Les guerriers et chevaux en terre cuite, qui dorment depuis plus de deux mille ans, se sont réveillés ? 
La ligne d'ouverture de l'Opéra Qin nous a amenés sur le plateau de Loess. S'ils ne l'avaient pas vu de leurs propres yeux, de nombreux téléspectateurs n'auraient peut-être pas imaginé qu'ils verraient un jour Terracotta Warriors et Gem interpréter "Army March" sur la même scène de leur vivant. "Les longs nuages et les sombres montagnes enneigées du Qinghai, la ville solitaire regardant le col de Yumen au loin." Bien que l'air ancien ait changé dans la musique, le son est toujours touchant :
La "technique d'invocation de résurrection IA" derrière cette performance s'appelle EMO, du laboratoire Alibaba Tongyi. Avec juste une photo et un son, EMO peut transformer une image fixe en une vidéo chantée réaliste et capturer avec précision les hauts et les bas et les hauts et les bas de l'audio. Lors du "2024 China AI Festival" de CCTV, également basé sur la technologie EMO, l'écrivain de la dynastie des Song du Nord, Su Shi, a été "ressuscité" et a chanté une chanson "Shui Tiao Ge Tou" avec Li Yugang sur la même scène. Les mouvements de "AI Su Shi" sont simples et naturels, comme s'il avait voyagé dans le temps et l'espace :
Inspiré des technologies de pointe dans le domaine de l'IA comme l'EMO, la première technologie de niveau national un festin avec l'intelligence artificielle comme noyau Le « Festival chinois de l'IA 2024 » est grandiose. Lors de l'ouverture, la puissance technologique nationale de l'IA la plus avancée sera livrée à chaque public avant le spectacle sous la forme d'une intégration « médias + technologie + art » : Ce n'est pas la première fois qu'EMO sort "du cercle". "Gao Qiqiang et Luo Xiang Pufa", devenu populaire sur les réseaux sociaux, a également été créé par EMO : Après s'être connecté à l'application Tongyi, avec l'aide des divers essais imaginatifs des joueurs, EMO est devenu si populaire aujourd'hui Pas réduit. Les amis qui ne l'ont pas encore essayé peuvent télécharger cette application, entrer « Channel » et sélectionner « National Stage » pour vivre une expérience fluide.
En fait, dès février de cette année, le laboratoire Tongyi a publié des articles liés à l'EMO (Emote Portrait Alive). Cet article a reçu des critiques élogieuses lors de son lancement. Certaines personnes ont même fait l'éloge : "EMO est une recherche révolutionnaire."
- Adresse papier : https://arxiv.org/pdf/2402.17485
- Page d'accueil du projet : https://humanaigc.github.io/emote-portrait-alive/
Pourquoi ça marche Pour recevoir de tels éloges ? Cela commence également par l'état actuel du développement de la technologie de génération vidéo et l'innovation technologique sous-jacente d'EMO. Alors hors du cercle, pourquoi EMO ? Ces dernières années, le succès de l'IA dans la génération d'images est une évidence pour tous. Actuellement, le point chaud de la recherche dans le domaine de l’IA consiste à surmonter une tâche plus difficile : la génération de vidéos. EMO est confronté à l'une des tâches les plus difficiles : Génération vidéo de personnages pilotés par l'audio. Différent du gameplay vidéo commun de Vincent et de Tusheng, la génération vidéo de personnages basée sur l'audio est un processus qui passe directement de la modalité audio à la modalité vidéo. La génération de ce type de vidéo implique souvent plusieurs éléments tels que le mouvement de la tête, le regard, le clignement des yeux, le mouvement des lèvres, etc., et la cohérence et la fluidité du contenu vidéo doivent être maintenues. Dans les méthodes précédentes, la plupart des modèles effectuent d'abord une modélisation 3D ou un marquage des points clés du visage pour les visages, les têtes ou les parties du corps, et l'utilisent comme expression intermédiaire pour générer la vidéo finale. Cependant, la méthode d'utilisation de l'expression intermédiaire peut entraîner une surcompression des informations contenues dans l'audio, affectant l'expression émotionnelle de la vidéo finale générée. Bo Liefeng, chef de l'équipe de vision appliquée du laboratoire Tongyi, a déclaré que L'innovation clé d'EMO "conception de contrôle faible" résout bien les problèmes ci-dessus, non seulement en réduisant le coût de la génération vidéo, mais en améliorant également considérablement qualité de génération vidéo.
Le « contrôle faible » se reflète dans deux aspects : Premièrement, EMO ne nécessite pas de modélisation et extrait directement les informations de l'audio pour générer des vidéos de dynamique d'expression faciale et de synchronisation labiale, éliminant ainsi le besoin d'un prétraitement complexe. . Créez des vidéos de portraits naturelles, fluides et expressives de bout en bout. Deuxièmement, EMO n'a pas trop de « contrôle » sur les expressions et les mouvements corporels générés. Les résultats finaux naturels et fluides générés sont dus à la capacité de généralisation du modèle lui-même formé par l'apprentissage à partir de données de haute qualité. En prenant les guerriers et les chevaux en terre cuite et Gem Gem dans le même cadre pour chanter "Army March", les émotions (telles que l'excitation) à transmettre dans la chanson sont bien affichées sur son visage sans donner aux gens une impression de désobéissance :
Basée sur le concept de contrôle faible, l'équipe de recherche a construit un ensemble de données audio et vidéo vaste et diversifié pour le modèle EMO, totalisant plus de 250 heures d'enregistrement et plus de 150 millions d'images, couvrant divers contenus, y compris des discours, des films Avec des clips télévisés et des performances de chant dans plusieurs langues, dont le chinois et l'anglais, la riche variété de vidéos garantit que le matériel de formation capture un large éventail d'expressions humaines et de styles vocaux. Il existe une opinion dans la communauté universitaire selon laquelle la meilleure compression sans perte pour un ensemble de données est la meilleure généralisation pour les données en dehors de l'ensemble de données. Les algorithmes capables d’obtenir une compression efficace peuvent souvent révéler les schémas profonds des données, ce qui constitue également une manifestation importante de l’intelligence. Par conséquent, l'équipe a conçu un algorithme de codage de données haute fidélité pendant le processus de formation pour garantir que les détails riches et la plage dynamique des informations d'origine sont conservés autant que possible pendant le processus de compression ou de traitement des données. . Spécifique à la formation EMO, ce n'est que lorsque les informations audio sont complètes que les émotions du personnage peuvent être bien affichées.
La piste de génération vidéo est en plein essorComment Tongyi Lab est-il devenu le premier échelon au monde ? Début février de cette année, la sortie de Sora a enflammé la piste de la génération vidéo, et de nombreuses technologies derrière elle ont attiré l'attention, notamment DiT (Diffusion Transformer). Nous savons que U-Net dans le modèle de diffusion peut simuler le processus de récupération progressive des signaux du bruit. Il peut théoriquement se rapprocher de toute distribution de données complexe et est supérieur aux réseaux contradictoires génératifs (GAN) et variable en termes de. qualité d'image Autoencoder (VAE), qui génère des images du monde réel avec des textures plus naturelles et des détails plus précis. Cependant, l'article DiT montre que le biais inductif U-Net n'est pas indispensable aux performances du modèle de diffusion et peut être facilement remplacé par une conception standard (telle que Transformer). Il s'agit du nouveau modèle de diffusion DiT basé sur l'architecture Transformer. proposé dans le document. La chose la plus importante est que Sora avec DiT comme noyau a vérifié que la loi de mise à l'échelle existe toujours dans le modèle de génération vidéo, et les chercheurs peuvent étendre la taille du modèle pour obtenir de meilleurs résultats en ajoutant plus de paramètres et de données. Le succès du modèle DiT dans la génération de vidéos réelles a permis à la communauté de l'IA de voir le potentiel de cette méthode, incitant le domaine de la génération vidéo à passer de l'architecture classique U-Net au paradigme du Architecture de base de diffusion basée sur un transformateur. La prédiction temporelle basée sur le mécanisme d’attention du Transformer et les données vidéo à grande échelle de haute qualité sont les principaux moteurs de cette transformation. Cependant, dans le domaine actuel de la génération vidéo, il n'y a pas encore eu d'architecture « grande unifiée ». EMO n'est pas basé sur une architecture de type DiT, c'est-à-dire qu'il n'utilise pas Transformer pour remplacer le U-Net traditionnel. Il peut également très bien simuler le monde physique réel, ce qui a inspiré toute la recherche. champ. Quelles voies techniques émergeront dans le domaine de la génération vidéo à l'avenir ? Les chercheurs théoriques et les praticiens peuvent maintenir des « attentes relativement ouvertes ». Bo Liefeng a déclaré qu'en substance, les modèles de langage actuels et les modèles de génération d'images/vidéos n'ont pas dépassé le cadre de l'apprentissage automatique statistique. Même la loi de mise à l'échelle a ses propres limites. Bien que chaque modèle ait une compréhension relativement précise de la génération de relations fortes et de relations moyennes, l’apprentissage des relations faibles reste encore insuffisant. Si les chercheurs ne peuvent pas continuer à fournir suffisamment de données de haute qualité, il sera difficile d’améliorer qualitativement les capacités du modèle. En regardant les choses sous un autre angle, même s'il existe une architecture unifiée qui "occupe la moitié du pays" dans le domaine de la génération vidéo, cela ne veut pas dire qu'elle a une supériorité absolue. Tout comme dans le domaine du langage naturel, Transformer, qui a toujours été fermement en position C, risque également d'être dépassé par Mamba. Plus précisément dans le domaine de la génération vidéo, chaque parcours technique a ses propres scénarios d'application. Par exemple, le pilote de point clé et le pilote vidéo sont plus adaptés aux scènes de migration d'expression, et le pilote audio est plus adapté aux scènes de personnages parlant et chantant. En termes de degré de contrôle conditionnel, les méthodes de contrôle faibles conviennent très bien aux tâches créatives, tandis que de nombreuses tâches professionnelles et spécifiques peuvent bénéficier de méthodes de contrôle fortes. Le laboratoire Tongyi est l'une des premières institutions en Chine à mettre au point une technologie de génération vidéo. Actuellement, il a accumulé des recherches et des développements dans plusieurs directions telles que Wensheng Video et Tusheng Video, en particulier dans le domaine de la génération de vidéos de personnages. il a formé une matrice de recherche Peoplecomplète comprenant Animate Anybody, le cadre de génération de vidéo de changement de personnage Outfit Anybody, le cadre de remplacement de rôle de vidéo de personnage Motionshop, le cadre de génération de vidéo de chant et de performance de personnage Emote Portrait Alive.
: Pour plus de projets, veuillez faire attention : https://github.com/humanaigc, comme avant EMO, Animate Any dominait autrefois les médias sociaux et le cercle d'amis. Ce modèle a résolu le problème du maintien de la continuité à court terme et de la cohérence à long terme de l'apparence des personnages dans la génération de vidéos de mouvements de personnages. Par la suite, la fonction « National Dance King » a été lancée sur l'application Tongyi, déclenchant une vague de danse à l'échelle nationale. Climax.
De la technologie au monde réelAu cours des deux dernières années, les modèles de langage ont démontré de puissantes capacités de texte en matière de dialogue, de compréhension, de résumé, de raisonnement, etc., et les modèles de génération d'images ont démontré de puissantes capacités de texte. génération naturelle, divertissement et capacités artistiques, les deux pistes majeures ont produit de nombreux produits à succès. Le succès de ces modèles nous dit au moins une chose :
Les équipes techniques qui veulent gagner en influence à cette époque doivent apprendre à marcher sur deux jambes : les « modèles de base » et les « super applications ». Actuellement, le contenu vidéo affiche une tendance à la croissance explosive, et les gens attendent avec impatience l'émergence d'une plate-forme de génération de vidéo IA qui soit « utilisable » et « pratique » pour tout le monde.
EMO peut constituer une avancée technologique importante pour mettre fin à cette situation, et l'application Tongyi fournit une large plate-forme pour la mise en œuvre de la technologie. Le prochain défi de la technologie de génération vidéo est de savoir comment capturer du contenu de niveau professionnel.
Les entreprises technologiques espèrent transformer la technologie de l'IA en un véritable outil de productivité au service des blogueurs de vidéos courtes, des producteurs de films et de télévision, des créateurs de publicité et de jeux. C’est pourquoi les applications de génération vidéo ne peuvent pas se contenter de rester au niveau du « contenu général ».
En regardant la plupart des applications de génération vidéo actuelles, la plupart sont basées sur 3 à 5 secondes de modèles de génération vidéo, avec des limitations évidentes en termes d'application et d'expérience.
Cependant, la technologie EMO est très tolérante à la durée audio et la qualité du contenu généré peut répondre aux normes des studios. Par exemple, dans cette « Chant et performance des guerriers et des chevaux en terre cuite » diffusée sur CCTV, pas une seule seconde de la vidéo de quatre minutes de la performance des guerriers et des chevaux en terre cuite n'a nécessité un « réglage fin » manuel en post-production. Maintenant, il semble que la technologie de génération de vidéos de personnages représentée par EMO soit l'une des directions de mise en œuvre les plus proches du « niveau de génération de niveau professionnel ». Comparée aux nombreuses incertitudes liées aux invites des utilisateurs dans la technologie vidéo Wensheng, la technologie EMO est tout à fait conforme aux exigences fondamentales en matière de cohérence du contenu et de cohérence dans la création vidéo de personnages, démontrant un espace d'application très potentiel.
La raison pour laquelle EMO "est sorti du cercle" n'est pas seulement la force technique de l'équipe R&D, mais plus important encore, l'accélération de la mise en œuvre de la technologie de génération vidéo.
L'ère des « créateurs professionnels par habitant » n'est peut-être pas loin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Périphériques technologiques
Périphériques technologiques



 Ce n'est pas la première fois qu'EMO sort "du cercle". "Gao Qiqiang et Luo Xiang Pufa", devenu populaire sur les réseaux sociaux, a également été créé par EMO :
Ce n'est pas la première fois qu'EMO sort "du cercle". "Gao Qiqiang et Luo Xiang Pufa", devenu populaire sur les réseaux sociaux, a également été créé par EMO : 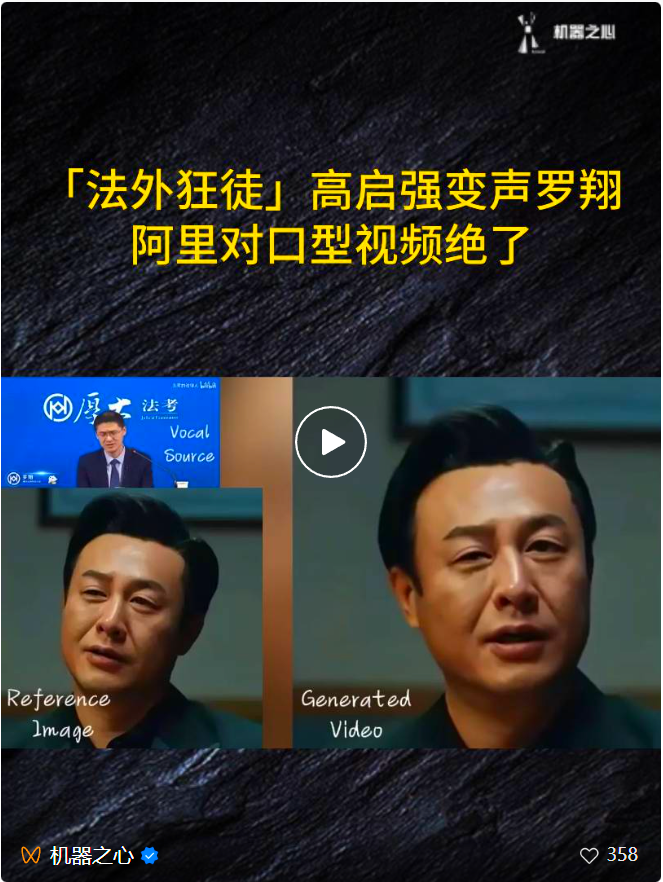





 De la technologie au monde réel
De la technologie au monde réel











 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
 Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
 La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
 Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
 L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
 Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
 Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
 Le premier grand modèle d'interface utilisateur en Chine est lancé ! Le grand modèle de Motiff crée le meilleur assistant pour les concepteurs et optimise le flux de travail de conception d'interface utilisateur
Aug 19, 2024 pm 04:48 PM
Le premier grand modèle d'interface utilisateur en Chine est lancé ! Le grand modèle de Motiff crée le meilleur assistant pour les concepteurs et optimise le flux de travail de conception d'interface utilisateur
Aug 19, 2024 pm 04:48 PM
