
 Périphériques technologiques
IA
Tous ces VLM sont-ils aveugles ? GPT-4o et Sonnet-3.5 ont successivement échoué au test de « vision »
Périphériques technologiques
IA
Tous ces VLM sont-ils aveugles ? GPT-4o et Sonnet-3.5 ont successivement échoué au test de « vision »
Tous ces VLM sont-ils aveugles ? GPT-4o et Sonnet-3.5 ont successivement échoué au test de « vision »

Les quatre grands VLM tentent tous de toucher aveuglément l'éléphant ?
Laissons les modèles SOTA les plus populaires (GPT-4o, Gemini-1.5, Sonnet-3, Sonnet-3.5) compter combien d'intersections il y a entre deux lignes. Seront-ils plus performants que les humains ?
La réponse est probablement non.
Depuis le lancement de GPT-4V, les modèles de langage visuel (VLM) ont fait de l'intelligence des grands modèles un grand pas en avant vers le niveau d'intelligence artificielle que nous imaginions.
Les VLM peuvent à la fois comprendre des images et utiliser un langage pour décrire ce qu'ils voient, et effectuer des tâches complexes basées sur ces compréhensions. Par exemple, si vous envoyez au modèle VLM une photo d'une table à manger et une photo d'un menu, il peut extraire le nombre de bouteilles de bière et le prix unitaire sur le menu à partir des deux images, et calculer combien coûte la bière pour le repas.
Les VLM ont progressé si vite qu'il est devenu une tâche pour le modèle de découvrir s'il y a des « éléments abstraits » déraisonnables dans cette image. Par exemple, il est nécessaire de demander au modèle d'identifier s'il y a une personne qui repasse. vêtements dans un taxi à grande vitesse. Une méthode d’évaluation courante.

Cependant, l'ensemble de tests de référence actuel n'évalue pas bien les capacités visuelles des VLM. En prenant MMMU comme exemple, 42,9 % des questions peuvent être résolues sans regarder des images, ce qui signifie que de nombreuses réponses peuvent être déduites uniquement à partir des questions et des options textuelles. Deuxièmement, les capacités actuellement démontrées par VLM sont en grande partie le résultat de la « mémorisation » de données Internet à grande échelle. Cela se traduit par des scores très élevés pour les VLM dans l'ensemble de tests, mais cela ne signifie pas que le jugement est vrai : les VLM peuvent-ils percevoir des images comme les humains ?
Afin d'obtenir la réponse à cette question, des chercheurs de l'Université d'Auburn et de l'Université de l'Alberta ont décidé de « tester la vision » des VLM. Inspirés par le « test de vision » de l'optométriste, ils ont demandé à quatre VLM de premier plan : GPT-4o, Gemini-1.5 Pro, Claude-3 Sonnet et Claude-3.5 Sonnet de créer une série de « questions de test de vision ».

Titre de l'article : Les modèles de langage de vision sont aveugles
Lien de l'article : https://arxiv.org/pdf/2407.06581
Lien du projet : https://vlmsareblind.github.io/
Cet ensemble de questions est très simple. Par exemple, compter le nombre d'intersections de deux lignes et identifier quelle lettre est marquée par un cercle rouge ne nécessite presque aucune connaissance du monde. Les résultats des tests sont choquants. Les VLM sont en réalité « myopes » et les détails de l’image sont en réalité flous à leur avis.
VLM Aveugle ou pas ? Sept tâches principales, vous pouvez les connaître avec un seul test
Afin d'empêcher les VLM de « copier les réponses » directement à partir des ensembles de données Internet, l'auteur de l'article a conçu un nouvel ensemble de « tests de vision ». Les auteurs de l'article ont choisi de laisser les VLM déterminer la relation entre les figures géométriques dans l'espace, par exemple si deux figures se croisent. Parce que les informations spatiales de ces motifs sur une toile blanche ne peuvent généralement pas être décrites en langage naturel.
Lorsque les humains traiteront ces informations, ils les percevront à travers le « cerveau visuel ». Mais pour les VLM, ils reposent sur la combinaison des fonctionnalités d'image et de texte dès les premières étapes du modèle, c'est-à-dire l'intégration de l'encodeur visuel dans un grand modèle de langage, qui est essentiellement un cerveau de connaissances sans yeux.
Des expériences préliminaires montrent que les VLM fonctionnent étonnamment bien lorsqu'ils sont confrontés à des tests de vision humaine, tels que la carte oculaire « E » à l'envers que chacun de nous a testée.
Test et résultats
Niveau 1 : Comptez combien d'intersections y a-t-il entre les lignes ?
L'auteur de l'article a créé 150 images contenant deux segments de ligne sur fond blanc. Les coordonnées x de ces segments de ligne sont fixes et équidistantes, tandis que les coordonnées y sont générées de manière aléatoire. Il n'y a que trois points d'intersection entre deux segments de droite : 0, 1 et 2.

Comme le montre la figure 5, lors du test de deux versions de mots d'invite et de trois versions d'épaisseur de segment de ligne, tous les VLM ont mal performé sur cette tâche simple.

Sonnet-3.5, qui a la meilleure précision, n'est que de 77,33% (voir tableau 1).

Plus précisément, les VLM ont tendance à moins fonctionner lorsque la distance entre deux lignes diminue (voir la figure 6 ci-dessous). Étant donné que chaque graphique linéaire est constitué de trois points clés, la distance entre deux lignes est calculée comme la distance moyenne de trois paires de points correspondantes.

Ce résultat contraste fortement avec la grande précision des VLM sur ChartQA, qui montre que les VLM sont capables d'identifier la tendance globale du graphique linéaire, mais ne peuvent pas « zoomer » pour voir des détails tels que « quelles lignes se croisent ». ".
Deuxième niveau : Déterminer la relation de position entre deux cercles
Comme le montre l'image, l'auteur de l'article a généré aléatoirement deux cercles de même taille sur une toile d'une taille donnée. Il n'y a que trois situations dans la relation de position entre deux cercles : intersection, tangence et séparation. 
Étonnamment, dans cette tâche intuitivement visible par les humains et dont la réponse est visible d'un seul coup d'œil, aucun VLM ne peut donner la réponse parfaitement (voir Figure 7).

Le modèle avec la meilleure précision (92,78%) est Gemini-1.5 (voir tableau 2).

Dans les expériences, une situation s'est produite fréquemment : lorsque deux cercles sont très proches, les VLM ont tendance à avoir de mauvais résultats mais à faire des suppositions éclairées. Comme le montre la figure ci-dessous, Sonnet-3.5 répond généralement à un « non » conservateur.

Comme le montre la figure 8, même lorsque la distance entre les deux cercles est très éloignée et a un rayon (d = 0,5) aussi large que celui-là, GPT-4o, qui a la pire précision, ne peut pas atteindre 100 % précis.
Cela dit, la vision de VLM ne semble pas suffisamment claire pour voir les petits écarts ou intersections entre les deux cercles.

Niveau 3 : Combien de lettres sont entourées en rouge ?
Étant donné que la distance entre les lettres d'un mot est très petite, les auteurs de l'article ont émis l'hypothèse que si les VLM sont « myopes », alors ils ne seront pas capables de reconnaître les lettres entourées en rouge.
Alors, ils ont choisi des chaînes comme « Acknowledgement », « Subdermatoglyphic » et « tHyUiKaRbNqWeOpXcZvM ». Générez aléatoirement un cercle rouge pour encercler une lettre dans la chaîne à titre de test.

Les résultats des tests montrent que les modèles testés ont très mal fonctionné à ce niveau (voir Figure 9 et Tableau 3).


Par exemple, les modèles de langage visuel ont tendance à faire des erreurs lorsque les lettres sont légèrement obscurcies par des cercles rouges. Ils confondent souvent les lettres à côté du cercle rouge. Parfois, le modèle produira des hallucinations. Par exemple, même s'il peut épeler le mot avec précision, il ajoutera des caractères tronqués (par exemple, "9", "n", "©") au mot.

Tous les modèles, à l'exception de GPT-4o, ont obtenu des résultats légèrement meilleurs sur les mots que sur les chaînes aléatoires, ce qui suggère que connaître l'orthographe d'un mot peut aider les modèles de langage visuel à porter des jugements, améliorant ainsi légèrement la précision.
Gemini-1.5 et Sonnet-3.5 sont les deux meilleurs modèles avec des taux de précision de 92,81 % et 89,22 % respectivement, et surpassent GPT-4o et Sonnet-3 de près de 20 %.

Niveau 4 et Niveau 5 : Combien y a-t-il de formes qui se chevauchent ? Combien y a-t-il de carrés « matriochka » ?
En supposant que les VLM soient « myopes », ils pourraient ne pas être en mesure de voir clairement l'intersection entre chacun des deux cercles selon un motif similaire aux « anneaux olympiques ». À cette fin, l'auteur de l'article a généré de manière aléatoire 60 groupes de motifs similaires aux « anneaux olympiques » et a demandé aux VLM de compter combien de motifs se chevauchaient. Ils ont également généré une version pentagonale des « anneaux olympiques » pour des tests plus approfondis.

Étant donné que les VLM fonctionnent mal lors du comptage du nombre de cercles qui se croisent, les auteurs ont testé en outre le cas où les bords du motif ne se croisent pas et où chaque forme est complètement imbriquée dans une autre forme. Ils ont généré un motif de type « matriochka » de 2 à 5 carrés et ont demandé aux VLM de compter le nombre total de carrés dans l'image.

Il est facile de constater aux croix rouge vif du tableau ci-dessous que ces deux niveaux sont également des obstacles insurmontables pour les VLM.

Dans le test des carrés imbriqués, la précision de chaque modèle varie considérablement : GPT-4o (précision 48,33%) et Sonnet-3 (précision 55,00%) sont au moins meilleurs que Gemini-1.5 (précision 80,00%) et Sonnet-3,5 (précision de 87,50 %) est inférieur de 30 points de pourcentage.
Cet écart sera plus grand lorsque le modèle compte les cercles et les pentagones qui se chevauchent, mais Sonnet-3.5 fonctionne plusieurs fois mieux que les autres modèles. Comme le montre le tableau ci-dessous, lorsque l’image est un pentagone, la précision de Sonnet-3.5 de 75,83 % dépasse de loin celle de Gemini-1.5 de 9,16 %.
Étonnamment, les quatre modèles testés ont atteint une précision de 100 % en comptant 5 anneaux, mais l'ajout d'un seul anneau supplémentaire a suffi à faire chuter la précision de manière significative jusqu'à près de zéro.
Cependant, lors du calcul de pentagones, tous les VLM (sauf Sonnet-3.5) fonctionnent mal même lors du calcul de 5 pentagones. Dans l'ensemble, calculer 6 à 9 formes (y compris des cercles et des pentagones) est difficile pour tous les modèles.

Cela montre que VLM est partial et qu'ils sont plus enclins à produire les fameux "anneaux olympiques" comme résultat. Par exemple, Gemini-1.5 prédira le résultat comme « 5 » dans 98,95 % des essais, quel que soit le nombre réel de cercles (voir tableau 5). Pour d’autres modèles, cette erreur de prédiction se produit beaucoup plus fréquemment pour les anneaux que pour les pentagones.

En plus de la quantité, VLM a également différentes « préférences » dans la couleur des formes.
GPT-4o fonctionne mieux sur les formes colorées que sur les formes noires pures, tandis que Sonnet-3.5 prédit de mieux en mieux à mesure que la taille de l'image augmente. Cependant, lorsque les chercheurs ont modifié la couleur et la résolution de l’image, la précision des autres modèles n’a que légèrement changé.
Il convient de noter que dans la tâche de calcul des carrés imbriqués, même si le nombre de carrés n'est que de 2-3, GPT-4o et Sonnet-3 sont encore difficiles à calculer. Lorsque le nombre de carrés augmente jusqu’à quatre ou cinq, tous les modèles sont loin d’atteindre une précision de 100 %. Cela montre qu'il est difficile pour VLM d'extraire avec précision la forme cible même si les bords des formes ne se croisent pas.

Niveau 6 : Comptez combien de lignes y a-t-il dans le tableau ? Combien y a-t-il de colonnes ?
Bien que les VLM aient du mal à chevaucher ou à imbriquer des graphiques, que considèrent-ils comme des motifs de mosaïque ? Dans l'ensemble de tests de base, en particulier DocVQA, qui contient de nombreuses tâches tabulaires, la précision des modèles testés est ≥90 %. L'auteur de l'article a généré de manière aléatoire 444 tableaux avec différents nombres de lignes et de colonnes, et a demandé aux VLM de compter combien de lignes il y avait dans le tableau ? Combien y a-t-il de colonnes ?
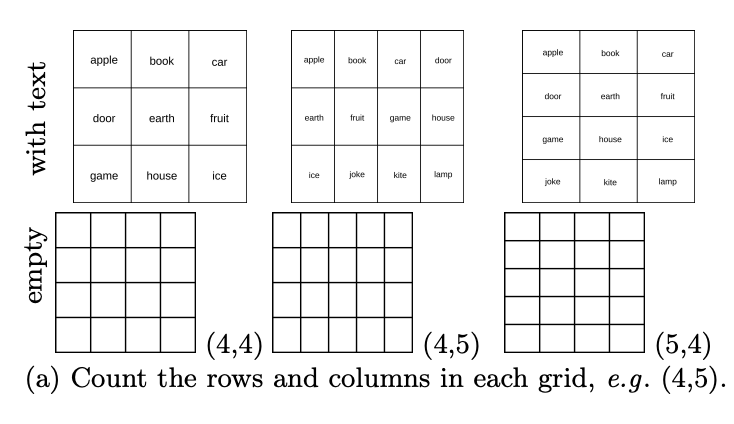
Les résultats montrent que bien qu'il ait obtenu des scores élevés dans l'ensemble de données de base, comme le montre la figure ci-dessous, VLM a également obtenu de mauvais résultats en matière de comptage des lignes et des colonnes dans les tableaux vides.

Plus précisément, ils sont généralement à 1 ou 2 barres de distance. Comme le montre la figure ci-dessous, GPT-4o reconnaît la grille 4×5 comme 4×4 et Gemini-1.5 la reconnaît comme 5×5.

Cela montre que même si les VLM peuvent extraire le contenu important des tableaux pour répondre aux questions liées aux tableaux dans DocVQA, ils ne peuvent pas identifier clairement les tableaux cellule par cellule.
Cela peut être dû au fait que les tables du document sont pour la plupart non vides et que VLM n'est pas utilisé pour vider les tables. Fait intéressant, après que les chercheurs ont simplifié la tâche en essayant d'ajouter un mot à chaque cellule, une amélioration significative de la précision a été observée pour tous les VLM, par exemple, GPT-4o est passé de 26,13 % à 53,03 % (voir Tableau 6). Cependant, dans ce cas, les performances du modèle testé ne sont toujours pas parfaites. Comme le montrent les figures 15a et b, le modèle le plus performant (Sonnet-3.5) a obtenu des résultats de 88,68 % dans les grilles contenant du texte et de 59,84 % dans les grilles vides.
Et la plupart des modèles (Gemini-1.5, Sonnet-3 et Sonnet-3.5) fonctionnent systématiquement mieux dans le comptage des colonnes que dans le comptage des lignes (voir Figures 15c et d).

Niveau 7 : Combien y a-t-il de lignes de métro directes du point de départ à la destination ?
Ce test teste la capacité des VLM à suivre des chemins, ce qui est crucial pour que le modèle puisse interpréter des cartes, des graphiques et comprendre les annotations telles que les flèches ajoutées par les utilisateurs dans les images d'entrée. À cette fin, l’auteur de l’article a généré de manière aléatoire 180 plans de lignes de métro, chacune comportant quatre stations fixes. Ils ont demandé aux VLM de compter le nombre de chemins monochromatiques entre deux sites.

Les résultats des tests sont choquants. Même si le chemin entre les deux sites est simplifié à un seul, tous les modèles ne peuvent pas atteindre une précision à 100 %. Comme le montre le tableau 7, le modèle le plus performant est Sonnet-3.5 avec une précision de 95 % ; le modèle le moins performant est Sonnet-3 avec une précision de 23,75 % ;

Il n'est pas difficile de voir sur la figure ci-dessous que la prédiction du VLM présente généralement un écart de 1 à 3 chemins. À mesure que la complexité de la carte passe de 1 à 3 chemins, les performances de la plupart des VLM se détériorent.

Face au « fait brutal » selon lequel le VLM grand public d'aujourd'hui fonctionne extrêmement mal en matière de reconnaissance d'image, de nombreux internautes ont d'abord mis de côté leur statut d'« avocats de la défense de l'IA » et ont laissé de nombreux commentaires pessimistes.
Un internaute a déclaré : « Il est embarrassant que les modèles SOTA (GPT-4o, Gemini-1.5 Pro, Sonnet-3, Sonnet-3.5) fonctionnent si mal, et ces modèles prétendent en fait dans leur promotion : ils peuvent comprendre les images pour ? Par exemple, ils pourraient être utilisés pour aider les aveugles ou enseigner la géométrie aux enfants ! Avec environ 100 000 exemples et formé avec des données réelles, le problème est résolu
L'auteur de l'article a également reçu d'autres questions quant à savoir si ce test est scientifique.
 Cependant, les "défenseurs de l'IA" et les "pessimistes de l'IA" ont reconnu que VLM fonctionne toujours bien dans le test d'image. des défauts extrêmement difficiles à concilier.
Cependant, les "défenseurs de l'IA" et les "pessimistes de l'IA" ont reconnu que VLM fonctionne toujours bien dans le test d'image. des défauts extrêmement difficiles à concilier. 
En fait, les défis rencontrés par ces modèles de langage visuel (VLM) dans la gestion de telles tâches peuvent avoir davantage à voir avec leurs capacités de raisonnement et la façon dont ils interprètent le contenu de l'image, plutôt qu'un simple problème de résolution visuelle. En d’autres termes, même si chaque détail d’une image est clairement visible, les modèles peuvent ne pas être en mesure d’accomplir ces tâches avec précision s’ils ne disposent pas d’une logique de raisonnement correcte ou d’une compréhension approfondie des informations visuelles. Par conséquent, cette recherche devra peut-être approfondir les capacités des VLM en matière de compréhension visuelle et de raisonnement, plutôt que simplement leurs capacités de traitement d’images.
Certains internautes pensent que si la vision humaine est traitée par convolution, les humains eux-mêmes rencontreront également des difficultés pour juger de l'intersection des lignes.
Pour plus d'informations, veuillez vous référer au document original.
Liens de référence :
https://arxiv.org/pdf/2407.06581
https://news.ycombinator.com/item?id=40926734
https://vlmsareblind.github.io/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Mais peut-être qu’il ne pourra pas vaincre le vieil homme dans le parc ? Les Jeux Olympiques de Paris battent leur plein et le tennis de table suscite beaucoup d'intérêt. Dans le même temps, les robots ont également réalisé de nouvelles avancées dans le domaine du tennis de table. DeepMind vient tout juste de proposer le premier agent robot apprenant capable d'atteindre le niveau des joueurs amateurs humains de tennis de table de compétition. Adresse papier : https://arxiv.org/pdf/2408.03906 Quelle est la capacité du robot DeepMind à jouer au tennis de table ? Probablement à égalité avec les joueurs amateurs humains : tant en coup droit qu'en revers : l'adversaire utilise une variété de styles de jeu, et le robot peut également résister : recevoir des services avec des tours différents : Cependant, l'intensité du jeu ne semble pas aussi intense que le vieil homme dans le parc. Pour les robots, le tennis de table
 La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
Le 21 août, la Conférence mondiale sur les robots 2024 s'est tenue en grande pompe à Pékin. La marque de robots domestiques de SenseTime, "Yuanluobot SenseRobot", a dévoilé toute sa famille de produits et a récemment lancé le robot de jeu d'échecs Yuanluobot AI - Chess Professional Edition (ci-après dénommé "Yuanluobot SenseRobot"), devenant ainsi le premier robot d'échecs au monde pour le maison. En tant que troisième produit robot jouant aux échecs de Yuanluobo, le nouveau robot Guoxiang a subi un grand nombre de mises à niveau techniques spéciales et d'innovations en matière d'IA et de machines d'ingénierie. Pour la première fois, il a réalisé la capacité de ramasser des pièces d'échecs en trois dimensions. grâce à des griffes mécaniques sur un robot domestique et effectuer des fonctions homme-machine telles que jouer aux échecs, tout le monde joue aux échecs, réviser la notation, etc.
 Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
La rentrée scolaire est sur le point de commencer, et ce ne sont pas seulement les étudiants qui sont sur le point de commencer le nouveau semestre qui doivent prendre soin d’eux-mêmes, mais aussi les grands modèles d’IA. Il y a quelque temps, Reddit était rempli d'internautes se plaignant de la paresse de Claude. « Son niveau a beaucoup baissé, il fait souvent des pauses et même la sortie devient très courte. Au cours de la première semaine de sortie, il pouvait traduire un document complet de 4 pages à la fois, mais maintenant il ne peut même plus produire une demi-page. !" https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dans un post intitulé "Totalement déçu par Claude", plein de
 Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference qui se tient à Pékin, l'exposition de robots humanoïdes est devenue le centre absolu de la scène. Sur le stand Stardust Intelligent, l'assistant robot IA S1 a réalisé trois performances majeures de dulcimer, d'arts martiaux et de calligraphie. un espace d'exposition, capable à la fois d'arts littéraires et martiaux, a attiré un grand nombre de publics professionnels et de médias. Le jeu élégant sur les cordes élastiques permet au S1 de démontrer un fonctionnement fin et un contrôle absolu avec vitesse, force et précision. CCTV News a réalisé un reportage spécial sur l'apprentissage par imitation et le contrôle intelligent derrière "Calligraphy". Le fondateur de la société, Lai Jie, a expliqué que derrière les mouvements soyeux, le côté matériel recherche le meilleur contrôle de la force et les indicateurs corporels les plus humains (vitesse, charge). etc.), mais du côté de l'IA, les données réelles de mouvement des personnes sont collectées, permettant au robot de devenir plus fort lorsqu'il rencontre une situation forte et d'apprendre à évoluer rapidement. Et agile
 Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Les contributeurs ont beaucoup gagné de cette conférence ACL. L'ACL2024, d'une durée de six jours, se tient à Bangkok, en Thaïlande. ACL est la plus grande conférence internationale dans le domaine de la linguistique informatique et du traitement du langage naturel. Elle est organisée par l'Association internationale pour la linguistique informatique et a lieu chaque année. L'ACL s'est toujours classée première en termes d'influence académique dans le domaine de la PNL, et c'est également une conférence recommandée par le CCF-A. La conférence ACL de cette année est la 62e et a reçu plus de 400 travaux de pointe dans le domaine de la PNL. Hier après-midi, la conférence a annoncé le meilleur article et d'autres récompenses. Cette fois, il y a 7 Best Paper Awards (deux inédits), 1 Best Theme Paper Award et 35 Outstanding Paper Awards. La conférence a également décerné 3 Resource Paper Awards (ResourceAward) et Social Impact Award (
 L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
Intégration profonde de la vision et de l'apprentissage des robots. Lorsque deux mains de robot travaillent ensemble en douceur pour plier des vêtements, verser du thé et emballer des chaussures, associées au robot humanoïde 1X NEO qui a fait la une des journaux récemment, vous pouvez avoir le sentiment : nous semblons entrer dans l'ère des robots. En fait, ces mouvements soyeux sont le produit d’une technologie robotique avancée + d’une conception de cadre exquise + de grands modèles multimodaux. Nous savons que les robots utiles nécessitent souvent des interactions complexes et exquises avec l’environnement, et que l’environnement peut être représenté comme des contraintes dans les domaines spatial et temporel. Par exemple, si vous souhaitez qu'un robot verse du thé, le robot doit d'abord saisir la poignée de la théière et la maintenir verticalement sans renverser le thé, puis la déplacer doucement jusqu'à ce que l'embouchure de la théière soit alignée avec l'embouchure de la tasse. , puis inclinez la théière selon un certain angle. ce
 Conférence sur l'intelligence artificielle distribuée Appel à communications DAI 2024 : Agent Day, Richard Sutton, le père de l'apprentissage par renforcement, sera présent ! Yan Shuicheng, Sergey Levine et les scientifiques de DeepMind prononceront des discours d'ouverture
Aug 22, 2024 pm 08:02 PM
Conférence sur l'intelligence artificielle distribuée Appel à communications DAI 2024 : Agent Day, Richard Sutton, le père de l'apprentissage par renforcement, sera présent ! Yan Shuicheng, Sergey Levine et les scientifiques de DeepMind prononceront des discours d'ouverture
Aug 22, 2024 pm 08:02 PM
Introduction à la conférence Avec le développement rapide de la science et de la technologie, l'intelligence artificielle est devenue une force importante dans la promotion du progrès social. À notre époque, nous avons la chance d’être témoins et de participer à l’innovation et à l’application de l’intelligence artificielle distribuée (DAI). L’intelligence artificielle distribuée est une branche importante du domaine de l’intelligence artificielle, qui a attiré de plus en plus d’attention ces dernières années. Les agents basés sur de grands modèles de langage (LLM) ont soudainement émergé. En combinant les puissantes capacités de compréhension du langage et de génération des grands modèles, ils ont montré un grand potentiel en matière d'interaction en langage naturel, de raisonnement par connaissances, de planification de tâches, etc. AIAgent reprend le grand modèle de langage et est devenu un sujet brûlant dans le cercle actuel de l'IA. Au
 Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Cet après-midi, Hongmeng Zhixing a officiellement accueilli de nouvelles marques et de nouvelles voitures. Le 6 août, Huawei a organisé la conférence de lancement de nouveaux produits Hongmeng Smart Xingxing S9 et Huawei, réunissant la berline phare intelligente panoramique Xiangjie S9, le nouveau M7Pro et Huawei novaFlip, MatePad Pro 12,2 pouces, le nouveau MatePad Air, Huawei Bisheng With de nombreux nouveaux produits intelligents tous scénarios, notamment la série d'imprimantes laser X1, FreeBuds6i, WATCHFIT3 et l'écran intelligent S5Pro, des voyages intelligents, du bureau intelligent aux vêtements intelligents, Huawei continue de construire un écosystème intelligent complet pour offrir aux consommateurs une expérience intelligente du Internet de tout. Hongmeng Zhixing : Autonomisation approfondie pour promouvoir la modernisation de l'industrie automobile intelligente Huawei s'associe à ses partenaires de l'industrie automobile chinoise pour fournir
