

Tumpuan kalangan akademik minggu ini sudah pasti adalah Sidang Kemuncak ACL 2024 yang diadakan di Bangkok, Thailand. Acara ini menarik ramai penyelidik cemerlang dari seluruh dunia, yang berkumpul bersama untuk membincangkan dan berkongsi keputusan akademik terkini.
Data rasmi menunjukkan bahawa ACL tahun ini menerima hampir 5,000 penyerahan kertas, 940 daripadanya telah diterima oleh persidangan utama, dan 168 karya telah dipilih untuk laporan lisan (Lisan) Kadar penerimaan adalah kurang daripada 3.4%. Antaranya, ByteDance mempunyai 5 keputusan dan Oral telah dipilih.
Dalam sesi Anugerah Kertas pada petang 14 Ogos, Pencapaian ByteDance "G-DIG: Towards Gradient-based Diverse and high-quality Instruction Data Selection for Machine Translation" telah diumumkan secara rasmi oleh penganjur sebagai Kertas Cemerlang ( 1/ 35).现 ACL 2024 di tapak foto
 Kembali ke ACL 2021, byte beating telah mengambil satu-satunya kertas terbaik dengan laurel Ini adalah kali kedua pasukan saintis China telah dipilih untuk kali kedua sejak penubuhan ACL. Hadiah utama!
Kembali ke ACL 2021, byte beating telah mengambil satu-satunya kertas terbaik dengan laurel Ini adalah kali kedua pasukan saintis China telah dipilih untuk kali kedua sejak penubuhan ACL. Hadiah utama!
Untuk mengadakan perbincangan mendalam tentang hasil penyelidikan termaju tahun ini, kami secara khas menjemput pekerja teras kertas kerja ByteDance untuk mentafsir dan berkongsi. Selasa depan, 20 Ogos, dari 19:00-21:00, "ByteDance ACL 2024 Sesi Perkongsian Kertas Termaju" akan disiarkan dalam talian!
Wang Mingxuan, ketua pasukan penyelidik model bahasa Doubao, akan berganding bahu dengan ramai penyelidik ByteDance
Huang Zhichao, Zheng Zaixiang, Li Chaowei, Zhang Xinbo, dan Outstanding Paper's Paper's's result misteri yang berkongsi beberapa tetamu yang menarikdan arahan penyelidikan ACL Ia melibatkan pemprosesan bahasa semula jadi, pemprosesan pertuturan, pembelajaran pelbagai mod, penaakulan model besar dan bidang lain Selamat datang untuk membuat temu janji!
Agenda Acara



Dengan perkembangan pesat model bahasa besar (LLM), tokenisasi pertuturan diskret memainkan peranan penting dalam menyuntik pertuturan ke dalam LLM. Walau bagaimanapun, pendiskretan ini membawa kepada kehilangan maklumat, sekali gus menjejaskan prestasi keseluruhan. Untuk meningkatkan prestasi token pertuturan diskret ini, kami mencadangkan RepCodec, codec perwakilan pertuturan baru untuk pendiskretan pertuturan semantik. Framework de RepCodec
Contrairement aux codecs audio qui reconstruisent l'audio d'origine, RepCodec apprend le livre de codes VQ en reconstruisant la représentation vocale à partir d'un encodeur vocal tel comme HuBERT ou data2vec. L'encodeur vocal, l'encodeur codec et le livre de codes VQ forment ensemble un processus qui convertit les formes d'onde vocales en jetons sémantiques. Des expériences approfondies montrent que RepCodec surpasse considérablement la méthode de clustering k-means largement utilisée en termes de compréhension et de génération de la parole en raison de ses capacités améliorées de rétention d'informations. De plus, cet avantage s'applique à une variété de codeurs vocaux et de langages, affirmant la robustesse de RepCodec. Cette approche peut faciliter la recherche à grande échelle de modèles linguistiques dans le traitement de la parole. DINOISER : Modèle de génération de séquence conditionnelle de diffusion amélioré par la manipulation du bruit Adresse papier : https://arxiv.org/pdf/2302.10025 Pendant la diffusion le modèle génère Un grand succès a été obtenu avec des signaux continus tels que des images et du son, mais des difficultés subsistent dans l'apprentissage de données de séquences discrètes comme le langage naturel. Bien qu’une série récente de modèles de diffusion de texte contourne ce défi de la discrétion en intégrant des états discrets dans un espace latent d’états continus, leur qualité de génération reste insatisfaisante.
Pour comprendre cela, nous analysons d'abord en profondeur le processus de formation des modèles de génération de séquences basés sur des modèles de diffusion et identifions trois problèmes sérieux avec eux : (1) l'échec d'apprentissage ; (2) le manque d'évolutivité ; (3) le signal de condition de négligence ; Nous pensons que ces problèmes peuvent être attribués à l'imperfection de la discrétion dans l'espace d'intégration, où l'ampleur du bruit joue un rôle décisif.
Dans ce travail, nous proposons DINOISER, qui améliore les modèles de diffusion pour la génération de séquences en manipulant le bruit. Nous déterminons de manière adaptative la plage de l'échelle de bruit échantillonnée pendant la phase d'entraînement d'une manière inspirée par la transmission optimale, et encourageons le modèle pendant la phase d'inférence à mieux exploiter le signal conditionnel en amplifiant l'échelle de bruit. Les expériences montrent que, sur la base de la stratégie efficace de formation et d'inférence proposée, DINOISER surpasse la ligne de base des modèles de génération de séquences de diffusion précédents sur plusieurs références de modélisation de séquences conditionnelles. Une analyse plus approfondie a également vérifié que DINOISER peut mieux utiliser les signaux conditionnels pour contrôler son processus de génération.
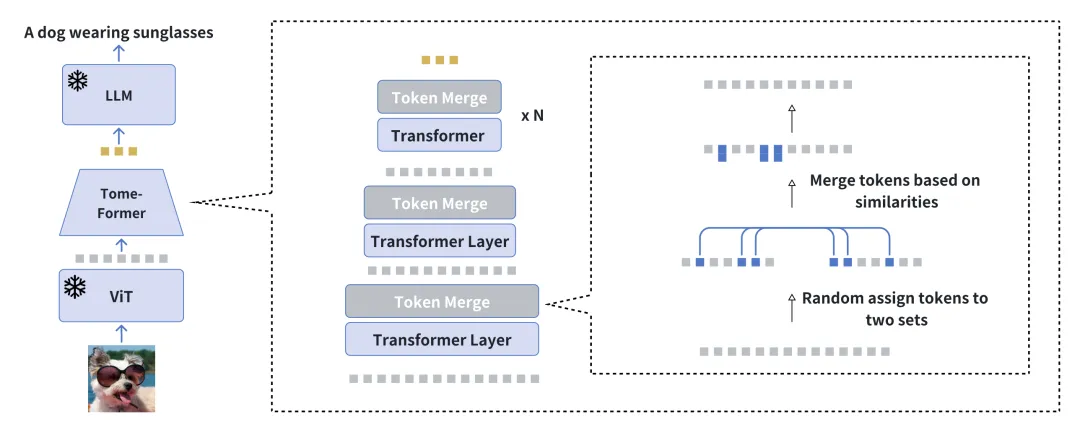
Accélérer la formation à la génération visuelle de langage conditionnel en réduisant la redondance Adresse papier : https://arxiv.org/pdf/2310.03291 Nous vous présentons EVLGen, un outil pour un langage simplifié cadre conçu pour la pré-formation de modèles de génération de langage visuellement conditionnels avec des exigences de calcul élevées, exploitant des grands modèles de langage (LLM) gelés et pré-entraînés. L'approche conventionnelle en pré-entraînement au langage visuel (VLP) implique généralement un processus d'optimisation en deux étapes : une étape initiale gourmande en ressources dédiée au langage visuel général. Axes d'apprentissage de la représentation sur l’extraction et l’intégration de caractéristiques visuelles pertinentes. Ceci est suivi d'une phase de suivi mettant l'accent sur l'alignement de bout en bout entre les modalités visuelles et linguistiques. Notre nouveau cadre en une seule étape et à perte unique contourne la première étape de formation exigeante en termes de calcul en fusionnant progressivement des repères visuels similaires pendant la formation, tout en évitant les inconvénients du modèle causés par la formation en une seule étape de l'effondrement des modèles de type BLIP-2. Le processus de fusion progressif compresse efficacement les informations visuelles tout en conservant la richesse sémantique, permettant ainsi une convergence rapide sans affecter les performances. Les résultats expérimentaux montrent que notre méthode accélère de 5 fois la formation des modèles de langage visuel sans impact significatif sur les performances globales. De plus, notre modèle réduit considérablement l'écart de performances avec les modèles de langage visuel actuels en utilisant seulement 1/10ème des données. Enfin, nous montrons comment notre modèle image-texte peut être adapté de manière transparente aux tâches de génération de langage conditionnées par la vidéo grâce à un nouveau module de contexte étiqueté temporel et attentionnel doux.
StreamVoice : modélisation de langage contextuelle diffusable pour une conversion vocale en temps réel sans prise de vue
Adresse papier : https://arxiv.org/pdf/2401.11053
Streaming Streaming La conversion vocale sans tir fait référence à la capacité de convertir la parole d'entrée en parole de n'importe quel locuteur en temps réel, et ne nécessite qu'une seule phrase de la voix de l'orateur comme référence, et ne nécessite pas de mises à jour supplémentaires du modèle. Les méthodes existantes de conversion vocale à échantillon nul sont généralement conçues pour des systèmes hors ligne et sont difficiles à répondre aux exigences de capacité de diffusion en continu des applications de conversion vocale en temps réel. Les méthodes récentes basées sur un modèle de langage (LM) ont démontré d'excellentes performances en matière de génération de parole sans tir (y compris la conversion), mais nécessitent un traitement de phrases complètes et sont limitées à des scénarios hors ligne. L'architecture globale de StreamVoice G-DIG : Engagé en faveur d'une diversité de traduction automatique basée sur des gradients et d'une sélection de données d'instruction de haute qualité Adresse papier : https://arxiv.org/pdf/2405.12915 Large Les modèles de langage (LLM) ont démontré des capacités extraordinaires dans des scénarios généraux. Le réglage fin des instructions leur permet d'effectuer des tâches comparables à celles des humains. Cependant, la diversité et la qualité des données sur l’enseignement restent deux défis majeurs pour le réglage fin de l’enseignement. À cette fin, nous proposons une nouvelle approche basée sur le gradient pour sélectionner automatiquement des données de réglage fin d'instructions diversifiées et de haute qualité pour la traduction automatique. Notre innovation clé réside dans l'analyse de la manière dont les exemples de formation individuels affectent le modèle pendant la formation.
Présentation de G-DIG
Plus précisément, nous sélectionnons des exemples de formation qui ont un impact bénéfique sur le modèle en tant qu'exemples de haute qualité à l'aide de fonction d'influence et un petit ensemble de données de départ de haute qualité. De plus, pour améliorer la diversité des données d'entraînement, nous maximisons la diversité de leur influence sur le modèle en regroupant et en rééchantillonnant leurs gradients. Des expériences approfondies sur les tâches de traduction WMT22 et FLORES démontrent la supériorité de notre méthode, et une analyse approfondie valide en outre son efficacité et sa généralité.
GroundingGPT : langage amélioré Multimodal Modèle de mise à la terre Adresse papier : https://arxiv.org/pdf/2401.06071 Grand langage multimodal Le modèle démontre d’excellentes performances dans diverses tâches selon différentes modalités. Cependant, les modèles précédents mettent principalement l'accent sur la capture d'informations globales sur les entrées multimodales. Par conséquent, ces modèles n'ont pas la capacité de comprendre efficacement les détails des données d'entrée et fonctionnent mal dans les tâches qui nécessitent en même temps une compréhension détaillée de l'entrée. de ces modèles souffrent de graves problèmes d'hallucinations, limitant son utilisation généralisée.
Afin de résoudre ce problème et d'améliorer la polyvalence des grands modèles multimodaux dans un plus large éventail de tâches, nous proposons GroundingGPT, un modèle multimodal capable d'obtenir différentes compréhensions granulaires des images, des vidéos et des audios. En plus de capturer des informations globales, le modèle proposé est également efficace pour gérer des tâches qui nécessitent une compréhension plus fine, telles que la capacité du modèle à identifier des régions spécifiques dans une image ou des moments spécifiques dans une vidéo. Afin d'atteindre cet objectif, nous avons conçu un processus de construction d'ensembles de données diversifié pour construire un ensemble de données de formation multimodal et multigranulaire. Des expériences sur plusieurs benchmarks publics démontrent la polyvalence et l’efficacité de notre modèle.
ReFT : Inférence basée sur un réglage fin du renforcement Adresse papier : https://arxiv.org/pdf/2401.08967 Un renforcement commun pour les grands modèles de langage (LLM) inférence L'approche capable est le réglage fin supervisé (SFT) à l'aide de données annotées de chaîne de pensée (CoT). Cependant, cette méthode ne montre pas une capacité de généralisation suffisamment forte car la formation repose uniquement sur les données CoT fournies. Plus précisément, dans les ensembles de données liés à des problèmes mathématiques, il n'existe généralement qu'un seul chemin de raisonnement annoté pour chaque problème dans les données d'entraînement. Pour l’algorithme, s’il peut apprendre plusieurs chemins de raisonnement étiquetés pour un problème, il aura de plus fortes capacités de généralisation.
Pour résoudre ce défi, en prenant comme exemple des problèmes mathématiques, nous proposons une méthode simple et efficace appelée Reinforced Fine-Tuning (ReFT) pour améliorer la capacité de généralisation des LLM lors de l'inférence. ReFT utilise d'abord SFT pour réchauffer le modèle, puis utilise l'apprentissage par renforcement en ligne (en particulier l'algorithme PPO dans ce travail) pour l'optimisation, qui échantillonne automatiquement un grand nombre de chemins de raisonnement pour un problème donné et obtient des récompenses basées sur les réponses réelles pour mise au point ultérieure du modèle. Des expériences approfondies sur les ensembles de données GSM8K, MathQA et SVAMP montrent que ReFT surpasse considérablement SFT et que les performances du modèle peuvent être encore améliorées en combinant des stratégies telles que le vote majoritaire et la réorganisation. Il convient de noter qu'ici ReFT s'appuie uniquement sur le même problème de formation que SFT et ne s'appuie pas sur des problèmes de formation supplémentaires ou améliorés. Cela montre que ReFT a une capacité de généralisation supérieure. Dans l'attente de vos questions interactives
Heure de diffusion en direct : 20 août 2024 (mardi) 19h00-21h00 Plateforme de diffusion en direct : Compte vidéo WeChat [Doubao Big Model Team], Numéro du Livre Rouge Xiao [Chercheur Doubao] Vous êtes invités à remplir le questionnaire et à nous faire part des questions qui vous intéressent sur l'article ACL 2024, et à discuter avec plusieurs chercheurs en ligne ! L'équipe modèle Beanbao continue d'être très recrutée. Veuillez cliquer sur ce lien pour en savoir plus sur les informations relatives au recrutement de l'équipe.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 arithmétique binaire
arithmétique binaire
 Comment utiliser la lecture aléatoire
Comment utiliser la lecture aléatoire
 Comment acheter de vraies pièces Ripple
Comment acheter de vraies pièces Ripple
 Comment redémarrer le service dans le framework swoole
Comment redémarrer le service dans le framework swoole
 commande telnet
commande telnet
 utilisation de la fonction informix
utilisation de la fonction informix
 Comment définir une bordure pointillée CSS
Comment définir une bordure pointillée CSS
 Dernier classement des échanges de devises numériques
Dernier classement des échanges de devises numériques
 Quels sont les sept principes des spécifications du code PHP ?
Quels sont les sept principes des spécifications du code PHP ?

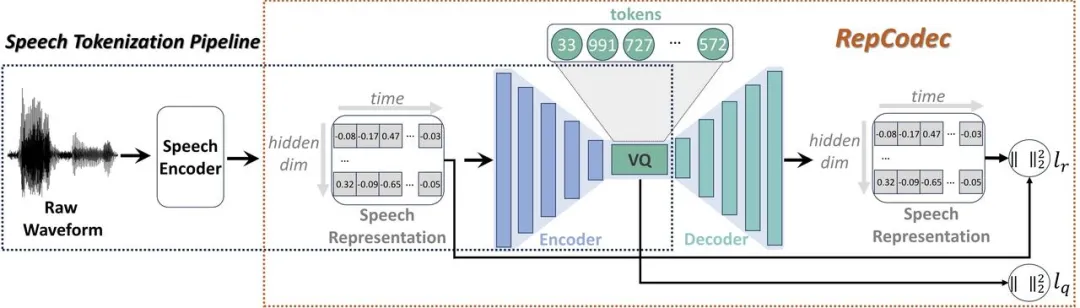 Framework de RepCodec
Framework de RepCodec 


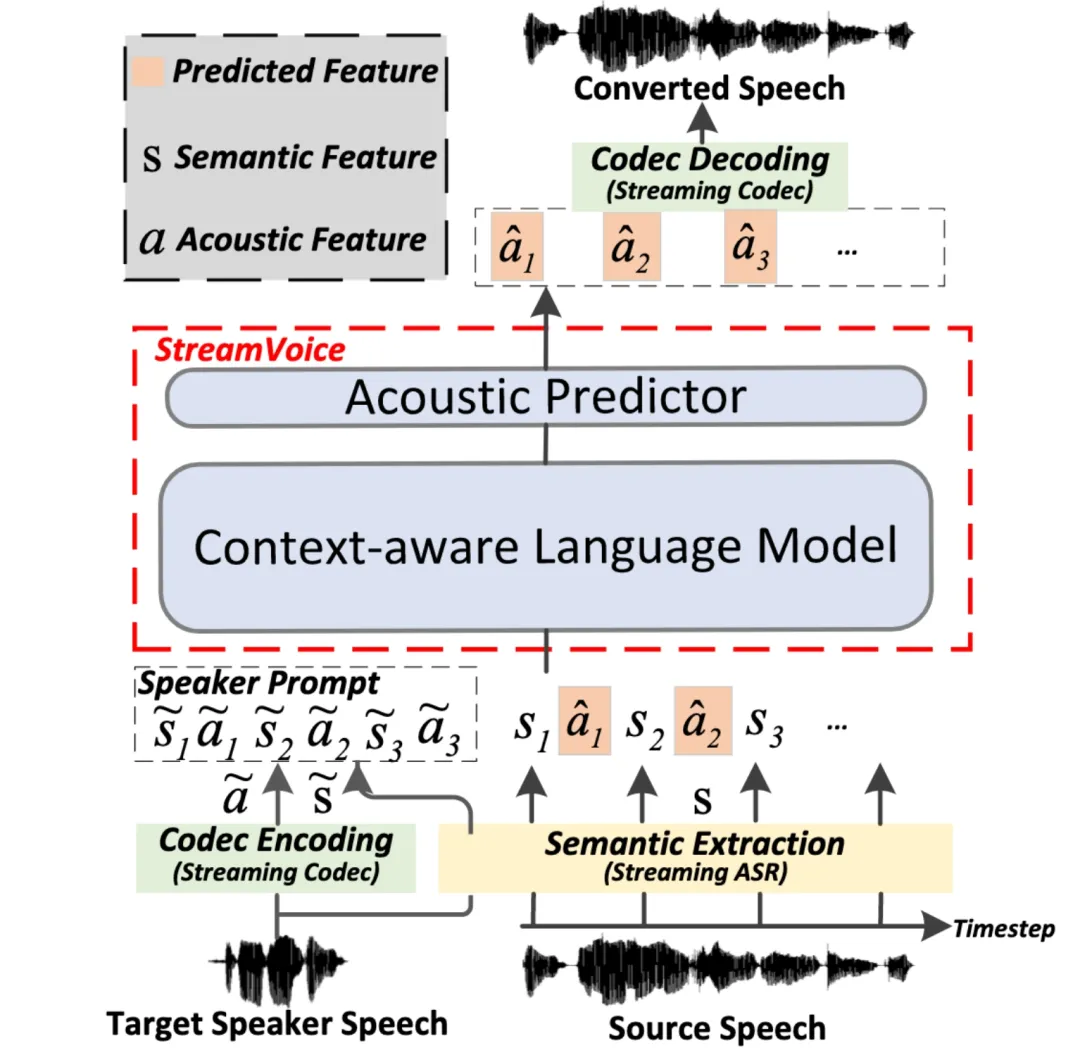 Dans ce travail, nous proposons StreamVoice, un nouveau modèle de conversion vocale sans tir basé sur le streaming LM, pour réaliser une conversion en temps réel pour des locuteurs arbitraires et la parole d'entrée. Plus précisément, pour obtenir des capacités de streaming, StreamVoice utilise un LM entièrement causal et sensible au contexte ainsi qu'un prédicteur acoustique indépendant du timing, tandis que le traitement alterné des caractéristiques sémantiques et acoustiques dans un processus autorégressif élimine la dépendance à l'égard de la parole source complète. Afin de résoudre la dégradation des performances causée par un contexte incomplet dans les scénarios de streaming, deux stratégies sont utilisées pour améliorer la conscience contextuelle du futur et de l'histoire de LM : 1) la prospective contextuelle guidée par l'enseignant, grâce à la prospective contextuelle guidée par l'enseignant. une sémantique précise actuelle et future pour guider le modèle dans la prédiction du contexte manquant ; 2) La stratégie de masquage sémantique encourage le modèle à réaliser une prédiction acoustique à partir d'une entrée sémantique précédemment endommagée et à améliorer la capacité d'apprentissage du contexte historique. Les expériences montrent que StreamVoice possède des capacités de conversion en streaming tout en atteignant des performances zéro-shot proches des systèmes VC sans streaming.
Dans ce travail, nous proposons StreamVoice, un nouveau modèle de conversion vocale sans tir basé sur le streaming LM, pour réaliser une conversion en temps réel pour des locuteurs arbitraires et la parole d'entrée. Plus précisément, pour obtenir des capacités de streaming, StreamVoice utilise un LM entièrement causal et sensible au contexte ainsi qu'un prédicteur acoustique indépendant du timing, tandis que le traitement alterné des caractéristiques sémantiques et acoustiques dans un processus autorégressif élimine la dépendance à l'égard de la parole source complète. Afin de résoudre la dégradation des performances causée par un contexte incomplet dans les scénarios de streaming, deux stratégies sont utilisées pour améliorer la conscience contextuelle du futur et de l'histoire de LM : 1) la prospective contextuelle guidée par l'enseignant, grâce à la prospective contextuelle guidée par l'enseignant. une sémantique précise actuelle et future pour guider le modèle dans la prédiction du contexte manquant ; 2) La stratégie de masquage sémantique encourage le modèle à réaliser une prédiction acoustique à partir d'une entrée sémantique précédemment endommagée et à améliorer la capacité d'apprentissage du contexte historique. Les expériences montrent que StreamVoice possède des capacités de conversion en streaming tout en atteignant des performances zéro-shot proches des systèmes VC sans streaming. 



 Comparaison entre SFT et ReFT sur la présence d'alternatives CoT
Comparaison entre SFT et ReFT sur la présence d'alternatives CoT







![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



