d'intelligence artificielle générative (GAIR Lab) de l'Université Jiao Tong de Shanghai, les principales orientations de recherche sont : la formation de grands modèles , alignement et évaluation. Page d'accueil de l'équipe : https://plms.ai/La technologie de l'IA évolue chaque jour qui passe Récemment, le dernier Claude-3.5-Sonnet publié par Anthropic Company a été largement utilisé dans le domaine de la connaissance. Le raisonnement basé sur le raisonnement mathématique, les tâches de programmation et le raisonnement visuel. L’établissement de nouvelles références industrielles sur d’autres tâches a suscité de nombreuses discussions : Claude-3.5-Sonnet a-t-il remplacé le GPT4o d’OpenAI en tant qu’« IA la plus intelligente » au monde ? Le défi pour répondre à cette question est que nous avons d'abord besoin d'un test de référence d'intelligence suffisamment exigeant qui nous permette de distinguer le niveau le plus élevé actuel de l'IA. L'OlympicArena[1] (Olympic Arena) lancée par le laboratoire d'intelligence artificielle générative de l'université Jiao Tong de Shanghai (GAIR Lab) répond à ce besoin.
Le Concours Olympique par Sujet n'est pas seulement un défi extrême pour l'agilité de la pensée humaine (intelligence basée sur le carbone), la maîtrise des connaissances et le raisonnement logique, c'est aussi un excellent terrain d'entraînement pour l'IA ("intelligence basée sur le silicium" ). Un étalon important pour mesurer la distance entre l’IA et la « super intelligence ». OlympicArena - une véritable arène olympique IA. Ici, l’IA doit non seulement démontrer sa profondeur dans les connaissances traditionnelles (compétitions de haut niveau telles que les mathématiques, la physique, la biologie, la chimie, la géographie, etc.), mais aussi rivaliser sur les capacités de raisonnement cognitif entre les modèles.
Récemment, la même équipe de recherche a proposé pour la première fois l'utilisation de la méthode "
Liste des médailles olympiques" pour classer chaque modèle d'IA en fonction de sa performance globale dans l'arène olympique (diverses disciplines) et sélectionner le meilleur jusqu'à présent L'IA la plus intelligente. Dans ce domaine, l'équipe de recherche s'est concentrée sur l'analyse et la comparaison de deux modèles avancés récemment publiés : Claude-3.5-Sonnet et Gemini-1.5-Pro, ainsi que la série GPT-4 d'OpenAI (par exemple, GPT4o). De cette manière, l’équipe de recherche espère évaluer et promouvoir plus efficacement le développement de la technologie de l’IA. 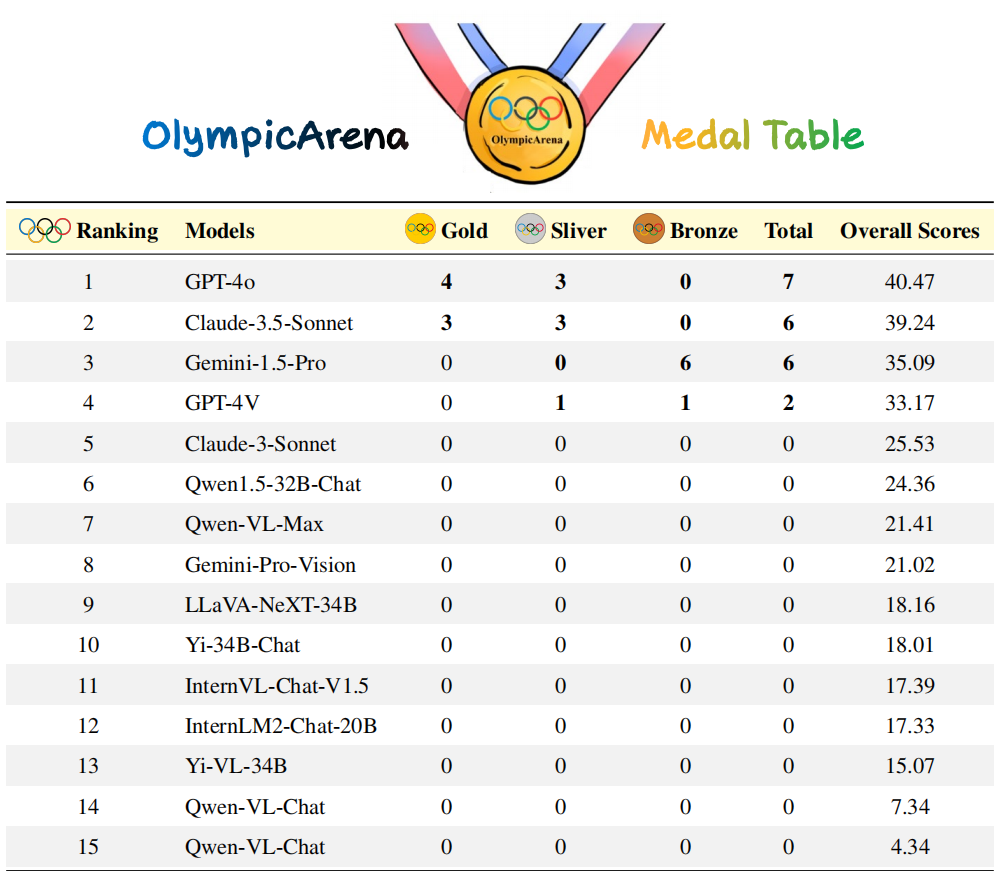
: L'équipe de recherche trie d'abord les modèles en fonction du nombre de médailles d'or. Si le nombre de médailles d'or est le même, les modèles sont triés en fonction de la note de performance globale. Les résultats expérimentaux montrent que : Claude-3.5-Sonnet est extrêmement compétitif avec GPT-4o en termes de performances globales, et surpasse même GPT-4o dans certaines matières (comme en physique, chimie et biologie). Gemini-1.5-Pro et GPT-4V se classent de près derrière GPT-4o et Claude-3.5-Sonnet, mais il existe un net écart de performances entre eux.
-
Les performances des modèles d'IA de la communauté open source sont clairement en retard par rapport à ces modèles propriétaires.
-
Les performances peu satisfaisantes de ces modèles sur ce benchmark montrent que nous avons encore un long chemin à parcourir sur la route de la superintelligence.
-
- Page d'accueil du projet : https://gair-nlp.github.io/OlympicArena/
L'équipe de recherche a pris l'ensemble de tests d'OlympicArena pour évaluation. Les réponses à cet ensemble de tests ne sont pas rendues publiques pour aider à prévenir les fuites de données et ainsi refléter les véritables performances du modèle. L’équipe de recherche a testé de grands modèles multimodaux (LMM) et de grands modèles textuels (LLM). Pour les tests des LLM, aucune information relative à l'image n'est fournie au modèle en entrée, uniquement du texte. Toutes les évaluations utilisent des mots d’invite de chaîne de pensée sans tir. L'équipe de recherche a évalué une série de grands modèles multimodaux (LMM) et de grands modèles textuels (LLM) open source et fermés. Pour les LMM, des modèles à source fermée tels que GPT-4o, GPT-4V, Claude-3-Sonnet, Gemini Pro Vision, Qwen-VL-Max, etc. ont été sélectionnés. De plus, LLaVA-NeXT-34B, InternVL-Chat. -V1.5 ont également été évalués, Yi-VL-34B et Qwen-VL-Chat et d'autres modèles open source. Pour les LLM, les modèles open source tels que Qwen-7B-Chat, Qwen1.5-32B-Chat, Yi-34B-Chat et InternLM2-Chat-20B ont été principalement évalués. De plus, l'équipe de recherche a spécifiquement inclus les nouveaux Claude-3.5-Sonnet ainsi que Gemini-1.5-Pro et les a comparés aux puissants GPT-4o et GPT-4V. pour refléter les dernières performances du modèle. Métriques Étant donné que tous les problèmes peuvent être évalués par une correspondance basée sur des règles, l'équipe de recherche a utilisé la précision pour les tâches non liées à la programmation et des métriques pass@k impartiales pour les tâches de programmation, définies comme suit : 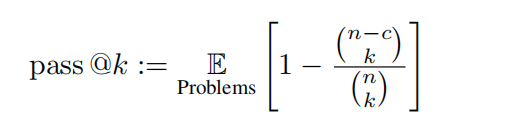
Dans cette évaluation, k = 1 et n = 5 sont définis, et c représente le nombre d'échantillons corrects qui réussissent tous les cas de test. Liste des médailles de l'arène olympique : Semblable au système de médailles utilisé aux Jeux Olympiques, il s'agit d'un mécanisme de classement pionnier spécialement conçu pour évaluer les performances des modèles d'IA dans divers domaines académiques. Le tableau décerne des médailles aux modèles qui obtiennent les trois meilleurs résultats dans une discipline donnée, offrant ainsi un cadre clair et compétitif pour comparer les différents modèles. L'équipe de recherche a d'abord trié les modèles en fonction du nombre de médailles d'or, si le nombre de médailles d'or était le même, ils ont été triés selon la note de performance globale. Il fournit un moyen intuitif et concis d'identifier les principaux modèles dans différents domaines universitaires, permettant ainsi aux chercheurs et aux développeurs de comprendre plus facilement les forces et les faiblesses des différents modèles. L'équipe de recherche effectue également une évaluation fine basée sur la précision et basée sur différentes disciplines, différentes modalités, différentes langues et différents types de capacités de raisonnement logique et visuel. Le contenu de l'analyse se concentre principalement sur Claude-3.5-Sonnet et GPT-4o, et discute également partiellement des performances de Gemini-1.5-Pro. 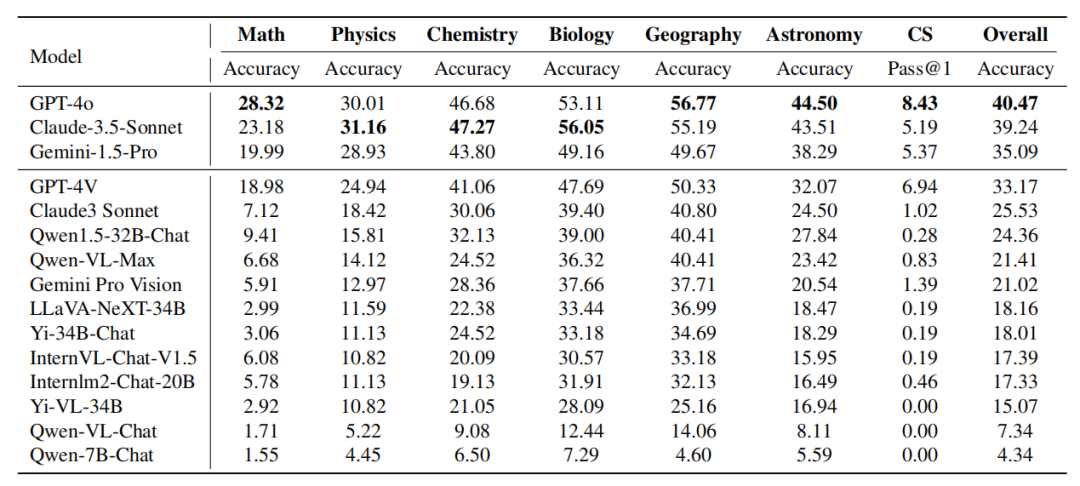
Tableau : Performances du modèle sur différents sujets Les performances de Claude-3.5-Sonnet sont puissantes et atteignent presque Comparable à GPT-4o. La différence globale de précision entre les deux n’est que d’environ 1 %. Le nouveau Gemini-1.5-Pro a également fait preuve d'une force considérable, surpassant le GPT-4V (le deuxième modèle le plus puissant actuel d'OpenAI) dans la plupart des disciplines.
Il convient de noter qu’au moment de la rédaction de cet article, le premier de ces trois modèles est sorti il y a à peine un mois, reflétant le développement rapide dans ce domaine.
- Analyse fine pour les disciplines
GPT-4o vs. Claude-3.5-Sonnet :
Bien que GPT-4o et Claude- 3. 5-Sonnets dans l'ensemble Les performances sont similaires, mais les deux modèles présentent des avantages en matière différents. GPT-4o démontre des capacités supérieures sur les tâches de raisonnement déductif et inductif traditionnelles, en particulier en mathématiques et en informatique. Claude-3.5-Sonnet obtient de bons résultats dans des matières telles que la physique, la chimie et la biologie, notamment en biologie, où il dépasse le GPT-4o de 3 %.
GPT-4V contre Gemini-1.5-Pro : Un phénomène similaire peut être observé dans la comparaison de Gemini-1.5-Pro contre GPT-4V. Gemini-1.5-Pro surpasse considérablement le GPT-4V en physique, chimie et biologie. Cependant, en termes de mathématiques et d'informatique, les avantages de Gemini-1.5-Pro ne sont pas évidents ni même inférieurs à ceux de GPT-4V. De ces deux séries de comparaisons, on peut voir que : La série GPT d'OpenAI fonctionne de manière exceptionnelle en termes de capacités de raisonnement et de programmation mathématiques traditionnelles. Cela montre que les modèles de la série GPT ont été rigoureusement formés pour gérer des tâches qui nécessitent beaucoup de raisonnement déductif et de pensée algorithmique. En revanche, d'autres modèles tels que Claude-3.5-Sonnet et Gemini-1.5-Pro ont démontré des performances compétitives lorsqu'il s'agit de matières qui nécessitent de combiner connaissances et raisonnement, comme la physique, la chimie et la biologie. Cela reflète les différents domaines d'expertise du modèle et l'orientation potentielle de la formation, indiquant des compromis possibles entre les tâches à forte intensité de raisonnement et les tâches d'intégration des connaissances. Analyse fine des types de raisonnement
- Légende : Les performances de chaque modèle en capacités de raisonnement logique. Les capacités de raisonnement logique comprennent : le raisonnement déductif (DED), le raisonnement inductif (IND), le raisonnement abductif (ABD), le raisonnement analogique (ANA), le raisonnement causal (CAE), la pensée critique (CT), le raisonnement de décomposition (DEC) et le raisonnement quantitatif ( EN TANT QUE).
Comparaison entre GPT-4o et Claude-3.5-Sonnet en termes de capacités de raisonnement logique : 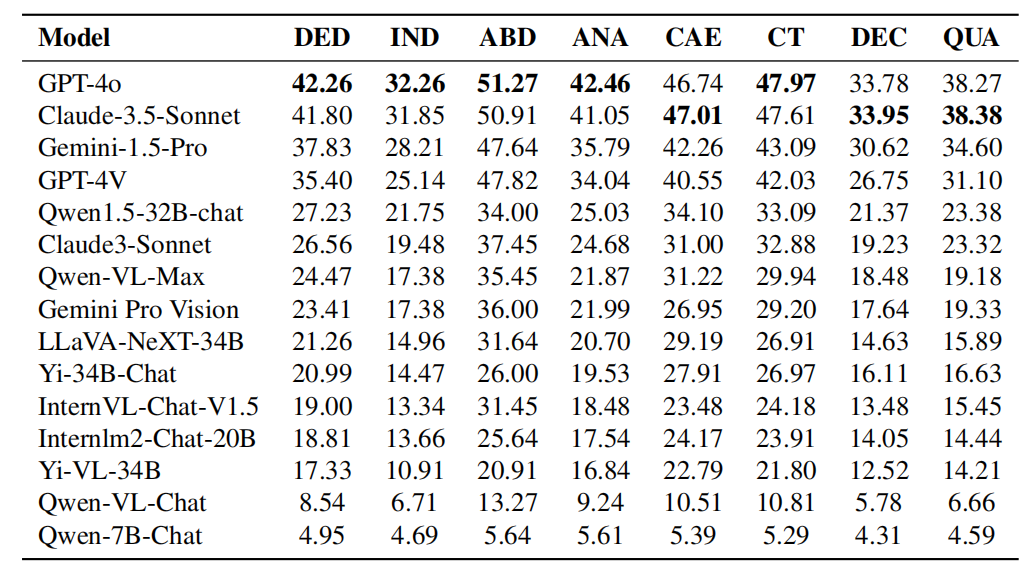
Comme le montrent les résultats expérimentaux du tableau, GPT-4o a d'excellentes performances dans la plupart des capacités de raisonnement logique Mieux que Claude-3.5-Sonnet dans des domaines tels que le raisonnement déductif, le raisonnement inductif, le raisonnement abductif, le raisonnement analogique et la pensée critique. Cependant, Claude-3.5-Sonnet surpasse GPT-4o en raisonnement causal, en raisonnement par décomposition et en raisonnement quantitatif. Dans l'ensemble, les performances des deux modèles sont comparables, même si le GPT-4o présente un léger avantage dans la plupart des catégories. Tableau : Performances de chaque modèle en capacités de raisonnement visuel. Les capacités de raisonnement visuel comprennent : la reconnaissance de formes (PR), le raisonnement spatial (SPA), le raisonnement schématique (DIA), l'interprétation symbolique (SYB) et la comparaison visuelle (COM). GPT-4o vs Claude-3.5-Sonnet Performance en capacité de raisonnement visuel : Comme le montrent les résultats expérimentaux du tableau, Claude-3.5-Sonnet est meilleur en reconnaissance de formes et leader dans le raisonnement de diagrammes, démontrant sa compétitivité dans la reconnaissance de formes et l'interprétation de diagrammes. Les deux modèles ont des performances comparables en matière d’interprétation des symboles, ce qui indique qu’ils ont des capacités comparables en matière de compréhension et de traitement des informations symboliques. Cependant, GPT-4o surpasse Claude-3.5-Sonnet en raisonnement spatial et en comparaison visuelle, démontrant sa supériorité sur les tâches qui nécessitent de comprendre les relations spatiales et de comparer des données visuelles. Analyse complète des disciplines et des types de raisonnement, l'équipe de recherche a découvert que :
- Les mathématiques et la programmation informatique mettent l'accent sur les compétences de raisonnement déductif complexes et la dérivation de conclusions universelles basées sur des règles, et ont tendance à moins s'appuyer sur Connaissances préexistantes. En revanche, des disciplines comme la chimie et la biologie nécessitent souvent de vastes bases de connaissances pour raisonner sur la base d’informations connues sur les relations causales et les phénomènes. Cela suggère que si les capacités mathématiques et de programmation restent des indicateurs valables de la capacité de raisonnement d'un modèle, d'autres disciplines testent mieux la capacité d'un modèle à raisonner et à analyser des problèmes sur la base de ses connaissances internes.
- Les caractéristiques des différentes disciplines indiquent l'importance des ensembles de données d'entraînement personnalisés. Par exemple, pour améliorer les performances du modèle dans des matières à forte intensité de connaissances telles que la chimie et la biologie, le modèle doit être largement exposé à des données spécifiques au domaine pendant la formation. En revanche, pour les matières qui nécessitent une forte logique et un raisonnement déductif, comme les mathématiques et l’informatique, les modèles peuvent bénéficier d’une formation axée sur le raisonnement purement logique.
- De plus, la distinction entre capacité de raisonnement et application des connaissances démontre le potentiel du modèle pour une application interdisciplinaire. Par exemple, les modèles dotés de fortes capacités de raisonnement déductif peuvent aider les domaines qui nécessitent une réflexion systématique pour résoudre des problèmes, comme la recherche scientifique. Et les modèles riches en connaissances sont précieux dans les disciplines qui s’appuient fortement sur les informations existantes, comme la médecine et les sciences de l’environnement. Comprendre ces nuances permet de développer des modèles plus spécialisés et plus polyvalents.
Analyse fine des types de langues Légende : Les performances de chaque modèle dans différents problèmes linguistiques.
Légende : Les performances de chaque modèle dans différents problèmes linguistiques.
Le tableau ci-dessus montre les performances du modèle dans différentes langues. L’équipe de recherche a constaté que la plupart des modèles étaient plus précis en anglais qu’en chinois, cet écart étant particulièrement important parmi les modèles les mieux classés. On suppose qu'il peut y avoir plusieurs raisons :
- Bien que ces modèles contiennent une grande quantité de données de formation en chinois et aient des capacités de généralisation multilingue, leurs données de formation sont principalement basées sur l'anglais.
- Les questions chinoises sont plus difficiles que les questions anglaises, en particulier dans des matières comme la physique et la chimie, les questions de l'Olympiade chinoise sont plus difficiles.
- Ces modèles sont insuffisants pour identifier les caractères dans les images multimodales, et ce problème est plus grave dans l'environnement chinois.
Cependant, l'équipe de recherche a également constaté que certains modèles développés par des fabricants chinois ou affinés sur la base de modèles de base prenant en charge le chinois fonctionnent mieux dans les scénarios chinois que dans les scénarios anglais, tels que Qwen1.5-32B- Chat, Qwen-VL-Max, Yi-34B-Chat et Qwen-7B-Chat, etc. D'autres modèles, tels que InternLM2-Chat-20B et Yi-VL-34B, bien que toujours plus performants en anglais, présentent des différences de précision beaucoup plus faibles entre les scènes anglaises et chinoises que la plupart des modèles à source fermée les mieux classés. Cela montre que l’optimisation des modèles pour les données chinoises et encore plus de langues dans le monde nécessite encore une attention particulière. Analyse fine des modalités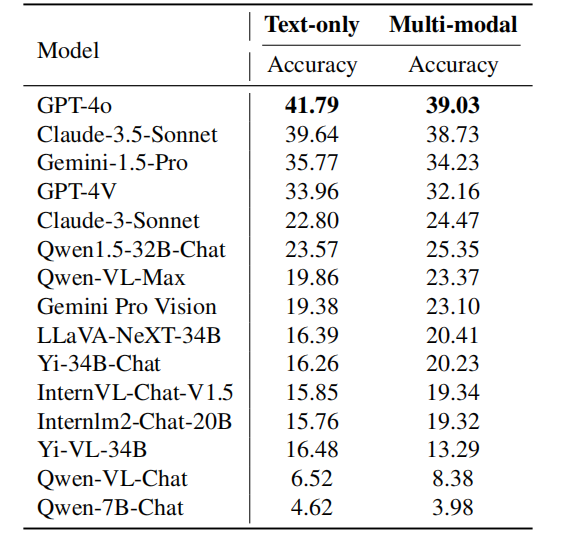
Légende : Les performances de chaque modèle dans différents problèmes modaux. Le tableau ci-dessus montre les performances du modèle dans différentes modalités. GPT-4o surpasse Claude-3.5-Sonnet dans les tâches de texte brut et multimodales, et est plus performant sur le texte brut. D'un autre côté, Gemini-1.5-Pro surpasse GPT-4V sur les tâches de texte brut et multimodales. Ces observations indiquent que même les modèles les plus puissants actuellement disponibles ont une plus grande précision sur les tâches contenant uniquement du texte que sur les tâches multimodales. Cela montre que le modèle peut encore être amélioré considérablement dans l’utilisation d’informations multimodales pour résoudre des problèmes de raisonnement complexes. Dans cette revue, l'équipe de recherche s'est principalement concentrée sur les derniers modèles : Claude-3.5-Sonnet et Gemini-1.5-Pro, et les a comparés avec les GPT-4o et GPT- d'OpenAI. 4V pour comparaison. En outre, l’équipe de recherche a également conçu un nouveau système de classement pour les grands modèles, l’OlympicArena Medal Table, afin de comparer clairement les capacités des différents modèles. L’équipe de recherche a découvert que GPT-4o excelle dans des matières telles que les mathématiques et l’informatique, et possède de fortes capacités de raisonnement déductif complexe et la capacité de tirer des conclusions générales basées sur des règles. Claude-3.5-Sonnet, en revanche, raisonne mieux à partir de relations causales et de phénomènes existants. En outre, l’équipe de recherche a également observé que ces modèles étaient plus performants sur les problèmes de langue anglaise et disposaient d’une marge d’amélioration significative en termes de capacités multimodales. Comprendre ces nuances de modèles peut aider à développer des modèles plus spécialisés qui répondent mieux aux divers besoins des différents domaines universitaires et professionnels. À l’approche de l’événement olympique quadriennal, nous ne pouvons nous empêcher d’imaginer quel genre de confrontation entre la sagesse et la technologie ce sera si l’intelligence artificielle peut également participer ? Il ne s’agit plus seulement d’une compétition physique. L’ajout de l’IA ouvrira sans aucun doute une nouvelle exploration des limites de l’intelligence. Nous attendons également avec impatience que davantage d’acteurs de l’IA rejoignent ces Jeux olympiques intellectuels. [1] Huang et al., OlympicArena : analyse comparative du raisonnement cognitif multidisciplinaire pour l'IA superintelligente https://arxiv.org/abs/2406.12753v 1
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Que sont les variables d'environnement
Que sont les variables d'environnement
 Comment définir les éléments de démarrage au démarrage
Comment définir les éléments de démarrage au démarrage
 Comment fermer le port 445
Comment fermer le port 445
 utilisation de la fonction de longueur
utilisation de la fonction de longueur
 Prix du Litecoin aujourd'hui
Prix du Litecoin aujourd'hui
 Quels sont les composants de base d'un ordinateur ?
Quels sont les composants de base d'un ordinateur ?
 Il existe plusieurs types de noyaux de navigateur
Il existe plusieurs types de noyaux de navigateur








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



