

… ou en d'autres termes, la manière la plus stupide de se lancer dans les systèmes embarqués.
Regardez-le en action ici !
L'objectif était simple. Écrivez du code en C ou C++ et soyez capable de l'exécuter dans Scratch. Honnêtement, je viens de trouver l’idée assez amusante : un des langages de programmation les plus rapides dans l’un des plus lents. J’avais le sentiment que c’était possible, mais je ne savais pas trop comment. Au cours du processus, j'ai appris bien plus que prévu sur les langages d'assemblage, la mémoire de processus et les fichiers exécutables, et j'espère que vous apprendrez quelque chose de nouveau tout en racontant mon parcours.
Ma première idée était de prendre le code que j'avais écrit en C, de le diviser en morceaux, puis de reconstituer ces morceaux à l'aide de Scratch. Par exemple, une boucle while en C peut devenir une répétition jusqu'au bloc dans Scratch :

Pour qu'un compilateur C comprenne le code, il doit d'abord générer un AST (arbre de syntaxe abstraite), qui est une représentation arborescente de chaque symbole important du code source. Par exemple, une parenthèse ouvrante, le nom d'une variable ou le mot-clé return peuvent chacun être convertis en nœuds distincts. Cependant, après avoir regardé l'AST pour un simple programme de nombres de Fibonacci…
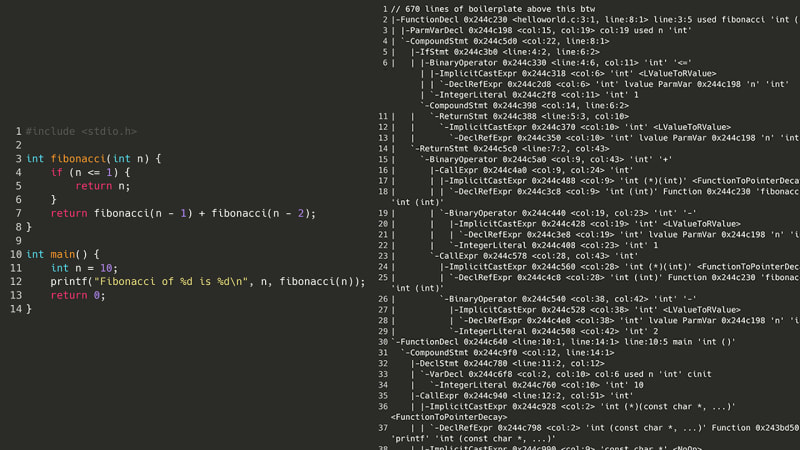
D'accord, donc c'était hors de question. Mais et si au lieu d’essayer de recompiler le code source, nous descendions un échelon plus bas : l’assemblage ? Pour qu’un programme puisse s’exécuter, il doit d’abord être compilé en assembleur. Sur mon ordinateur, c'est x86-64asm. Étant donné que l'assemblage n'a pas de structures d'imbrication, de classes ou même de variables compliquées, essayer d'analyser une liste d'instructions d'assemblage devrait (en théorie) être plus facile que d'essayer d'analyser le monstre spaghetti d'un AST, comme celui ci-dessus. Voici le même programme de Fibonacci mais en assemblage x86.
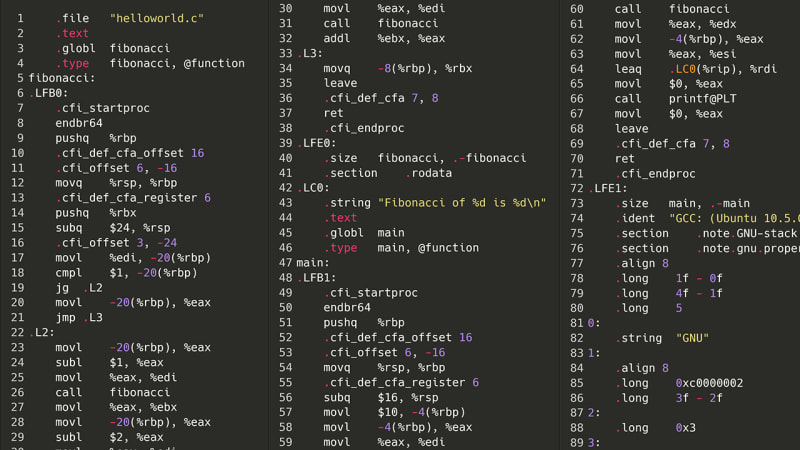
Oh, mon frère. D'accord, ce n'est peut-être pas si grave. Combien y a-t-il d'instructions au total ?
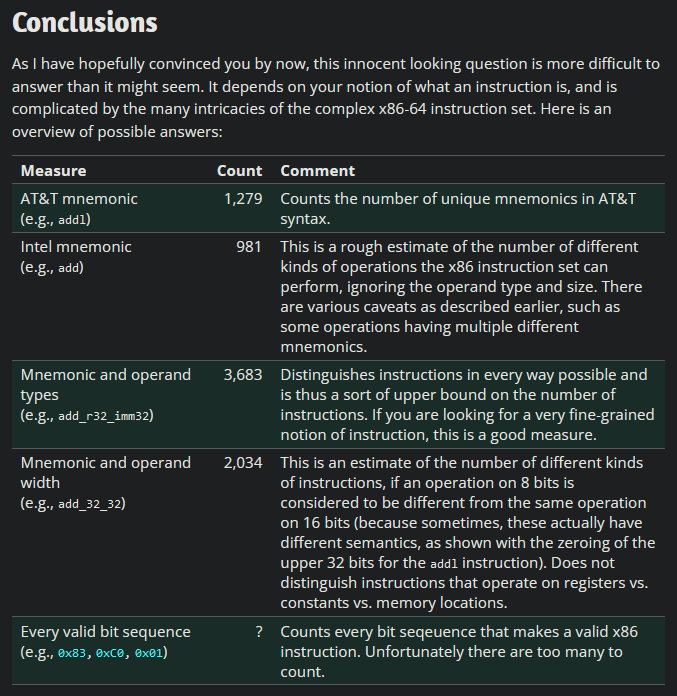
Heureusement, x86 n’est pas le seul langage assembleur disponible. Dans le cadre d'un cours universitaire, j'ai découvert MIPS, un type de langage assembleur (simplifiant à l'excès) utilisé dans certaines consoles de jeux vidéo et superordinateurs des années 90 au début des années 2000, qui est encore utilisé aujourd'hui. Le passage de x86 à MIPS ramène le compte d'instructions de *inconnu *à environ 50.
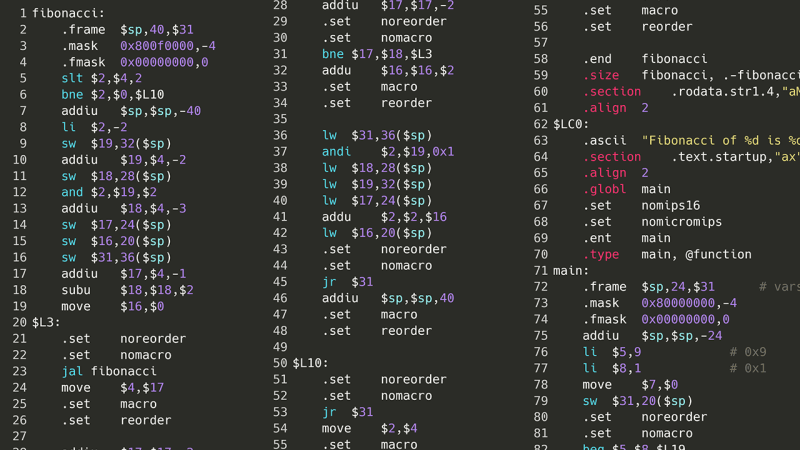
À l'aide d'une version 32 bits de MIPS, ce code assembleur peut ensuite être converti en code machine, où chaque instruction est convertie en un entier 32 bits que le processeur peut comprendre, sur la base des directives définies par l'architecture du processeur. Il existe un livre sur l'architecture du jeu d'instructions MIPS disponible en ligne, donc si je prends le code machine, puis que j'émule exactement ce qu'un processeur MIPS ferait, alors je devrais pouvoir exécuter mon code C dans Scratch !

Maintenant que c’est réglé, nous pouvons commencer.
Eh bien, il y a déjà un problème. Habituellement, si vous avez un entier et que vous souhaitez en extraire une série de bits, vous calculez num & masque, où masque est un entier dans lequel chaque bit important est 1 et chaque bit sans importance est 0.
001000 01001 01000 1111111111111100 & 000000 00000 00000 1111111111111111 -------------------------------------- 000000 0000 000000 1111111111111100
Le problème ? Il n'y a pas d'opérateur & dans Scratch.
Maintenant, je *pourrais *simplement parcourir les deux nombres petit à petit et vérifier chacune des quatre combinaisons possibles de deux bits, mais ce serait inutilement lent ; après tout, cela devra être fait plusieurs fois pour *chaque*instruction. Au lieu de cela, j'ai trouvé un meilleur plan.
Tout d'abord, j'ai écrit un script Python rapide pour calculer x & y pour chaque x et chaque y entre 0 et 255.
for x in range(256):
for y in range(256):
print(x & y)
0 (0 & 0 == 0)
0 (0 & 1 == 0)
0 (0 & 2 == 0)
...
0 (0 & 255 == 0)
0 (1 & 0 == 0)
1 (1 & 1 == 1)
0 (1 & 2 == 0)
...
254 (255 & 254 == 254)
255 (255 & 255 == 255)
Maintenant, par exemple, pour calculer x & y pour deux entiers de 32 bits, nous pouvons faire ce qui suit :
Split x and y into four 8-bit integers (or bytes).
Check what first_byte_in_x & first_byte_in_y is by looking in the table generated from the Python script.
Similarly, look up what second_byte_in_x & second_byte_in_y is, and the third bytes, and the fourth bytes.
Take the results of each of these calculations, and put them together to get the result of x & y .

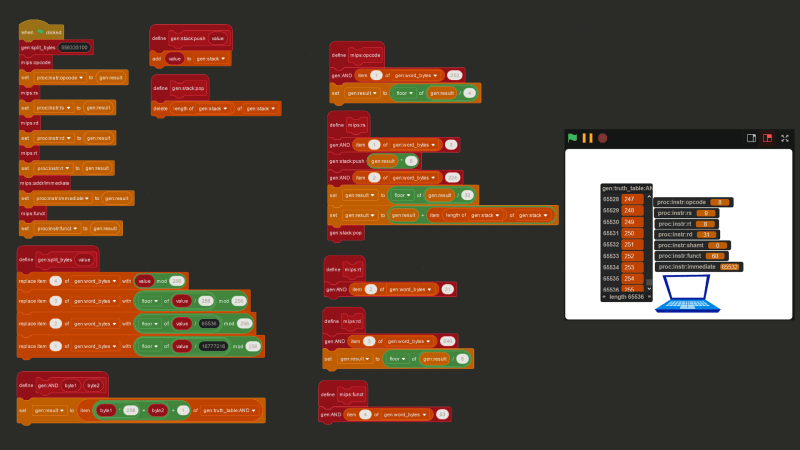
However, once a MIPS instruction has been cut up into four bytes, we’ll only & the bytes we need. For example, if we only need data from the first byte, we won’t even look at the bottom three. But how do we know which bytes we need? Based on the opcode (i.e. the “type”) of an instruction, MIPS will try to split up the bits of an instruction in one of three ways.

Putting everything together, below is the Scratch code to extract opcode, $rs, $rt, $rd, shamt, funct, and immediate for any instruction.
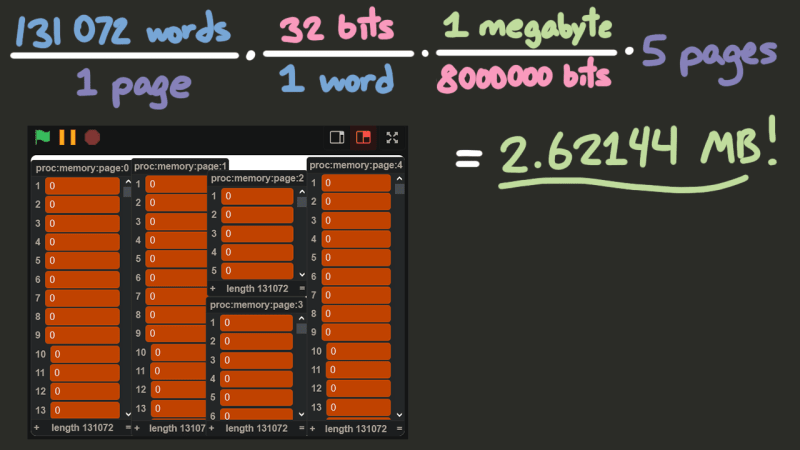
So, how much memory should our processor actually have? And how should we store it? Well, minimum, MIPS processors have 31 general-purpose registers, and one $zero register that is meant to store the number 0 at all times. A register is a location in memory that a processor can access quickly. We can represent these 32 registers as a list with 32 items in Scratch. As for the rest of the memory, simulating a processor moving chunks of data in and out of its cache in Scratch would be pretty pointless and would actually slow things down, rather than speed them up. So instead, the physical memory will be represented as five lists containing 131,072 elements each, where each element will be a 32-bit integer, giving us about 2.6MB of memory. A contiguous block of memory like these lists is usually called a “page”, and the size of the data that the instruction set works with (in this case 32 bits) is usually called a “word”.
So, how do we get machine code in here? We can’t just import a file into Scratch. But we *can *import text! So, I wrote a program in C to take a binary executable file, and convert every 32 bytes of the file into an integer. C, by default, was reading each byte in little-endian, so I had to introduce a function to flip the endianness. Then, I can save the machine code of a program as a text file (a list of integers), and then import it into my proc:memory:program variable.
#include <stdio.h>
unsigned int flip_endian(unsigned int value) {
return ((value >> 24) & 0xff) | ((value >> 8) & 0xff00) | ((value << 8) & 0xff0000) | ((value << 24) & 0xff000000);
}
int main(int argc, char* argv[]) {
if (argc != 3 && argc != 2) {
printf("Usage: %s <input file> <output file?>\n", argv[0]);
return 1;
}
FILE* in = fopen(argv[1], "r");
if (!in) {
perror("fopen");
return 1;
}
unsigned int value;
FILE* out = argc == 3 ? fopen(argv[2], "w") : stdout;
if (!out) {
perror("fopen");
return 1;
}
while (fread(&value, sizeof(value), 1, in) == 1) {
fprintf(out, "%u\n", flip_endian(value));
}
fclose(in);
if (out != stdout) {
fclose(out);
}
return 0;
}
Okay, so now that we can import the data into Scratch, we can just set the program counter (the integer keeping track of the current instruction) to the top of the list, and start executing instructions, right?
Wrong.
I didn’t realize this going into this project, but the first several bytes of an executable file *aren’t *instructions, but a header identifying what type of executable file it is. On Windows, it’ll usually be the PE, or Portable Executable, format, and on UNIX-based systems (the version we’ll be using) it’ll be the ELF format. So, how do we actually know where the code starts? On Linux, we can use the builtin readelf utility to actually see what’s in the ELF header, and the Linux Foundation has a page detailing the ELF header standard. So, we can use the LF page to figure out which bytes mean what, and the readelf command to “check our work”.
$ readelf -h fibonacci ELF Header: Magic: 7f 45 4c 46 01 02 01 00 00 00 00 00 00 00 00 00 Class: ELF32 Data: 2's complement, big endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: MIPS R3000 Version: 0x1 Entry point address: 0x4012cc Start of program headers: 52 (bytes into file) Start of section headers: 7596 (bytes into file) Flags: 0x1001, noreorder, o32, mips1 Size of this header: 52 (bytes) Size of program headers: 32 (bytes) Number of program headers: 5 Size of section headers: 40 (bytes) Number of section headers: 14 Section header string table index: 13
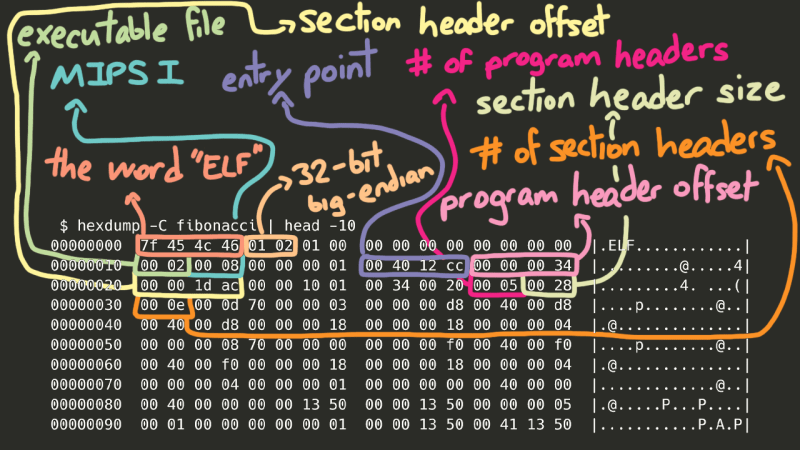
Now, there’s a lot of really interesting stuff here, but to save some time, the *really *important data here (besides the entry point, of course) are the section headers. Oversimplifying greatly, in order for our program to run correctly, we need to take certain chunks of the file and place them in certain parts of memory so our code can access them.

Using the readelf utility, we can actually see all of the sections in the file:
$ readelf -S fibonacci There are 14 section headers, starting at offset 0x1dac: Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al [ 0] NULL 00000000 000000 000000 00 0 0 0 [ 1] .MIPS.abiflags MIPS_ABIFLAGS 004000d8 0000d8 000018 18 A 0 0 8 [ 2] .reginfo MIPS_REGINFO 004000f0 0000f0 000018 18 A 0 0 4 [ 3] .note.gnu.build-i NOTE 00400108 000108 000024 00 A 0 0 4 [ 4] .text PROGBITS 00400130 000130 001200 00 AX 0 0 16 [ 5] .rodata PROGBITS 00401330 001330 000020 00 A 0 0 16 [ 6] .bss NOBITS 00411350 001350 000010 00 WA 0 0 16 [ 7] .comment PROGBITS 00000000 001350 000029 01 MS 0 0 1 [ 8] .pdr PROGBITS 00000000 00137c 000440 00 0 0 4 [ 9] .gnu.attributes GNU_ATTRIBUTES 00000000 0017bc 000010 00 0 0 1 [10] .mdebug.abi32 PROGBITS 00000000 0017cc 000000 00 0 0 1 [11] .symtab SYMTAB 00000000 0017cc 000380 10 12 14 4 [12] .strtab STRTAB 00000000 001b4c 0001db 00 0 0 1 [13] .shstrtab STRTAB 00000000 001d27 000085 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), I (info), L (link order), O (extra OS processing required), G (group), T (TLS), C (compressed), x (unknown), o (OS specific), E (exclude), p (processor specific)
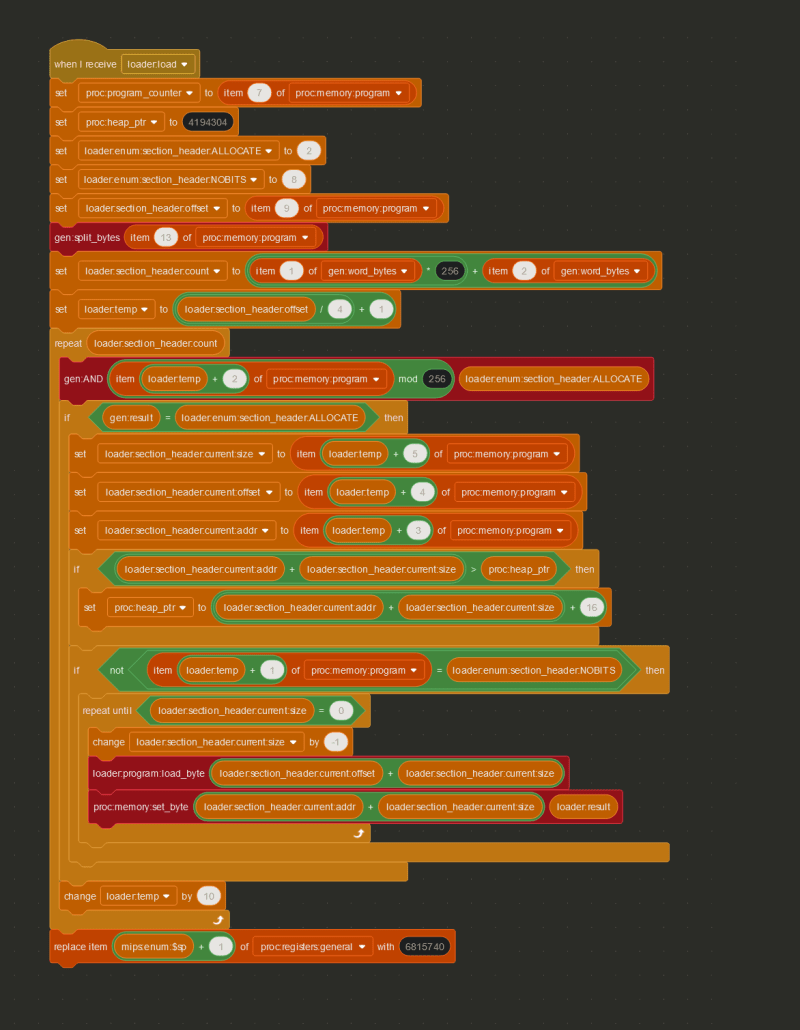
Going through all the details of the ELF format could be its own multi-part write-up, but using the Linux Foundation page on section headers, I was able to decipher the section header bytes of the program, and copy all the important bytes from the proc:memory:program variable to the correct places in memory, by checking whether or not the section header had the ALLOCATE flag set.
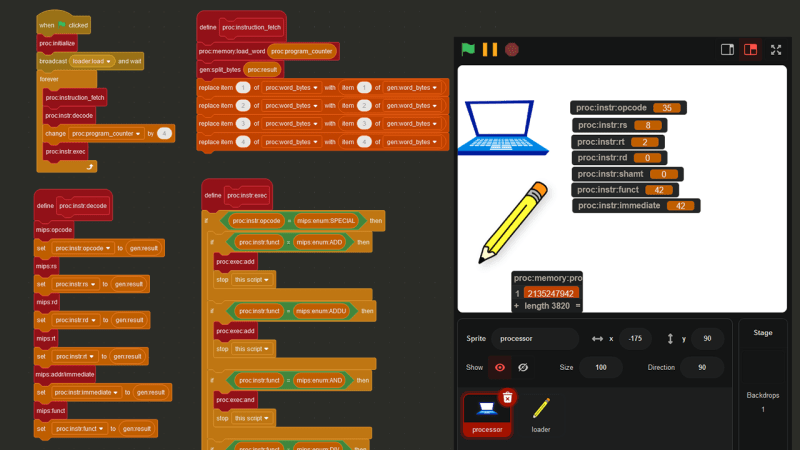
Fast-forwarding about a week to the point where all of the important instructions have been implemented, let’s take a look at the steps the processor (or really, any processor) needs to take in order to understand just one instruction, using 0x8D02002A (2365718570) as an example.
The first step is called **INSTRUCTION FETCH. **The current instruction is retrieved from the address stored in the proc:program_counter variable.
The next step is INSTRUCTION DECODE, where the instruction is decoded into its separate parts (see Step 1).
Finally, we reach EXECUTE, which, in my Scratch processor, is pretty much just a big if statement.
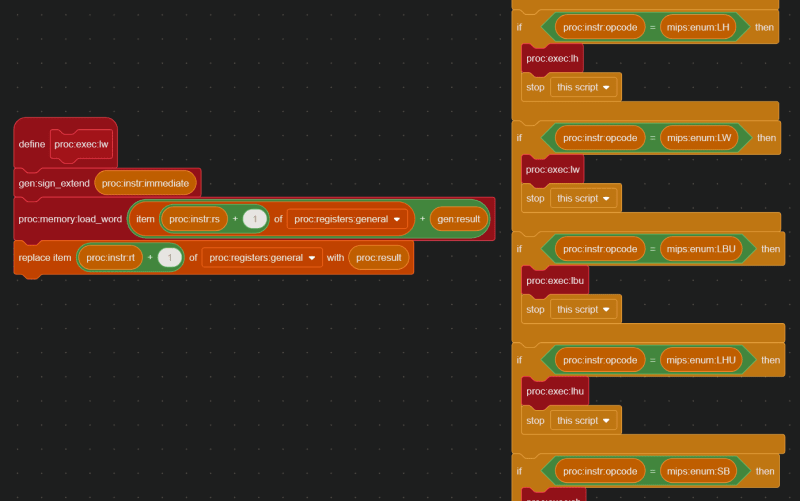
In this case, the INSTRUCTION DECODE step revealed that the opcode is 35, which means 0x8D02002A is a lw (load word) instruction. Therefore, based off the values in proc:instr:rs, proc:instr:rt, and proc:instr:immediate, the instruction 0x8D02002A actually means lw $2, 0x2a($8) , or in other words, lw $v0, 42($t0).
And here is the code that handles the lw instruction:
Okay, home stretch. Now, we just need to be able to do the bare minimum and create a “Hello, World” program in C, and run it in Scratch, and the last two weeks of my life will have been validated.
So, will this work?
#include <stdio.h>
int main() {
printf("Hello, world!");
return 0;
}
Three changes. First of all, the MIPS linker uses start to find the entry point of the program, much the same way you use main in C, or "main__" in Python. So, that’s an easy fix.
#include <stdio.h>
int __start() {
printf("Hello, world!");
return 0;
}
Next, we need some way to actually see this output in Scratch. We *could *make some intricate array of text sprites, but the simpler solution is just to use a list.
Finally, we can’t use stdio.h.
Yeah, basically, implementing floating point registers and multiprocessor instructions would have been more trouble than it was worth, so I skipped it, but the standard library kind of expects all that to be there. So, we need to make printf ourselves.
Putting the complications of variadic arguments and text formatting aside, how can you actually print a string using MIPS? The TL;DR is you put the address of the string in a certain register, and then a special “print string” value in another register, and then execute the syscall (“system call”) instruction, and let the OS/CPU handle the rest.
The exact special values and registers to use are implementation-dependent, and can be implemented pretty much any way you see fit, but I chose to replicate MARS’ (a very popular MIPS simulator) implementation. With MARS, the address of the string goes in $a0, and the value 4 goes in $v0 to say “hey, I want to print a string!”
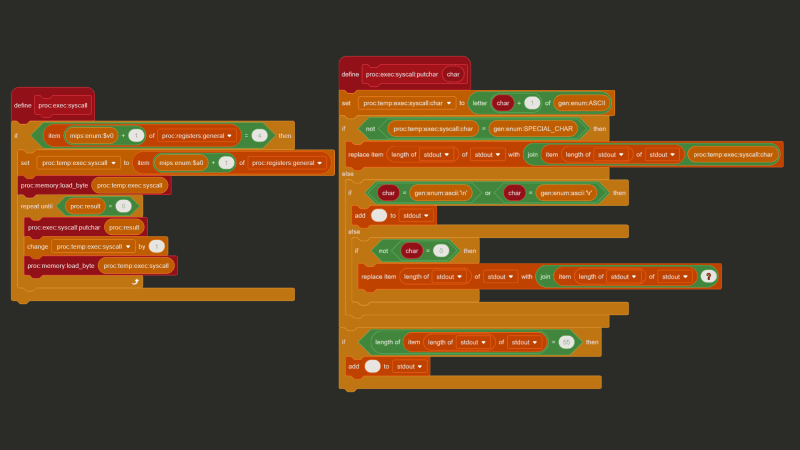
And with C, we can use a feature called “inline assembly” to inject assembly code directly into our compiled output. Putting it all together we get this:
#define puts _puts
void _puts(const char *s) {
__asm__(
"li $v0, 4\n"
"syscall\n"
:
: "a"(s)
);
}
int __start() {
puts("Hello, World!\n");
return 0;
}
And when we run it, we get this:
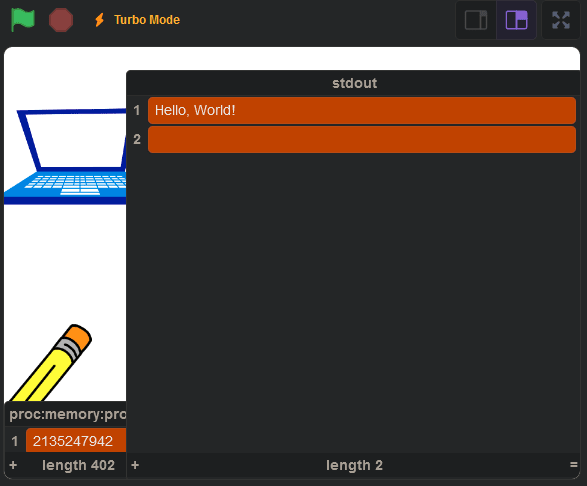
You can view the final product here: https://scratch.mit.edu/projects/1000840481/.
I wanted to keep this read under 15 minutes, so I had to skip over **a lot **of details. Some parts of the Scratch code had to be cut out of the screenshots for simplicity’s sake and I ran into a lot of silly and not-so-silly mistakes. If you’re curious how I was able to get Connect Four working (with minimax and alpha-beta pruning), the source code is on my Github. Here’s a quick list of some of the other problems I ran into in development:
* The fact that my computer is little-endian, but MIPS is big-endian caused more issues than I'd like to admit * The `mult` instruction in MIPS is 32-bit multiplication, and multiplying two 32-bit integers can result in a 64-bit integer. Javascript (and as a result, Scratch) is incapable of storing a 64-bit integer without losing precision. * The `u` in the `addu` instruction and the `u` in the `sltu` instruction both stand for "unsigned", but mean completely different things. * As you may have noticed, functions in Scratch don't have return values. This was quite annoying. * Any branch instruction (like "jump", "jump register", "branch on equals") in MIPS will also execute the instruction immediately after it, **regardless** of if the branch was taken or not. So, instead of updating the program count directly, the next address needs to be put in the "branch delay slot" and the program counter should only be updated after the *next* instruction. * Lists in Scratch are one-indexed. * All of a sudden, Scratch stopped letting me save the project to the cloud. It took awhile before I realized that lists filled with over 100,000 items wasn't something Scratch's servers were particularly excited to store. * I had to design my own `malloc` in C, which was fun, but also very difficult to debug in Scratch. * When I tried making syscalls that asked the user for input, all of the letters ended up capitalized. It turns out that in Scratch a lowercase `"a"` and a capital `"A"` are considered equal. I thought this was an unsolvable problem for awhile, before I realized that the names of sprites' costumes in Scratch are actually case-sensitive. So every time I try to convert a character to its ASCII value, I tell the processor sprite to switch to, for example, the `"a"` costume or the `"A"` costume, and then retrieve the costume number. * I made another syscall to print emojis to the `stdout`, but some emojis are considered two characters long and other emojis are considered one character long. * Compiling any code that calls `malloc` with -O1 crashes the CPU. I still have no idea why this is the case. * Endianness is really hard to get right. I know I said this in the beginning of the list, but it's worth repeating.
With all that said, I’m really happy with the way this project turned out. If you found this interesting, please check out sharc, my graphics engine built completely in Typescript: https://www.sharcjs.org. Because clearly, if there’s one thing I know how to make, it’s questionable decisions.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



