

Boosting est une technique d'apprentissage d'ensemble utilisée en apprentissage automatique pour améliorer la précision des modèles. Il combine plusieurs classificateurs faibles (modèles qui fonctionnent légèrement mieux que les devinettes aléatoires) pour créer un classificateur puissant. L'objectif principal du boosting est d'appliquer séquentiellement les classificateurs faibles aux données, en corrigeant les erreurs commises par les classificateurs précédents, et ainsi d'améliorer les performances globales.
AdaBoost, abréviation de Adaptive Boosting, est un algorithme de boosting populaire. Il ajuste les poids des instances mal classées afin que les classificateurs suivants se concentrent davantage sur les cas difficiles. L'objectif principal d'AdaBoost est d'améliorer les performances des classificateurs faibles en mettant l'accent sur les exemples difficiles à classer à chaque itération.
Initialiser les poids :
Classificateur faible de train :
Calculer l'erreur du classificateur :
Calculer le poids du classificateur :
Mettre à jour les poids des instances :
Combiner les classificateurs faibles :
AdaBoost, abréviation de Adaptive Boosting, est une technique d'ensemble qui combine plusieurs classificateurs faibles pour créer un classificateur fort. Cet exemple montre comment implémenter AdaBoost pour la classification binaire à l'aide de données synthétiques, évaluer les performances du modèle et visualiser la limite de décision.
1. Importer des bibliothèques
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
Ce bloc importe les bibliothèques nécessaires à la manipulation des données, au traçage et à l'apprentissage automatique.
2. Générer des exemples de données
np.random.seed(42) # For reproducibility # Generate synthetic data for 2 classes n_samples = 1000 n_samples_per_class = n_samples // 2 # Class 0: Centered around (-1, -1) X0 = np.random.randn(n_samples_per_class, 2) * 0.7 + [-1, -1] # Class 1: Centered around (1, 1) X1 = np.random.randn(n_samples_per_class, 2) * 0.7 + [1, 1] # Combine the data X = np.vstack([X0, X1]) y = np.hstack([np.zeros(n_samples_per_class), np.ones(n_samples_per_class)]) # Shuffle the dataset shuffle_idx = np.random.permutation(n_samples) X, y = X[shuffle_idx], y[shuffle_idx]
Ce bloc génère des données synthétiques avec deux fonctionnalités, où la variable cible y est définie en fonction du centre de classe, simulant un scénario de classification binaire.
3. Diviser l'ensemble de données
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Ce bloc divise l'ensemble de données en ensembles de formation et de test pour l'évaluation du modèle.
4. Créer et entraîner le classificateur AdaBoost
base_estimator = DecisionTreeClassifier(max_depth=1) # Decision stump model = AdaBoostClassifier(estimator=base_estimator, n_estimators=3, random_state=42) model.fit(X_train, y_train)
Ce bloc initialise le modèle AdaBoost avec une souche de décision comme estimateur de base et l'entraîne à l'aide de l'ensemble de données d'entraînement.
5. Faire des pronostics
y_pred = model.predict(X_test)
Ce bloc utilise le modèle entraîné pour faire des prédictions sur l'ensemble de test.
6. Évaluer le modèle
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
print("\nConfusion Matrix:")
print(conf_matrix)
print("\nClassification Report:")
print(class_report)
Sortie :
Accuracy: 0.9400
Confusion Matrix:
[[96 8]
[ 4 92]]
Classification Report:
precision recall f1-score support
0.0 0.96 0.92 0.94 104
1.0 0.92 0.96 0.94 96
accuracy 0.94 200
macro avg 0.94 0.94 0.94 200
weighted avg 0.94 0.94 0.94 200
Ce bloc calcule et imprime la précision, la matrice de confusion et le rapport de classification, fournissant ainsi un aperçu des performances du modèle.
7. Visualisez la limite de décision
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z, alpha=0.4, cmap='RdYlBu')
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, cmap='RdYlBu', edgecolor='black')
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("AdaBoost Binary Classification")
plt.colorbar(scatter)
plt.show()
This block visualizes the decision boundary created by the AdaBoost model, illustrating how the model separates the two classes in the feature space.
Output:

This structured approach demonstrates how to implement and evaluate AdaBoost for binary classification tasks, providing a clear understanding of its capabilities. The visualization of the decision boundary aids in interpreting the model's predictions.
AdaBoost is an ensemble learning technique that combines multiple weak classifiers to create a strong classifier. This example demonstrates how to implement AdaBoost for multiclass classification using synthetic data, evaluate the model's performance, and visualize the decision boundary for five classes.
1. Import Libraries
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
This block imports the necessary libraries for data manipulation, plotting, and machine learning.
2. Generate Sample Data with 5 Classes
np.random.seed(42) # For reproducibility
n_samples = 2500 # Total number of samples
n_samples_per_class = n_samples // 5 # Ensure this is exactly n_samples // 5
# Class 0: Centered around (-2, -2)
X0 = np.random.randn(n_samples_per_class, 2) * 0.5 + [-2, -2]
# Class 1: Centered around (0, -2)
X1 = np.random.randn(n_samples_per_class, 2) * 0.5 + [0, -2]
# Class 2: Centered around (2, -2)
X2 = np.random.randn(n_samples_per_class, 2) * 0.5 + [2, -2]
# Class 3: Centered around (-1, 2)
X3 = np.random.randn(n_samples_per_class, 2) * 0.5 + [-1, 2]
# Class 4: Centered around (1, 2)
X4 = np.random.randn(n_samples_per_class, 2) * 0.5 + [1, 2]
# Combine the data
X = np.vstack([X0, X1, X2, X3, X4])
y = np.hstack([np.zeros(n_samples_per_class),
np.ones(n_samples_per_class),
np.full(n_samples_per_class, 2),
np.full(n_samples_per_class, 3),
np.full(n_samples_per_class, 4)])
# Shuffle the dataset
shuffle_idx = np.random.permutation(n_samples)
X, y = X[shuffle_idx], y[shuffle_idx]
This block generates synthetic data for five classes located in different regions of the feature space.
3. Split the Dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
This block splits the dataset into training and testing sets for model evaluation.
4. Create and Train the AdaBoost Classifier
base_estimator = DecisionTreeClassifier(max_depth=1) # Decision stump model = AdaBoostClassifier(estimator=base_estimator, n_estimators=10, random_state=42) model.fit(X_train, y_train)
This block initializes the AdaBoost classifier with a weak learner (decision stump) and trains it using the training dataset.
5. Make Predictions
y_pred = model.predict(X_test)
This block uses the trained model to make predictions on the test set.
6. Evaluate the Model
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
print("\nConfusion Matrix:")
print(conf_matrix)
print("\nClassification Report:")
print(class_report)
Output:
Accuracy: 0.9540
Confusion Matrix:
[[ 97 2 0 0 0]
[ 0 92 3 0 0]
[ 0 4 92 0 0]
[ 0 0 0 86 14]
[ 0 0 0 0 110]]
Classification Report:
precision recall f1-score support
0.0 1.00 0.98 0.99 99
1.0 0.94 0.97 0.95 95
2.0 0.97 0.96 0.96 96
3.0 1.00 0.86 0.92 100
4.0 0.89 1.00 0.94 110
accuracy 0.95 500
macro avg 0.96 0.95 0.95 500
weighted avg 0.96 0.95 0.95 500
This block calculates and prints the accuracy, confusion matrix, and classification report, providing insights into the model's performance.
7. Visualize the Decision Boundary
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(12, 10))
plt.contourf(xx, yy, Z, alpha=0.4, cmap='viridis')
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', edgecolor='black')
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("AdaBoost Multiclass Classification (5 Classes)")
plt.colorbar(scatter)
plt.show()
This block visualizes the decision boundaries created by the AdaBoost classifier, illustrating how the model separates the five classes in the feature space.
Output:
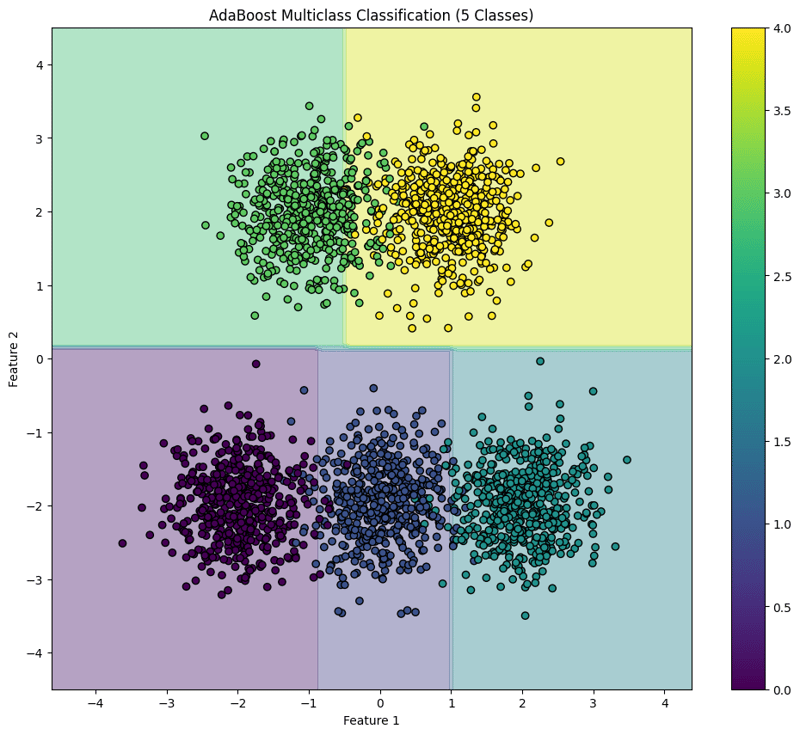
This structured approach demonstrates how to implement and evaluate AdaBoost for multiclass classification tasks, providing a clear understanding of its capabilities and the effectiveness of visualizing decision boundaries.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Solution d'erreur de paramètre 0x80070057
Solution d'erreur de paramètre 0x80070057
 Qu'est-ce qu'un serveur de noms de domaine racine
Qu'est-ce qu'un serveur de noms de domaine racine
 Méthode Window.setInterval()
Méthode Window.setInterval()
 quelle est l'URL
quelle est l'URL
 Programmation en langage de haut niveau
Programmation en langage de haut niveau
 Comment résoudre l'absence de route vers l'hôte
Comment résoudre l'absence de route vers l'hôte
 Que dois-je faire si chaturbate est bloqué ?
Que dois-je faire si chaturbate est bloqué ?
 Comment restaurer la base de données MySQL
Comment restaurer la base de données MySQL








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



