La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
L'équipe d'auteurs de cet article vient du Centre de recherche en informatique sociale et en recherche d'informations de l'Institut de technologie de Harbin. Zheng Zihao, Zhang Zihan, Wang Zexin, Fu Rui Ji, Liu Ming, Wang Zhongyuan, Qin Bing. Représentation multimodaleLa reconnaissance multimodale d'entités nommées, en tant que tâche fondamentale et clé dans la création de graphiques de connaissances multimodaux, nécessite que les chercheurs intègrent plusieurs informations modales pour extraire avec précision les entités nommées du texte. Bien que des recherches antérieures aient exploré les méthodes d'intégration de représentations multimodales à différents niveaux, elles sont encore insuffisantes pour fusionner ces représentations multimodales pour fournir des informations contextuelles riches et ainsi améliorer les performances de reconnaissance d'entités nommées multimodales. Dans cet article, l'équipe de recherche propose DPE-MNER, un cadre de raisonnement itératif innovant qui suit la stratégie « décomposer, prioriser, éliminer » et intègre dynamiquement diverses représentations multimodales. Ce cadre décompose intelligemment la fusion des représentations multimodales en couches de fusion hiérarchiques et interconnectées, simplifiant considérablement le processus de traitement. Lors de l'intégration de l'information multimodale, l'équipe a mis un accent particulier sur les transitions progressives du « simple au complexe » et du « macro au micro ». De plus, en modélisant explicitement les corrélations intermodales, l’équipe de recherche exclut efficacement les informations non pertinentes susceptibles d’induire en erreur les prédictions du MNER. Grâce à des expériences approfondies sur deux ensembles de données publiques, la méthode de l'équipe de recherche s'est avérée considérablement efficace pour améliorer la précision et l'efficacité de la reconnaissance multimodale d'entités nommées. Cet article fait partie des dix meilleurs papiers candidats parmi 1558 papiers acceptés pour le LREC-COLING 2024. 
Un exemple de reconnaissance d'entités nommées multimodale. L'équipe de recherche a démontré une variété de représentations multimodales qui peuvent être utiles pour les décisions de reconnaissance d'entités nommées. Les humains traitent généralement ces informations mentalement de manière itérative. Pour répondre à cette problématique, l'équipe de recherche s'est inspirée du domaine de la Résolution de problèmes complexes (Sternberg et Frensch, 1992). Ce domaine se concentre sur l'étude des méthodes et des stratégies utilisées par les humains et les ordinateurs pour résoudre des problèmes impliquant plusieurs variables, une incertitude et une grande complexité. Premièrement, ils pensent que face à des problèmes complexes, les humains adoptent généralement une approche itérative. Comme le montre la figure, l’équipe de recherche utilise en fait un processus itératif lorsqu’elle traite du MNER. Deuxièmement, les humains utilisent des stratégies spécifiques pour simplifier ces problèmes, telles que la décomposition, la priorisation et l’élimination des facteurs non pertinents. L'équipe de recherche estime que traiter la reconnaissance multimodale d'entités nommées (MNER) comme un processus itératif d'intégration d'informations multimodales et d'utiliser ces stratégies est très approprié pour les tâches MNER. Par rapport aux méthodes en une seule étape, les méthodes en plusieurs étapes peuvent exploiter de manière plus complète diverses représentations multimodales dans le processus d'optimisation itérative des résultats de reconnaissance d'entités nommées (NER). De plus, ces trois stratégies sont très adaptées à l'intégration de représentations multiples dans un NER multimodal :
- La stratégie de décomposition nous encourage à diviser la fusion de représentations multimodales en plus petites, Des unités plus facilement manipulables, capables d'explorer les interactions multimodales à différents niveaux de granularité.
- La stratégie de priorisation recommande d'intégrer les informations multimodales selon l'ordre de « facile à difficile » et de « grossier à fin » ; cette intégration progressive contribue à l'optimisation étape par étape des prédictions MNER ; Cela permet au modèle de déplacer progressivement son attention des informations simples mais grossières vers des détails complexes mais précis.
- La stratégie d'élimination des non-pertinences nous incite à filtrer et exclure explicitement les informations non pertinentes dans différentes représentations multimodales ; cela peut éliminer les informations non pertinentes qui peuvent affecter les performances du MNER.
L'équipe de recherche a conçu un cadre d'extraction d'entités multimodales itératives qui fusionne dynamiquement plusieurs fonctionnalités multimodales, qui comprend un processus itératif et un réseau de prédiction.
Modélisation itérative MNERL'équipe de recherche a suivi le modèle de diffusion pour modéliser la reconnaissance d'objets, l'alignement visuel et l'extraction d'entités de texte en tant que processus de débruitage itératif, et a également utilisé le modèle de diffusion pour combiner l'extraction d'entités multimodales. est modélisé comme un processus itératif. Le modèle initialise d'abord de manière aléatoire une série d'intervalles d'entité et utilise un réseau de prédiction pour coder des caractéristiques multimodales afin de débruiter de manière itérative pendant le processus de débruitage afin d'obtenir les intervalles d'entité corrects dans le texte. Comme le montre la figure, l'équipe de recherche a obtenu un total de trois représentations granulaires dans le texte , deux granularités et deux difficultés dans l'image (ils pensent que l'alignement Les représentations sont des représentations simples, les représentations mal alignées sont des représentations difficiles) . Le réseau de prédiction de l'équipe AMRN comprend un réseau de codage (DMMF) et un réseau de décodage (MER). La conception du réseau de prédiction repose sur les trois stratégies mentionnées précédemment. Comme le montre la figure, le réseau de codage est un réseau de fusion hiérarchique qui fusionne et décompose plusieurs fonctionnalités multimodales en un processus hiérarchique. Le processus ascendant consiste d'abord à intégrer les caractéristiques de l'image de même granularité et de difficulté différente dans les caractéristiques du texte $x_i$ de chaque granularité, puis d'intégrer les caractéristiques de l'image $Y$ de différentes granularités dans les caractéristiques du texte de chaque granularité. , et enfin intégrer les différentes caractéristiques de granularité $Y$ dans les caractéristiques de texte de chaque granularité. Les caractéristiques d'image Y et les caractéristiques de texte X sont fusionnées pour obtenir la représentation multimodale finale. Entrée dans le réseau de décodage pour décodage, et le réseau de décodage obtient de nouveaux intervalles et le type d'entité de chaque intervalle. Fusion sous-jacente. Cette couche d'équipe de recherche intègre des caractéristiques d'image d'une certaine granularité dans des caractéristiques de texte d'une certaine granularité. Selon le processus de diffusion, l'équipe de recherche peut obtenir un planificateur qui peut refléter l'état de l'itération en cours, ce qui est également la clé pour introduire la
priorité. Sur la base de ce planificateur, l'équipe de recherche a fusionné les caractéristiques de l'image de différentes difficultés pour obtenir la et la corrélation rel, qui est utilisée pour éliminer les informations non pertinentes. Enfin, un transformateur de goulot d'étranglement est utilisé sur la base de cette corrélation pour fusionner et , et une représentation multimodale de fusion d'images et de textes d'une certaine granularité est obtenue. Fusion de couche intermédiaire.L'équipe de recherche de cette couche fusionne les caractéristiques de l'image de différentes granularités en caractéristiques de texte d'une certaine granularité, c'est-à-dire la fusion
. Au niveau de cette couche, nous utilisons un planificateur pour fusionner dynamiquement les caractéristiques de l'image de différentes granularités afin d'obtenir une représentation textuelle multimodale d'une certaine granularité
.
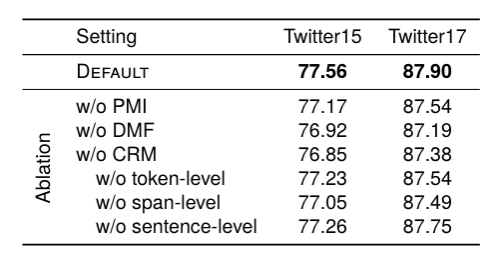
Top fusion. L'équipe de recherche de cette couche fusionne des représentations textuelles multimodales de différentes granularités en représentations par intervalles pour obtenir une représentation textuelle multimodale totale , qui est entrée dans le réseau de décodage à des fins de prédiction. L'équipe de l'auteur a comparé certaines méthodes typiques du MNER. Les résultats expérimentaux montrent que cette méthode atteint les meilleures performances sur deux ensembles de données couramment utilisés. Les chercheurs ont supprimé les conceptions de priorisation, hiérarchiques et d'élimination dans notre article pour observer les performances du modèle. Les résultats ont montré que la suppression de chaque conception entraînait une dégradation des performances. Comparaison avec les méthodes de fusion de fonctionnalités statiquesIls ont comparé certaines méthodes de fusion multimodales statiques typiques, telles que le pooling maximum, le pooling moyen, les méthodes basées sur MLP et MoE. Les résultats montrent que le cadre de fusion dynamique proposé peut atteindre les meilleures performances.
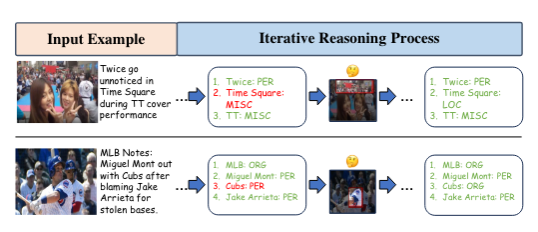
Analyse d'échantillons typiquesL'équipe de recherche a sélectionné deux échantillons représentatifs pour illustrer le processus itératif. On peut voir que lors de la première étape d'itération, les types de carrés temporels et de cubes ont été prédits de manière incorrecte ; cependant, sur la base des indices de caractéristiques importants de l'image, ils ont été corrigés de manière itérative pour obtenir le type d'entité correct. Cet article vise à utiliser pleinement le potentiel de diverses représentations multimodales dans le domaine de la reconnaissance multimodale d'entités nommées (MNER), afin d'obtenir d'excellents résultats de reconnaissance. À cette fin, les auteurs ont conçu et proposé un cadre de raisonnement itératif innovant : le DPE-MNER. DPE-MNER simplifie intelligemment le processus d'intégration de ces représentations multimodales riches et diverses en décomposant la tâche MNER en plusieurs étapes. Dans ce processus itératif, les représentations multimodales réalisent une fusion et une intégration dynamiques basées sur la stratégie de « décomposition, priorisation et élimination ». Grâce à une série de vérifications expérimentales rigoureuses, l’équipe de recherche a pleinement démontré les effets remarquables et les performances supérieures du cadre DPE-MNER. [1] Les Knowledge Graphs rencontrent l'apprentissage multimodal : enquête complète, arxiv[2] Décomposer, hiérarchiser et éliminer dynamiquement : En intégrant Divers Représentations pour la reconnaissance multimodale d'entités nommées, 2024, Conférence internationale conjointe sur la linguistique informatique, les ressources linguistiques et l'évaluation[3] Résolution de problèmes complexes : principes et mécanismes, 1992, American Journal of Psycholog [4] DiffusionNER : Diffusion aux limites pour la reconnaissance d'entités nommées, ACL23 [5] DiffusionDet : Modèle de diffusion pour la détection d'objets, ICCV23[6] Modèle de diffusion guidé par le langage pour le sol visuel ing , arxiv23Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!






 et utilise un réseau de prédiction pour coder des caractéristiques multimodales afin de débruiter de manière itérative pendant le processus de débruitage afin d'obtenir les intervalles d'entité corrects
et utilise un réseau de prédiction pour coder des caractéristiques multimodales afin de débruiter de manière itérative pendant le processus de débruitage afin d'obtenir les intervalles d'entité corrects  dans le texte.
dans le texte. 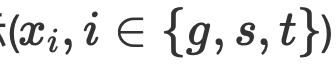 , deux granularités et deux difficultés dans l'image (ils pensent que l'alignement Les représentations sont des représentations simples, les représentations mal alignées sont des représentations difficiles)
, deux granularités et deux difficultés dans l'image (ils pensent que l'alignement Les représentations sont des représentations simples, les représentations mal alignées sont des représentations difficiles) 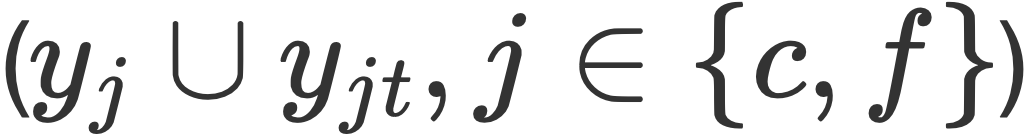 . Le réseau de prédiction de l'équipe AMRN comprend un réseau de codage (DMMF) et un réseau de décodage (MER). La conception du réseau de prédiction repose sur les trois stratégies mentionnées précédemment.
. Le réseau de prédiction de l'équipe AMRN comprend un réseau de codage (DMMF) et un réseau de décodage (MER). La conception du réseau de prédiction repose sur les trois stratégies mentionnées précédemment. 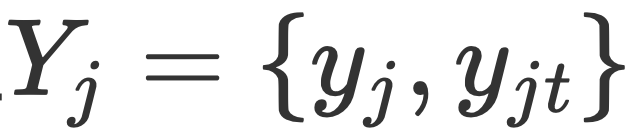 de chaque granularité. Les caractéristiques d'image
de chaque granularité. Les caractéristiques d'image  Y et les caractéristiques de texte X sont fusionnées pour obtenir la représentation multimodale finale. Entrée dans le réseau de décodage pour décodage, et le réseau de décodage obtient de nouveaux intervalles et le type d'entité de chaque intervalle.
Y et les caractéristiques de texte X sont fusionnées pour obtenir la représentation multimodale finale. Entrée dans le réseau de décodage pour décodage, et le réseau de décodage obtient de nouveaux intervalles et le type d'entité de chaque intervalle. 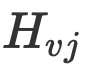 corrélation
corrélation 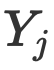 rel, qui est utilisée pour éliminer les informations non pertinentes. Enfin, un transformateur de goulot d'étranglement est utilisé sur la base de cette corrélation pour fusionner et
rel, qui est utilisée pour éliminer les informations non pertinentes. Enfin, un transformateur de goulot d'étranglement est utilisé sur la base de cette corrélation pour fusionner et  , et une représentation multimodale de fusion d'images et de textes
, et une représentation multimodale de fusion d'images et de textes  d'une certaine granularité est obtenue.
d'une certaine granularité est obtenue. 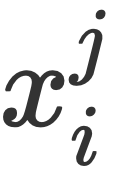
 . Au niveau de cette couche, nous utilisons un planificateur pour fusionner dynamiquement les caractéristiques de l'image de différentes granularités afin d'obtenir une représentation textuelle multimodale d'une certaine granularité
. Au niveau de cette couche, nous utilisons un planificateur pour fusionner dynamiquement les caractéristiques de l'image de différentes granularités afin d'obtenir une représentation textuelle multimodale d'une certaine granularité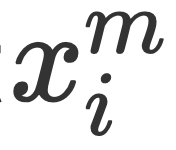 .
.  de différentes granularités en représentations par intervalles pour obtenir une représentation textuelle multimodale totale
de différentes granularités en représentations par intervalles pour obtenir une représentation textuelle multimodale totale 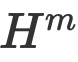 , qui est entrée dans le réseau de décodage à des fins de prédiction.
, qui est entrée dans le réseau de décodage à des fins de prédiction. 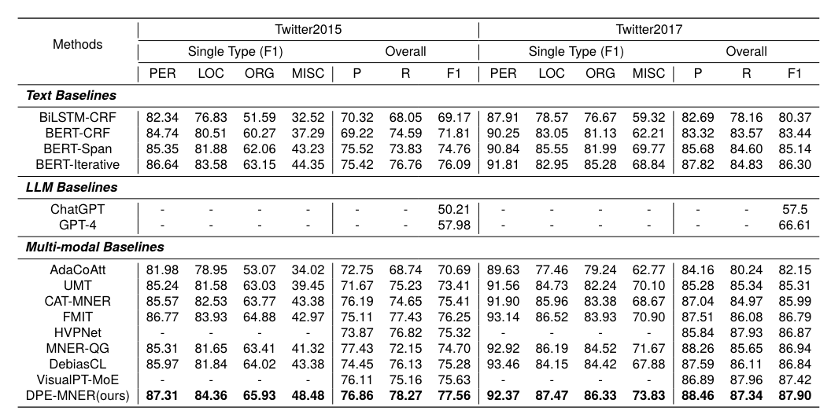

 CPU
CPU
 paramètres des variables d'environnement Java
paramètres des variables d'environnement Java
 Pourquoi l'ordinateur redémarre-t-il automatiquement ?
Pourquoi l'ordinateur redémarre-t-il automatiquement ?
 Quels sont les attributs du javabean ?
Quels sont les attributs du javabean ?
 La différence entre le masque de pâte et le masque de soudure
La différence entre le masque de pâte et le masque de soudure
 Dernières tendances des prix du Bitcoin
Dernières tendances des prix du Bitcoin
 Apprenez le C# à partir de zéro
Apprenez le C# à partir de zéro
 Comment fermer le port 445
Comment fermer le port 445








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



