


La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Du Chaoqun, le premier auteur de cet article, est un doctorant direct 2020 au Département d'automatisation de l'Université Tsinghua. Le tuteur est le professeur agrégé Huang Gao. Il a auparavant obtenu un baccalauréat ès sciences du département de physique de l'université Tsinghua. Ses intérêts de recherche incluent la généralisation des modèles et la recherche de robustesse sur différentes distributions de données, telles que l'apprentissage longue traîne, l'apprentissage semi-supervisé, l'apprentissage par transfert, etc. A publié de nombreux articles dans des revues et conférences internationales de premier ordre telles que TPAMI et ICML.
Page d'accueil personnelle : https://andy-du20.github.io
Cet article présente un article sur la reconnaissance visuelle à longue traîne de l'Université Tsinghua : Apprentissage contrastif probabiliste pour la reconnaissance visuelle à longue traîne. Ce travail a été. TPAMI 2024 accepté, le code est open source.
Cette recherche se concentre principalement sur l'application de l'apprentissage contrastif dans les tâches de reconnaissance visuelle à longue traîne. Elle propose une nouvelle méthode d'apprentissage contrastif à longue traîne ProCo, en améliorant la perte contrastive, elle permet d'obtenir un apprentissage contrastif d'un nombre illimité de paires contrastives. résoudre efficacement le problème L'apprentissage contrastif supervisé[1] dépend intrinsèquement de la taille du lot (banque de mémoire). En plus des tâches de classification visuelle à longue traîne, cette méthode a également été expérimentée sur l'apprentissage semi-supervisé à longue traîne, la détection d'objets à longue traîne et des ensembles de données équilibrés, permettant ainsi des améliorations significatives des performances.

Comparaison Le succès de l’apprentissage en apprentissage auto-supervisé démontre son efficacité dans l’apprentissage des représentations de caractéristiques visuelles. Le facteur principal affectant les performances d'apprentissage contrastif est le nombre de
paires contrastées, qui permet au modèle d'apprendre à partir d'échantillons plus négatifs, ce qui se reflète dans les deux méthodes les plus représentatives SimCLR [2] et MoCo [3] respectivement. taille de la banque de mémoire. Cependant, dans les tâches de reconnaissance visuelle à longue traîne, en raison du déséquilibre des catégories, le gain apporté par l'augmentation du nombre de paires contrastives produira un effet décroissant marginal sérieux. En effet, la plupart des paires contrastives sont composées de catégories de tête. . Composé d'échantillons, il est difficile de couvrir les catégories de queue. Par exemple, dans l'ensemble de données Imagenet à longue traîne, si la taille du lot (banque de mémoire) est définie sur les valeurs communes 4096 et 8192, alors il y a une moyenne de 212
et89 catégories dans chaque lot (mémoire banque) respectivement. La taille de l’échantillon est inférieure à un. Par conséquent, l'idée centrale de la méthode ProCo est la suivante : sur l'ensemble de données longue traîne, en modélisant la distribution de chaque type de données, en estimant les paramètres et en les échantillonnant pour construire des paires contrastées, en garantissant que toutes les catégories peuvent être couvert. De plus, lorsque le nombre d'échantillons tend vers l'infini, la solution analytique attendue de perte contrastive peut être strictement dérivée théoriquement, de sorte qu'elle puisse être directement utilisée comme cible d'optimisation pour éviter un échantillonnage inefficace de paires contrastives et obtenir un nombre infini d'échantillons contrastifs. paires.
Cependant, la mise en œuvre des idées ci-dessus présente plusieurs difficultés principales : Comment modéliser la distribution de chaque type de données.
Étant donné que les caractéristiques de l'apprentissage contrastif sont distribuées sur l'hypersphère unitaire, une solution réalisable consiste à sélectionner la distribution de von Mises-Fisher (vMF) sur la sphère comme distribution des caractéristiques (cette distribution est similaire à la distribution normale sur la sphère) . L'estimation du maximum de vraisemblance des paramètres de distribution vMF a une solution analytique approximative et repose uniquement sur les statistiques de moment de premier ordre de la caractéristique. Par conséquent, les paramètres de la distribution peuvent être estimés efficacement et l'espérance de perte contrastive peut ainsi être strictement dérivée. réaliser la comparaison d’un nombre illimité de paires d’études contrastées.
Rajah 1 Algoritma ProCo menganggarkan pengedaran sampel berdasarkan ciri-ciri kumpulan yang berbeza Dengan mengambil sampel bilangan sampel yang tidak terhad, penyelesaian analitik bagi kerugian kontrastif yang dijangkakan boleh diperolehi, dengan berkesan menghapuskan pergantungan yang wujud pada pembelajaran kontrastif yang diselia. saiz kumpulan (bank memori) saiz .
Butiran kaedah
Berikut akan memperkenalkan kaedah ProCo secara terperinci dari empat aspek: andaian pengedaran, anggaran parameter, objektif pengoptimuman dan analisis teori.
Andaian Agihan
Seperti yang dinyatakan sebelum ini, ciri-ciri dalam pembelajaran kontras adalah terhad kepada hipersfera unit. Oleh itu, boleh diandaikan bahawa taburan yang dipatuhi oleh ciri-ciri ini ialah taburan von Mises-Fisher (vMF), dan fungsi ketumpatan kebarangkaliannya ialah: 
di mana z ialah vektor unit ciri p-dimensi, I ialah diubah suai. Fungsi Bessel jenis pertama,
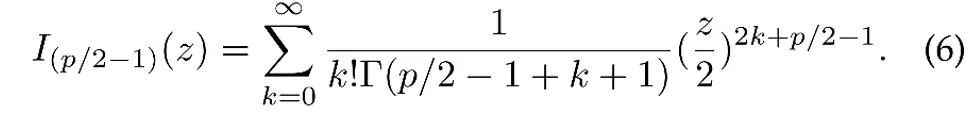
μ ialah arah min taburan, κ ialah parameter kepekatan, yang mengawal tahap kepekatan taburan Apabila κ lebih besar, tahap pengelompokan sampel berhampiran min adalah lebih tinggi; apabila κ =0, taburan vMF merosot menjadi sfera.
Anggaran parameter
Berdasarkan andaian pengedaran di atas, pengedaran keseluruhan ciri data ialah pengedaran vMF bercampur, di mana setiap kategori sepadan dengan pengedaran vMF.

di mana parameter  mewakili kebarangkalian terdahulu bagi setiap kategori, sepadan dengan kekerapan kategori y dalam set latihan. Purata vektor
mewakili kebarangkalian terdahulu bagi setiap kategori, sepadan dengan kekerapan kategori y dalam set latihan. Purata vektor  dan parameter gumpalan
dan parameter gumpalan  taburan ciri dianggarkan mengikut anggaran kemungkinan maksimum.
taburan ciri dianggarkan mengikut anggaran kemungkinan maksimum.
Dengan mengandaikan bahawa N vektor unit bebas dijadikan sampel daripada taburan vMF kategori y, anggaran kemungkinan maksimum (anggaran) [4] bagi arah min dan parameter kepekatan memenuhi persamaan berikut:
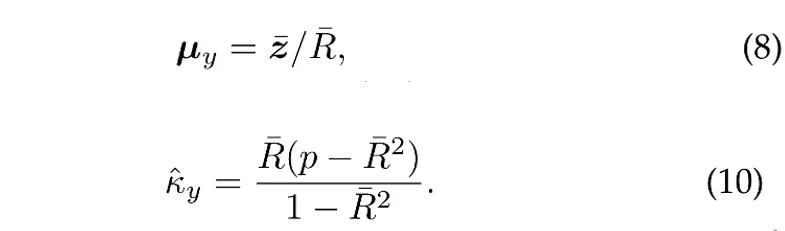
di mana  ialah sampel min,
ialah sampel min,  ialah panjang modulus bagi min sampel. Di samping itu, untuk menggunakan sampel sejarah, ProCo menggunakan kaedah anggaran dalam talian, yang boleh menganggarkan parameter kategori ekor dengan berkesan. . Oleh itu, kajian ini secara teorinya memanjangkan bilangan sampel kepada infiniti dan dengan tegas memperoleh penyelesaian analisis bagi fungsi kehilangan kontras yang dijangkakan secara langsung sebagai matlamat pengoptimuman.
ialah panjang modulus bagi min sampel. Di samping itu, untuk menggunakan sampel sejarah, ProCo menggunakan kaedah anggaran dalam talian, yang boleh menganggarkan parameter kategori ekor dengan berkesan. . Oleh itu, kajian ini secara teorinya memanjangkan bilangan sampel kepada infiniti dan dengan tegas memperoleh penyelesaian analisis bagi fungsi kehilangan kontras yang dijangkakan secara langsung sebagai matlamat pengoptimuman.
Dengan memperkenalkan cawangan ciri tambahan (pembelajaran perwakilan berdasarkan matlamat pengoptimuman ini) semasa proses latihan, cawangan ini boleh dilatih bersama-sama dengan cawangan klasifikasi dan tidak akan meningkat kerana hanya cawangan klasifikasi diperlukan semasa inferens Pengiraan tambahan kos. Jumlah wajaran kerugian kedua-dua cabang digunakan sebagai matlamat pengoptimuman akhir, dan α=1 ditetapkan dalam eksperimen Akhirnya, proses keseluruhan algoritma ProCo adalah seperti berikut: Analisis teori
Untuk meneruskan. menganalisis Untuk mengesahkan keberkesanan kaedah ProCo secara teori, para penyelidik menganalisis terikat ralat generalisasi dan terikat risiko yang berlebihan. Untuk memudahkan analisis, diandaikan di sini hanya terdapat dua kategori, iaitu y∈{-1+1}. Analisis menunjukkan bahawa terikat ralat generalisasi dikawal terutamanya oleh bilangan sampel latihan dan varians data Pengedaran. Dapatan ini konsisten dengan Analisis teori kerja berkaitan [6][7] adalah konsisten, memastikan bahawa kehilangan ProCo tidak memperkenalkan faktor tambahan dan tidak meningkatkan terikat ralat generalisasi, yang secara teorinya menjamin keberkesanan kaedah ini. 
Selain itu, kaedah ini bergantung pada andaian tertentu tentang pengagihan ciri dan anggaran parameter. Untuk menilai kesan parameter ini pada prestasi model, penyelidik juga menganalisis lebihan risiko kerugian ProCo, yang mengukur sisihan antara risiko yang dijangka menggunakan parameter anggaran dan risiko optimum Bayes, yang berada dalam pengedaran sebenar risiko Dijangka parameter.

Ini menunjukkan bahawa lebihan risiko kerugian ProCo dikawal terutamanya oleh terma urutan pertama ralat anggaran parameter.
Hasil eksperimen
Sebagai pengesahan motivasi teras, penyelidik terlebih dahulu membandingkan prestasi kaedah pembelajaran kontrastif yang berbeza di bawah saiz kelompok yang berbeza. Baseline termasuk Pembelajaran Kontrastif Seimbang [5] (BCL), kaedah yang dipertingkatkan juga berdasarkan SCL pada tugas pengecaman ekor panjang. Tetapan percubaan khusus mengikut strategi latihan dua peringkat Pembelajaran Kontrastif Terselia (SCL), iaitu, pertama hanya menggunakan kehilangan kontrastif untuk melatih pembelajaran perwakilan, dan kemudian melatih pengelas linear untuk ujian dengan tulang belakang beku.
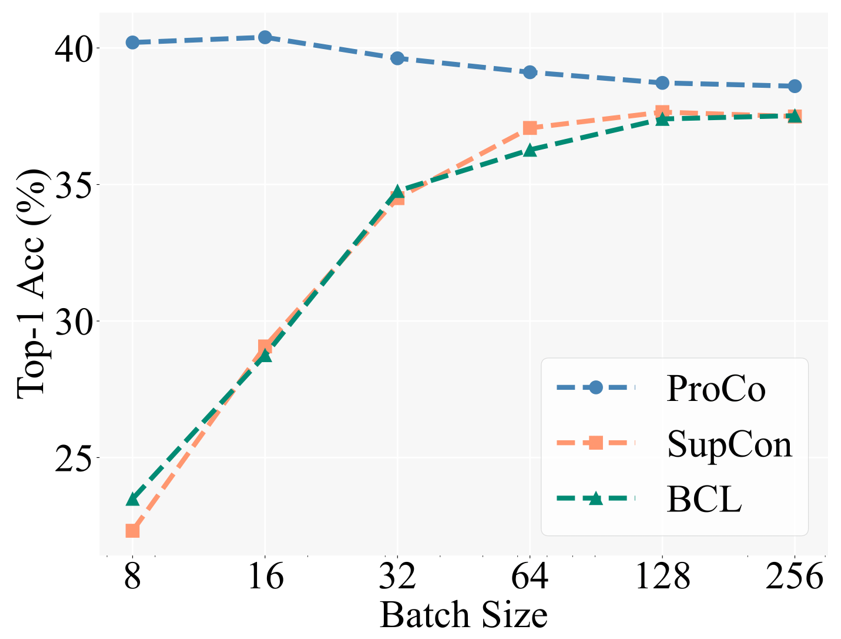
Angka di bawah menunjukkan keputusan percubaan pada set data CIFAR100-LT (IF100) Prestasi BCL dan SupCon jelas terhad oleh saiz kelompok, tetapi ProCo secara berkesan menghapuskan kesan SupCon pada saiz kelompok dengan memperkenalkan ciri tersebut. pengedaran setiap kategori pergantungan, dengan itu mencapai prestasi terbaik di bawah saiz kelompok yang berbeza.
Selain itu, para penyelidik juga menjalankan eksperimen tentang tugas pengecaman ekor panjang, pembelajaran separa penyeliaan ekor panjang, pengesanan objek ekor panjang dan set data seimbang. Di sini kami terutamanya menunjukkan hasil percubaan pada set data ekor panjang berskala besar Imagenet-LT dan iNaturalist2018. Pertama, di bawah jadual latihan selama 90 zaman, berbanding kaedah serupa untuk meningkatkan pembelajaran kontrastif, ProCo mempunyai sekurang-kurangnya 1% peningkatan prestasi pada dua set data dan dua tulang belakang.

Keputusan berikut seterusnya menunjukkan bahawa ProCo juga boleh mendapat manfaat daripada jadual latihan yang lebih panjang Di bawah jadual 400 zaman, ProCo mencapai prestasi SOTA pada set data iNaturalist2018, dan juga mengesahkan bahawa ia boleh bersaing dengan kombinasi bukan A yang lain. kaedah pembelajaran kontrastif, termasuk penyulingan (NCL) dan kaedah lain. "Rangka kerja ringkas untuk pembelajaran kontras perwakilan visual." mengenai penglihatan komputer dan pengecaman corak 2020.

J. Zhu, et al. "Pembelajaran kontrastif seimbang untuk pengecaman visual berekor panjang," dalam CVPR, 2022.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



