

Pour l'IA, l'Olympiade mathématique n'est plus un problème.
Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, OMI, et elle n'était qu'à un pas de remporter la médaille d'or.

Le concours de l'OMI qui vient de se terminer la semaine dernière comportait un total de six questions impliquant l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d’IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d’argent.
Au début de ce mois, le professeur titulaire de l'UCLA, Terence Tao, vient de promouvoir l'AI Math Olympiad (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'est amélioré à ce niveau avant juillet.
Résolvez des questions simultanément sur IMO et répondez aux questions les plus difficiles
IMO est le concours le plus ancien, le plus grand et le plus prestigieux pour les jeunes mathématiciens, organisé chaque année depuis 1959. Récemment, le concours de l'OMI a également été largement reconnu comme un grand défi dans le domaine de l'apprentissage automatique, devenant une référence idéale pour mesurer les capacités avancées de raisonnement mathématique des systèmes d'intelligence artificielle.
Lors du concours IMO de cette année, AlphaProof et AlphaGeometry 2 développés conjointement par l'équipe DeepMind ont réalisé une avancée majeure.
Parmi eux, AlphaProof est un système d'apprentissage par renforcement pour le raisonnement mathématique formel, tandis qu'AlphaGeometry 2 est une version améliorée du système de résolution géométrique de DeepMind, AlphaGeometry.
Cette avancée démontre le potentiel de l’intelligence générale artificielle (AGI) dotée de capacités avancées de raisonnement mathématique pour ouvrir de nouveaux domaines scientifiques et technologiques.
Alors, comment le système d’IA de DeepMind participe-t-il au concours IMO ?
Pour faire simple, ces problèmes mathématiques sont d'abord traduits manuellement en langage mathématique formel pour que le système d'IA puisse les comprendre. Dans le concours officiel, les candidats humains soumettent leurs réponses en deux sessions (deux jours), avec une limite de temps de 4,5 heures par session. Le système d’IA AlphaProof+AlphaGeometry 2 a résolu un problème en quelques minutes, mais a mis trois jours pour résoudre d’autres problèmes. Cependant, si vous suivez strictement les règles, le système de DeepMind a expiré. Certaines personnes pensent que cela pourrait impliquer beaucoup de craquage par force brute.

Google a déclaré qu'AlphaProof avait résolu deux problèmes d'algèbre et un problème de théorie des nombres en déterminant les réponses et en prouvant leur exactitude. Il s'agit notamment du problème le plus difficile de la compétition, que seuls cinq concurrents ont résolu lors de l'OMI de cette année. Et AlphaGeometry 2 prouve un problème de géométrie.
La solution donnée par l'IA : https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/imo-2024-solutions/index.html
Médaillé d'or IMO et médaillé Fields Timothy Gowers et Le Dr Joseph Myers, double médaillé d'or de l'OMI et président du comité de sélection des problèmes de l'OMI 2024, a noté les solutions proposées par le système combiné conformément aux règles de notation de l'OMI.
Chacune des six questions vaut 7 points, pour un score total maximum de 42 points. Le système de DeepMind a reçu une note finale de 28, ce qui signifie que les quatre problèmes résolus ont reçu des notes parfaites, équivalentes à la note la plus élevée dans la catégorie médaille d'argent. Le seuil de médaille d'or de cette année était de 29 points, et 58 des 609 concurrents ayant participé à la compétition ont officiellement remporté des médailles d'or.
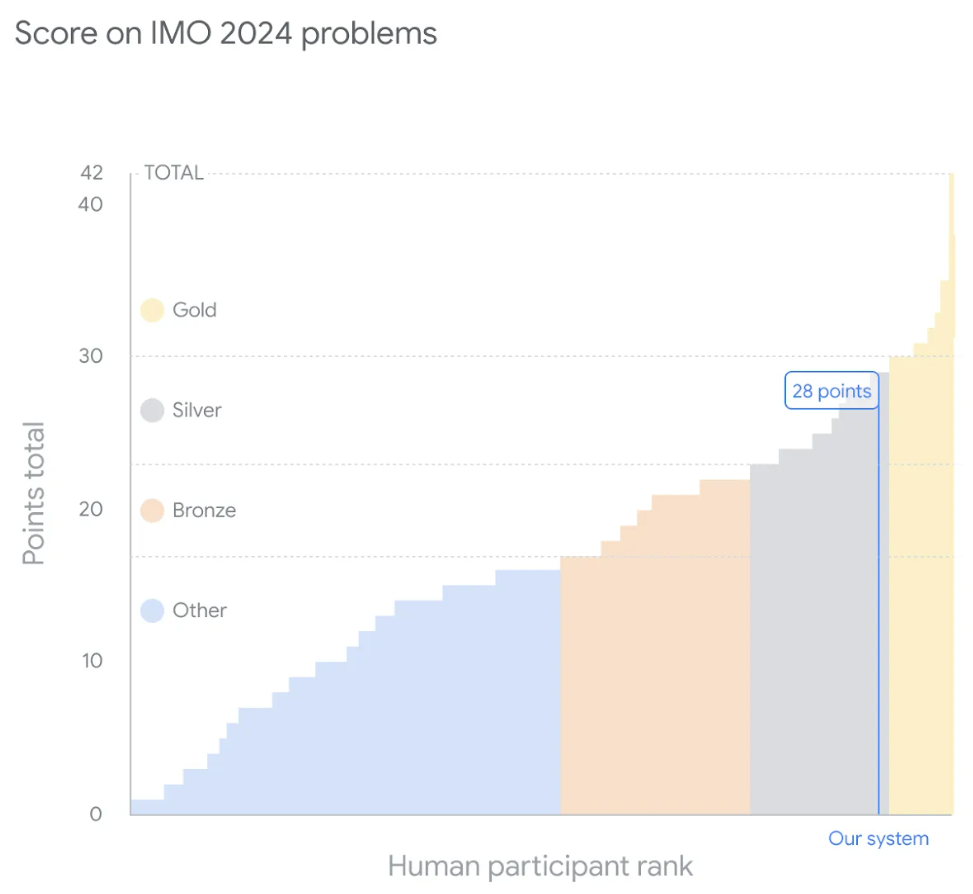
Ce graphique montre les performances du système d'intelligence artificielle de Google DeepMind par rapport aux concurrents humains à l'OMI 2024. Le système a obtenu 28 points sur 42, ce qui le place à égalité avec le médaillé d'argent de la compétition. De plus, 29 points suffisent pour décrocher une médaille d’or cette année.
AlphaProof : une méthode de raisonnement formel
Dans le système d'IA hybride utilisé par Google, AlphaProof est un système auto-entraîné qui utilise le langage formel Lean pour prouver des énoncés mathématiques. Il combine un modèle de langage pré-entraîné avec l'algorithme d'apprentissage par renforcement AlphaZero.
Parmi eux, les langages formels offrent des avantages importants pour vérifier formellement l'exactitude des preuves de raisonnement mathématique. Jusqu’à présent, cela a été d’une utilité limitée en apprentissage automatique car la quantité de données écrites par l’homme était très limitée.
En revanche, bien que les méthodes basées sur le langage naturel aient accès à de plus grandes quantités de données, elles produisent des étapes de raisonnement intermédiaires et des solutions qui semblent raisonnables mais incorrectes.
Google DeepMind construit un pont entre ces deux domaines complémentaires en affinant le modèle Gemini pour traduire automatiquement les énoncés de problèmes en langage naturel en énoncés formels, créant ainsi une vaste bibliothèque de problèmes formels de difficulté variable.
Face à un problème mathématique, AlphaProof générera des solutions candidates puis les prouvera en recherchant des étapes de preuve possibles dans Lean. Chaque solution de preuve trouvée et vérifiée est utilisée pour renforcer le modèle de langage d'AlphaProof et améliorer sa capacité à résoudre des problèmes ultérieurs plus difficiles.
Pour former AlphaProof, Google DeepMind a prouvé ou réfuté des millions de problèmes mathématiques couvrant un large éventail de difficultés et de sujets au cours des semaines précédant le concours de l'OMI. Une boucle d'entraînement est également appliquée pendant la compétition pour renforcer la preuve des variantes de problèmes de compétition auto-générées jusqu'à ce qu'une solution complète soit trouvée.
 Infographie du processus de boucle de formation par apprentissage par renforcement AlphaProof : environ un million de problèmes mathématiques informels sont traduits en langage mathématique formel par le réseau formel. Le solveur recherche ensuite dans le réseau des preuves ou des réfutations du problème, s'entraînant progressivement à résoudre des problèmes plus difficiles via l'algorithme AlphaZero.
Infographie du processus de boucle de formation par apprentissage par renforcement AlphaProof : environ un million de problèmes mathématiques informels sont traduits en langage mathématique formel par le réseau formel. Le solveur recherche ensuite dans le réseau des preuves ou des réfutations du problème, s'entraînant progressivement à résoudre des problèmes plus difficiles via l'algorithme AlphaZero.
AlphaGeometry 2
Plus compétitifAlphaGeometry 2 est une version considérablement améliorée de l'IA mathématique AlphaGeometry qui a été présentée dans le magazine Nature cette année. Il s'agit d'un système hybride neuro-symbolique dans lequel le modèle de langage est basé sur Gemini et formé à partir de zéro sur un ordre de grandeur plus de données synthétiques que son prédécesseur. Cela aide le modèle à résoudre des problèmes géométriques plus complexes, notamment ceux concernant le mouvement des objets et les équations d'angles, de proportions ou de distances.
AlphaGeometry 2 utilise un moteur symbolique qui est deux ordres de grandeur plus rapide que la génération précédente. Lorsque de nouveaux problèmes sont rencontrés, de nouveaux mécanismes de partage des connaissances permettent des combinaisons avancées de différents arbres de recherche pour résoudre des problèmes plus complexes.
Avant le concours de cette année, AlphaGeometry 2 pouvait résoudre 83 % de tous les problèmes de géométrie historiques de l'OMI au cours des 25 dernières années, contre 53 % pour son prédécesseur. Dans IMO 2024, AlphaGeometry 2 a résolu le problème 4 dans les 19 secondes suivant sa formalisation.
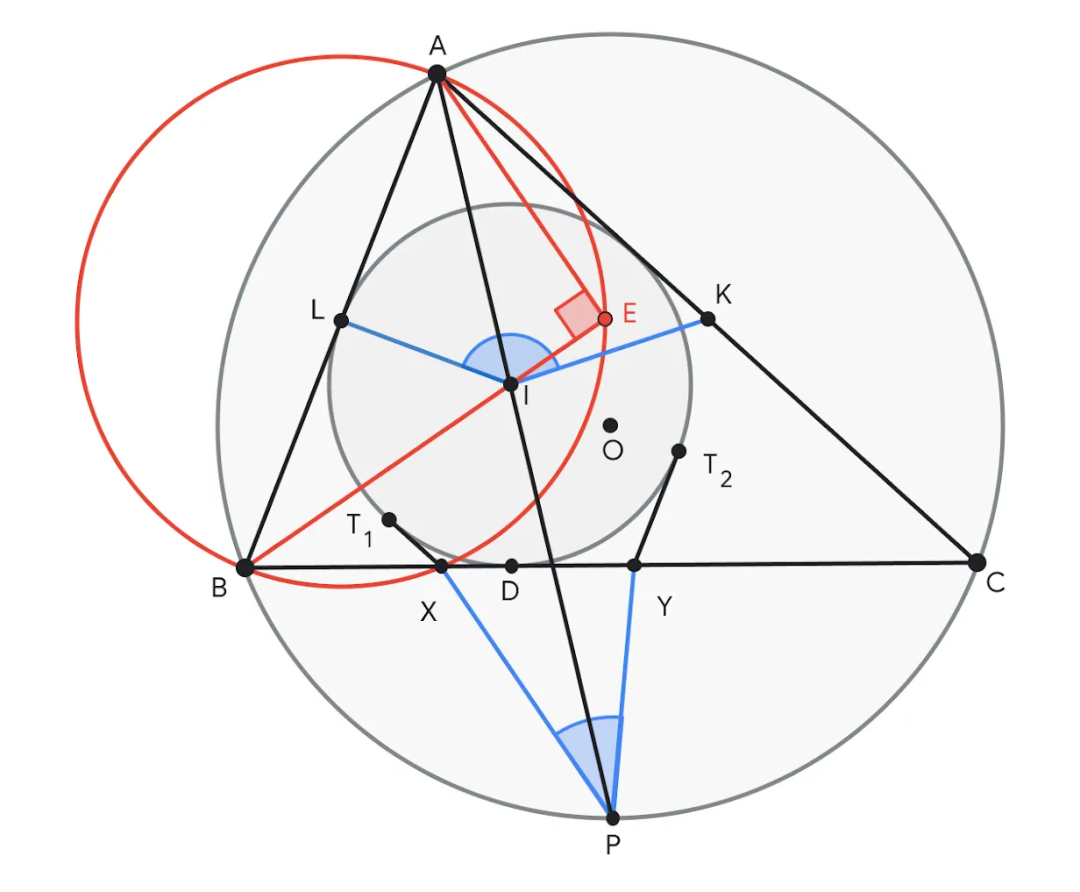
Exemple de la question 4, demandant de prouver que la somme de ∠KIL et ∠XPY est égale à 180°. AlphaGeometry 2 propose de construire le point E sur la droite BI tel que ∠AEB = 90°. Le point E aide à donner un sens au milieu L du segment de droite AB, créant ainsi de nombreuses paires de triangles similaires comme ABE ~ YBI et ALE ~ IPC pour prouver la conclusion.
Google DeepMind rapporte également que dans le cadre des travaux de l'OMI, les chercheurs expérimentent également un nouveau système de raisonnement en langage naturel basé sur Gemini et un système de raisonnement en langage naturel de pointe, dans l'espoir de parvenir à une résolution avancée de problèmes. capacités. Le système ne nécessite pas de traduction des questions dans un langage formel et peut être combiné avec d'autres systèmes d'IA. Lors du test des questions du concours de l'OMI de cette année, il "a montré un grand potentiel".
Google continue d'explorer les méthodes d'IA pour faire progresser le raisonnement mathématique et prévoit de publier prochainement plus de détails techniques sur AlphaProof.
Nous sommes enthousiasmés par un avenir dans lequel les mathématiciens utiliseront des outils d’IA pour explorer des hypothèses, essayer de nouvelles façons audacieuses de résoudre des problèmes de longue date et compléter rapidement des éléments de preuve chronophages – et des systèmes d’IA comme Gemini révolutionneront les mathématiques et le raisonnement plus large. les aspects deviennent plus puissants.
Équipe de recherche
Google a déclaré que la nouvelle recherche a été soutenue par l'Organisation internationale de l'Olympiade mathématique. De plus :
Le développement d'AlphaProof a été dirigé par Thomas Hubert, Rishi Mehta et Laurent Sartran, parmi lesquels Hussain Masoom, Aja Huang, Miklós Z. Horváth, Tom Zahavy, Vivek Veeriah, Eric Wieser, Jessica Yung, Lei Yu, Yannick Schroecker, Julian Schrittwieser, Ottavia Bertolli, Borja Ibarz, Edward Lockhart, Edward Hughes, Mark Rowland et Grace Margand.
Parmi eux, Aja Huang, Julian Schrittwieser, Yannick Schroecker et d'autres membres étaient également des membres principaux du journal AlphaGo il y a 8 ans (2016). Il y a huit ans, leur AlphaGo, basé sur l’apprentissage par renforcement, est devenu célèbre. Huit ans plus tard, l’apprentissage par renforcement brille à nouveau avec AlphaProof. Quelqu'un a déploré dans le cercle d'amis : RL est tellement de retour !

Les travaux d'AlphaGeometry 2 et d'inférence en langage naturel sont dirigés par Thang Luong. Le développement d'AlphaGeometry 2 a été dirigé par Trieu Trinh et Yuri Chervonyi, avec d'importantes contributions de Mirek Olšák, Xiaomeng Yang, Hoang Nguyen, Junehyuk Jung, Dawsen Hwang et Marcelo Menegali.
De plus, David Silver, Quoc Le, Hassabis et Pushmeet Kohli sont responsables de la coordination et de la gestion de l'ensemble du projet.
Contenu de référence :
https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quel est le format du caj
Quel est le format du caj
 Comment installer le système Linux
Comment installer le système Linux
 Quelles sont les différences entre weblogic et Tomcat
Quelles sont les différences entre weblogic et Tomcat
 vscode exécute le langage C
vscode exécute le langage C
 Comment résoudre les caractères chinois tronqués de Tomcat
Comment résoudre les caractères chinois tronqués de Tomcat
 La différence entre les serveurs d'applications légers et les serveurs cloud
La différence entre les serveurs d'applications légers et les serveurs cloud
 Quel logiciel est Xiaohongshu ?
Quel logiciel est Xiaohongshu ?
 Comment fermer le démarrage sécurisé
Comment fermer le démarrage sécurisé








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



