Le grand modèle de l'architecture Mamba a une nouvelle fois défié Transformer.
Le modèle d'architecture Mamba va-t-il enfin « tenir tête » cette fois-ci ? Depuis son lancement initial en décembre 2023, le Mamba s’est imposé comme un concurrent sérieux du Transformer. Depuis, des modèles utilisant l'architecture Mamba n'ont cessé d'apparaître, comme Codestral 7B, le premier grand modèle open source basé sur l'architecture Mamba édité par Mistral. Aujourd'hui, l'Abu Dhabi Technology Innovation Institute (TII) a publié un nouveau modèle Mamba open source - Falcon Mamba 7B. 
Résumons d'abord les points forts du Falcon Mamba 7B : il peut gérer des séquences de n'importe quelle longueur sans augmenter la mémoire de stockage, et il peut fonctionner sur un seul GPU A10 de 24 Go. Vous pouvez actuellement visualiser et utiliser Falcon Mamba 7B sur Hugging Face. Ce modèle causal uniquement par décodeur utilise la nouvelle architecture Mamba State Space Language Model (SSLM) pour gérer diverses tâches de génération de texte. À en juger par les résultats, le Falcon Mamba 7B surpasse les principaux modèles de sa catégorie de taille sur plusieurs critères, notamment le Llama 3 8B de Meta, le Llama 3.1 8B et le Mistral 7B. 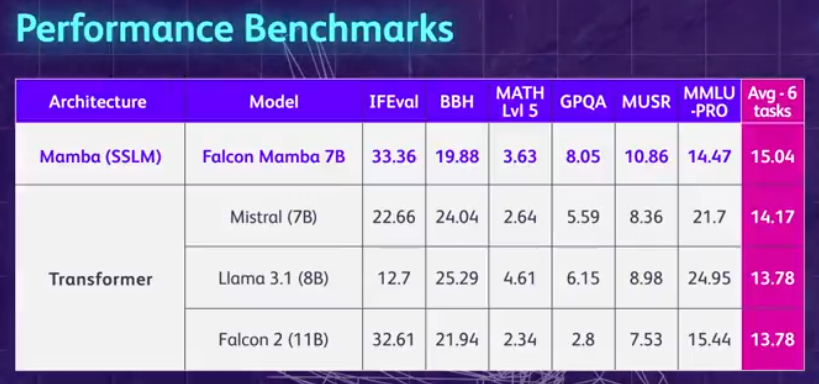
Falcon Mamba 7B est divisé en quatre modèles de variantes, à savoir la version de base, la version de réglage fin des commandes, la version 4 bits et la version 4 bits de réglage fin des commandes. 
En tant que modèle open source, Falcon Mamba 7B adopte la licence basée sur Apache 2.0 « Falcon License 2.0 » pour prendre en charge des fins de recherche et d'application. 
Adresse Hugging Face : https://huggingface.co/tiiuae/falcon-mamba-7bFalcon Mamba 7B est également devenu le troisième open source TII après Falcon 180B, Falcon 40B et Falcon 2 Four modèles, et c'est le premier modèle d'architecture Mamba SSLM. 
Le premier modèle Mamba pur à grande échelle à usage généralPendant longtemps, les modèles basés sur Transformer ont dominé l'IA générative. Cependant, les chercheurs ont remarqué que l'architecture Transformer a des difficultés à traiter les informations textuelles longues. peuvent être rencontrés. Essentiellement, le mécanisme d'attention de Transformer comprend le contexte en comparant chaque mot (ou jeton) avec chaque mot du texte, ce qui nécessite plus de puissance de calcul et de mémoire pour gérer la fenêtre contextuelle croissante. Mais si les ressources informatiques ne sont pas étendues en conséquence, la vitesse d'inférence du modèle ralentira et le texte dépassant une certaine longueur ne pourra pas être traité. Pour surmonter ces obstacles, l'architecture State Space Language Model (SSLM), qui fonctionne en mettant à jour en permanence l'état lors du traitement des mots, est apparue comme une alternative prometteuse et est déployée par de nombreuses institutions, dont TII. Falcon Mamba 7B utilise l'architecture Mamba SSM initialement proposée dans un article de décembre 2023 par des chercheurs de l'Université Carnegie Mellon et de l'Université de Princeton. L'architecture utilise un mécanisme de sélection qui permet au modèle d'ajuster dynamiquement ses paramètres en fonction de l'entrée. De cette manière, le modèle peut se concentrer sur ou ignorer des entrées spécifiques, de la même manière que fonctionne le mécanisme d'attention dans Transformer, tout en offrant la possibilité de traiter de longues séquences de texte (comme des livres entiers) sans nécessiter de mémoire ou de ressources informatiques supplémentaires. TII a noté que cette approche rend le modèle adapté à des tâches telles que la traduction automatique au niveau de l'entreprise, le résumé de texte, les tâches de vision par ordinateur et de traitement audio, ainsi que l'estimation et la prédiction. Falcon Mamba 7B Les données d'entraînement vont jusqu'à 5500GT, principalement composées d'un ensemble de données RefinedWeb, avec l'ajout de données techniques de haute qualité, de données de code et de données mathématiques provenant de sources publiques . Toutes les données sont tokenisées via les tokenizers Falcon-7B/11B. Semblable aux autres modèles de la série Falcon, le Falcon Mamba 7B est formé à l'aide d'une stratégie de formation en plusieurs étapes, la longueur du contexte est augmentée de 2048 à 8192. De plus, inspiré par le concept d'apprentissage en cours, TII sélectionne soigneusement des données mixtes tout au long de la phase de formation, en tenant pleinement compte de la diversité et de la complexité des données. Dans la phase finale de formation, TII utilise un petit ensemble de données organisées de haute qualité (c'est-à-dire des échantillons de Fineweb-edu) pour améliorer encore les performances. Processus de formation, hyperparamètres La majeure partie de la formation du Falcon Mamba 7B est réalisée sur 256 GPU H100 80GB, en utilisant le parallélisme 3D (TP=1, PP=1, DP=256) stratégie combinée avec ZeRO. La figure ci-dessous montre les détails des hyperparamètres du modèle, notamment la précision, l'optimiseur, le taux d'apprentissage maximal, la perte de poids et la taille du lot. 
Plus précisément, Falcon Mamba 7B a été formé avec l'optimiseur AdamW, le plan de taux d'apprentissage WSD (warm-stabilisize-decay), et pendant le processus de formation des 50 premiers GT, la taille du lot est passée de b_min=128 à b_max=2048. Dans la phase stable, TII utilise le taux d'apprentissage maximum η_max=6,4×10^−4, puis le diminue jusqu'à la valeur minimale en utilisant un plan exponentiel sur 500GT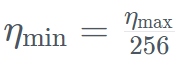 . Dans le même temps, TII utilise BatchScaling dans la phase d'accélération pour réajuster le taux d'apprentissage η afin que la température de bruit d'Adam
. Dans le même temps, TII utilise BatchScaling dans la phase d'accélération pour réajuster le taux d'apprentissage η afin que la température de bruit d'Adam 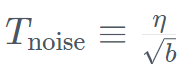 reste constante. La formation complète du modèle a duré environ deux mois. Pour comprendre comment le Falcon Mamba 7B se compare aux principaux modèles Transformer de sa catégorie de taille, l'étude a mené un test pour déterminer ce que le modèle peut gérer en utilisant un seul GPU A10 de 24 Go. Contexte maximum longueur. Les résultats montrent que Falcon Mamba est capable de s'adapter à des séquences plus grandes que le modèle Transformer actuel, tout en théoriquement capable de s'adapter à des longueurs de contexte illimitées.
reste constante. La formation complète du modèle a duré environ deux mois. Pour comprendre comment le Falcon Mamba 7B se compare aux principaux modèles Transformer de sa catégorie de taille, l'étude a mené un test pour déterminer ce que le modèle peut gérer en utilisant un seul GPU A10 de 24 Go. Contexte maximum longueur. Les résultats montrent que Falcon Mamba est capable de s'adapter à des séquences plus grandes que le modèle Transformer actuel, tout en théoriquement capable de s'adapter à des longueurs de contexte illimitées. 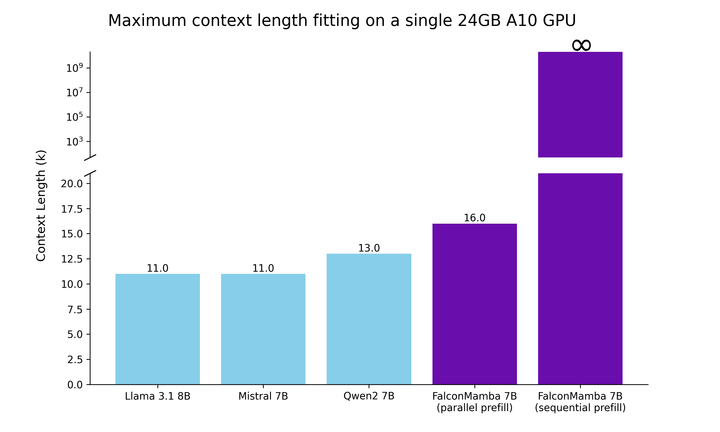
Ensuite, les chercheurs ont mesuré le débit de génération de modèles en utilisant une taille de lot de 1 et un paramètre matériel de GPU H100. Les résultats sont présentés dans la figure ci-dessous, Falcon Mamba génère tous les jetons à débit constant sans aucune augmentation de la mémoire maximale CUDA. Pour les modèles Transformer, la mémoire maximale augmente et la vitesse de génération ralentit à mesure que le nombre de jetons générés augmente. 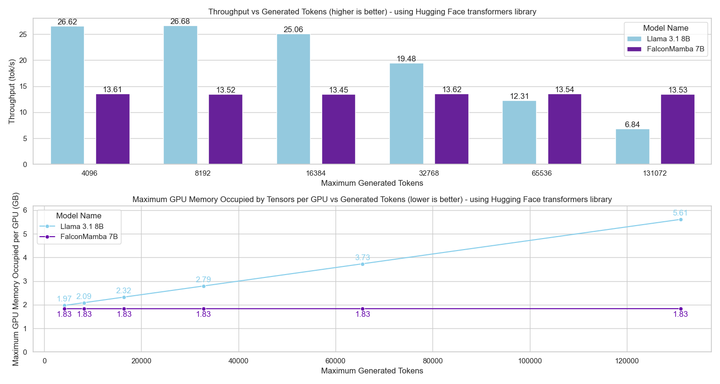
Même sur les références standards de l'industrie, le nouveau modèle fonctionne mieux ou proche des modèles de transformateurs populaires ainsi que des modèles d'espace d'état purs et hybrides. Par exemple, dans les benchmarks Arc, TruthfulQA et GSM8K, Falcon Mamba 7B a obtenu respectivement 62,03%, 53,42% et 52,54%, surpassant Llama 3 8B, Llama 3.1 8B, Gemma 7B et Mistral 7B. Cependant, le Falcon Mamba 7B est loin derrière ces modèles dans les benchmarks MMLU et Hellaswag. 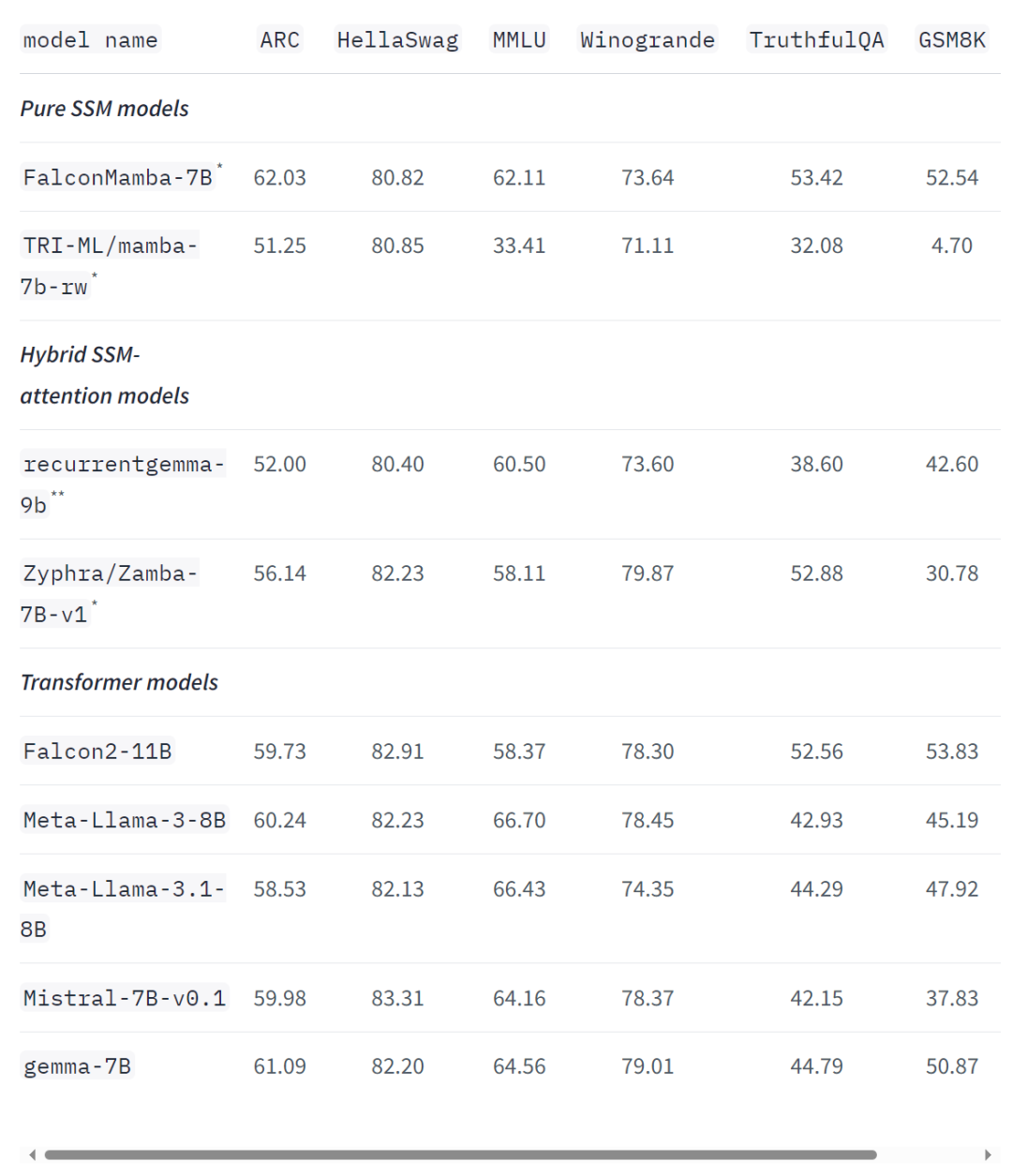

Hakim Hacid, chercheur principal de TII, a déclaré dans un communiqué : Le lancement du Falcon Mamba 7B représente une étape majeure pour l'agence, inspirant de nouvelles perspectives et favorisant l'exploration systématique du renseignement. Chez TII, ils repoussent les limites du SSLM et des modèles de transformateurs pour inspirer de nouvelles innovations en matière d'IA générative. Actuellement, la famille de modèles linguistiques Falcon de TII a été téléchargée plus de 45 millions de fois, ce qui en fait l'une des versions LLM les plus réussies aux Émirats arabes unis. Le papier Falcon Mamba 7B sortira bientôt, vous pouvez attendre un instant. https://huggingface.co/blog/falconmambahttps://venturebeat.com/ai/falcon-mamba-7bs-powerful -nouvelles-offres-d'architecture-ai-alternatives-aux-modèles-de-transformateurs/Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


 utilisation d'unetbootin
utilisation d'unetbootin
 Introduction aux niveaux des examens Python
Introduction aux niveaux des examens Python
 Comment résoudre le problème selon lequel le logiciel antivirus Win11 ne peut pas être ouvert
Comment résoudre le problème selon lequel le logiciel antivirus Win11 ne peut pas être ouvert
 réalisation de pages web html
réalisation de pages web html
 Comment arrondir dans Matlab
Comment arrondir dans Matlab
 Comment définir une image d'arrière-plan ppt
Comment définir une image d'arrière-plan ppt
 Quelles sont les différences entre le langage C++ et C
Quelles sont les différences entre le langage C++ et C
 outils de développement Python
outils de développement Python








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



