

Pan Yichen : Étudiant en première année de master à l'Université du Zhejiang. Kong Dehan : responsable de l'algorithme de modèle chez Cross Star Technology. Zhou Sida : Diplômé de l'Université de Nanchang en 2024, il étudiera pour une maîtrise à l'Université des sciences et technologies électroniques de Xi'an. Cui Cheng : diplômé en 2024 de l'Université de médecine traditionnelle chinoise du Zhejiang. Il étudiera pour une maîtrise à l'Université de Suzhou.
Pan Yichen, Zhou Sida et Cui Cheng ont réalisé conjointement les travaux de recherche de cet article en tant que stagiaires en algorithme chez Cross Star Technology.
À l'ère actuelle de développement technologique rapide, le Large Language Model (LLM) change la façon dont nous interagissons avec le monde numérique à une vitesse sans précédent. Les agents intelligents basés sur LLM (LLM Agents) sont progressivement intégrés dans nos vies, depuis les simples recherches d'informations jusqu'aux opérations complexes sur les pages Web. Cependant, une question clé reste ouverte : Lorsque ces agents LLM entreront dans le monde réel des réseaux en ligne, seront-ils aussi performants que prévu ?
La plupart des méthodes d'évaluation existantes restent au niveau d'ensembles de données statiques ou de sites Web simulés. Ces méthodes ont leur valeur, mais leurs limites sont évidentes : les ensembles de données statiques sont difficiles à capturer les changements dynamiques dans l'environnement Web, tels que les mises à jour d'interface et les itérations de contenu de sites Web, qui n'ont pas la complexité du monde réel et ne parviennent pas à prendre pleinement en compte les différents sites ; opérations, telles que l'utilisation des moteurs de recherche et d'autres opérations, ces facteurs sont indispensables dans les environnements réels.
Afin de résoudre ce problème, un article intitulé "WebCanvas : Benchmarking Web Agents
in Online Environments" a proposé un cadre d'évaluation en ligne innovant - WebCanvas, visant à comparer les performances des agents dans le monde réel en ligne. approche.

Lien papier : https://arxiv.org/pdf/2406.12373
Lien plateforme WebCanvas : https://imean.ai/web-canvas
Lien code projet : https : //github.com/iMeanAI/WebCanvas
Lien vers l'ensemble de données : https://huggingface.co/datasets/iMeanAI/Mind2Web-Live
L'une des innovations de WebCanvas est la proposition du concept de "nœuds clés" . Ce concept se concentre non seulement sur l'achèvement final de la tâche, mais approfondit également les détails du processus d'exécution de la tâche pour garantir l'exactitude de l'évaluation. WebCanvas offre une nouvelle perspective pour l'évaluation en ligne des agents en identifiant et en détectant les nœuds clés dans le flux de tâches, qu'il s'agisse d'atteindre une page Web spécifique ou d'effectuer une action spécifique (comme cliquer sur un bouton spécifique).

Schéma du cadre WebCanvas. Le côté gauche montre le processus d'étiquetage de la tâche et le côté droit montre le processus d'évaluation de la tâche. WebCanvas prend en compte le caractère non unique des chemins de tâches dans les interactions réseau en ligne, et le « trophée » représente le score de pas obtenu après avoir atteint avec succès chaque nœud clé.
Sur la base du framework WebCanvas, l'auteur a construit l'ensemble de données Mind2Web-Live, qui contient 542 tâches sélectionnées au hasard dans Mind2Web. L'auteur de cet article a également annoté les nœuds clés pour chaque tâche de l'ensemble de données. Grâce à une série d'expériences, nous avons constaté que lorsque l'Agent est équipé d'un module Mémoire, complété par le cadre de raisonnement ReAct, et équipé du modèle GPT-4-turbo, son taux de réussite des tâches augmente à 23,1 %. Nous sommes convaincus qu'avec l'évolution continue de la technologie, le potentiel de Web Agent est encore illimité et ce nombre sera bientôt dépassé.
Nœuds clés
Le concept de "nœuds clés" est l'une des idées fondamentales de WebCanvas. Les nœuds clés font référence aux étapes indispensables pour accomplir une tâche réseau spécifique, c'est-à-dire que ces étapes sont indispensables quel que soit le chemin pour accomplir la tâche. Ces étapes vont de la visite d'une page Web spécifique à l'exécution d'actions spécifiques sur la page, comme remplir un formulaire ou cliquer sur un bouton.
En prenant la partie verte du cadre WebCanvas comme exemple, l'utilisateur doit trouver le prochain film d'aventure le mieux noté sur le site Web de Rotten Tomatoes. Il peut le faire de différentes manières, par exemple en partant de la page d’accueil de Rotten Tomatoes ou en ciblant directement la page « films à venir » du moteur de recherche. Lors du filtrage des vidéos, un utilisateur peut d'abord sélectionner le genre « Aventure », puis trier par popularité, ou vice versa. Bien qu'il existe plusieurs chemins pour atteindre vos objectifs, accéder à une page spécifique et la filtrer fait partie intégrante de l'accomplissement de la tâche. Par conséquent, ces trois opérations sont définies comme des nœuds critiques pour cette tâche.
Indicateurs d'évaluation
Le système d'évaluation de WebCanvas est divisé en deux parties : le score d'étape et le score de tâche, qui constituent ensemble l'évaluation des capacités globales de WebAgent.
Step Score : Mesure les performances de l'Agent sur les nœuds clés. Chaque nœud clé est associé à une fonction d'évaluation, à travers trois cibles d'évaluation (URL, chemin de l'élément, valeur de l'élément) et trois fonctions de correspondance (exact, inclusion, sémantique). ) atteindre. Chaque fois qu'il atteint un nœud clé et réussit la fonction d'évaluation, l'Agent peut obtenir le score correspondant.

Aperçu des fonctions d'évaluation, où E représente l'élément Web Element
Score de tâche : divisé en score d'achèvement de tâche et score d'efficacité. Le score d'achèvement de la tâche indique si l'agent a réussi à obtenir tous les scores d'étape pour cette tâche. Le score d'efficacité prend en compte l'utilisation des ressources lors de l'exécution des tâches et est calculé comme le nombre moyen d'étapes requises pour noter chaque étape.
Ensemble de données Mind2Web-Live
L'auteur a sélectionné au hasard 601 tâches indépendantes du temps dans l'ensemble de formation Mind2Web et 179 tâches également indépendantes du temps dans le sous-ensemble de tâches croisées de l'ensemble de test, puis a combiné ces tâches. annoté dans des environnements en ligne réels. Enfin, l'auteur a construit un Ensemble de données Mind2Web-Live composé de 542 tâches, dont 438 échantillons de formation et 104 échantillons de test. La figure ci-dessous montre visuellement la distribution des résultats d'annotation et des fonctions d'évaluation.

Outil d'annotation de données
Pendant le processus d'annotation des données, l'auteur a utilisé le plug-in de navigateur iMean Builder développé par Chuanxingkong Technology. Ce plug-in peut enregistrer les comportements d'interaction de l'utilisateur avec le navigateur, y compris, mais sans s'y limiter, les clics, la saisie de texte, le survol, le glisser et d'autres actions. Il enregistre également le type d'opération spécifique, les paramètres d'exécution, le chemin de sélection de l'élément cible, ainsi que. contenu de l’élément et position des coordonnées de la page. De plus, iMean Builder génère également des captures d'écran de pages Web pour chaque étape de l'opération, offrant ainsi un affichage intuitif du flux de travail de vérification et de maintenance.
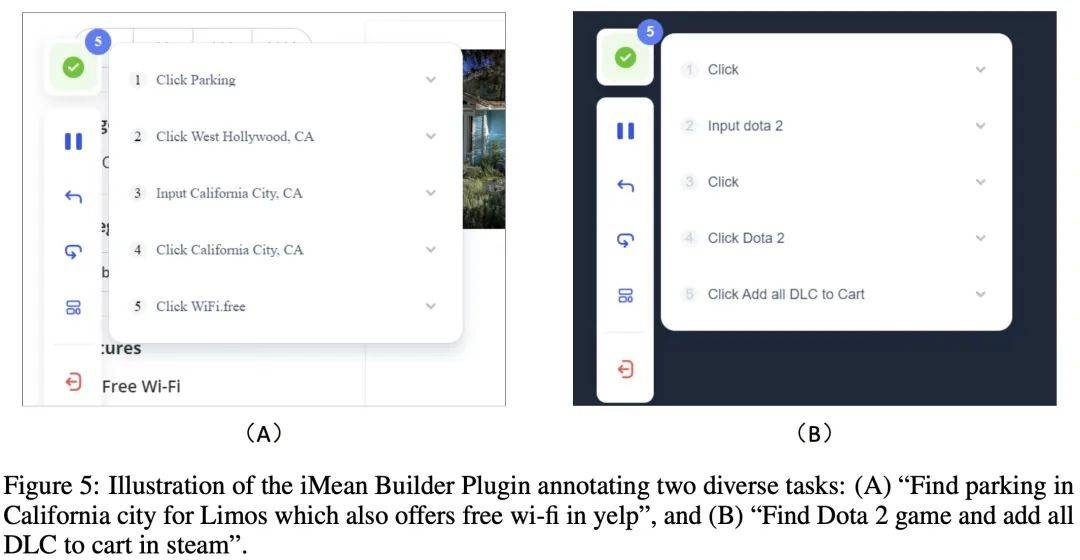
Exemple : Annotation de deux tâches différentes à l'aide du plugin iMean Builder. (A) Trouvez des parkings pour limousines en Californie qui offrent une connexion Wi-Fi gratuite sur Yelp, (B) Trouvez le jeu Dota 2 sur Steam et ajoutez tous les DLC à votre panier
Maintenance des données
L'environnement réseau évolue rapidement, les mises à jour du contenu du site Web, les ajustements de l’interface utilisateur et même les fermetures de sites sont inévitables et normaux. Ces changements peuvent faire perdre en actualité des tâches ou des nœuds clés précédemment définis, affectant ainsi la validité et l'équité de l'évaluation.
À cette fin, l'auteur a conçu un plan de maintenance des données visant à assurer la pertinence et l'exactitude continues de l'ensemble d'évaluation. Dans la phase de collecte de données, en plus de marquer les nœuds clés, le plug-in iMean Builder peut également enregistrer des informations détaillées sur chaque étape de l'exécution du flux de travail, notamment le type d'action, le chemin du sélecteur, la valeur de l'élément, la position des coordonnées, etc. L'utilisation ultérieure de la stratégie de correspondance d'éléments du SDK iMean Replay peut reproduire les actions du flux de travail et détecter et signaler rapidement toute condition non valide dans le flux de travail ou la fonction d'évaluation.
Grâce à cette solution, nous résolvons efficacement les défis causés par les échecs de processus, garantissons que l'ensemble de données d'évaluation peut s'adapter à l'évolution continue du monde en ligne et fournissons une base solide pour la capacité des agents d'évaluation automatisés.
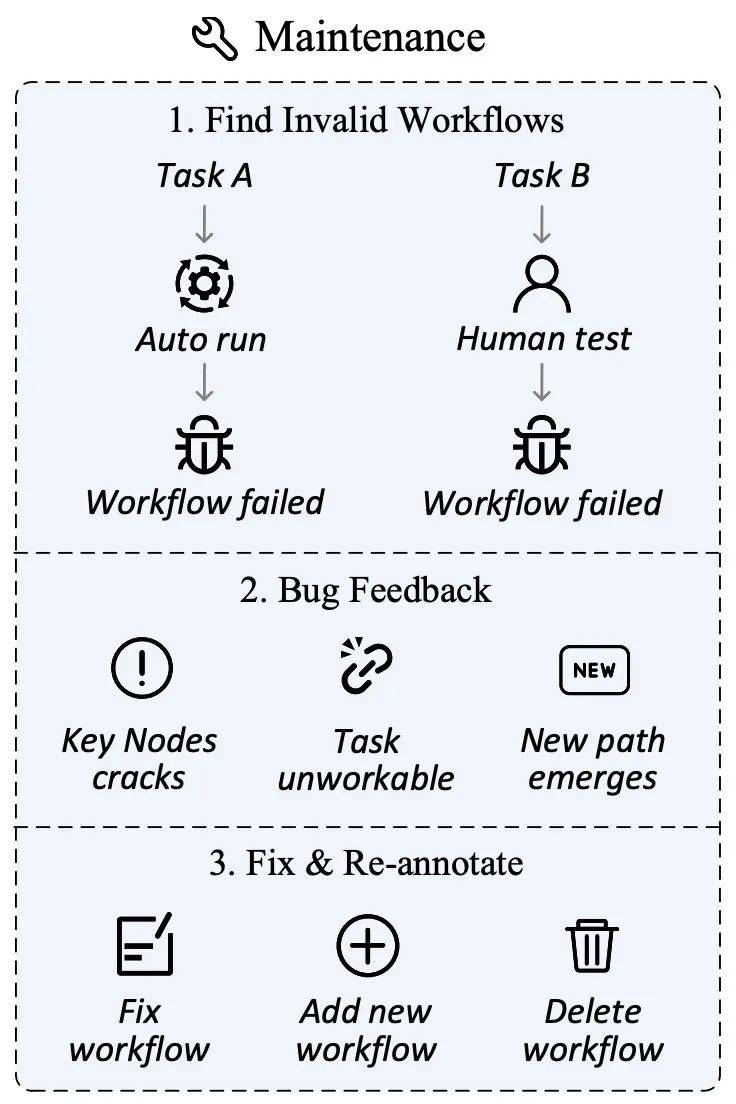
Plateforme de gestion des données
Sur le site Web WebCanvas, les utilisateurs peuvent parcourir clairement tous les processus de tâches enregistrés et leurs nœuds clés, et peuvent également rapidement signaler les processus ayant échoué à l'administrateur de la plate-forme pour garantir l'actualité et l'exactitude des données.
Dans le même temps, l'auteur encourage les membres de la communauté à participer activement et à construire conjointement un bon écosystème. Qu'il s'agisse de maintenir l'intégrité des données existantes, de développer des agents de test plus avancés ou même de créer des ensembles de données entièrement nouveaux, WebCanvas accueille les contributions de toutes sortes. Cela favorise non seulement l'amélioration de la qualité des données, mais encourage également l'innovation technologique, qui peut former un cercle vertueux pour promouvoir le développement de l'ensemble du domaine.
Page d'accueil WebCanvas
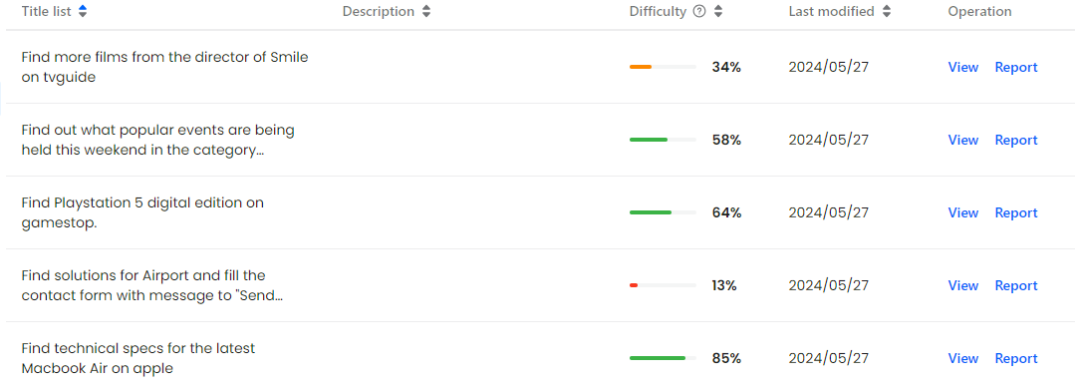
Affichage visuel de l'ensemble de données Mind2Web-Live
Basic Agent Framework
L'auteur a construit un cadre d'agent complet conçu pour optimiser l'efficacité d'exécution des tâches des agents dans les réseaux en ligne. dans l'environnement. Le cadre est principalement composé de quatre composants clés : modules de planification, d'observation, de mémoire et de récompense.
Planification : sur la base des entrées de l'arbre d'accessibilité, le module de planification utilise le cadre de raisonnement ReAct pour effectuer une inférence logique et générer des instructions d'opération spécifiques. La fonction principale de ce module est de fournir des pistes d'action basées sur l'état actuel et les objectifs de la tâche.
Observation : L'agent analyse le code source HTML fourni par le navigateur et le convertit en une arborescence d'accessibilité. Ce processus garantit que l'agent peut recevoir les informations de la page Web dans un format standardisé pour une analyse et une prise de décision ultérieures.
Mémoire : Le module Mémoire est chargé de stocker les données historiques de l'agent pendant l'exécution de la tâche, y compris, mais sans s'y limiter, le processus de réflexion de l'agent, les décisions passées, etc.
Récompense : le module Récompense peut évaluer le comportement de l'agent, y compris des commentaires sur la qualité de la prise de décision et donner des signaux d'achèvement des tâches.

Diagramme schématique du framework de base de l'agent
Expériences principales
L'auteur utilise le framework de base de l'agent et accède à différents LLM pour l'évaluation (à l'exclusion du module Reward). Les résultats expérimentaux sont présentés dans la figure ci-dessous, où le taux d'achèvement fait référence au taux de réalisation des nœuds clés et le taux de réussite des tâches fait référence au taux de réussite des tâches.
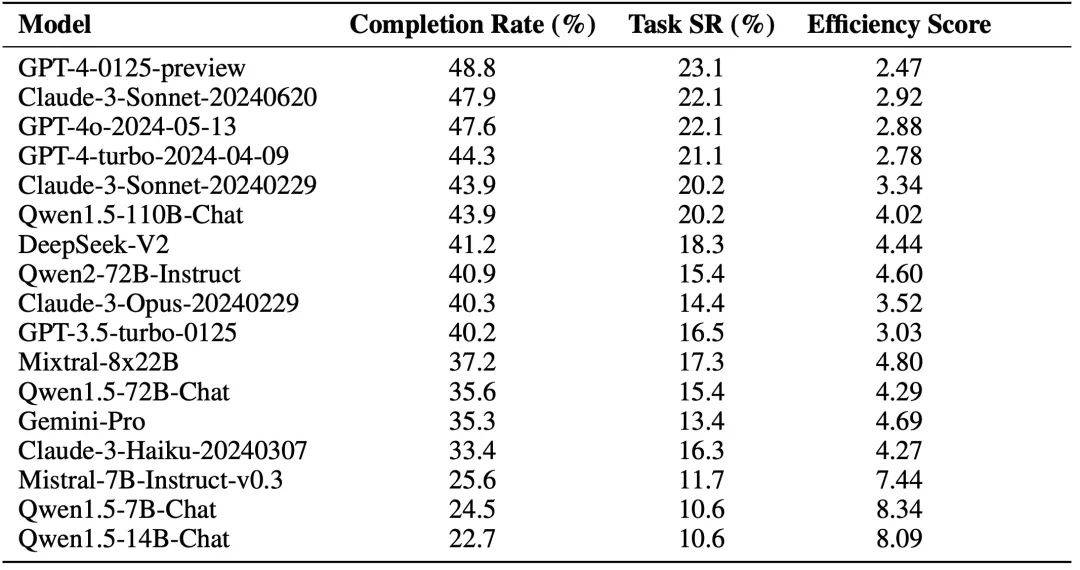

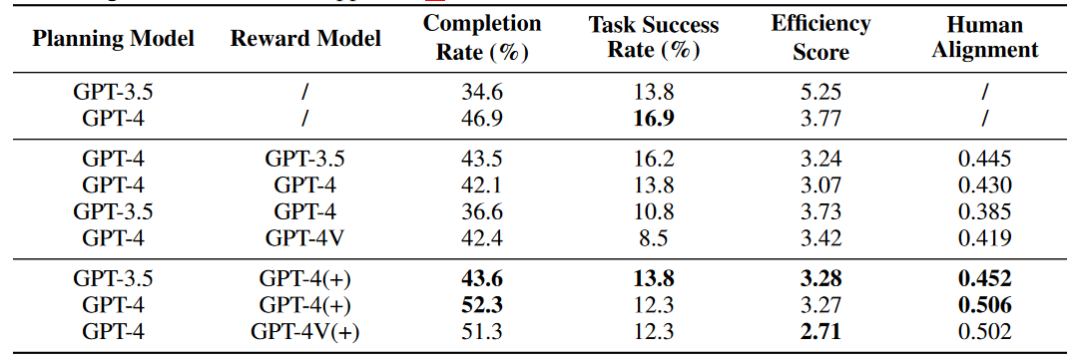
De plus, l'auteur a également exploré l'impact du module Récompense sur la capacité de l'Agent. Le signe (+) indique que les informations sur la Récompense contiennent des données d'annotation humaine et des informations sur les nœuds clés pour la référence de l'Agent. le score d'alignement humain représente le degré d'alignement de l'agent avec les humains. Les résultats des expériences préliminaires montrent que dans un environnement de réseau en ligne, Agent ne peut pas améliorer ses capacités via le module Self Reward, mais le module Reward qui intègre les données d'annotation d'origine peut améliorer les capacités de l'agent.
Analyse expérimentale
En annexe, l'auteur analyse les résultats expérimentaux. La figure suivante est la relation entre la complexité de la tâche et la difficulté de la tâche. La ligne orange représente le taux de réussite des nœuds clés avec la complexité de la tâche. trajectoire de changements croissants, tandis que la ligne bleue reflète la trajectoire du taux de réussite des tâches en fonction de la complexité des tâches.
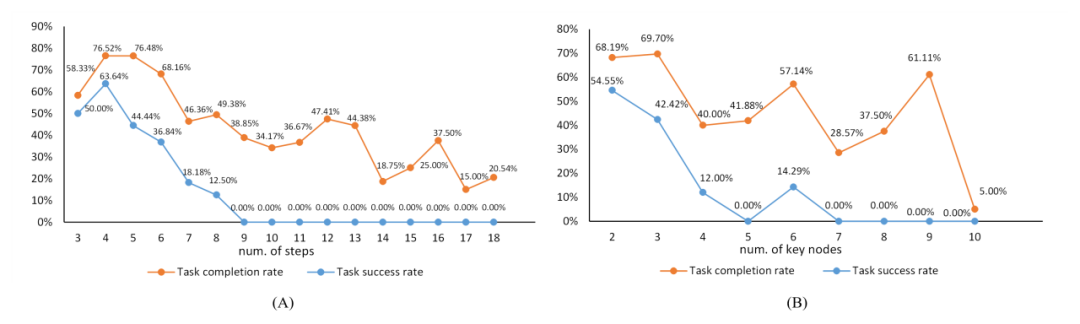
La relation entre la complexité des tâches et la difficulté des tâches. « nombre d'étapes » fait référence à la longueur de la séquence d'actions dans les données annotées, qui, avec le nombre de nœuds clés, sert de référence pour la complexité de la tâche.
Le tableau suivant montre la relation entre les résultats expérimentaux et les régions, les équipements et les systèmes.

Résumé
Sur le chemin visant à promouvoir le développement de la technologie LLM et Agent, il est crucial de construire un système d'évaluation qui s'adapte à l'environnement réseau réel. Cet article se concentre sur l’évaluation efficace des performances des agents dans un monde Internet en évolution rapide. Nous avons relevé le défi de front et atteint cet objectif en définissant les nœuds clés et les fonctions d'évaluation correspondantes dans un environnement ouvert, et en développant un système de maintenance des données pour réduire les coûts de maintenance ultérieurs.
Grâce à des efforts inlassables, nous avons pris des mesures substantielles pour établir un système d'évaluation en ligne robuste et précis. Cependant, mener des examens dans un cyberespace dynamique n’est pas facile, et cela introduit une série de problèmes complexes que l’on ne rencontre pas dans des scénarios fermés et hors ligne. Lors du processus d'évaluation de l'agent, nous avons rencontré des difficultés telles que des connexions réseau instables, un accès restreint au site Web et des limitations des fonctions d'évaluation. Ces problèmes mettent en évidence la tâche ardue d'évaluer les agents dans des environnements réels complexes, nous obligeant à affiner et à ajuster continuellement le cadre de raisonnement et d'évaluation de l'agent.
Nous appelons l'ensemble de la communauté de la recherche scientifique à travailler ensemble pour faire face aux défis inconnus et promouvoir l'innovation et l'amélioration des technologies d'évaluation. Nous sommes fermement convaincus que ces obstacles ne pourront être progressivement surmontés que grâce à la recherche et à la pratique continues. Nous sommes impatients de travailler main dans la main avec nos pairs pour créer une nouvelle ère d'agent LLM.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



