
 Tutoriel matériel
Examen du matériel
Spider-Man danse de manière séduisante et la prochaine génération de ControlNet est là ! Lancé par l'équipe Jiajiaya, il est plug-and-play et peut également contrôler la génération vidéo
Tutoriel matériel
Examen du matériel
Spider-Man danse de manière séduisante et la prochaine génération de ControlNet est là ! Lancé par l'équipe Jiajiaya, il est plug-and-play et peut également contrôler la génération vidéo
Spider-Man danse de manière séduisante et la prochaine génération de ControlNet est là ! Lancé par l'équipe Jiajiaya, il est plug-and-play et peut également contrôler la génération vidéo

Utilisez moins de 10 % des paramètres d'entraînement pour obtenir la même génération contrôlable que ControlNet !
Et les modèles courants de la famille Stable Diffusion tels que SDXL et SD1.5 peuvent être adaptés, et ils sont toujours plug-and-play.

En même temps, il peut également être utilisé avec SVD pour contrôler la génération vidéo, et les détails du mouvement peuvent être contrôlés avec précision jusqu'aux doigts.

Derrière ces images et vidéos se trouve ControlNeXt, un outil open source de guidage de génération d'images/vidéos lancé par l'équipe chinoise Jiajiaya de Hong Kong.
Vous pouvez voir au nom que l'équipe R&D l'a positionné comme le ControlNet de nouvelle génération.
Comme l'œuvre classique ResNeXt (une extension de ResNet) des grands dieux He Kaiming et Xie Saining, le nom est également basé sur cette méthode.
Certains internautes estiment que ce nom est bien mérité et qu'il s'agit bien du produit de nouvelle génération, élevant ControlNet à un niveau supérieur.

Certaines personnes ont également dit sans détour que ControlNeXt change la donne, ce qui a considérablement amélioré l'efficacité de la génération contrôlable. Ils ont hâte de voir les œuvres créées par les personnes qui l'utilisent.
Spider-Man danse avec beauté
ControlNeXt prend en charge une variété de modèles de la série SD et est plug-and-play.
Il comprend les modèles de génération d'images SD1.5, SDXL, SD3 (prenant en charge la super résolution) et le modèle de génération vidéo SVD.
Pas grand chose à dire, regardons juste les résultats.
Vous pouvez voir qu'en ajoutant le guidage Edge (Canny) dans SDXL, la fille en deux dimensions dessinée et les lignes de contrôle s'adaptent presque parfaitement.

Même si les contours de contrôle sont nombreux et détaillés, le modèle peut toujours dessiner des images qui répondent aux exigences.

Et s'intègre parfaitement aux autres poids LoRA sans entraînement supplémentaire.
Par exemple, dans SD1.5, vous pouvez utiliser des conditions de contrôle de posture (Pose) avec différentes LoRA pour former des personnages avec des styles différents ou même dans plusieurs dimensions, mais avec les mêmes actions.

De plus, ControlNeXt prend également en charge les modes de contrôle de masque et de profondeur.

SD3 prend également en charge la Super Résolution, qui peut générer des images ultra haute définition.

Pendant la génération vidéo, ControlNeXt peut contrôler les mouvements des personnages.
Par exemple, laissez Spider-Man danser la belle danse de TikTok, et même les mouvements des doigts sont imités avec assez de précision.

Il a même fait pousser les mains d'une chaise et exécuter la même danse Bien que ce soit un peu abstrait, la reproduction de l'action est plutôt bonne.

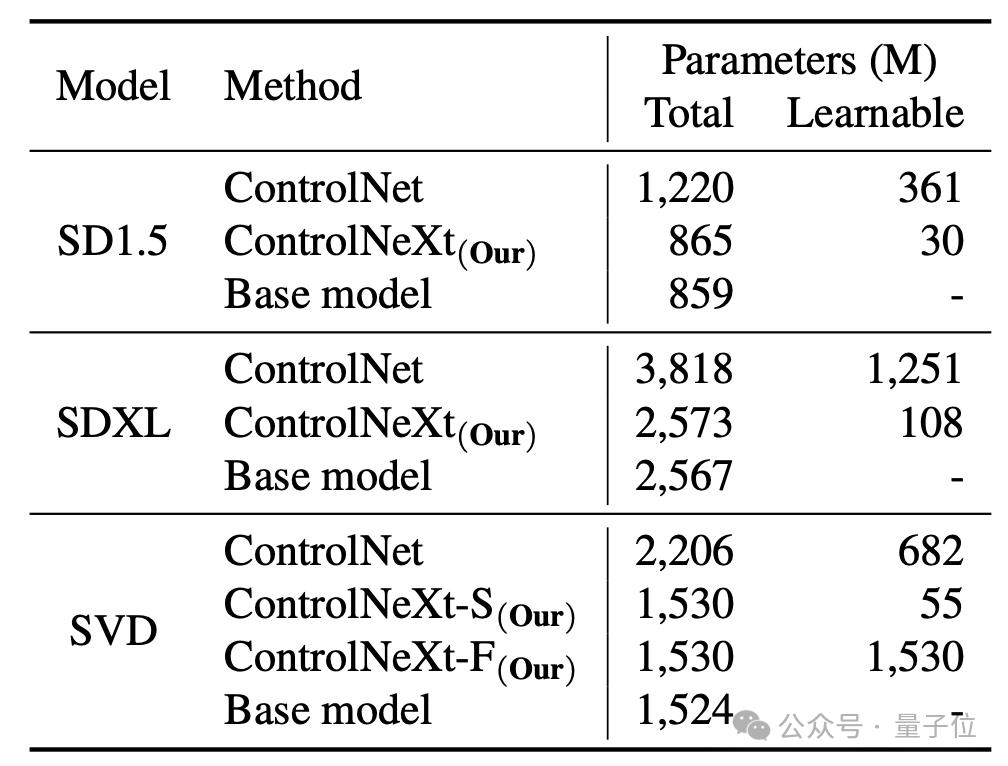
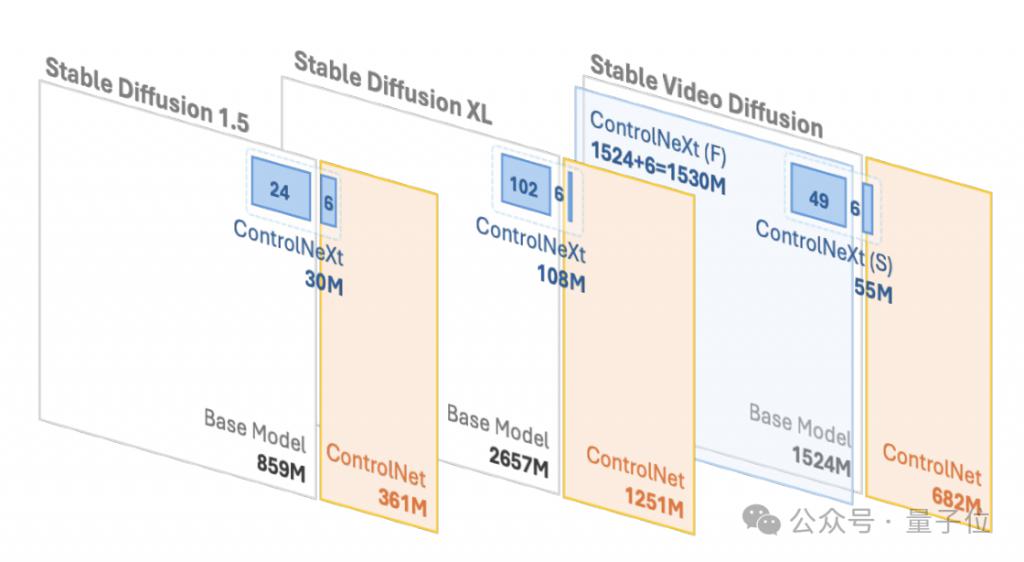
Et par rapport au ControlNet original, ControlNeXt nécessite moins de paramètres de formation et converge plus rapidement.
Par exemple, dans SD1.5 et SDXL, ControlNet nécessite respectivement 361 millions et 1,251 milliard de paramètres apprenables, mais ControlNeXt n'en nécessite respectivement que 30 millions et 108 millions, soit moins de 10 % de ControlNet.
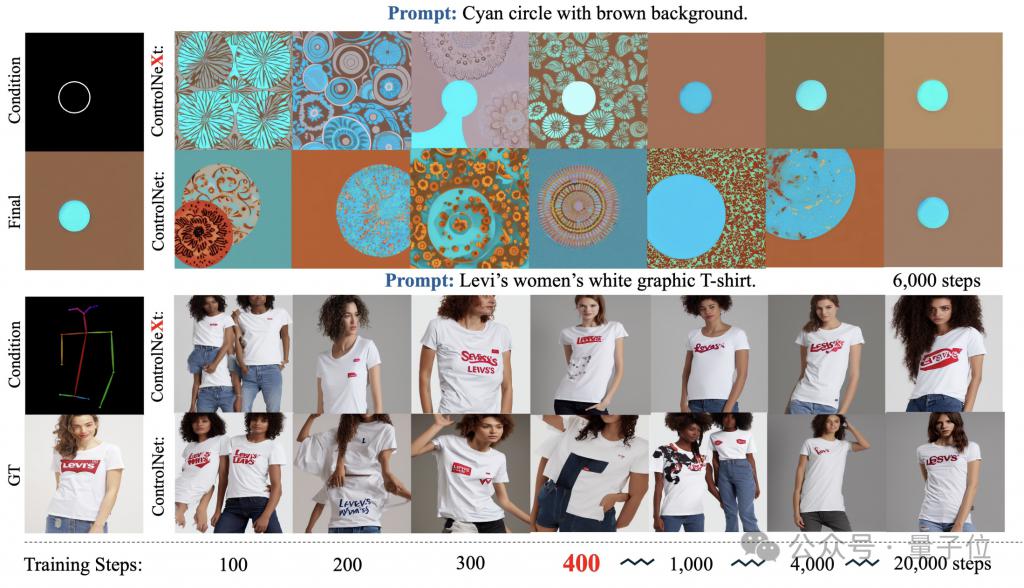
Pendant le processus de formation, ControlNeXt est proche de la convergence à environ 400 étapes, mais ControlNet nécessite dix fois, voire des dizaines de fois, le nombre d'étapes.
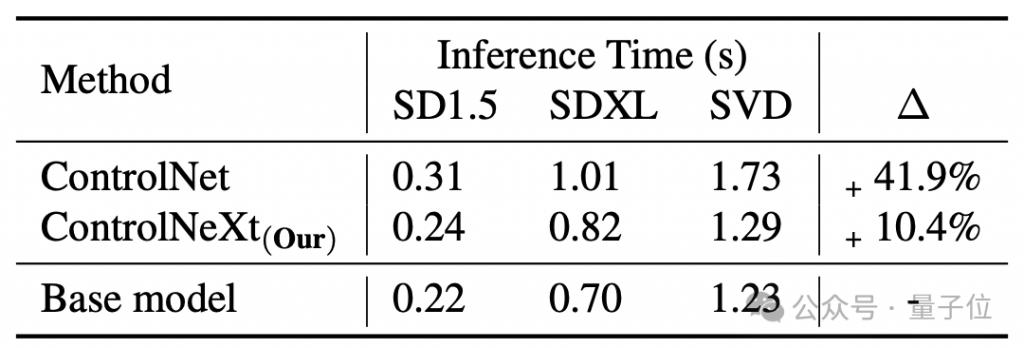
La vitesse de génération est également plus rapide que ControlNet En moyenne, ControlNet est équivalent au modèle de base, qui apporte 41,9% de retard, mais ControlNeXt n'en a que 10,4%.
Alors, comment ControlNeXt est-il implémenté et quelles améliorations ont été apportées à ControlNet ?
Un module de contrôle conditionnel plus léger
Tout d'abord, utilisez une image pour comprendre l'ensemble du flux de travail de ControlNeXt.
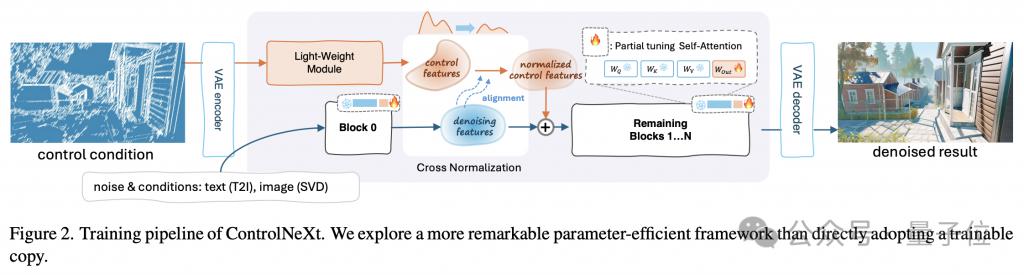
La clé de l'allègement est que ControlNeXt supprime l'énorme branche de contrôle dans ControlNet et introduit à la place un module de convolution léger composé d'un petit nombre de blocs ResNet.
Ce module est chargé d'extraire les représentations de caractéristiques des conditions de contrôle (telles que les masques de segmentation sémantique, les priorités de points clés, etc.).
La quantité de paramètres d'entraînement est généralement inférieure à 10 % du modèle pré-entraîné dans ControlNet, mais il peut toujours bien apprendre les informations de contrôle conditionnel d'entrée. Cette conception réduit considérablement la surcharge de calcul et l'utilisation de la mémoire.
Plus précisément, il échantillonne à intervalles égaux différentes couches de réseau d'un modèle pré-entraîné pour former un sous-ensemble de paramètres utilisés pour l'entraînement, tandis que les paramètres restants sont gelés.
De plus, lors de la conception de l'architecture de ControlNeXt, l'équipe de recherche a également maintenu la cohérence de la structure du modèle avec l'architecture d'origine, réalisant ainsi le plug-and-play.
Qu'il s'agisse de ControlNet ou de ControlNeXt, l'injection d'informations de contrôle conditionnel est un maillon important.
Au cours de ce processus, l'équipe de recherche de ControlNeXt a mené des recherches approfondies sur deux questions clés : la sélection des sites d'injection et la conception des méthodes d'injection.
L'équipe de recherche a observé que dans la plupart des tâches de génération contrôlables, la forme d'informations conditionnelles pour guider la génération est relativement simple et fortement corrélée aux caractéristiques du processus de débruitage.
L'équipe a donc estimé qu'il n'était pas nécessaire d'injecter des informations de contrôle dans chaque couche du réseau de débruitage, elle a donc choisi d'agréger les caractéristiques conditionnelles et les caractéristiques de débruitage uniquement dans la couche intermédiaire du réseau.
La méthode d'agrégation est également aussi simple que possible : après avoir aligné les distributions des deux ensembles de caractéristiques à l'aide de la normalisation croisée, ajoutez-les directement.
Cela garantit non seulement que le signal de contrôle affecte le processus de débruitage, mais évite également l'introduction de paramètres d'apprentissage supplémentaires et l'instabilité due à des opérations complexes telles que le mécanisme d'attention.
La normalisation croisée est également une autre technologie de base de ControlNeXt, remplaçant les stratégies d'initialisation progressive précédemment couramment utilisées telles que la convolution zéro.
Les méthodes traditionnelles atténuent le problème d'effondrement en libérant progressivement l'influence des nouveaux modules à partir de zéro, mais le résultat est souvent une convergence lente.
La normalisation croisée utilise directement la moyenne μ et la variance σ des caractéristiques de débruitage du réseau fédérateur pour normaliser les caractéristiques produites par le module de contrôle, de sorte que la distribution des données des deux soit aussi alignée que possible.
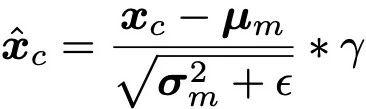
(Remarque : est une petite constante ajoutée pour la stabilité numérique, γ est un paramètre de mise à l'échelle.)
Les fonctionnalités de contrôle normalisées sont ensuite ajustées en amplitude et en ligne de base via les paramètres d'échelle et de décalage, puis combinées avec l'ajout de fonctionnalités de débruitage. non seulement évite la sensibilité de l'initialisation des paramètres, mais permet également aux conditions de contrôle de prendre effet dès les premiers stades de la formation pour accélérer le processus de convergence.
De plus, ControlNeXt utilise également le module de contrôle pour apprendre le mappage des informations de condition avec les caractéristiques de l'espace latent, ce qui le rend plus abstrait et sémantique, et plus propice à la généralisation à des conditions de contrôle invisibles.
Page d'accueil du projet :
https://pbihao.github.io/projects/controlnext/index.html
Adresse papier :
https://arxiv.org/abs/2408.06070
GitHub :
https : //github.com/dvlab-research/ControlNeXt
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Comment définir le statut d'absence programmée dans Teams
Feb 19, 2024 pm 07:21 PM
Comment définir le statut d'absence programmée dans Teams
Feb 19, 2024 pm 07:21 PM
Vous en avez assez de recevoir des messages et des appels de Microsoft Teams pendant vos vacances ? Ce n'est plus le cas ; Teams permet désormais aux utilisateurs de planifier leur absence du bureau. Cela permettra à vos coéquipiers de savoir que vous êtes absent ou en vacances. Comment définir le statut d'absence programmée dans les équipes Il existe deux façons de définir le statut d'absence programmée dans Microsoft Teams : À partir de votre photo de profil Dans les paramètres de l'équipe, examinons-les maintenant en détail. Planifier le statut d'absence du bureau dans Teams avec photo de profil Cliquez sur votre photo de profil en haut, puis cliquez sur Définir le message de statut. Cliquez sur Planifier l'heure d'absence en bas et l'onglet Hors jours s'ouvrira. Ici, activez la bascule à côté pour activer les réponses automatiques, saisissez un message d'absence du bureau et activez l'envoi de réponses uniquement dans un certain laps de temps. Suivant,
![Les réunions Teams n'apparaissent pas dans Outlook [FIXED]](https://img.php.cn/upload/article/000/465/014/170831343613934.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Les réunions Teams n'apparaissent pas dans Outlook [FIXED]
Feb 19, 2024 am 11:30 AM
Les réunions Teams n'apparaissent pas dans Outlook [FIXED]
Feb 19, 2024 am 11:30 AM
Le complément Teams Meeting n’apparaît-il pas dans Microsoft Outlook ? Certains utilisateurs de MSOutlook ont signalé que le complément Teams ne fonctionne pas ou disparaît du ruban. Désormais, ce problème peut avoir plusieurs causes. Découvrons ces raisons. Pourquoi la présence de Teams n'apparaît-elle pas dans Outlook ? Si vous ne trouvez pas la nouvelle option de réunion Teams dans Outlook, cela peut être dû au fait que l'option est désactivée dans les paramètres Outlook. En dehors de cela, le problème peut provenir de l'utilisation d'une application Outlook obsolète ou d'un fichier Microsoft.Teams.AddinLoader.dll corrompu. Plusieurs utilisateurs d'Outlook utilisant le complément Teams ont signalé ce problème
 Utiliser PHP pour contrôler la caméra : analyse de l'ensemble du processus depuis la connexion jusqu'à la prise de vue
Jul 30, 2023 pm 03:21 PM
Utiliser PHP pour contrôler la caméra : analyse de l'ensemble du processus depuis la connexion jusqu'à la prise de vue
Jul 30, 2023 pm 03:21 PM
Utilisez PHP pour contrôler la caméra : Analysez l'ensemble du processus, de la connexion à la prise de vue. Les applications de caméra sont de plus en plus répandues, comme les appels vidéo, les systèmes de surveillance, etc. Dans les applications Web, nous devons souvent contrôler et faire fonctionner des caméras via PHP. Cet article explique comment utiliser PHP pour réaliser l'ensemble du processus, de la connexion de la caméra à la prise de vue. Confirmez l'état de connexion de la caméra. Avant de commencer à utiliser la caméra, nous devons d'abord confirmer l'état de connexion de la caméra. PHP fournit une bibliothèque d'extensions vidéo pour faire fonctionner la caméra. Nous pouvons passer le code suivant
 Comment générer k dates aléatoires entre deux dates en utilisant Python ?
Sep 09, 2023 pm 08:17 PM
Comment générer k dates aléatoires entre deux dates en utilisant Python ?
Sep 09, 2023 pm 08:17 PM
La génération de données aléatoires est très importante dans le domaine de la science des données. Lors de la création de prévisions de réseaux neuronaux, de données boursières, etc., la date est généralement utilisée comme l'un des paramètres. Nous devrons peut-être générer des nombres aléatoires entre deux dates à des fins d'analyse statistique. Cet article montrera comment générer k dates aléatoires entre deux dates données à l'aide des modules random et datetime. Datetime est la bibliothèque intégrée de Python pour la gestion du temps. D'un autre côté, le module aléatoire aide à générer des nombres aléatoires. On peut donc combiner les modules random et datetime pour générer une date aléatoire entre deux dates. La syntaxe random.randint (start, end, k) random fait ici référence à la bibliothèque aléatoire Python. La méthode Randint utilise trois éléments importants
 Comment définir des rappels récurrents dans Microsoft Teams ?
Feb 18, 2024 pm 04:45 PM
Comment définir des rappels récurrents dans Microsoft Teams ?
Feb 18, 2024 pm 04:45 PM
Voulez-vous savoir comment définir des rappels récurrents dans Microsoft Teams pour rester au top de vos responsabilités ? C'est pourquoi nous avons créé cet article pour vous guider tout au long du processus. Tout comme les rappels de tâches dans Outlook, les rappels dans l'application Teams vous permettent de recevoir des rappels réguliers des événements à venir, des réunions importantes ou des délais pour vous assurer que rien ne passe entre les mailles du filet. Ainsi, que vous soyez un professionnel essayant d'être productif ou un étudiant jonglant avec plusieurs engagements, ce didacticiel vous aidera à définir des rappels dans Microsoft Teams pour respecter votre emploi du temps quotidien. Comment définir des rappels récurrents dans Microsoft Teams ? Microsoft Teams ne dispose pas de rappels intégrés comme Outlook pour vous aider à vous souvenir des tâches, des réunions ou des appels.
![Comment désactiver les fenêtres contextuelles de contrôle du volume multimédia [permanent]](https://img.php.cn/upload/article/000/000/164/168493981948502.png?x-oss-process=image/resize,m_fill,h_207,w_330) Comment désactiver les fenêtres contextuelles de contrôle du volume multimédia [permanent]
May 24, 2023 pm 10:50 PM
Comment désactiver les fenêtres contextuelles de contrôle du volume multimédia [permanent]
May 24, 2023 pm 10:50 PM
Lorsque vous utilisez la touche de raccourci correspondante pour affiner le niveau de volume, une fenêtre contextuelle de contrôle du volume multimédia apparaîtra à l'écran. Cela peut être ennuyeux, alors lisez la suite pour découvrir différentes façons de désactiver définitivement les fenêtres contextuelles de contrôle du volume multimédia. Comment désactiver la fenêtre contextuelle de contrôle du volume multimédia ? 1. Cliquez sur l'icône Windows dans la barre des tâches de Google Chrome, tapez chrome dans la barre de recherche en haut et sélectionnez les résultats de recherche pertinents pour lancer Google Chrome. Tapez ou copiez-collez ce qui suit dans la barre d'adresse et appuyez sur la touche . Entrez chrome://flags, tapez les clés multimédias dans la zone de recherche en haut et sélectionnez Désactiver dans la liste déroulante Gestion des clés multimédias matérielles. Quittez maintenant l'application Google Chrome et relancez-la. Google
 Comment planifier une réunion d'équipe dans Outlook
Feb 19, 2024 pm 07:30 PM
Comment planifier une réunion d'équipe dans Outlook
Feb 19, 2024 pm 07:30 PM
Savez-vous? Si vous utilisez Microsoft Teams et Outlook pour le travail, vous pouvez planifier des réunions d'équipe dans Outlook. Oui, vous avez bien entendu. Mais pour accéder à cette fonctionnalité, vous devez disposer d’un compte scolaire ou professionnel Microsoft Office 365. Si vous utilisez un compte personnel, vous devrez planifier des réunions via l'application Microsoft Teams (mobile, PC ou Web). Donc, si vous remplissez les conditions requises pour le compte, voici un didacticiel concis pour configurer les réunions Microsoft Teams dans Outlook. Comment planifier une réunion d'équipe dans Outlook Lors de la planification d'une réunion d'équipe, il est important de s'assurer que l'application Outlook est mise à jour vers la dernière version car
 Comment générer un code de vérification d'image actualisable à l'aide de PHP
Sep 13, 2023 am 11:54 AM
Comment générer un code de vérification d'image actualisable à l'aide de PHP
Sep 13, 2023 am 11:54 AM
Comment utiliser PHP pour générer des codes de vérification d'image actualisables. Avec le développement d'Internet, afin de prévenir les attaques malveillantes et les opérations automatiques des machines, de nombreux sites Web utilisent des codes de vérification pour la vérification des utilisateurs. Un type courant de code de vérification est le code de vérification d'image, qui génère une image contenant des caractères aléatoires et oblige l'utilisateur à saisir les caractères corrects avant de continuer. Cet article explique comment utiliser PHP pour générer des codes de vérification d'image actualisables et fournit des exemples de code spécifiques. Étape 1 : Créer une image de code de vérification Tout d'abord, nous devons créer une image de code de vérification
