


La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Les auteurs de l'article sont tous du laboratoire de technologie linguistique de l'université de Cambridge. L'un d'eux est Liu Yinhong, un doctorant de troisième année, et ses superviseurs. sont les professeurs Nigel Collier et Ehsan Shareghi. Ses intérêts de recherche portent sur l'évaluation de grands modèles et de textes, la génération de données, etc. Zhou Han, doctorant en deuxième année à Tongyi, est encadré par les professeurs Anna Korhonen et Ivan Vulić. Ses recherches portent sur les grands modèles efficaces.
Le grand modèle présente d'excellentes capacités de suivi des commandes et de généralisation des tâches. Cette capacité unique provient de l'utilisation des données de suivi des commandes et de l'apprentissage par renforcement par rétroaction humaine (RLHF) dans la formation LLM. Dans le paradigme de formation RLHF, le modèle de récompense est aligné sur les préférences humaines sur la base des données de comparaison de classement. Cela améliore l'alignement des LLM sur les valeurs humaines, générant ainsi des réponses qui aident mieux les humains et adhèrent aux valeurs humaines.
Récemment, la première grande conférence de modèles COLM vient d'annoncer les résultats d'acceptation. L'un des travaux les plus performants a analysé le problème de biais de score difficile à éviter et à corriger lorsque le LLM est utilisé comme évaluateur de texte, et a proposé de convertir le problème. problème d'évaluation en un problème de classement des préférences, et a ainsi conçu l'algorithme PairS, un algorithme qui peut rechercher et trier les préférences par paires. En tirant parti des hypothèses d'incertitude et de transitivité LLM, PairS peut donner des classements de préférences efficaces et précis et démontrer une plus grande cohérence avec le jugement humain sur plusieurs ensembles de tests.

Lien de l'article : https://arxiv.org/abs/2403.16950
Titre de l'article : Alignement avec le jugement humain : le rôle de la préférence par paire dans les évaluateurs de grands modèles linguistiques
Adresse Github : https://github.com/cambridgeltl/PairS
Quels sont les problèmes liés à l'évaluation de grands modèles ?
Un grand nombre de travaux récents ont démontré l'excellente performance des LLM dans l'évaluation de la qualité du texte, formant un nouveau paradigme pour l'évaluation sans référence des tâches génératives, évitant ainsi des coûts coûteux d'annotation humaine. Cependant, les évaluateurs LLM sont très sensibles à la conception des invites et peuvent même être affectés par de multiples biais, notamment le biais de position, le biais de verbosité et le biais de contexte. Ces préjugés empêchent les évaluateurs LLM d'être justes et dignes de confiance, entraînant des incohérences et des désalignements avec le jugement humain.
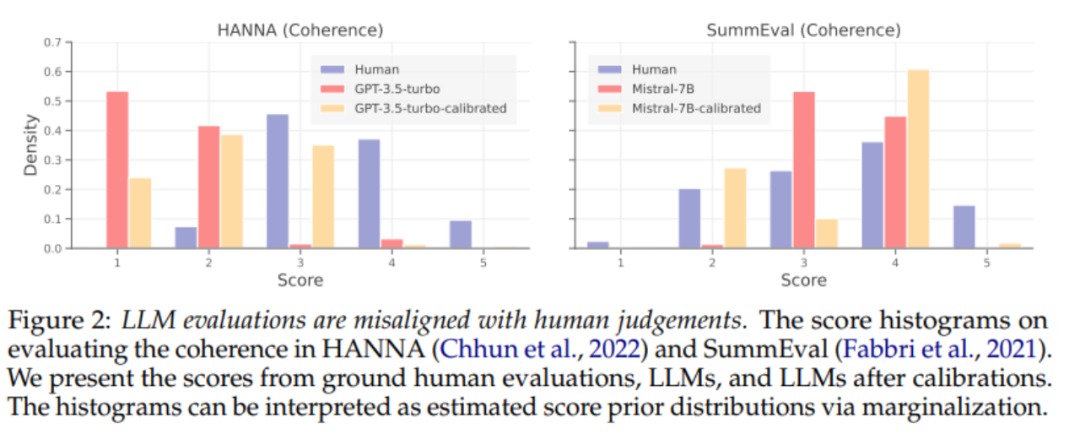
Pour réduire les prédictions biaisées des LLM, des travaux antérieurs ont développé des techniques d'étalonnage pour réduire les biais dans les prédictions des LLM. Nous effectuons d’abord une analyse systématique de l’efficacité des techniques de calage pour aligner les estimateurs LLM ponctuels. Comme le montre la figure 2 ci-dessus, les méthodes de calage existantes n'alignent toujours pas bien l'estimateur LLM, même lorsque des données de supervision sont fournies.
Comme le montre la Formule 1, nous pensons que la principale raison du désalignement de l'évaluation n'est pas les a priori biaisés sur la distribution des scores d'évaluation du LLM, mais le désalignement de la norme d'évaluation, c'est-à-dire la probabilité (probabilité) de l'évaluateur LLM. . Nous pensons que les évaluateurs LLM auront des critères d'évaluation plus cohérents avec ceux des humains lors de l'évaluation par paires. Nous explorons donc un nouveau paradigme d'évaluation LLM pour promouvoir des jugements plus alignés.

Inspiration apportée par RLHF
Comme le montre la figure 1 ci-dessous, inspiré par l'alignement des modèles de récompense via les données de préférence dans RLHF, nous pensons que l'évaluateur LLM peut être obtenu en générant un classement de préférences plus humain. -prédictions alignées. Certains travaux récents ont commencé à obtenir des classements de préférences en demandant à LLM d'effectuer des comparaisons par paires. Cependant, l’évaluation de la complexité et de l’évolutivité des classements de préférences a été largement négligée. Ils ignorent l'hypothèse de transitivité, rendant le nombre de comparaisons O (N ^ 2), rendant le processus d'évaluation coûteux et irréalisable.
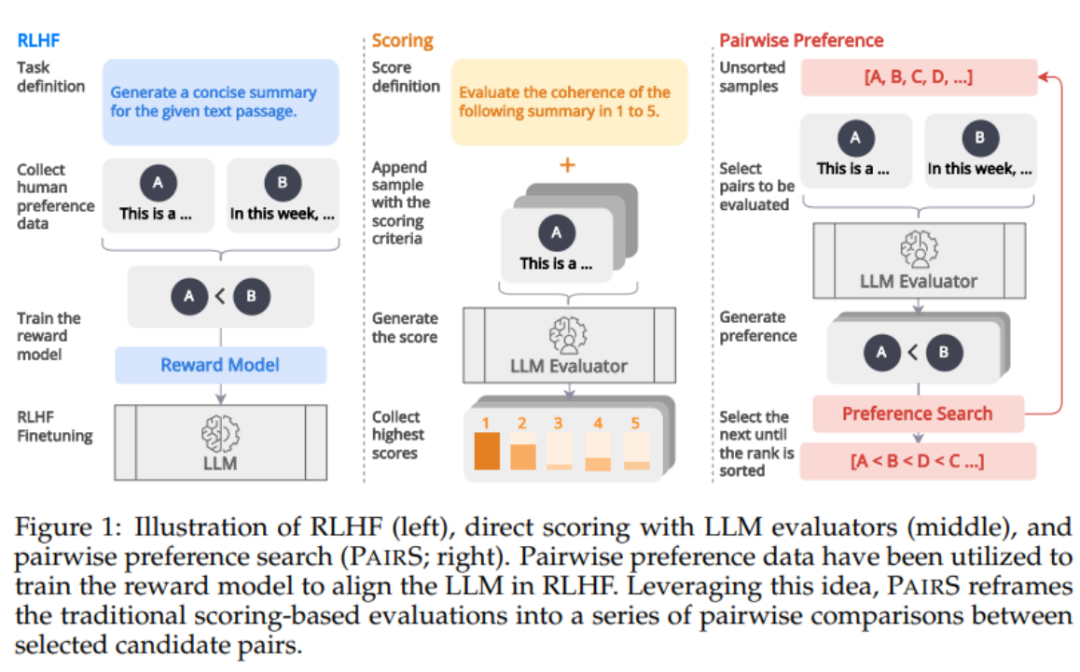
PairS : Algorithme de recherche de préférences efficace
Dans ce travail, nous proposons deux algorithmes de recherche de préférences par paires (PairS-greedy et PairS-beam). PairS-greedy est un algorithme basé sur une hypothèse de transitivité complète et un tri par fusion, et peut obtenir un tri de préférence global avec seulement une complexité O (NlogN). L'hypothèse de transitivité signifie que, par exemple, pour 3 candidats, LLM a toujours si A≻B et B≻C, alors A≻C. Sous cette hypothèse, nous pouvons utiliser directement les algorithmes de classement traditionnels pour obtenir des classements de préférences à partir de préférences par paires.
Mais LLM n'a pas une transitivité parfaite, nous avons donc conçu l'algorithme PairS-beam. Sous l’hypothèse de transitivité plus souple, nous dérivons et simplifions la fonction de vraisemblance pour le classement des préférences. PairS-beam est une méthode de recherche qui effectue une recherche de faisceau basée sur la valeur de vraisemblance dans chaque opération de fusion de l'algorithme de tri par fusion et réduit l'espace de comparaison par paire grâce à l'incertitude des préférences. PairS-beam peut ajuster la complexité du contraste et la qualité du classement, et fournir efficacement l'estimation du maximum de vraisemblance (MLE) du classement des préférences. Dans la figure 3 ci-dessous, nous montrons un exemple de la façon dont PairS-beam effectue une opération de fusion.
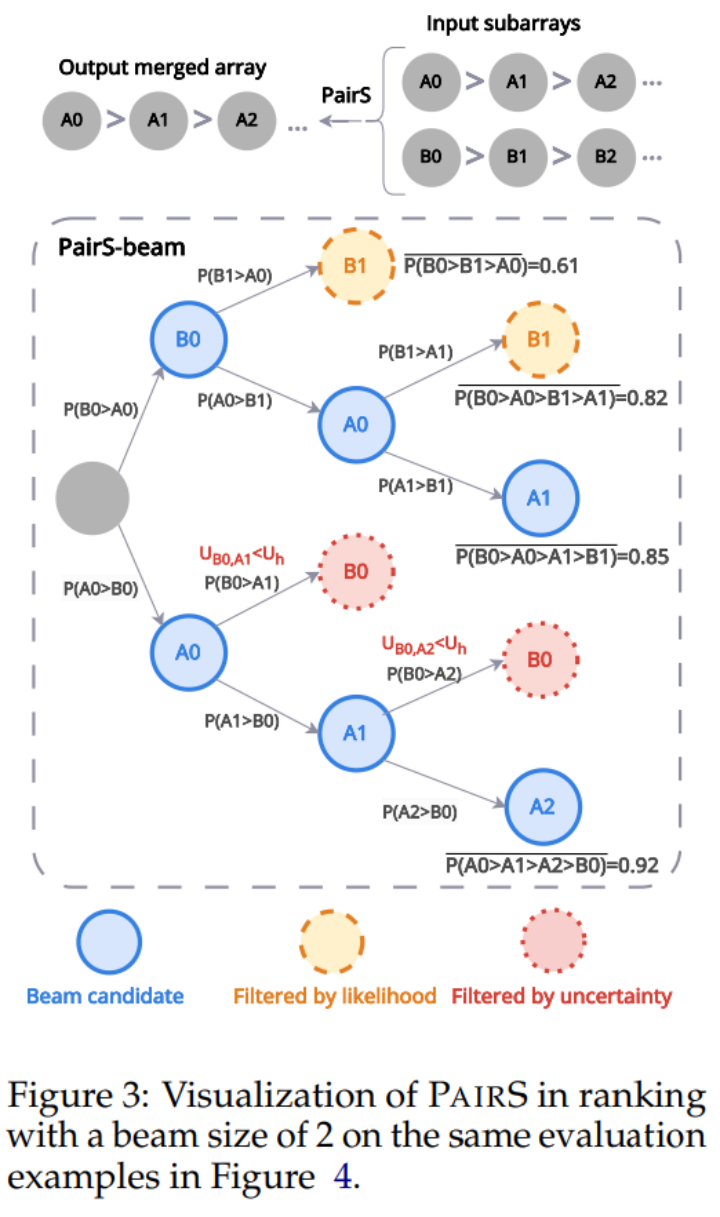
Résultats expérimentaux
Nous avons testé sur plusieurs ensembles de données représentatifs, y compris les tâches d'abréviation fermées NewsRoom et SummEval, et la tâche de génération d'histoires ouverte HANNA, et comparé plusieurs méthodes de base pour le LLM à point unique. évaluation, y compris la notation directe non supervisée, G-Eval, GPTScore et la formation supervisée UniEval et BARTScore. Comme le montre le tableau 1 ci-dessous, PairS a une plus grande cohérence avec les évaluations humaines qu'eux pour chaque tâche. GPT-4-turbo peut même obtenir des effets SOTA.
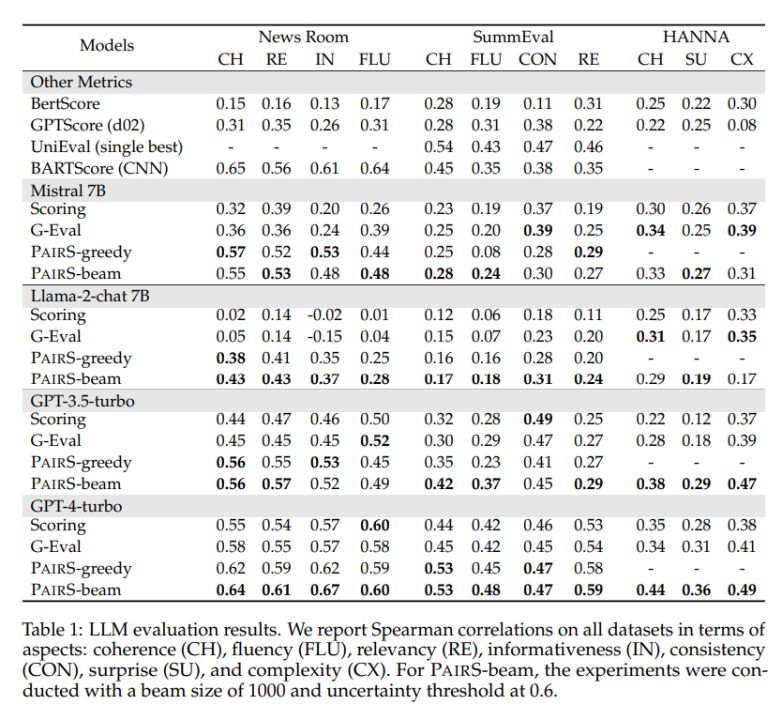
Dans l'article, nous avons également comparé deux méthodes de base pour le classement des préférences, le taux de victoire et la note ELO. Les paires peuvent obtenir le même classement de préférence de qualité avec seulement environ 30 % du nombre de comparaisons. L'article fournit également plus d'informations sur la manière dont les préférences par paire peuvent être utilisées pour calculer quantitativement la transitivité des estimateurs LLM, et sur la manière dont les estimateurs par paire peuvent bénéficier du calage.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment ouvrir des fichiers HTML
Comment ouvrir des fichiers HTML
 Tutoriel d'installation du système Linux
Tutoriel d'installation du système Linux
 Analyse des perspectives de pièces ICP
Analyse des perspectives de pièces ICP
 Patch VIP Tonnerre
Patch VIP Tonnerre
 Solution de rapport d'erreur de fichier SQL d'importation Mysql
Solution de rapport d'erreur de fichier SQL d'importation Mysql
 Comment résoudre le problème de l'écran noir après avoir allumé l'ordinateur et impossible d'accéder au bureau
Comment résoudre le problème de l'écran noir après avoir allumé l'ordinateur et impossible d'accéder au bureau
 Introduction à l'utilisation de vscode
Introduction à l'utilisation de vscode
 Plateforme de change virtuelle
Plateforme de change virtuelle








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



