
 Périphériques technologiques
IA
L'étincelle des grands modèles et de l'intelligence incarnée, appel à communications et défi lancés pour l'atelier ICML 2024 MFM-EAI
Périphériques technologiques
IA
L'étincelle des grands modèles et de l'intelligence incarnée, appel à communications et défi lancés pour l'atelier ICML 2024 MFM-EAI
L'étincelle des grands modèles et de l'intelligence incarnée, appel à communications et défi lancés pour l'atelier ICML 2024 MFM-EAI


Overview
Ces dernières années, les modèles de base multimodaux (MFM), tels que CLIP, ImageBind, DALL・E 3. GPT-4V, Gemini et Sora sont devenus l'un des domaines les plus accrocheurs et les plus en développement dans le domaine de l'intelligence artificielle. Dans le même temps, la communauté open source MFM a également émergé avec des projets open source représentatifs tels que LLaVA, LAMM, MiniGPT-4, Stable Diffusion et OpenSora.
Différent des modèles traditionnels de vision par ordinateur et de traitement du langage naturel, ce type de MFM explore activement les solutions générales aux problèmes. En introduisant MFM, l'intelligence incorporée (EAI) peut mieux gérer diverses tâches complexes dans les simulateurs et les environnements du monde réel. Cependant, il reste encore de nombreux problèmes qui n'ont pas encore été explorés et résolus à l'intersection de MFM et d'EAI, notamment la prise de décision à long terme de l'agent, la planification des mouvements de l'agent, les capacités de généralisation de nouveaux environnements, etc.
Cet atelier sera consacré à l'exploration de plusieurs questions clés, notamment :
- Capacité de généralisation de la MFM ;
- MFM pour l'intelligence incarnée ;
- Modèle mondial basé sur des modèles génératifs ;
- Collecte de données d'apprentissage par imitation ;
Appel à communications de l'atelier
Cet atelier se concentre sur le modèle de base multimodal (MFM), l'intelligence incorporée (EAI) et l'intersection des deux études. Les sujets de cet appel à communications incluent, sans s'y limiter :
- Formation et évaluation de la MFM dans des scénarios ouverts
- Collecte de données pour la formation des agents incarnés
- Conception de cadres pour les agents incarnés propulsés par MFM
- Perception et haute- planification de niveau chez les agents incarnés habilités par MFM
- Prise de décision et contrôle de bas niveau chez les agents incarnés habilités par MFM
- Évaluation de la capacité des agents incarnés
- Modèle génératif comme simulateur du monde
- Limitations de MFM dans l'autonomisation de l'EAI
Règles de soumission
Cette soumission sera soumise à un examen en double aveugle via la plateforme OpenReview. La longueur du texte principal de la soumission est de 4 pages, et il n'y a aucune limite quant à la longueur des références et des documents supplémentaires.
- Le format et le modèle de soumission suivent les directives de soumission de l'ICML 2024 : https://icml.cc/Conferences/2024/CallForPapers
- Entrée de soumission : https://openreview.net/group?id=ICML.cc/2024 /Atelier /MFM-EAI
Nœuds temporels
Tous les nœuds temporels sont [AoE] (N'importe où sur Terre).
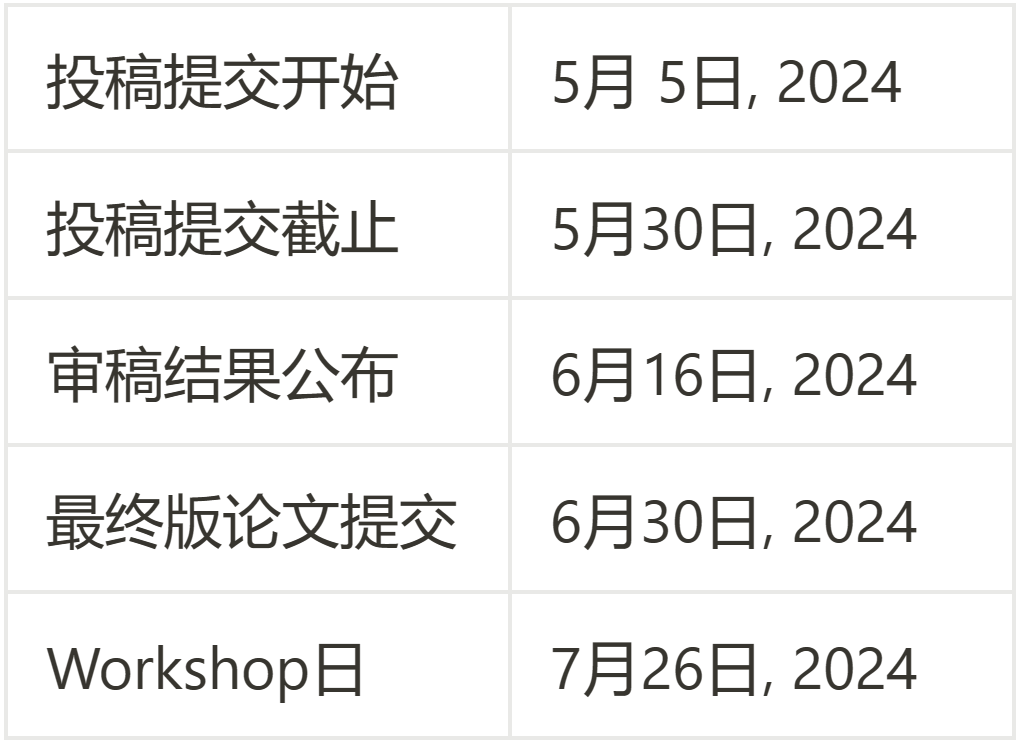
Trois pistes (peuvent participer en même temps)
- EgoPlan Challenge
EgoPlan Challenge est conçu pour évaluer de grands modèles multimodaux dans des scénarios réels, ciblage La capacité de planifier des tâches du monde réel impliquées dans les activités humaines quotidiennes. Le modèle doit sélectionner des actions raisonnables pour accomplir la tâche en fonction de la description de l'objectif de la tâche, de la vidéo en perspective à la première personne et de l'observation de l'environnement actuel.
- Site officiel du concours : https://chenyi99.github.io/ego_plan_challenge/
- Méthode d'inscription : Remplissez [Google Form](https://docs.google.com/forms/d/e/1FAIpQLScnWoXjZcwaagozP3jXnzdSEXX3r2tgXbqO6JWP_lr_fdnpQ w /viewform? usp =sf_link)
- Date d'inscription : à partir de maintenant - 1er juillet 2024
-
Paramètres du prix :
- Gagnant : 800 $
- Deuxième : 600 $
- Prix de l'innovation : 600 $
- Composable Generalization Agent Challenge
Le Composable Generalization Challenge vise à évaluer les capacités de tâches et les capacités de généralisation du système combiné planification-exécution dans des scénarios ouverts. Le modèle effectue une décomposition de tâches sur la base d'une description de tâche linguistique et d'une entrée visuelle multimodale, et le contrôleur exécute les sous-tâches décomposées.
- Plus de détails seront annoncés en juillet
- World Model Challenge
Le World Model Challenge vise à évaluer les performances d'application des simulateurs mondiaux dans des scénarios d'intelligence incorporée. Le modèle génère des vidéos conformes aux instructions de tâche sur la base de descriptions de tâches incorporées et d'observations de scène en temps réel, et évalue la qualité de la génération vidéo et la capacité à guider l'agent pour accomplir des tâches. Plus de détails seront annoncés en juillet
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
 Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
 La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
 Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
 L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
 Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
 Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
 Le premier grand modèle d'interface utilisateur en Chine est lancé ! Le grand modèle de Motiff crée le meilleur assistant pour les concepteurs et optimise le flux de travail de conception d'interface utilisateur
Aug 19, 2024 pm 04:48 PM
Le premier grand modèle d'interface utilisateur en Chine est lancé ! Le grand modèle de Motiff crée le meilleur assistant pour les concepteurs et optimise le flux de travail de conception d'interface utilisateur
Aug 19, 2024 pm 04:48 PM
Le premier grand modèle d'interface utilisateur en Chine est lancé ! Le grand modèle de Motiff crée le meilleur assistant pour les concepteurs et optimise le flux de travail de conception d'interface utilisateur
