

Imaginez si un robot pouvait comprendre vos besoins et travailler dur pour y répondre, ne serait-ce pas génial ?
Si vous souhaitez qu'un robot vous aide, vous devez généralement donner une commande plus précise, mais la mise en œuvre réelle de la commande n'est peut-être pas idéale. Si nous considérons l'environnement réel, lorsqu'on demande au robot de trouver un élément spécifique, l'élément peut ne pas exister réellement dans l'environnement actuel, et le robot ne peut pas le trouver de toute façon, mais est-il possible qu'il y ait un autre élément dans l'environnement ? qui est lié à l'utilisateur ? L'article demandé a-t-il des fonctions similaires et peut-il également répondre aux besoins de l'utilisateur ? C'est l'avantage d'utiliser des « exigences » comme instructions de tâche.
Récemment, l'équipe de l'Université de Pékin Dong Hao a proposé une nouvelle tâche de navigation - Navigation pilotée par la demande (DDN), a été acceptée par NeurIPS 2023. Dans cette tâche, le robot doit trouver des articles qui répondent aux besoins de l'utilisateur sur la base d'une instruction de demande donnée par l'utilisateur. Dans le même temps, l'équipe de Dong Hao a également proposé d'apprendre les caractéristiques des objets en fonction des instructions de la demande, ce qui a effectivement amélioré le taux de réussite du robot dans la recherche d'objets.

Adresse papier : https://arxiv.org/pdf/2309.08138.pdf
Page d'accueil du projet : https://sites.google.com/view/demand-driven-navigation/home 
Les utilisateurs doivent uniquement donner des instructions en fonction de leurs propres besoins, sans tenir compte de ce qu'il y a dans la scène.

Utiliser les besoins comme instructions peut augmenter la probabilité que les besoins des utilisateurs soient satisfaits. Par exemple, lorsque vous avez « soif », demander au robot de trouver du « thé » et demander au robot de trouver « des objets qui peuvent étancher votre soif » ont évidemment une portée plus large dans ce dernier.
Les exigences décrites en langage naturel ont un espace de description plus grand et peuvent proposer des exigences plus précises et plus précises.
Afin d'entraîner un tel robot, il est nécessaire d'établir une relation cartographique entre les instructions de demande et les éléments afin que l'environnement puisse donner des signaux d'entraînement. Afin de réduire les coûts, l'équipe de Dong Hao a proposé une méthode de génération « semi-automatique » basée sur un grand modèle de langage : utilisez d'abord GPT-3.5 pour générer des besoins pouvant être satisfaits par les éléments existants dans la scène, puis filtrez manuellement ceux-ci. qui ne répondent pas aux exigences.
Considérant que les objets qui peuvent répondre aux mêmes besoins ont des attributs similaires, si les caractéristiques des attributs de ces objets peuvent être apprises, le robot semble être capable d'utiliser ces caractéristiques d'attribut pour trouver des objets. Par exemple, pour l'exigence « J'ai soif », les éléments requis doivent avoir l'attribut « étancher la soif », et « jus » et « thé » ont tous deux cet attribut. Ce qu'il faut noter ici, c'est qu'un article peut présenter différents attributs selon différents besoins. Par exemple, « l'eau » peut présenter à la fois l'attribut « nettoyer les vêtements » (sous l'exigence de « laver les vêtements ») et exposer l'attribut « . étancher ma soif » (sous l'exigence de « J'ai soif »).
Étape d'apprentissage des attributs
Alors, comment faire comprendre au modèle les besoins de « étancher la soif » et de « nettoyer les vêtements » ? Il est de bon sens relativement stable de noter les attributs affichés par les éléments sous certaines conditions. Ces dernières années, avec la montée progressive des grands modèles de langage (LLM), la compréhension du bon sens de la société humaine démontrée par le LLM est étonnante. Par conséquent, l’équipe de l’Université de Pékin à Dong Hao a décidé d’apprendre ce bon sens grâce au LLM. Ils ont d'abord demandé à LLM de générer un grand nombre d'instructions de demande (appelées Language-grounding Demand, LGD sur la figure), puis ont demandé à LLM quels éléments peuvent satisfaire ces instructions de demande (appelées Language-grounding Object, LGO sur la figure).
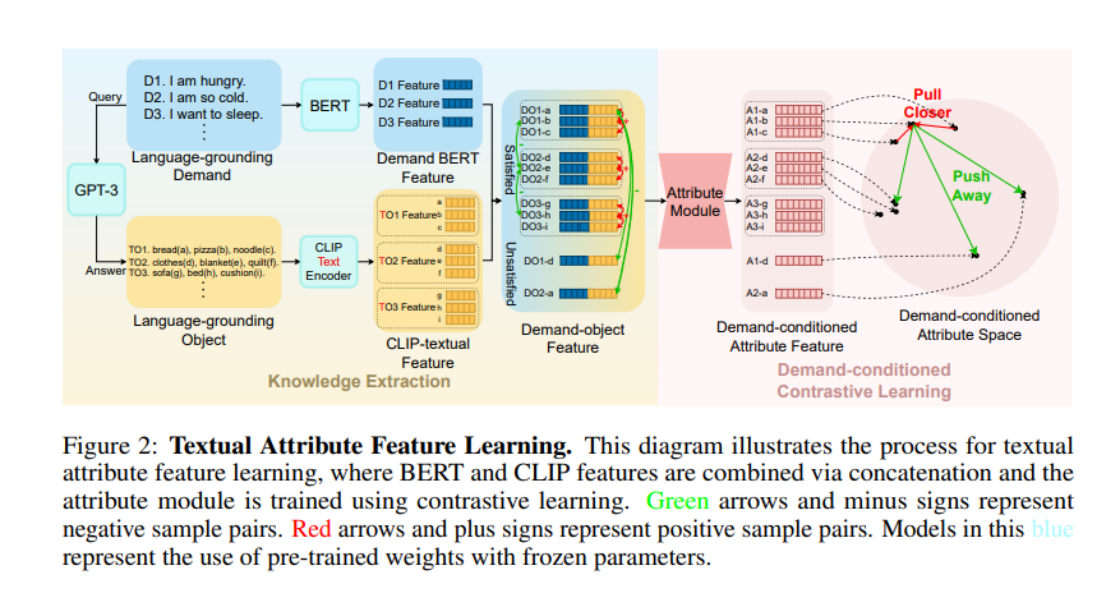
Il convient de noter ici que le préfixe Language-grounding souligne que ces demandes/objets peuvent être obtenus à partir de LLM et ne dépendent pas d'un scénario spécifique. World-grounding dans la figure ci-dessous met l'accent sur ces demandes/objets. L'objet est ; étroitement intégré à un environnement spécifique (tel que ProcThor, Replica et d'autres ensembles de données de scène).
Ensuite, afin d'obtenir les propriétés de LGO sous LGD, les auteurs ont utilisé BERT pour encoder LGD, CLIP-Text-Encoder pour encoder LGO, puis les ont épissés pour obtenir des fonctionnalités d'objet de demande. Notant qu'il y avait une « similarité » lors de l'introduction des attributs des items au début, les auteurs ont utilisé cette similarité pour définir des « échantillons positifs et négatifs », puis ont utilisé l'apprentissage contrastif pour entraîner les « attributs des items ». Plus précisément, pour deux fonctionnalités d'objet de demande épissées, si les éléments correspondant aux deux fonctionnalités peuvent répondre à la même exigence, alors les deux fonctionnalités sont des échantillons positifs l'une de l'autre (par exemple, l'élément a et l'élément b dans l'image sont tous deux peut répondre à l'exigence D1, alors DO1-a et DO1-b sont des échantillons positifs l'un de l'autre) ; tout autre épissage est des échantillons négatifs l'un de l'autre. Une fois que les auteurs ont saisi les fonctionnalités de l'objet de demande dans un module d'attribut de l'architecture TransformerEncoder, ils se sont entraînés avec InfoNCE Loss.
Phase d'apprentissage de la stratégie de navigation
Grâce à l'apprentissage comparatif, le module d'attribut a appris le bon sens fourni par LLM. Dans la phase d'apprentissage de la stratégie de navigation, les paramètres du module d'attribut sont directement importés, puis l'algorithme A* est. appris en utilisant l'apprentissage par imitation. À un certain pas de temps, l'auteur utilise le modèle DETR pour segmenter les éléments dans le champ de vision actuel afin d'obtenir l'objet de mise à la terre du monde, qui est ensuite codé par CLIP-Visual-Endocer. D'autres processus sont similaires à l'étape d'apprentissage des attributs. Enfin, les fonctionnalités BERT, les fonctionnalités d'image globale et les fonctionnalités d'attribut des instructions requises sont fusionnées, introduites dans un modèle Transformer, et enfin une action est générée.

Il convient de noter que les auteurs ont utilisé CLIP-Text-Encoder dans la phase d'apprentissage des attributs, et dans la phase d'apprentissage de la politique de navigation, les auteurs ont utilisé CLIP-Visual-Encoder. Ici, les puissantes capacités d'alignement visuel et textuel du modèle CLIP sont intelligemment utilisées pour transférer le bon sens textuel appris de LLM à la vision à chaque pas de temps.
Résultats expérimentaux
L'expérience a été menée sur le simulateur AI2Thor et les ensembles de données ProcThor. Les résultats expérimentaux montrent que cette méthode est nettement supérieure aux variantes précédentes de divers algorithmes de navigation d'éléments visuels et aux algorithmes pris en charge par de grands modèles de langage.

VTN est un algorithme de navigation à vocabulaire fermé qui ne peut effectuer des tâches de navigation que sur des éléments prédéfinis. Les auteurs ont apporté quelques variantes à son algorithme. Cependant, que les fonctionnalités BERT des instructions requises soient utilisées comme entrée ou que les résultats de l'analyse GPT des instructions soient utilisés comme entrée, les résultats de l'algorithme ne sont pas très idéaux. Lors du passage à ZSON, un algorithme de navigation à vocabulaire ouvert, en raison du mauvais effet d'alignement de CLIP entre les instructions de demande et les images, plusieurs variantes de ZSON ne peuvent pas accomplir correctement les tâches de navigation à la demande. Cependant, certains algorithmes basés sur la recherche heuristique + LLM ont une faible efficacité d'exploration en raison de la vaste zone de scène de l'ensemble de données Procthor, et leur taux de réussite n'est pas très élevé. Les algorithmes LLM purs, tels que GPT-3-Prompt et MiniGPT-4, présentent de faibles capacités de raisonnement pour les emplacements invisibles de la scène, ce qui entraîne l'incapacité de découvrir efficacement les éléments qui répondent aux exigences.
Les expériences d'ablation montrent que le module d'attribut améliore considérablement le taux de réussite de la navigation. Les auteurs montrent que le graphique t-SNE démontre bien que le module d'attribut apprend avec succès les caractéristiques d'attribut des éléments grâce à un apprentissage contrastif conditionné par la demande. Après avoir remplacé l'architecture du module d'attribut par MLP, les performances ont chuté, indiquant que l'architecture TransformerEncoder est plus adaptée à la capture des caractéristiques d'attribut. BERT peut très bien extraire les caractéristiques des instructions requises, ce qui améliore la généralisation des instructions invisibles.

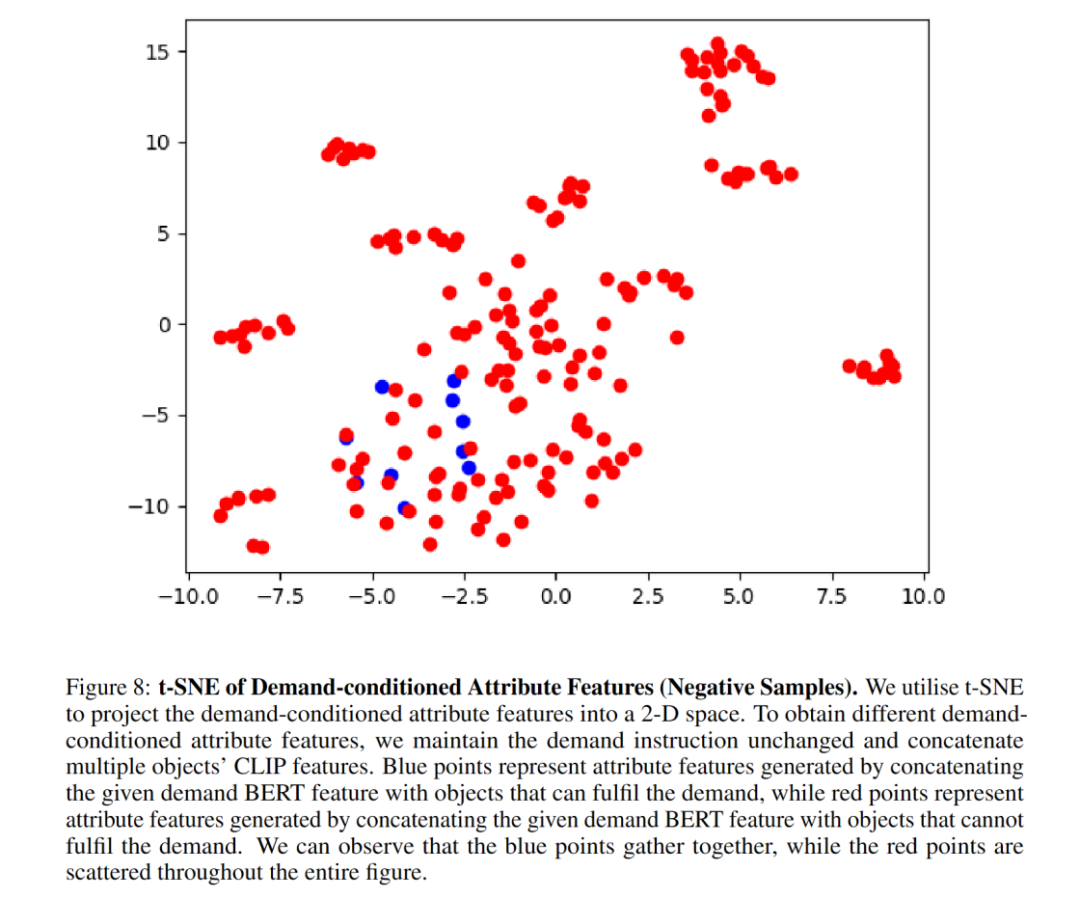
Voici quelques visualisations : 



L'auteur correspondant de cette étude, le Dr Dong Hao, est actuellement professeur adjoint au Frontier Computing Research Center de Pékin. Université, directeur de doctorat et chercheur en arts libéraux et chercheur intellectuel, il a fondé et dirigé le laboratoire Hyperplane de l'Université de Pékin en 2019. Il a publié plus de 40 articles dans des conférences/revues internationales de premier plan telles que NeurIPS, ICLR, CVPR, ICCV. , ECCV, etc. Google Scholar Il a été cité plus de 4 700 fois et a remporté le prix ACM MM du meilleur logiciel Open Source et le prix OpenI Outstanding Project. Il a également été président de terrain et membre adjoint du comité de rédaction de conférences internationales de premier plan telles que NeurIPS, CVPR, AAAI et ICRA à plusieurs reprises, a entrepris un certain nombre de projets nationaux et provinciaux et a présidé la nouvelle génération du ministère des Sciences et de la Technologie. Grand projet Intelligence Artificielle 2030.

Le premier auteur de l'article, Wang Hongzhen, est actuellement doctorant en deuxième année à l'École d'informatique de l'Université de Pékin. Ses intérêts de recherche se concentrent sur la robotique, la vision par ordinateur et la psychologie. Il espère partir des aspects du comportement humain, de la cognition et de la motivation pour aligner la connexion entre les humains et les robots.

Liens de référence :
[1] https://zsdonghao.github.io/
[2] https://whcpumpkin.github.io/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction aux touches de raccourci de capture d'écran dans Win10
Introduction aux touches de raccourci de capture d'écran dans Win10
 Comment ouvrir un fichier rar
Comment ouvrir un fichier rar
 Avantages du téléchargement du site officiel de l'application Yiou Exchange
Avantages du téléchargement du site officiel de l'application Yiou Exchange
 Comment réparer la passerelle par défaut de l'ordinateur n'est pas disponible
Comment réparer la passerelle par défaut de l'ordinateur n'est pas disponible
 Comment taper des guillemets doubles en latex
Comment taper des guillemets doubles en latex
 Tim mobile en ligne
Tim mobile en ligne
 Introduction à la différence entre javascript et java
Introduction à la différence entre javascript et java
 Base de données de restauration MySQL
Base de données de restauration MySQL








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



