
 Périphériques technologiques
IA
L'intégration de molécules de lama est meilleure que le GPT, LLM peut-il comprendre les molécules ? Meta a battu OpenAI dans ce tour
Périphériques technologiques
IA
L'intégration de molécules de lama est meilleure que le GPT, LLM peut-il comprendre les molécules ? Meta a battu OpenAI dans ce tour
L'intégration de molécules de lama est meilleure que le GPT, LLM peut-il comprendre les molécules ? Meta a battu OpenAI dans ce tour


Les grands modèles de langage (LLM) tels que GPT d'OpenAI et Llama de Meta AI sont de plus en plus reconnus pour leur potentiel dans le domaine de la chimioinformatique, notamment dans la compréhension de l'aspect des systèmes d'entrée de ligne d'entrée moléculaire simplifiés (SMILES). Ces LLM sont également capables de décoder les chaînes SMILES en représentations vectorielles.
Des chercheurs de l'Université de Windsor au Canada ont comparé les performances de modèles pré-entraînés sur GPT et Llama avec SMILES pour intégrer des chaînes SMILES dans des tâches en aval, en se concentrant sur deux applications clés : la prédiction des propriétés moléculaires et la prédiction des interactions médicamenteuses.
L'étude s'intitulait « Les grands modèles de langage peuvent-ils comprendre les molécules ? » et a été publiée dans « BMC Bioinformatics » le 25 juin 2024.

L'intégration moléculaire est une tâche cruciale dans la découverte de médicaments et est largement utilisée dans la prédiction des propriétés moléculaires, la prédiction des interactions médicament-cible (DTI) et la fonction d'interaction médicament-médicament (DDI). ) prédiction et autres tâches connexes.
2. Technologie d'intégration moléculaire
La technologie d'intégration moléculaire peut apprendre des caractéristiques à partir de graphiques moléculaires codant pour des informations de connexion structurelle moléculaire ou des annotations linéaires de leurs structures, telles que la représentation populaire SMILES.
3. Intégrations moléculaires dans les chaînes SMILES
Les intégrations moléculaires via les chaînes SMILES ont évolué en tandem avec les progrès de la modélisation du langage, des intégrations de mots statiques aux modèles pré-entraînés contextualisés. Ces techniques d'intégration visent à capturer des informations structurelles et chimiques pertinentes dans une représentation numérique compacte.
L'hypothèse de base est que les molécules ayant des structures similaires se comportent de manière similaire. Cela permet aux algorithmes d’apprentissage automatique de traiter et d’analyser les structures moléculaires pour les tâches de prédiction de propriétés et de découverte de médicaments.
Avec les percées du LLM, une question importante est de savoir si le LLM peut comprendre les molécules et faire des inférences basées sur des données moléculaires ?
Plus précisément, le LLM peut-il produire des représentations sémantiques de haute qualité ?
Shaghayegh Sadeghi, Alioune Ngom Jianguo Lu et d'autres de l'Université de Windsor ont exploré plus en détail la capacité de ces modèles à intégrer efficacement les SMILES. Actuellement, cette fonctionnalité est sous-explorée, peut-être en partie à cause du coût des appels API.
Les chercheurs ont découvert que les intégrations SMILES générées à l'aide de Llama fonctionnaient mieux que les intégrations SMILES générées à l'aide de GPT dans les tâches de propriété moléculaire et de prédiction DDI.
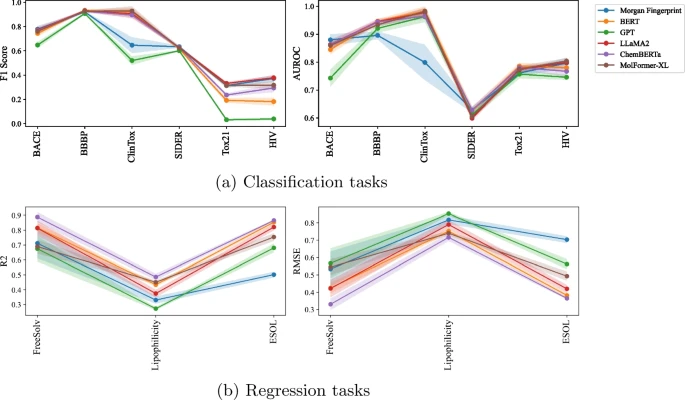
Notamment, les intégrations SMILES basées sur Llama montrent des résultats comparables aux modèles pré-entraînés sur SMILES dans la tâche de prédiction moléculaire et surpassent le modèle pré-entraîné dans la tâche de prédiction DDI.
D'après cela, l'équipe a conclu comme suit :
(1) Les performances du LLM sont en effet meilleures que celles des méthodes traditionnelles. (2) Les performances dépendent de la tâche et parfois des données. (3) Même lorsqu'elle est formée à une tâche plus générale, la nouvelle version de LLM s'améliore par rapport à l'ancienne version. (4) L’intégration de Llama est généralement meilleure que l’intégration GPT. (5) De plus, on observe que Llama et Llama2 sont très proches en termes de performances d'intégration.

L'équipe recommande spécifiquement les modèles Llama par rapport à GPT en raison de leurs performances supérieures dans la génération d'intégrations moléculaires à partir de chaînes SMILES. Ces résultats suggèrent que Llama pourrait être particulièrement efficace pour prédire les propriétés moléculaires et les interactions médicamenteuses.
Bien que les modèles comme Llama et GPT ne soient pas spécifiquement conçus pour l'intégration de chaînes SMILES (contrairement aux modèles spécialisés comme ChemBERTa et MolFormer-XL), ils font néanmoins preuve de compétitivité. Ce travail jette les bases des améliorations futures de l’intégration moléculaire LLM.
À l'avenir, l'équipe se concentrera sur l'amélioration de la qualité des intégrations moléculaires LLM inspirées des techniques d'intégration de phrases en langage naturel, telles que le réglage fin et les modifications de la tokenisation de Llama.
GitHub : https://github.com/sshaghayeghs/LLaMA-VS-GPT
Lien papier : https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-024-05847-x
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1668
1668
 14
1428
52
1329
25
1273
29
1256
24
14
1428
52
1329
25
1273
29
1256
24

 Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Traducteur | Bugatti Review | Chonglou Cet article décrit comment utiliser le moteur d'inférence GroqLPU pour générer des réponses ultra-rapides dans JanAI et VSCode. Tout le monde travaille à la création de meilleurs grands modèles de langage (LLM), tels que Groq, qui se concentre sur le côté infrastructure de l'IA. Une réponse rapide de ces grands modèles est essentielle pour garantir que ces grands modèles réagissent plus rapidement. Ce didacticiel présentera le moteur d'analyse GroqLPU et comment y accéder localement sur votre ordinateur portable à l'aide de l'API et de JanAI. Cet article l'intégrera également dans VSCode pour nous aider à générer du code, à refactoriser le code, à saisir la documentation et à générer des unités de test. Cet article créera gratuitement notre propre assistant de programmation d’intelligence artificielle. Introduction au moteur d'inférence GroqLPU Groq
 Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud, la société derrière le Plaud Note AI Voice Recorder (disponible sur Amazon pour 159 $), a annoncé un nouveau produit. Surnommé NotePin, l’appareil est décrit comme une capsule mémoire AI, et comme le Humane AI Pin, il est portable. Le NotePin est
 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
La génération améliorée de récupération de graphiques (GraphRAG) devient progressivement populaire et est devenue un complément puissant aux méthodes de recherche vectorielles traditionnelles. Cette méthode tire parti des caractéristiques structurelles des bases de données graphiques pour organiser les données sous forme de nœuds et de relations, améliorant ainsi la profondeur et la pertinence contextuelle des informations récupérées. Les graphiques présentent un avantage naturel dans la représentation et le stockage d’informations diverses et interdépendantes, et peuvent facilement capturer des relations et des propriétés complexes entre différents types de données. Les bases de données vectorielles sont incapables de gérer ce type d'informations structurées et se concentrent davantage sur le traitement de données non structurées représentées par des vecteurs de grande dimension. Dans les applications RAG, la combinaison de données graphiques structurées et de recherche de vecteurs de texte non structuré nous permet de profiter des avantages des deux en même temps, ce dont discutera cet article. structure
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
