

Avec les progrès actuels de l'IA, il est facile de configurer un modèle d'IA génératif sur votre ordinateur pour créer un chatbot.
Dans cet article, nous verrons comment configurer un chatbot sur votre système à l'aide d'Ollama et Next.js
Commençons par configurer Ollama sur notre système. Visitez ollama.com et téléchargez-le pour votre système d'exploitation. Cela nous permettra d'utiliser la commande ollama dans le terminal/invite de commande.
Vérifiez la version d'Ollama en utilisant la commande ollama -v
Consultez la liste des modèles sur la page de la bibliothèque Ollama.
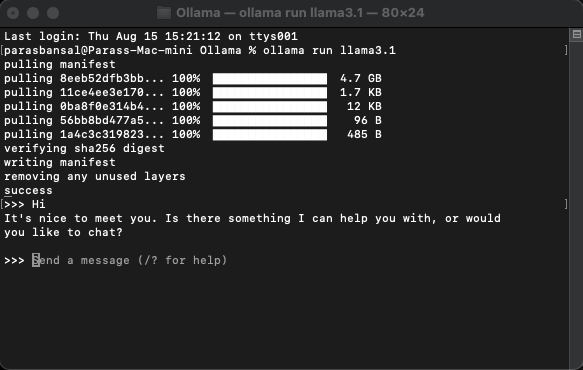
Pour télécharger et exécuter un modèle, exécutez la commande ollama run
Exemple : ollama run llama3.1 ou ollama run gemma2
Vous pourrez discuter avec le modèle directement dans le terminal.
Il y a quelques packages npm qui doivent être installés pour utiliser l'ollama.
Pour installer ces dépendances, exécutez npm i ai ollama ollama-ai-provider.
Sous app/src se trouve un fichier nommé page.tsx.
Supprimons tout ce qu'il contient et commençons par le composant fonctionnel de base :
src/app/page.tsx
export default function Home() {
return (
<main className="flex min-h-screen flex-col items-center justify-start p-24">
{/* Code here... */}
</main>
);
}
Commençons par importer le hook useChat depuis ai/react et react-markdown
"use client";
import { useChat } from "ai/react";
import Markdown from "react-markdown";
Parce que nous utilisons un hook, nous devons convertir cette page en composant client.
Astuce : Vous pouvez créer un composant distinct pour le chat et l'appeler dans le page.tsx pour limiter l'utilisation des composants clients.
Dans le composant, obtenez les messages, l'entrée, handleInputChange et handleSubmit à partir du hook useChat.
const { messages, input, handleInputChange, handleSubmit } = useChat();
Dans JSX, créez un formulaire de saisie pour obtenir la saisie de l'utilisateur afin d'initier la conversation.
<form onSubmit={handleSubmit} className="w-full px-3 py-2">
<input
className="w-full px-3 py-2 border border-gray-700 bg-transparent rounded-lg text-neutral-200"
value={input}
placeholder="Ask me anything..."
onChange={handleInputChange}
/>
</form>
Ce qui est bien, c'est que nous n'avons pas besoin de corriger le gestionnaire ou de maintenir un état pour la valeur d'entrée, le hook useChat nous le fournit.
Nous pouvons afficher les messages en parcourant le tableau des messages.
messages.map((m, i) => (<div key={i}>{m}</div>)
La version stylisée basée sur le rôle de l'expéditeur ressemble à ceci :
<div
className="min-h-[50vh] h-[50vh] max-h-[50vh] overflow-y-auto p-4"
>
<div className="min-h-full flex-1 flex flex-col justify-end gap-2 w-full pb-4">
{messages.length ? (
messages.map((m, i) => {
return m.role === "user" ? (
<div key={i} className="w-full flex flex-col gap-2 items-end">
<span className="px-2">You</span>
<div className="flex flex-col items-center px-4 py-2 max-w-[90%] bg-orange-700/50 rounded-lg text-neutral-200 whitespace-pre-wrap">
<Markdown>{m.content}</Markdown>
</div>
</div>
) : (
<div key={i} className="w-full flex flex-col gap-2 items-start">
<span className="px-2">AI</span>
<div className="flex flex-col max-w-[90%] px-4 py-2 bg-indigo-700/50 rounded-lg text-neutral-200 whitespace-pre-wrap">
<Markdown>{m.content}</Markdown>
</div>
</div>
);
})
) : (
<div className="text-center flex-1 flex items-center justify-center text-neutral-500 text-4xl">
<h1>Local AI Chat</h1>
</div>
)}
</div>
</div>
Jetons un œil à l'ensemble du dossier
src/app/page.tsx
"use client";
import { useChat } from "ai/react";
import Markdown from "react-markdown";
export default function Home() {
const { messages, input, handleInputChange, handleSubmit } = useChat();
return (
);
}
Avec cela, la partie frontend est terminée. Passons maintenant à l'API.
Commençons par créer route.ts dans app/api/chat.
Basé sur la convention de dénomination Next.js, cela nous permettra de gérer les requêtes sur le point de terminaison localhost:3000/api/chat.
src/app/api/chat/route.ts
import { createOllama } from "ollama-ai-provider";
import { streamText } from "ai";
const ollama = createOllama();
export async function POST(req: Request) {
const { messages } = await req.json();
const result = await streamText({
model: ollama("llama3.1"),
messages,
});
return result.toDataStreamResponse();
}
Le code ci-dessus utilise essentiellement ollama et vercel ai pour diffuser les données en réponse.
Exécutez npm run dev pour démarrer le serveur en mode développement.
Ouvrez le navigateur et accédez à localhost:3000 pour voir les résultats.
Si tout est correctement configuré, vous pourrez parler à votre propre chatbot.

Vous pouvez trouver le code source ici : https://github.com/parasbansal/ai-chat
Faites-moi savoir si vous avez des questions dans les commentaires, j'essaierai d'y répondre.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



