



Sur cette base, NetEase Fuxi a innové davantage en s'appuyant sur le grand modèle de compréhension d'image et de texte, et a proposé une méthode de récupération multimodale basée sur la sélection et la reconstruction d'informations locales clés pour résoudre le texte d'image dans des champs spécifiques pour des applications multi-modales. les agents modaux. Les problèmes d’interaction posent les bases techniques.
Ce qui suit est un résumé des articles sélectionnés :
"Sélection et reconstruction des éléments locaux clés : une nouvelle méthode de récupération d'images et de textes spécifiques à un domaine"
Sélection et reconstruction d'informations locales clés : une nouvelle image et un texte spécifiques à un domaine méthode de récupération
Mots clés : informations locales clés, fines, interprétables
Domaines impliqués : pré-entraînement au langage visuel (VLP), récupération intermodale d'images et de textes (CMITR)
Ces dernières années, avec le pré-entraînement au langage visuel -formation (Vision- Avec l'essor des modèles de pré-entraînement linguistique (VLP), des progrès significatifs ont été réalisés dans le domaine de la récupération multimodale d'images et de textes (CMITR). Bien que les modèles VLP comme CLIP fonctionnent bien dans les tâches CMITR générales du domaine, leurs performances sont souvent insuffisantes dans la récupération d'images et de textes de domaine spécifique (SDITR). En effet, un domaine spécifique possède souvent des caractéristiques de données uniques qui le distinguent du domaine général.
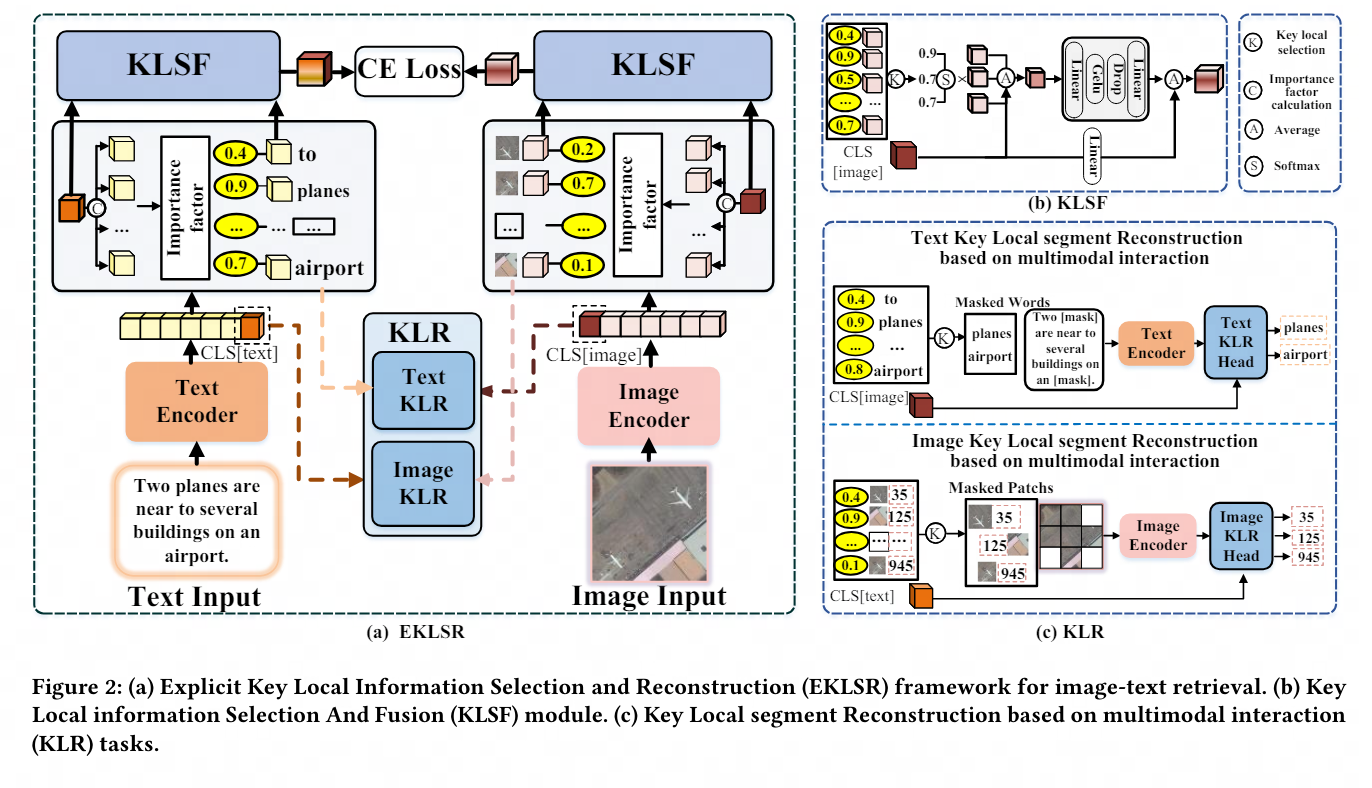
Dans un domaine spécifique, les images peuvent présenter un degré élevé de similitude visuelle entre elles, tandis que les différences sémantiques ont tendance à se concentrer sur des détails locaux clés, tels que des zones d'objets spécifiques dans l'image ou des mots significatifs dans le texte. Même de petits changements dans ces segments locaux peuvent avoir un impact significatif sur l'ensemble du contenu, soulignant l'importance de ces informations locales cruciales. Par conséquent, SDITR nécessite que le modèle se concentre sur des fragments d'informations locaux clés pour améliorer l'expression des caractéristiques de l'image et du texte dans un espace de représentation partagé, améliorant ainsi la précision de l'alignement entre les images et le texte.
Ce sujet explore l'application de modèles de pré-entraînement au langage visuel dans les tâches de récupération d'image-texte dans des domaines spécifiques, et étudie la question de l'utilisation des fonctionnalités locales dans les tâches de récupération d'image-texte dans des domaines spécifiques. La principale contribution est de proposer une méthode pour exploiter des informations locales discriminantes à granularité fine afin d'optimiser l'alignement des images et du texte dans un espace de représentation partagé.
À cette fin, nous concevons un cadre explicite de sélection et de reconstruction des informations locales clés et une stratégie de reconstruction de segments locaux clés basée sur une interaction multimodale. Ces méthodes utilisent efficacement des informations locales discriminantes à granularité fine, améliorant ainsi considérablement l'image et l'étendue et la suffisance. des expériences sur la qualité de l'alignement du texte dans un espace partagé démontrent l'avancement et l'efficacité de la stratégie proposée.
Un merci tout spécial au laboratoire IPIU de l'Université des sciences et technologies électroniques de Xi'an pour son solide soutien et sa contribution importante à la recherche à cet article.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Ordinateur portable avec double carte graphique
Ordinateur portable avec double carte graphique
 Système OA définitivement gratuit
Système OA définitivement gratuit
 utilisation de la fonction js
utilisation de la fonction js
 bootmgr est manquant et ne peut pas démarrer
bootmgr est manquant et ne peut pas démarrer
 Il y a une page vierge supplémentaire dans Word et je ne parviens pas à la supprimer.
Il y a une page vierge supplémentaire dans Word et je ne parviens pas à la supprimer.
 Pourquoi l'ordinateur continue de redémarrer automatiquement
Pourquoi l'ordinateur continue de redémarrer automatiquement
 Temps de panne du service Windows 10
Temps de panne du service Windows 10








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



