Meta a développé un formidable compilateur LLM pour aider les programmeurs à écrire du code plus efficacement.
Hier, les trois grands géants de l'IA OpenAI, Google et Meta se sont associés pour publier les derniers résultats de recherche de leurs propres grands modèles - OpenAI a lancé un nouveau modèle CriticGPT basé sur GPT-4 formation spécialisée dans la recherche de bogues, les versions Google Open source 9B et 27B de Gemma2, et Meta a mis au point la dernière percée en matière d'intelligence artificielle - le compilateur LLM. Il s'agit d'un ensemble puissant de modèles open source conçus pour optimiser le code et révolutionner la conception des compilateurs. Cette innovation a le potentiel de changer la façon dont les développeurs abordent l’optimisation du code, en la rendant plus rapide, plus efficace et plus rentable. Il est rapporté que le potentiel d'optimisation du compilateur LLM atteint 77% de la recherche de réglage automatique. Ce résultat peut réduire considérablement le temps de compilation et améliorer l'efficacité du code de diverses applications, et en termes de démontage, son tour. voyage Le taux de réussite du démontage est de 45%. Certains internautes ont dit que cela changeait la donne pour l'optimisation et le démontage du code. C'est une très bonne nouvelle pour les développeurs. Les grands modèles de langage ont montré d'excellentes capacités dans de nombreuses tâches d'ingénierie logicielle et de programmation, mais leur application dans le domaine de l'optimisation du code et des compilateurs n'a pas été pleinement exploitée. La formation de ces LLM nécessite des ressources informatiques étendues, notamment du temps GPU coûteux et de grands ensembles de données, ce qui rend souvent de nombreuses recherches et projets non durables. Pour combler cette lacune, l'équipe de recherche Meta a introduit un compilateur LLM pour optimiser spécifiquement le code et révolutionner la conception du compilateur. En entraînant le modèle sur un corpus massif de 546 milliards de jetons de LLVM-IR et de code assembleur, ils ont permis au modèle de comprendre les représentations intermédiaires du compilateur, le langage assembleur et les techniques d'optimisation. " LLM Compiler offre une meilleure compréhension des représentations intermédiaires (IR) du compilateur, du langage d'assemblage et des techniques d'optimisation », explique leur article. Cette compréhension améliorée permet aux modèles d'effectuer des tâches auparavant réservées à des experts humains ou à des outils spécialisés. Le processus de formation du LLM Compiler est illustré à la figure 1. Le compilateur LLM obtient des résultats significatifs en matière d'optimisation de la taille du code. Lors des tests, le potentiel d'optimisation du modèle a atteint 77 % de la recherche de réglage automatique, un résultat qui peut réduire considérablement le temps de compilation et améliorer l'efficacité du code pour une variété d'applications. Le modèle est meilleur au démontage. Le compilateur LLM atteint un taux de réussite de démontage aller-retour de 45 % (dont 14 % de correspondances exactes) lors de la reconversion du code d'assemblage x86_64 et ARM en LLVM-IR. Cette capacité peut s’avérer inestimable pour les tâches d’ingénierie inverse et la maintenance du code existant. L'un des principaux contributeurs au projet, Chris Cummins, a souligné l'impact potentiel de cette technologie : « En fournissant des modèles pré-entraînés en deux tailles (700 millions et 1,3 milliard de paramètres) et en démontrant son efficacité grâce à des analyses fines. versions optimisées, "LLM Compiler ouvre la voie à l'exploration du potentiel inexploité de LLM dans le domaine de l'optimisation du code et du compilateur", a-t-il déclaré. Pré-formation sur le code assembleur et le compilateur IR Les données utilisées pour entraîner la programmation. Les LLM se composent généralement principalement de langages sources de haut niveau comme Python, le code assembleur représente une proportion négligeable dans ces ensembles de données et l'IR du compilateur en représente une plus petite.
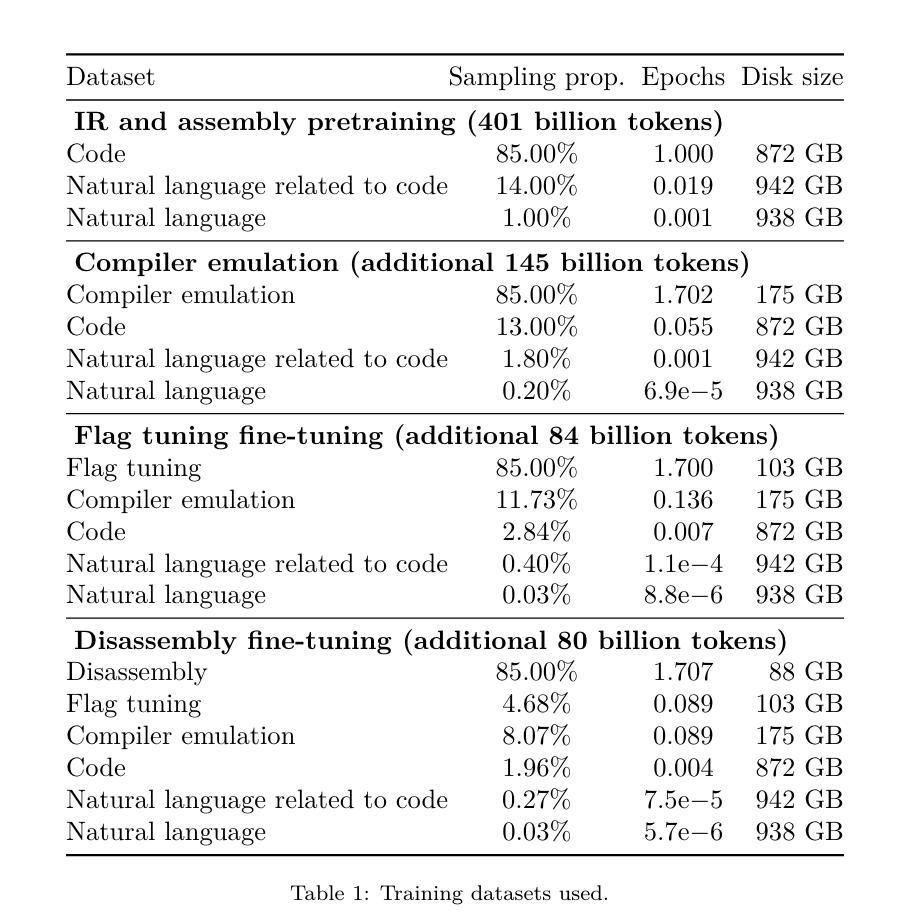
Afin de construire un LLM avec une bonne compréhension de ces langages, l'équipe de recherche a initialisé le modèle LLM Compiler avec les poids de Code Llama, puis a formé 401 milliards de jetons sur un ensemble de données centré sur le compilateur. se compose du code assembleur et du compilateur IR, comme indiqué dans le tableau 1. Dataset LLM Compiler est principalement formé sur la représentation intermédiaire du compilateur et le code d'assemblage généré par LLVM (version 17.0.6). Ces données sont dérivées du même ensemble de données utilisé pour former Code Llama, qui a été rapporté dans le tableau 2. L'ensemble de données est décrit dans . Comme Code Llama, nous obtenons également de petits lots de formation à partir d'ensembles de données en langage naturel.  Réglage fin des instructions pour la simulation du compilateurAfin de comprendre le mécanisme d'optimisation du code, l'équipe de recherche a effectué un réglage fin des instructions sur le modèle du compilateur LLM pour simuler l'optimisation du compilateur, comme le montre la figure 2. L'idée est de générer un grand nombre d'exemples à partir d'une collection limitée de programmes de départ non optimisés en appliquant à ces programmes des séquences générées aléatoirement d'optimisations du compilateur. Ils ont ensuite entraîné le modèle pour prédire le code généré par l'optimisation, et ont également entraîné le modèle pour prédire la taille du code après avoir appliqué l'optimisation. Spécifications des tâches. Étant donné LLVM-IR non optimisé (sortie par l'interface clang), une liste de passes d'optimisation et une taille de code de départ, générez le code résultant et la taille du code après avoir appliqué ces optimisations. Il existe deux types de cette tâche : dans le premier, le modèle s'attend à générer un IR du compilateur ; dans le second, le modèle s'attend à générer du code assembleur. L'IR d'entrée, le processus d'optimisation et la taille du code sont les mêmes pour les deux types, et l'indice détermine le format de sortie requis. Taille du code. Ils utilisent deux métriques pour mesurer la taille du code : le nombre d'instructions IR et la taille binaire. La taille binaire est calculée comme la somme des tailles des segments .TEXT et .DATA après la rétrogradation de l'IR ou de l'assembly vers un fichier objet. Nous excluons le segment .BSS car il n'affecte pas la taille du disque. Optimiser la passe. Dans ce travail, l'équipe de recherche cible LLVM 17.0.6 et utilise le nouveau gestionnaire de processus (PM, 2021), qui classe les passes en différents niveaux, tels que modules, fonctions, boucles, etc., ainsi que convertit et analyse les passes. . Une passe de transformation modifie un IR d'entrée donné, tandis qu'une passe d'analyse génère des informations qui affectent les transformations ultérieures. Sur 346 paramètres de réussite possibles pour l'option, ils en ont choisi 167 à utiliser. Cela inclut chaque pipeline d'optimisation par défaut (par exemple, module (default)), les passes de transformation d'optimisation individuelles (par exemple, module (constmerge)), mais exclut les passes utilitaires non optimisées (par exemple, module (dot-callgraph)) et ne préserve pas la passe de conversion sémantique. (tel que module (internaliser)). Ils excluent les passes d'analyse car elles n'ont aucun effet secondaire et nous comptons sur le gestionnaire de passes pour injecter des passes d'analyse dépendantes selon les besoins. Pour les passes qui acceptent des paramètres, nous utilisons des valeurs par défaut (par exemple module (licm)). Le tableau 9 contient une liste de tous les laissez-passer utilisés. Nous utilisons l'outil opt de LLVM pour appliquer la liste de réussite et clang pour rétrograder l'IR résultant vers un fichier objet. Le listing 1 montre les commandes utilisées.
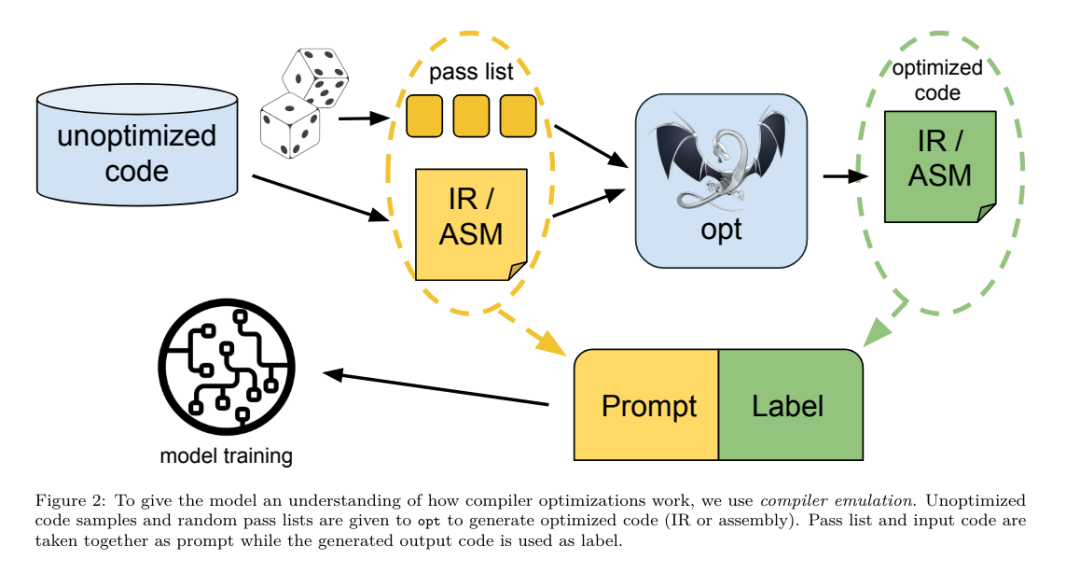
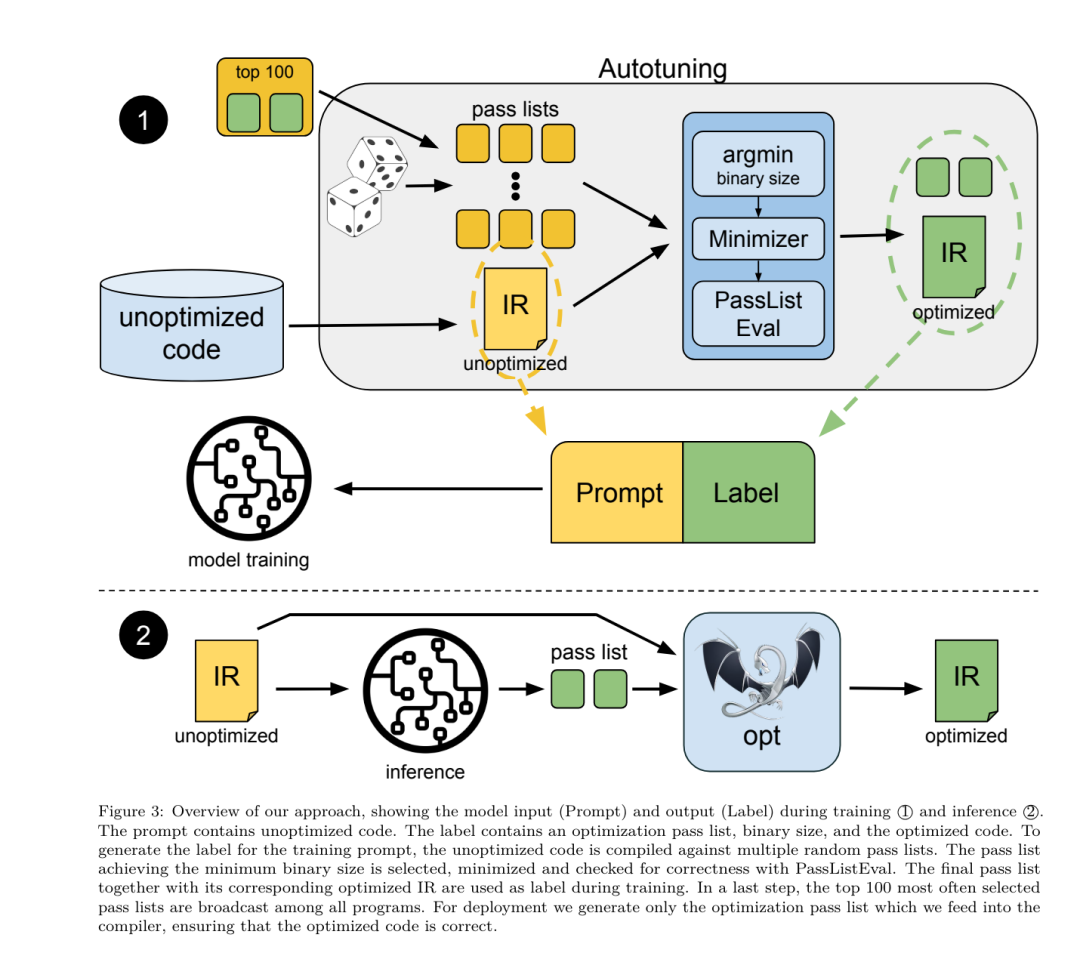
Réglage fin des instructions pour la simulation du compilateurAfin de comprendre le mécanisme d'optimisation du code, l'équipe de recherche a effectué un réglage fin des instructions sur le modèle du compilateur LLM pour simuler l'optimisation du compilateur, comme le montre la figure 2. L'idée est de générer un grand nombre d'exemples à partir d'une collection limitée de programmes de départ non optimisés en appliquant à ces programmes des séquences générées aléatoirement d'optimisations du compilateur. Ils ont ensuite entraîné le modèle pour prédire le code généré par l'optimisation, et ont également entraîné le modèle pour prédire la taille du code après avoir appliqué l'optimisation. Spécifications des tâches. Étant donné LLVM-IR non optimisé (sortie par l'interface clang), une liste de passes d'optimisation et une taille de code de départ, générez le code résultant et la taille du code après avoir appliqué ces optimisations. Il existe deux types de cette tâche : dans le premier, le modèle s'attend à générer un IR du compilateur ; dans le second, le modèle s'attend à générer du code assembleur. L'IR d'entrée, le processus d'optimisation et la taille du code sont les mêmes pour les deux types, et l'indice détermine le format de sortie requis. Taille du code. Ils utilisent deux métriques pour mesurer la taille du code : le nombre d'instructions IR et la taille binaire. La taille binaire est calculée comme la somme des tailles des segments .TEXT et .DATA après la rétrogradation de l'IR ou de l'assembly vers un fichier objet. Nous excluons le segment .BSS car il n'affecte pas la taille du disque. Optimiser la passe. Dans ce travail, l'équipe de recherche cible LLVM 17.0.6 et utilise le nouveau gestionnaire de processus (PM, 2021), qui classe les passes en différents niveaux, tels que modules, fonctions, boucles, etc., ainsi que convertit et analyse les passes. . Une passe de transformation modifie un IR d'entrée donné, tandis qu'une passe d'analyse génère des informations qui affectent les transformations ultérieures. Sur 346 paramètres de réussite possibles pour l'option, ils en ont choisi 167 à utiliser. Cela inclut chaque pipeline d'optimisation par défaut (par exemple, module (default)), les passes de transformation d'optimisation individuelles (par exemple, module (constmerge)), mais exclut les passes utilitaires non optimisées (par exemple, module (dot-callgraph)) et ne préserve pas la passe de conversion sémantique. (tel que module (internaliser)). Ils excluent les passes d'analyse car elles n'ont aucun effet secondaire et nous comptons sur le gestionnaire de passes pour injecter des passes d'analyse dépendantes selon les besoins. Pour les passes qui acceptent des paramètres, nous utilisons des valeurs par défaut (par exemple module (licm)). Le tableau 9 contient une liste de tous les laissez-passer utilisés. Nous utilisons l'outil opt de LLVM pour appliquer la liste de réussite et clang pour rétrograder l'IR résultant vers un fichier objet. Le listing 1 montre les commandes utilisées.  ensemble de données. L'équipe de recherche a généré un ensemble de données de simulation de compilateur en appliquant une liste de 1 à 50 passes d'optimisation aléatoires au programme non optimisé résumé dans le tableau 2. La longueur de chaque liste de passes est choisie de manière uniforme et aléatoire. La liste de passes est générée par un échantillonnage uniforme à partir de l'ensemble de 167 passes ci-dessus. Les listes de réussite qui provoquent le blocage ou l'expiration du compilateur après 120 secondes sont exclues. LLM Compiler FTD : étendre les tâches de compilation en aval Affinage des instructions pour le réglage des indicateurs d'optimisationLa manipulation des indicateurs du compilateur a un impact significatif sur les performances d'exécution et la taille du code. L'équipe de recherche a formé le modèle FTD du compilateur LLM pour effectuer la tâche en aval de sélection des indicateurs pour l'outil d'optimisation IR de LLVM et choisir de produire la plus petite taille de code. Les méthodes d'apprentissage automatique adaptées aux drapeaux ont déjà montré de bons résultats, mais ont rencontré des difficultés de généralisation à travers différents programmes.Les travaux antérieurs nécessitaient souvent de compiler de nouveaux programmes des dizaines ou des centaines de fois pour essayer différentes configurations et trouver l'option la plus performante. L'équipe de recherche a formé et évalué le modèle FTD du compilateur LLM sur une version zéro-shot de cette tâche en prédisant les indicateurs afin de minimiser la taille du code des programmes invisibles. Leur approche ne dépend pas du compilateur choisi et des métriques d'optimisation, et ils ont l'intention de cibler les performances d'exécution à l'avenir. Actuellement, l'optimisation de la taille du code simplifie la collecte des données de formation. Spécifications des tâches. L'équipe de recherche a présenté un LLVM-IR non optimisé (généré par l'interface clang) au modèle FTD du compilateur LLM et lui a demandé de générer une liste d'indicateurs opt qui doivent être appliqués, la taille binaire avant et après l'application de ces optimisations, et le code de sortie s'il ne peut pas être utilisé sur le code d'entrée. Des améliorations sont apportées pour produire un court message de sortie contenant uniquement la taille binaire non optimisée. Ils ont utilisé le même ensemble de passes d'optimisation restreintes que la tâche de simulation du compilateur et ont calculé la taille binaire de la même manière. La figure 3 illustre le processus utilisé pour générer les données d'entraînement et comment le modèle est utilisé au moment de l'inférence. Seule la liste de réussite générée est nécessaire lors de l'évaluation. Ils extraient la liste de réussite de la sortie du modèle et exécutent opt avec les paramètres donnés. Les chercheurs peuvent ensuite évaluer l'exactitude de la taille binaire prévue du modèle et optimiser le code de sortie, mais il s'agit de tâches d'apprentissage auxiliaires et ne sont pas nécessaires à l'utilisation. Justice. L'optimiseur LLVM n'est pas infaillible, et l'exécution des passes d'optimisation dans un ordre inattendu ou non testé peut exposer des erreurs d'exactitude subtiles qui réduisent l'utilité du modèle. Pour atténuer ce risque, l'équipe de recherche a développé PassListEval, un outil permettant d'identifier automatiquement les listes de réussite qui brisent la sémantique du programme ou provoquent le blocage des compilateurs. La figure 4 montre un aperçu de l'outil.
ensemble de données. L'équipe de recherche a généré un ensemble de données de simulation de compilateur en appliquant une liste de 1 à 50 passes d'optimisation aléatoires au programme non optimisé résumé dans le tableau 2. La longueur de chaque liste de passes est choisie de manière uniforme et aléatoire. La liste de passes est générée par un échantillonnage uniforme à partir de l'ensemble de 167 passes ci-dessus. Les listes de réussite qui provoquent le blocage ou l'expiration du compilateur après 120 secondes sont exclues. LLM Compiler FTD : étendre les tâches de compilation en aval Affinage des instructions pour le réglage des indicateurs d'optimisationLa manipulation des indicateurs du compilateur a un impact significatif sur les performances d'exécution et la taille du code. L'équipe de recherche a formé le modèle FTD du compilateur LLM pour effectuer la tâche en aval de sélection des indicateurs pour l'outil d'optimisation IR de LLVM et choisir de produire la plus petite taille de code. Les méthodes d'apprentissage automatique adaptées aux drapeaux ont déjà montré de bons résultats, mais ont rencontré des difficultés de généralisation à travers différents programmes.Les travaux antérieurs nécessitaient souvent de compiler de nouveaux programmes des dizaines ou des centaines de fois pour essayer différentes configurations et trouver l'option la plus performante. L'équipe de recherche a formé et évalué le modèle FTD du compilateur LLM sur une version zéro-shot de cette tâche en prédisant les indicateurs afin de minimiser la taille du code des programmes invisibles. Leur approche ne dépend pas du compilateur choisi et des métriques d'optimisation, et ils ont l'intention de cibler les performances d'exécution à l'avenir. Actuellement, l'optimisation de la taille du code simplifie la collecte des données de formation. Spécifications des tâches. L'équipe de recherche a présenté un LLVM-IR non optimisé (généré par l'interface clang) au modèle FTD du compilateur LLM et lui a demandé de générer une liste d'indicateurs opt qui doivent être appliqués, la taille binaire avant et après l'application de ces optimisations, et le code de sortie s'il ne peut pas être utilisé sur le code d'entrée. Des améliorations sont apportées pour produire un court message de sortie contenant uniquement la taille binaire non optimisée. Ils ont utilisé le même ensemble de passes d'optimisation restreintes que la tâche de simulation du compilateur et ont calculé la taille binaire de la même manière. La figure 3 illustre le processus utilisé pour générer les données d'entraînement et comment le modèle est utilisé au moment de l'inférence. Seule la liste de réussite générée est nécessaire lors de l'évaluation. Ils extraient la liste de réussite de la sortie du modèle et exécutent opt avec les paramètres donnés. Les chercheurs peuvent ensuite évaluer l'exactitude de la taille binaire prévue du modèle et optimiser le code de sortie, mais il s'agit de tâches d'apprentissage auxiliaires et ne sont pas nécessaires à l'utilisation. Justice. L'optimiseur LLVM n'est pas infaillible, et l'exécution des passes d'optimisation dans un ordre inattendu ou non testé peut exposer des erreurs d'exactitude subtiles qui réduisent l'utilité du modèle. Pour atténuer ce risque, l'équipe de recherche a développé PassListEval, un outil permettant d'identifier automatiquement les listes de réussite qui brisent la sémantique du programme ou provoquent le blocage des compilateurs. La figure 4 montre un aperçu de l'outil. 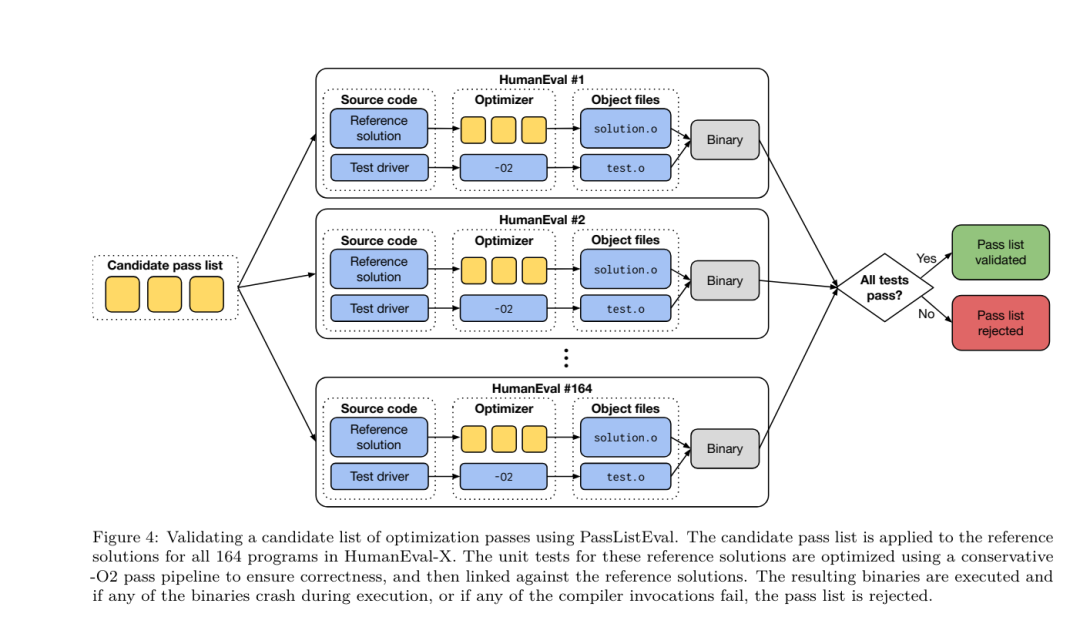 PassListEval accepte en entrée une liste de réussites des candidats et l'évalue sur une suite de 164 programmes C++ d'auto-test, tirés de HumanEval-X. Chaque programme contient une solution de référence à un défi de programmation, comme « vérifier si la distance entre deux nombres dans un vecteur de nombres donné est inférieure à un seuil donné », ainsi qu'une suite de tests unitaires pour vérifier l'exactitude. Ils appliquent la liste des réussites candidates aux solutions de référence, puis les relient aux suites de tests pour générer des binaires. Une fois exécuté, si un test échoue, le binaire plantera. Si un binaire plante ou si un appel du compilateur échoue, nous rejetons la liste de réussite des candidats. ensemble de données. L’équipe a formé le modèle FTD du compilateur LLM sur un exemple d’ensemble de données optimisé dérivé de 4,5 millions d’IR non optimisés utilisés pour le pré-entraînement. Pour générer les meilleurs exemples de listes de réussite pour chaque programme, ils ont effectué un processus de compilation itératif approfondi, comme le montre la figure 3. 1. L'équipe de recherche utilise une recherche aléatoire à grande échelle pour générer une liste initiale des meilleurs candidats pour le programme. Pour chaque programme, ils ont généré indépendamment une liste aléatoire comprenant jusqu'à 50 passes, uniformément échantillonnées à partir de l'ensemble de 167 passes consultables décrit précédemment. Chaque fois qu'ils évaluaient la liste de réussite d'un programme, ils enregistraient la taille binaire résultante, puis sélectionnaient la liste de réussite de chaque programme qui produisait la plus petite taille binaire. Ils ont diffusé 22 milliards de compilations indépendantes, soit une moyenne de 4 877 par programme. 2. La liste des passes générée par la recherche aléatoire peut contenir des passes redondantes, qui n'ont aucun impact sur le résultat final. De plus, certaines commandes de laissez-passer sont interchangeables et la réorganisation n’affectera pas le résultat final. Étant donné que ceux-ci introduisent du bruit dans les données d’entraînement, ils ont développé un processus de minimisation et l’ont appliqué à chaque liste de réussite. La minimisation comprend trois étapes : l'élimination des passes redondantes, le tri des bulles et la recherche d'insertion. Lors de l'élimination des passes redondantes, ils minimisent la liste de passes optimale en supprimant de manière itérative les passes individuelles pour voir si elles contribuent à la taille binaire, et sinon, les ignorent. Répétez ce processus jusqu'à ce qu'aucune autre passe ne puisse être abandonnée. Le tri à bulles tente ensuite de fournir un classement unifié des sous-séquences de passes, en triant les passes en fonction de mots-clés. Enfin, le tri par insertion effectue une recherche locale en parcourant chaque passe de la liste de passes et en essayant d'insérer chacune des 167 passes de recherche qui la précèdent. Si cela améliore la taille binaire, conservez cette nouvelle liste de passes. L'ensemble du pipeline de minimisation est bouclé jusqu'à ce qu'un point fixe soit atteint. La distribution minimisée de la longueur de la liste de réussite est illustrée à la figure 9. La longueur moyenne de la liste de réussite est de 3,84.3. Ils appliquent la PassListEval décrite précédemment à la liste des meilleures réussites du candidat. De cette façon, ils ont identifié 167 971 sur 1 704 443 listes de passes uniques (9,85 %) qui provoqueraient des erreurs de compilation ou d'exécution 4. Ils ont diffusé les 100 listes de passes optimales les plus courantes à tous les programmes et les ont mises à jour. la meilleure liste de réussite pour chaque programme si des améliorations sont trouvées. Par la suite, le nombre total de listes uniques de meilleures passes a été réduit de 1 536 472 à 581 076. Le pipeline de réglage automatique ci-dessus a produit une réduction de 7,1 % de la taille binaire moyenne géométrique par rapport à -Oz. La figure 10 montre la fréquence d'un seul passage. Pour eux, ce réglage automatique sert de référence pour chaque optimisation de programme. Même si les économies de taille binaire constatées sont significatives, cela a nécessité 28 milliards de compilations supplémentaires pour un coût de calcul de plus de 21 000 jours CPU. L'objectif du réglage fin des instructions du FTD du compilateur LLM pour effectuer des tâches de réglage des indicateurs est d'atteindre une fraction des performances du réglage automatique sans avoir à exécuter le compilateur des milliers de fois. Ajustement des instructions pour le désassemblage Fait passer le code du langage assembleur à une structure de niveau supérieur qui peut exécuter des optimisations supplémentaires, telles que le code de bibliothèque intégré directement dans le code de l'application, ou le portage du code hérité vers nouvelle architecture. Le domaine de la décompilation a progressé dans l'application de techniques d'apprentissage automatique pour générer un code lisible et précis à partir d'exécutables binaires. Dans cette étude, l'équipe de recherche montre comment le LLM Compiler FTD peut effectuer un démontage grâce à un réglage fin, en apprenant la relation entre le code assembleur et l'IR du compilateur. La tâche consiste à apprendre la traduction inverse de clang -xir - -o - -S, comme le montre la figure 5.
PassListEval accepte en entrée une liste de réussites des candidats et l'évalue sur une suite de 164 programmes C++ d'auto-test, tirés de HumanEval-X. Chaque programme contient une solution de référence à un défi de programmation, comme « vérifier si la distance entre deux nombres dans un vecteur de nombres donné est inférieure à un seuil donné », ainsi qu'une suite de tests unitaires pour vérifier l'exactitude. Ils appliquent la liste des réussites candidates aux solutions de référence, puis les relient aux suites de tests pour générer des binaires. Une fois exécuté, si un test échoue, le binaire plantera. Si un binaire plante ou si un appel du compilateur échoue, nous rejetons la liste de réussite des candidats. ensemble de données. L’équipe a formé le modèle FTD du compilateur LLM sur un exemple d’ensemble de données optimisé dérivé de 4,5 millions d’IR non optimisés utilisés pour le pré-entraînement. Pour générer les meilleurs exemples de listes de réussite pour chaque programme, ils ont effectué un processus de compilation itératif approfondi, comme le montre la figure 3. 1. L'équipe de recherche utilise une recherche aléatoire à grande échelle pour générer une liste initiale des meilleurs candidats pour le programme. Pour chaque programme, ils ont généré indépendamment une liste aléatoire comprenant jusqu'à 50 passes, uniformément échantillonnées à partir de l'ensemble de 167 passes consultables décrit précédemment. Chaque fois qu'ils évaluaient la liste de réussite d'un programme, ils enregistraient la taille binaire résultante, puis sélectionnaient la liste de réussite de chaque programme qui produisait la plus petite taille binaire. Ils ont diffusé 22 milliards de compilations indépendantes, soit une moyenne de 4 877 par programme. 2. La liste des passes générée par la recherche aléatoire peut contenir des passes redondantes, qui n'ont aucun impact sur le résultat final. De plus, certaines commandes de laissez-passer sont interchangeables et la réorganisation n’affectera pas le résultat final. Étant donné que ceux-ci introduisent du bruit dans les données d’entraînement, ils ont développé un processus de minimisation et l’ont appliqué à chaque liste de réussite. La minimisation comprend trois étapes : l'élimination des passes redondantes, le tri des bulles et la recherche d'insertion. Lors de l'élimination des passes redondantes, ils minimisent la liste de passes optimale en supprimant de manière itérative les passes individuelles pour voir si elles contribuent à la taille binaire, et sinon, les ignorent. Répétez ce processus jusqu'à ce qu'aucune autre passe ne puisse être abandonnée. Le tri à bulles tente ensuite de fournir un classement unifié des sous-séquences de passes, en triant les passes en fonction de mots-clés. Enfin, le tri par insertion effectue une recherche locale en parcourant chaque passe de la liste de passes et en essayant d'insérer chacune des 167 passes de recherche qui la précèdent. Si cela améliore la taille binaire, conservez cette nouvelle liste de passes. L'ensemble du pipeline de minimisation est bouclé jusqu'à ce qu'un point fixe soit atteint. La distribution minimisée de la longueur de la liste de réussite est illustrée à la figure 9. La longueur moyenne de la liste de réussite est de 3,84.3. Ils appliquent la PassListEval décrite précédemment à la liste des meilleures réussites du candidat. De cette façon, ils ont identifié 167 971 sur 1 704 443 listes de passes uniques (9,85 %) qui provoqueraient des erreurs de compilation ou d'exécution 4. Ils ont diffusé les 100 listes de passes optimales les plus courantes à tous les programmes et les ont mises à jour. la meilleure liste de réussite pour chaque programme si des améliorations sont trouvées. Par la suite, le nombre total de listes uniques de meilleures passes a été réduit de 1 536 472 à 581 076. Le pipeline de réglage automatique ci-dessus a produit une réduction de 7,1 % de la taille binaire moyenne géométrique par rapport à -Oz. La figure 10 montre la fréquence d'un seul passage. Pour eux, ce réglage automatique sert de référence pour chaque optimisation de programme. Même si les économies de taille binaire constatées sont significatives, cela a nécessité 28 milliards de compilations supplémentaires pour un coût de calcul de plus de 21 000 jours CPU. L'objectif du réglage fin des instructions du FTD du compilateur LLM pour effectuer des tâches de réglage des indicateurs est d'atteindre une fraction des performances du réglage automatique sans avoir à exécuter le compilateur des milliers de fois. Ajustement des instructions pour le désassemblage Fait passer le code du langage assembleur à une structure de niveau supérieur qui peut exécuter des optimisations supplémentaires, telles que le code de bibliothèque intégré directement dans le code de l'application, ou le portage du code hérité vers nouvelle architecture. Le domaine de la décompilation a progressé dans l'application de techniques d'apprentissage automatique pour générer un code lisible et précis à partir d'exécutables binaires. Dans cette étude, l'équipe de recherche montre comment le LLM Compiler FTD peut effectuer un démontage grâce à un réglage fin, en apprenant la relation entre le code assembleur et l'IR du compilateur. La tâche consiste à apprendre la traduction inverse de clang -xir - -o - -S, comme le montre la figure 5. 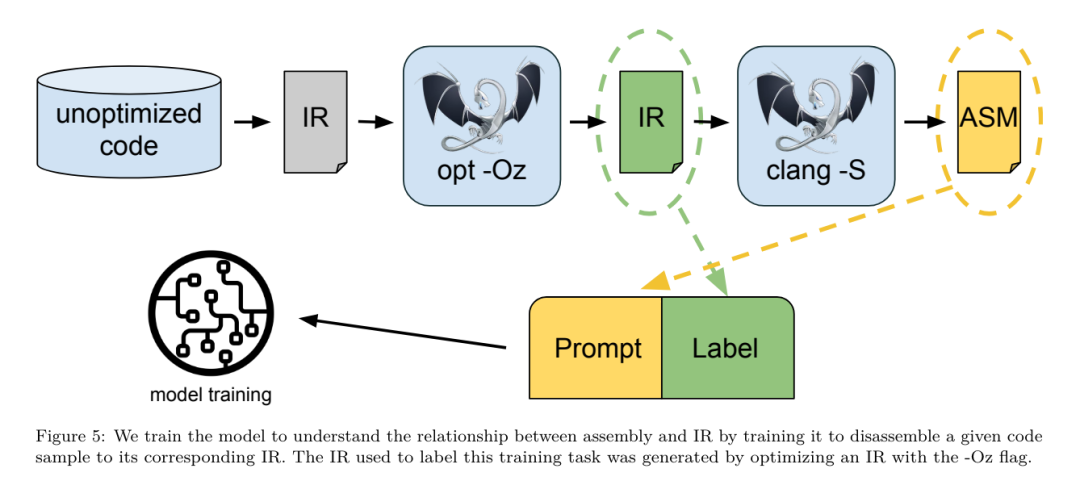 Test aller-retour. L'utilisation de LLM pour le démontage peut entraîner des problèmes d'exactitude. Le code boosté doit être vérifié avec un vérificateur d'équivalence, ce qui n'est pas toujours possible, ou nécessite une vérification manuelle de l'exactitude, ou suffisamment de cas de test pour gagner en confiance. Cependant, une limite inférieure d’exactitude peut être trouvée grâce à des tests aller-retour. Autrement dit, en recompilant l'IR levé en code assembleur, si le code assembleur est le même, l'IR est correct. Cela fournit un chemin simple pour utiliser les résultats du LLM et constitue un moyen simple de mesurer l’utilité du modèle désassemblé. Spécifications des tâches. L’équipe de recherche a alimenté le code d’assemblage du modèle et l’a entraîné à émettre les IR de désassemblage correspondants. La longueur du contexte pour cette tâche a été définie sur 8 000 jetons pour le code assembleur d'entrée et 8 000 jetons pour l'IR de sortie. ensemble de données. Ils ont dérivé le code assembleur et les paires IR de l'ensemble de données utilisé dans les tâches précédentes. Leur ensemble de données de réglage fin contient 4,7 millions d'échantillons et l'IR d'entrée a été optimisé à l'aide de -Oz avant d'être réduit à un assemblage x86. Paramètres d'entraînement Les données sont tokenisées via un codage par paire d'octets, en utilisant le même tokenizer que Code Llama, Llama et Llama 2. Ils utilisent les mêmes paramètres de formation pour les quatre phases de formation. Ils ont utilisé la plupart des mêmes paramètres d'entraînement que le modèle de base Code Llama, en utilisant l'optimiseur AdamW avec des valeurs de 0,9 et 0,95 pour β1 et β2. Ils ont utilisé une planification en cosinus avec une étape d'échauffement de 1 000 étapes et ont fixé le taux d'apprentissage final à 1/30 du taux d'apprentissage maximal. Par rapport au modèle de base Code Llama, l'équipe a augmenté la longueur du contexte d'une seule séquence de 4096 à 16384 mais a maintenu la taille du lot constante à 4 millions de jetons. Pour s'adapter à des contextes plus longs, ils ont fixé le taux d'apprentissage à 2e-5 et modifié les paramètres d'intégration de la position RoPE, où ils ont réinitialisé la fréquence à la valeur de base θ = 10 ^ 6. Ces paramètres sont cohérents avec une longue formation contextuelle du modèle de base Code Llama. L'équipe de recherche évalue les performances du modèle de compilateur LLM sur les tâches de réglage et de démontage des drapeaux, la simulation du compilateur, la prédiction du prochain jeton et les tâches d'ingénierie logicielle. Tâche de réglage du drapeauMéthode. Ils évaluent les performances de LLM Compiler FTD sur la tâche de réglage des indicateurs d'optimisation pour les programmes invisibles et les comparent avec GPT-4 Turbo et Code Llama - Instruct. Ils exécutent l'inférence sur chaque modèle et extraient une liste de passes d'optimisation de la sortie du modèle. Ils utilisent ensuite cette liste de passes pour optimiser un programme spécifique et enregistrer la taille binaire du programme lorsqu'il est optimisé avec -Oz. Pour GPT-4 Turbo et Code Llama - Instruct, ils ajoutent un suffixe après l'invite pour fournir un contexte supplémentaire pour décrire plus en détail le problème et le format de sortie attendu.Toutes les listes de réussite générées par le modèle sont vérifiées à l'aide de PassListEval, et -Oz est utilisé comme alternative si la vérification échoue. Pour vérifier davantage l'exactitude de la liste de réussite générée par le modèle, ils ont lié le binaire final du programme et testé différentiellement sa sortie par rapport à la sortie de référence optimisée à l'aide d'un pipeline d'optimisation conservateur -O2. Ensemble de données. L'équipe de recherche a mené l'évaluation à l'aide de 2 398 signaux de test extraits de la suite de référence MiBench. Pour générer ces indices, ils prennent les 713 unités de traduction qui composent les 24 benchmarks MiBench et génèrent des IR non optimisés à partir de chaque unité, puis les formatent en indices. Si les indices générés dépassent 15 000 jetons, ils utilisent llvm-extract pour diviser le module LLVM représentant cette unité de traduction en modules plus petits, un par fonction, ce qui donne 1 985 indices qui s'intègrent dans la fenêtre contextuelle de 15 000 jetons, laissant 443 unités de traduction. Ne convient pas. . Lors du calcul des scores de performance, ils ont utilisé -Oz pour les 443 unités de traduction exclues. Le tableau 10 résume les critères de référence.
Test aller-retour. L'utilisation de LLM pour le démontage peut entraîner des problèmes d'exactitude. Le code boosté doit être vérifié avec un vérificateur d'équivalence, ce qui n'est pas toujours possible, ou nécessite une vérification manuelle de l'exactitude, ou suffisamment de cas de test pour gagner en confiance. Cependant, une limite inférieure d’exactitude peut être trouvée grâce à des tests aller-retour. Autrement dit, en recompilant l'IR levé en code assembleur, si le code assembleur est le même, l'IR est correct. Cela fournit un chemin simple pour utiliser les résultats du LLM et constitue un moyen simple de mesurer l’utilité du modèle désassemblé. Spécifications des tâches. L’équipe de recherche a alimenté le code d’assemblage du modèle et l’a entraîné à émettre les IR de désassemblage correspondants. La longueur du contexte pour cette tâche a été définie sur 8 000 jetons pour le code assembleur d'entrée et 8 000 jetons pour l'IR de sortie. ensemble de données. Ils ont dérivé le code assembleur et les paires IR de l'ensemble de données utilisé dans les tâches précédentes. Leur ensemble de données de réglage fin contient 4,7 millions d'échantillons et l'IR d'entrée a été optimisé à l'aide de -Oz avant d'être réduit à un assemblage x86. Paramètres d'entraînement Les données sont tokenisées via un codage par paire d'octets, en utilisant le même tokenizer que Code Llama, Llama et Llama 2. Ils utilisent les mêmes paramètres de formation pour les quatre phases de formation. Ils ont utilisé la plupart des mêmes paramètres d'entraînement que le modèle de base Code Llama, en utilisant l'optimiseur AdamW avec des valeurs de 0,9 et 0,95 pour β1 et β2. Ils ont utilisé une planification en cosinus avec une étape d'échauffement de 1 000 étapes et ont fixé le taux d'apprentissage final à 1/30 du taux d'apprentissage maximal. Par rapport au modèle de base Code Llama, l'équipe a augmenté la longueur du contexte d'une seule séquence de 4096 à 16384 mais a maintenu la taille du lot constante à 4 millions de jetons. Pour s'adapter à des contextes plus longs, ils ont fixé le taux d'apprentissage à 2e-5 et modifié les paramètres d'intégration de la position RoPE, où ils ont réinitialisé la fréquence à la valeur de base θ = 10 ^ 6. Ces paramètres sont cohérents avec une longue formation contextuelle du modèle de base Code Llama. L'équipe de recherche évalue les performances du modèle de compilateur LLM sur les tâches de réglage et de démontage des drapeaux, la simulation du compilateur, la prédiction du prochain jeton et les tâches d'ingénierie logicielle. Tâche de réglage du drapeauMéthode. Ils évaluent les performances de LLM Compiler FTD sur la tâche de réglage des indicateurs d'optimisation pour les programmes invisibles et les comparent avec GPT-4 Turbo et Code Llama - Instruct. Ils exécutent l'inférence sur chaque modèle et extraient une liste de passes d'optimisation de la sortie du modèle. Ils utilisent ensuite cette liste de passes pour optimiser un programme spécifique et enregistrer la taille binaire du programme lorsqu'il est optimisé avec -Oz. Pour GPT-4 Turbo et Code Llama - Instruct, ils ajoutent un suffixe après l'invite pour fournir un contexte supplémentaire pour décrire plus en détail le problème et le format de sortie attendu.Toutes les listes de réussite générées par le modèle sont vérifiées à l'aide de PassListEval, et -Oz est utilisé comme alternative si la vérification échoue. Pour vérifier davantage l'exactitude de la liste de réussite générée par le modèle, ils ont lié le binaire final du programme et testé différentiellement sa sortie par rapport à la sortie de référence optimisée à l'aide d'un pipeline d'optimisation conservateur -O2. Ensemble de données. L'équipe de recherche a mené l'évaluation à l'aide de 2 398 signaux de test extraits de la suite de référence MiBench. Pour générer ces indices, ils prennent les 713 unités de traduction qui composent les 24 benchmarks MiBench et génèrent des IR non optimisés à partir de chaque unité, puis les formatent en indices. Si les indices générés dépassent 15 000 jetons, ils utilisent llvm-extract pour diviser le module LLVM représentant cette unité de traduction en modules plus petits, un par fonction, ce qui donne 1 985 indices qui s'intègrent dans la fenêtre contextuelle de 15 000 jetons, laissant 443 unités de traduction. Ne convient pas. . Lors du calcul des scores de performance, ils ont utilisé -Oz pour les 443 unités de traduction exclues. Le tableau 10 résume les critères de référence. 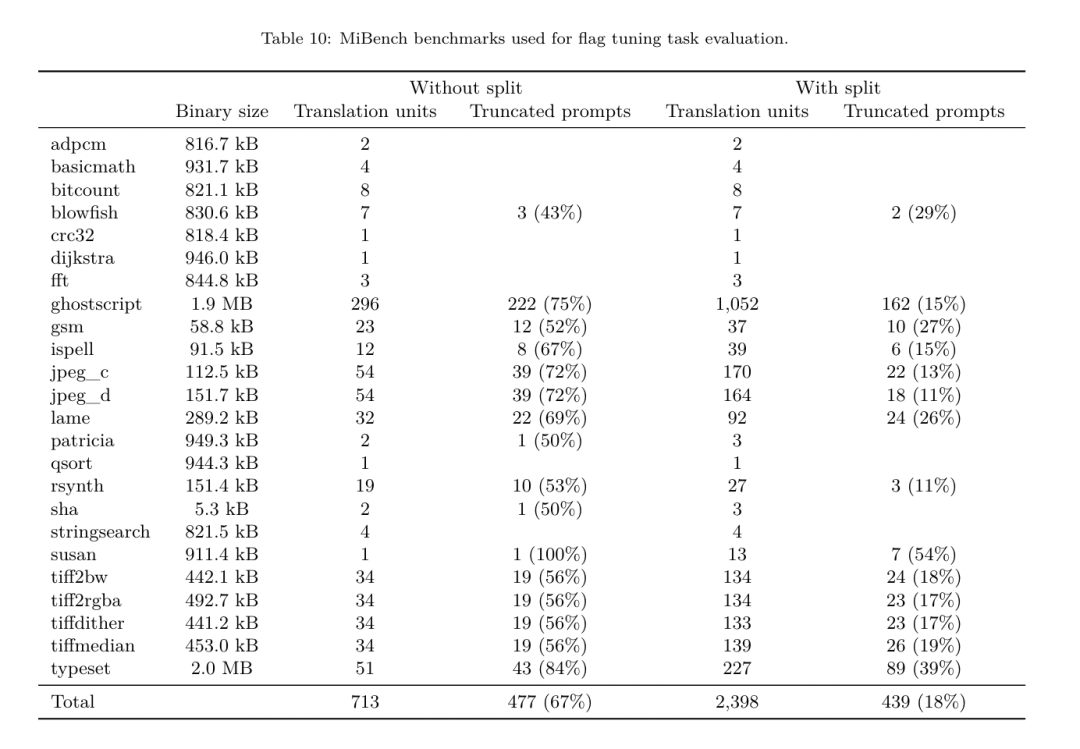 Résultats. Le tableau 3 montre les performances sans tir de tous les modèles lors de la tâche de réglage du drapeau. Seul le modèle FTD du compilateur LLM s'est amélioré par rapport à -Oz, le modèle de paramètres 13B surpassant légèrement le modèle plus petit, produisant des fichiers objets plus petits que -Oz 61 % du temps.
Résultats. Le tableau 3 montre les performances sans tir de tous les modèles lors de la tâche de réglage du drapeau. Seul le modèle FTD du compilateur LLM s'est amélioré par rapport à -Oz, le modèle de paramètres 13B surpassant légèrement le modèle plus petit, produisant des fichiers objets plus petits que -Oz 61 % du temps. 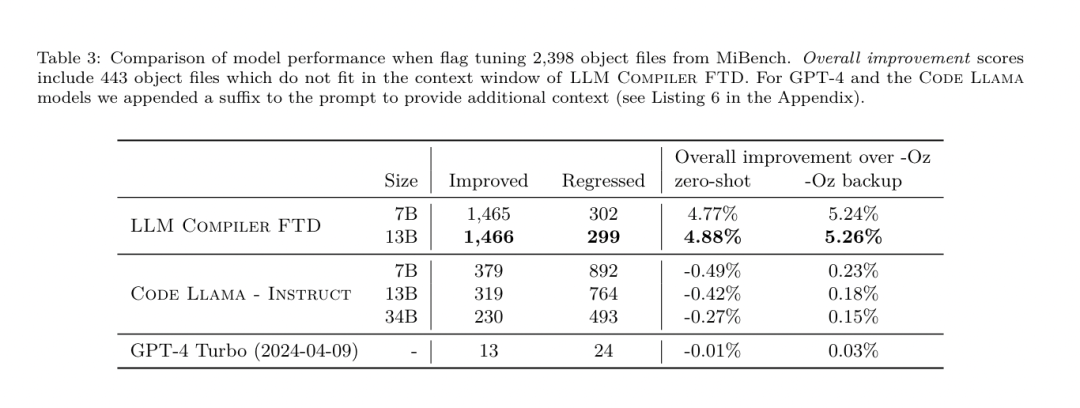 Dans certains cas, la liste de réussite générée par le modèle a abouti à une taille de fichier cible plus grande que -Oz. Par exemple, le LLM Compiler FTD 13B présente une dégradation dans 12 % des cas. Ces dégradations peuvent être évitées en compilant simplement le programme deux fois : une fois avec la liste de passes générée par le modèle, et une fois avec -Oz, puis en sélectionnant la liste de passes qui donne les meilleurs résultats. En éliminant la dégradation par rapport à -Oz, ces scores de sauvegarde -Oz augmentent l'amélioration globale du LLM Compiler FTD 13B par rapport à -Oz à 5,26 % et permettent à Code Llama - Instruct et GPT-4 Turbo d'obtenir des améliorations modestes par rapport à -Oz . La figure 6 montre la répartition des performances de chaque modèle sur différents benchmarks.
Dans certains cas, la liste de réussite générée par le modèle a abouti à une taille de fichier cible plus grande que -Oz. Par exemple, le LLM Compiler FTD 13B présente une dégradation dans 12 % des cas. Ces dégradations peuvent être évitées en compilant simplement le programme deux fois : une fois avec la liste de passes générée par le modèle, et une fois avec -Oz, puis en sélectionnant la liste de passes qui donne les meilleurs résultats. En éliminant la dégradation par rapport à -Oz, ces scores de sauvegarde -Oz augmentent l'amélioration globale du LLM Compiler FTD 13B par rapport à -Oz à 5,26 % et permettent à Code Llama - Instruct et GPT-4 Turbo d'obtenir des améliorations modestes par rapport à -Oz . La figure 6 montre la répartition des performances de chaque modèle sur différents benchmarks. 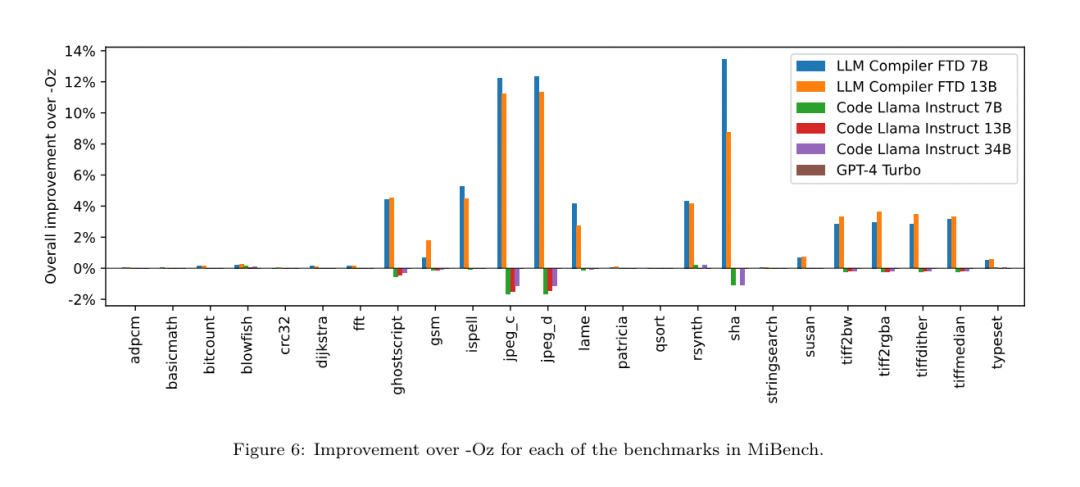 Précision de la taille binaire. Bien que les prédictions de taille binaire générées par le modèle n'aient aucun impact sur la compilation réelle, l'équipe de recherche peut évaluer les performances du modèle en matière de prédiction de la taille binaire avant et après l'optimisation pour comprendre dans quelle mesure chaque modèle comprend l'optimisation. La figure 7 montre les résultats. Les prédictions de taille binaire du compilateur LLM FTD sont bien corrélées à la situation réelle, le modèle de paramètres 7B atteignant les valeurs MAPE de 0,083 et 0,225 pour les tailles binaires non optimisées et optimisées, respectivement. Les valeurs MAPE pour le modèle de paramètres 13B étaient similaires, respectivement 0,082 et 0,225. Les prédictions de taille binaire de Code Llama - Instruct et GPT-4 Turbo ont peu de corrélation avec la réalité. Les chercheurs ont remarqué que LLM Compiler FTD présentait des erreurs légèrement plus élevées pour le code optimisé que pour le code non optimisé. En particulier, LLM Compiler FTD a parfois tendance à surestimer l'efficacité de l'optimisation, ce qui entraîne des tailles binaires prévues inférieures à ce qu'elles sont réellement.
Précision de la taille binaire. Bien que les prédictions de taille binaire générées par le modèle n'aient aucun impact sur la compilation réelle, l'équipe de recherche peut évaluer les performances du modèle en matière de prédiction de la taille binaire avant et après l'optimisation pour comprendre dans quelle mesure chaque modèle comprend l'optimisation. La figure 7 montre les résultats. Les prédictions de taille binaire du compilateur LLM FTD sont bien corrélées à la situation réelle, le modèle de paramètres 7B atteignant les valeurs MAPE de 0,083 et 0,225 pour les tailles binaires non optimisées et optimisées, respectivement. Les valeurs MAPE pour le modèle de paramètres 13B étaient similaires, respectivement 0,082 et 0,225. Les prédictions de taille binaire de Code Llama - Instruct et GPT-4 Turbo ont peu de corrélation avec la réalité. Les chercheurs ont remarqué que LLM Compiler FTD présentait des erreurs légèrement plus élevées pour le code optimisé que pour le code non optimisé. En particulier, LLM Compiler FTD a parfois tendance à surestimer l'efficacité de l'optimisation, ce qui entraîne des tailles binaires prévues inférieures à ce qu'elles sont réellement.  Recherche sur l'ablation. Le tableau 4 présente une étude d'ablation des performances du modèle sur un petit ensemble de validation de 500 indices provenant de la même distribution que leurs données d'entraînement (mais non utilisés dans l'entraînement). Ils ont effectué une formation adaptée aux drapeaux à chaque étape du pipeline de formation illustré à la figure 1 pour comparer les performances. Comme indiqué, la formation au démontage a entraîné une légère baisse des performances, passant d'une moyenne de 5,15 % à 5,12 % (amélioration par rapport à -Oz). Ils démontrent également les performances de l'autotuner utilisé pour générer les données de formation décrites dans la section 2. LLM Compiler FTD atteint 77% des performances de l'autotuner.
Recherche sur l'ablation. Le tableau 4 présente une étude d'ablation des performances du modèle sur un petit ensemble de validation de 500 indices provenant de la même distribution que leurs données d'entraînement (mais non utilisés dans l'entraînement). Ils ont effectué une formation adaptée aux drapeaux à chaque étape du pipeline de formation illustré à la figure 1 pour comparer les performances. Comme indiqué, la formation au démontage a entraîné une légère baisse des performances, passant d'une moyenne de 5,15 % à 5,12 % (amélioration par rapport à -Oz). Ils démontrent également les performances de l'autotuner utilisé pour générer les données de formation décrites dans la section 2. LLM Compiler FTD atteint 77% des performances de l'autotuner. Tâche de démontage
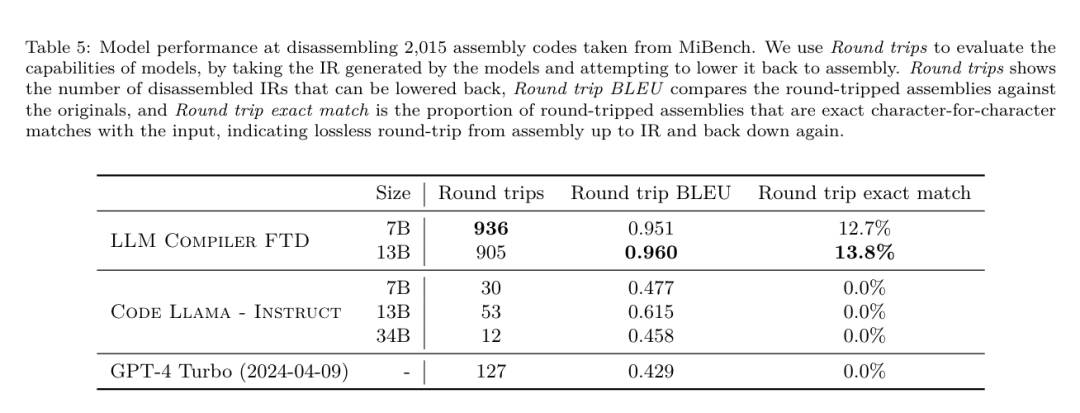
méthode. L'équipe de recherche évalue l'exactitude fonctionnelle du code généré par LLM lors du désassemblage du code assembleur dans LLVM-IR. Ils évaluent LLM Compiler FTD et le comparent avec Code Llama - Instruct et GPT-4 Turbo et constatent que des suffixes d'indices supplémentaires sont nécessaires pour extraire les meilleures performances de ces modèles. Le suffixe fournit un contexte supplémentaire sur la tâche et le format de sortie attendu. Pour évaluer les performances du modèle, ils ont rétrogradé l'IR de démontage généré par le modèle en assemblage. Cela nous permet d'évaluer la précision du démontage en comparant les scores BLEU de l'assemblage d'origine avec les résultats aller-retour.Un démontage parfait sans perte de l'assemblage à l'IR aura un score BLEU aller-retour de 1,0 (correspondance exacte).
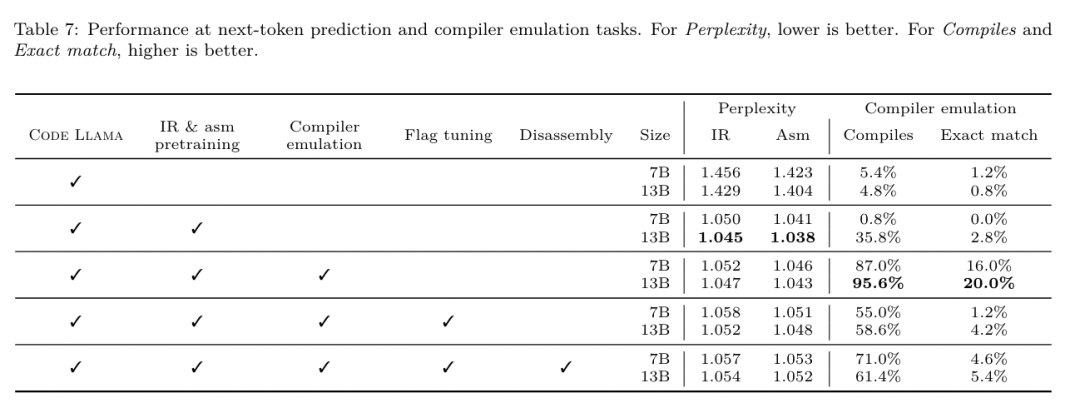
Ensemble de données. Ils ont évalué à l'aide de 2 015 indices de test extraits de la suite de référence MiBench, en prenant les 2 398 unités de traduction utilisées pour l'évaluation de réglage des drapeaux ci-dessus, pour générer des indices de désassemblage. Ils ont ensuite filtré les astuces en fonction de la longueur maximale de 8 000 jetons, autorisant 8 000 jetons pour la sortie du modèle, ce qui en laisse 2 015. Le tableau 11 résume les critères de référence. Résultats. Le tableau 5 montre les performances du modèle sur la tâche de démontage. Le compilateur LLM FTD 7B a un taux de réussite aller-retour légèrement plus élevé que le compilateur LLM FTD 13B, mais le compilateur LLM FTD 13B a la précision d'assemblage aller-retour la plus élevée (BLEU aller-retour) et produit le plus souvent des démontages parfaits ( correspondance exacte aller-retour). Code Llama - Instruct et GPT-4 Turbo ont des difficultés à générer un LLVM-IR syntaxiquement correct. La figure 8 montre la distribution des scores BLEU aller-retour pour tous les modèles. Recherche sur l'ablation. Le tableau 6 présente une étude d'ablation des performances du modèle sur un petit ensemble de validation de 500 indices, tiré de l'ensemble de données MiBench utilisé précédemment. Ils ont effectué une formation au démontage à chaque étape du pipeline de formation illustré à la figure 1 pour comparer les performances. Le taux d'aller-retour est le plus élevé lorsque l'on parcourt l'ensemble de la pile de données de formation et continue de diminuer à chaque étape de formation, bien que le BLEU aller-retour change peu à chaque étape. méthode. L'équipe de recherche a mené des recherches sur l'ablation sur le modèle LLM Compiler sur deux tâches de base du modèle : la prédiction du prochain jeton et la simulation du compilateur. Ils effectuent cette évaluation à chaque étape du pipeline de formation pour comprendre comment la formation pour chaque tâche successive affecte les performances. Pour la prochaine prédiction de jeton, ils calculent la perplexité sur un petit échantillon de LLVM-IR et de code assembleur à tous les niveaux d'optimisation. Ils évaluent les simulations du compilateur à l'aide de deux mesures : si le code IR ou assembleur généré se compile, et si le code IR ou assembleur généré correspond exactement à ce que produit le compilateur. Ensemble de données. Pour la prédiction du prochain jeton, ils utilisent un petit ensemble de données de validation de la même distribution que nos données de formation, mais non utilisé pour la formation. Ils utilisent un mélange de niveaux d'optimisation, notamment du code non optimisé, du code optimisé avec -Oz et des listes de réussite générées aléatoirement. Pour les simulations du compilateur, elles ont été évaluées à l'aide de 500 astuces générées à partir de MiBench à l'aide de listes de réussite générées aléatoirement de la manière décrite dans la section 2.2. Résultats. Le tableau 7 montre les performances de LLM Compiler FTD sur deux tâches de formation du modèle de base (prochaine prédiction de jeton et simulation du compilateur) à toutes les étapes de formation. Les performances de prédiction du prochain jeton augmentent fortement après Code Llama, qui voit à peine l'IR et l'assemblage, et diminuent légèrement à chaque étape de réglage ultérieur. Pour les simulations du compilateur, le modèle de base Code Llama et les modèles pré-entraînés ne fonctionnent pas bien car ils ne sont pas formés à cette tâche. Les performances maximales sont obtenues directement après la formation en simulation du compilateur, où 95,6 % des IR et des assemblys générés par le compilateur LLM FTD 13B se compilent et 20 % correspondent exactement au compilateur. Après avoir effectué le réglage des drapeaux et le réglage fin du démontage, les performances ont chuté. Méthodes. Bien que l'objectif de LLM Compiler FTD soit de fournir un modèle de base pour l'optimisation du code, il est construit sur le modèle de base Code Llama formé pour les tâches d'ingénierie logicielle. Pour évaluer comment une formation supplémentaire de LLM Compiler FTD affecte les performances de génération de code, ils ont utilisé la même suite de tests que Code Llama pour évaluer la capacité de LLM à générer du code Python à partir d'invites en langage naturel, telles que « Écrivez une fonction qui trouve la chaîne la plus longue. formé de paires d'ensembles. Ils utilisent les benchmarks HumanEval et MBPP, les mêmes que Code Llama. Résultats. Le tableau 8 montre les performances de décodage gloutons (pass@1) pour toutes les étapes de formation du modèle et toutes les tailles de modèle à partir du modèle de base Code Llama.Il montre également les scores du modèle sur pass@10 et pass@100, qui ont été générés avec p=0,95 et température=0,6. Chaque phase de formation centrée sur le compilateur entraîne une légère dégradation des capacités de programmation Python. Sur HumanEval et MBPP, les performances pass@1 du compilateur LLM ont chuté jusqu'à 18 % et 5 %, et le FTD du compilateur LLM a chuté jusqu'à 29 % et 22 % après un réglage supplémentaire des indicateurs et un réglage fin du désassemblage. Tous les modèles surpassent toujours Llama 2 dans les deux tâches. 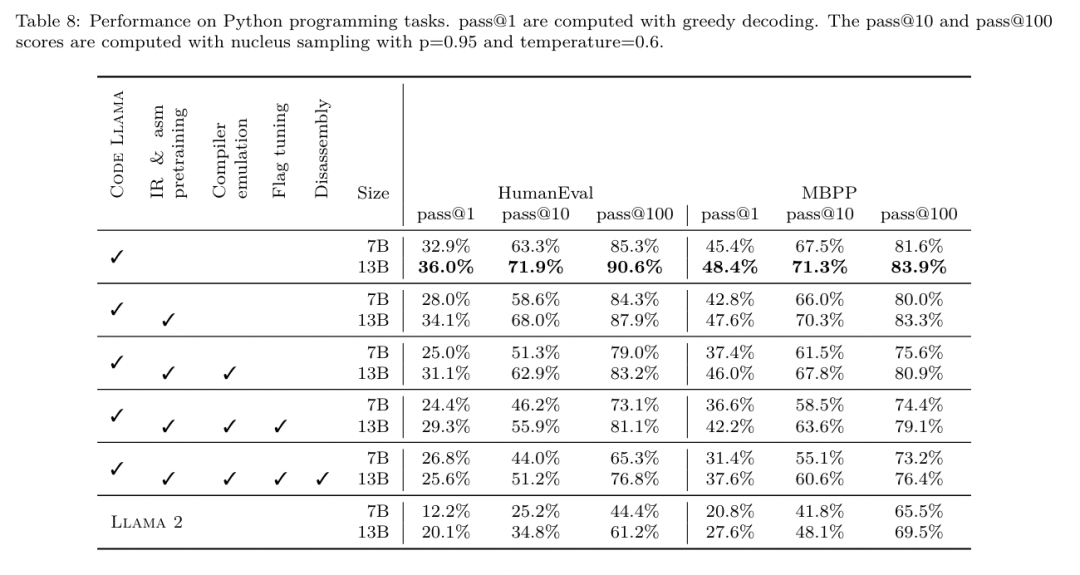 L'équipe de recherche Meta a démontré que LLM Compiler fonctionne bien sur les tâches d'optimisation du compilateur et offre une meilleure compréhension de la représentation du compilateur et du code d'assemblage par rapport aux travaux précédents, mais il existe encore certaines limites. La principale limitation est la longueur limitée de la séquence d'entrée (fenêtre contextuelle). Le compilateur LLM prend en charge une fenêtre contextuelle de 16 000 jetons, mais le code du programme peut être beaucoup plus long que cela. Par exemple, lorsqu'elles sont formatées comme une astuce de réglage des indicateurs, 67 % des unités de traduction MiBench ont dépassé cette fenêtre contextuelle, comme le montre le tableau 10. Pour atténuer ce problème, ils divisent les unités de traduction les plus grandes en fonctions distinctes, bien que cela limite la portée de l'optimisation qui peut être effectuée, et 18 % des unités de traduction divisées sont toujours trop grandes pour que le modèle soit trop grand. être accepté comme entrée. Les chercheurs utilisent des fenêtres contextuelles de plus en plus nombreuses, mais les fenêtres contextuelles limitées restent un problème courant en LLM. La deuxième limitation, et un problème commun à tous les LLM, est la précision de la sortie du modèle. Il est recommandé aux utilisateurs de LLM Compiler d'évaluer leurs modèles à l'aide de critères d'évaluation spécifiques au compilateur. Étant donné que les compilateurs ne sont pas exempts de bogues, toute optimisation proposée du compilateur doit être rigoureusement testée. Lorsqu'un modèle est décompilé en code assembleur, son exactitude doit être confirmée par un aller-retour, une inspection manuelle ou des tests unitaires. Pour certaines applications, la génération LLM peut être limitée aux expressions régulières ou combinée à une validation automatique pour garantir l'exactitude. https://x.com/AIatMeta/status/1806361623831171318
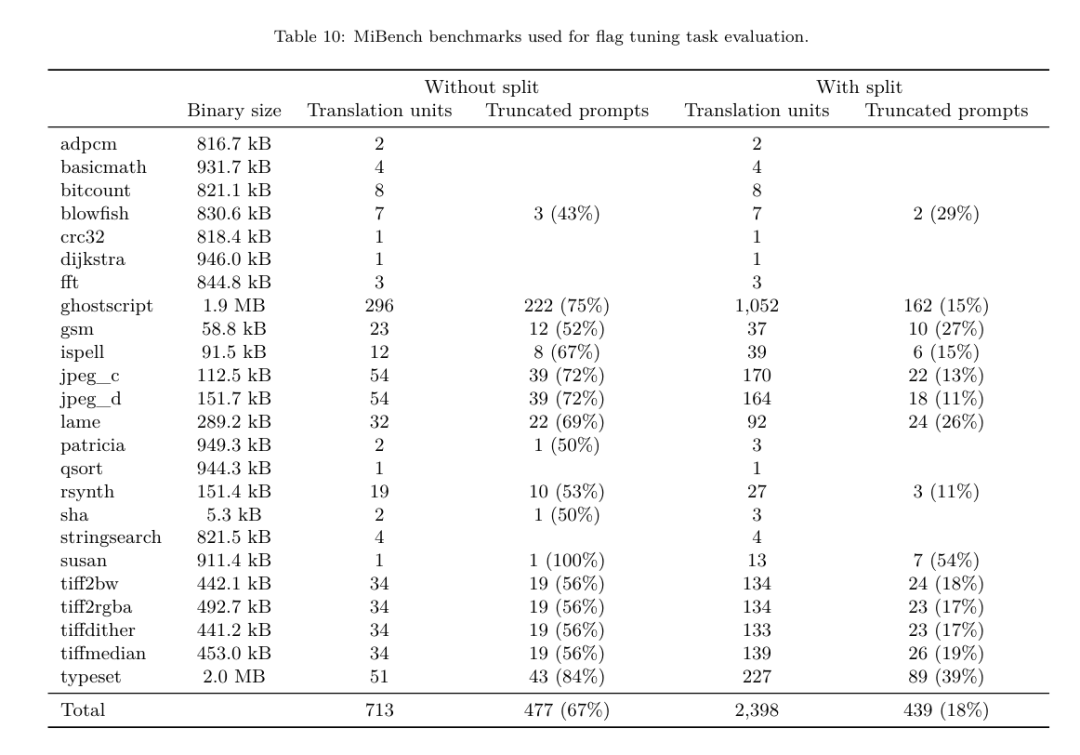
L'équipe de recherche Meta a démontré que LLM Compiler fonctionne bien sur les tâches d'optimisation du compilateur et offre une meilleure compréhension de la représentation du compilateur et du code d'assemblage par rapport aux travaux précédents, mais il existe encore certaines limites. La principale limitation est la longueur limitée de la séquence d'entrée (fenêtre contextuelle). Le compilateur LLM prend en charge une fenêtre contextuelle de 16 000 jetons, mais le code du programme peut être beaucoup plus long que cela. Par exemple, lorsqu'elles sont formatées comme une astuce de réglage des indicateurs, 67 % des unités de traduction MiBench ont dépassé cette fenêtre contextuelle, comme le montre le tableau 10. Pour atténuer ce problème, ils divisent les unités de traduction les plus grandes en fonctions distinctes, bien que cela limite la portée de l'optimisation qui peut être effectuée, et 18 % des unités de traduction divisées sont toujours trop grandes pour que le modèle soit trop grand. être accepté comme entrée. Les chercheurs utilisent des fenêtres contextuelles de plus en plus nombreuses, mais les fenêtres contextuelles limitées restent un problème courant en LLM. La deuxième limitation, et un problème commun à tous les LLM, est la précision de la sortie du modèle. Il est recommandé aux utilisateurs de LLM Compiler d'évaluer leurs modèles à l'aide de critères d'évaluation spécifiques au compilateur. Étant donné que les compilateurs ne sont pas exempts de bogues, toute optimisation proposée du compilateur doit être rigoureusement testée. Lorsqu'un modèle est décompilé en code assembleur, son exactitude doit être confirmée par un aller-retour, une inspection manuelle ou des tests unitaires. Pour certaines applications, la génération LLM peut être limitée aux expressions régulières ou combinée à une validation automatique pour garantir l'exactitude. https://x.com/AIatMeta/status/1806361623831171318
https://ai.meta.com / recherche/publications/méta -grand-langage-model-compiler-foundation-models-of-compiler-optimization/?utm_source=twitter&utm_medium=organic_social&utm_content=link&utm_campaign=fairCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!











 Quels programmes peuvent être développés avec php
Quels programmes peuvent être développés avec php
 Solution 0x80070002
Solution 0x80070002
 La pièce d'or Toutiao d'aujourd'hui est égale à 1 yuan
La pièce d'or Toutiao d'aujourd'hui est égale à 1 yuan
 Comment résoudre le problème selon lequel le logiciel antivirus Win11 ne peut pas être ouvert
Comment résoudre le problème selon lequel le logiciel antivirus Win11 ne peut pas être ouvert
 Que signifie formater un téléphone mobile ?
Que signifie formater un téléphone mobile ?
 Comment intégrer des styles CSS dans HTML
Comment intégrer des styles CSS dans HTML
 vscode
vscode
 Que dois-je faire si le paramètre de redémarrage chinois de vscode ne prend pas effet ?
Que dois-je faire si le paramètre de redémarrage chinois de vscode ne prend pas effet ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



