

Charger des données dans Neo4j

Dans le blog précédent, nous avons vu comment installer et configurer neo4j localement avec 2 plugins APOC et Graph Data Science Library - GDS. Dans ce blog, je vais prendre un ensemble de données sur les jouets (produits dans un site Web de commerce électronique) et le stocker dans Neo4j.
Allocation de mémoire suffisante pour Neo4j
Avant de commencer à charger les données, si dans votre cas d'utilisation vous disposez d'énormes données, assurez-vous qu'une quantité suffisante de mémoire est allouée à neo4j. Pour ce faire :
- Cliquez sur les trois points à droite d'ouvrir

- Cliquez sur Ouvrir le dossier -> Configuration

- Cliquez sur neo4j.conf
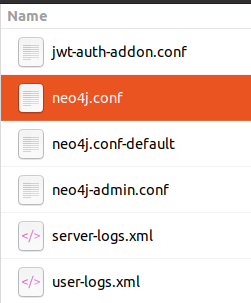
- Recherchez heap dans neo4j.conf, décommentez les lignes 77, 78 et remplacez 256m par 2048m, cela garantit que 2048 Mo sont alloués au stockage des données dans neo4j .

Création de nœuds
Les graphiques ont deux nœuds et relations de composants principaux, créons d'abord les nœuds et établissons ensuite les relations.
Les données que j'utilise sont présentes ici - data
Utilisez le fichier conditions.txt présent ici pour créer un environnement virtuel python - exigences.txt
Définissons diverses fonctions pour transmettre des données.
Importation des bibliothèques nécessaires
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI
- Nous allons utiliser openai pour générer des intégrations
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
- Pour générer des intégrations
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
- Selon notre ensemble de données, nous pouvons avoir deux étiquettes de nœuds uniques, Catégorie : Catégorie de produit, Produit : Nom du produit. Créons une étiquette de catégorie, neo4j propose quelque chose appelé propriété, vous pouvez imaginer qu'il s'agit de métadonnées pour un nœud particulier. Ici name et embedding sont les propriétés. Nous stockons donc le nom de la catégorie et son intégration correspondante dans la base de données.
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
- De même, nous pouvons créer des nœuds de produits, ici les propriétés seraient nom, description, prix, période_de garantie, available_stock, review_rating, product_release_date, intégration
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
- Créons maintenant une autre fonction pour exécuter les requêtes générées par les 2 fonctions ci-dessus. Mettez à jour votre nom d'utilisateur et votre mot de passe de manière appropriée.
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
- Code complet
import pandas as pd
from neo4j import GraphDatabase
from openai import OpenAI
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CREATE CATEGORY
query_list = create_category(product_data_df)
execute_bulk_query(query_list)
# CREATE PRODUCT
query_list = create_product(product_data_df)
execute_bulk_query(query_list)
Créer des relations
- Nous allons créer des relations entre Catégorie et Produit et le nom de la relation serait CATEGORY_CONTAINS_PRODUCT
from neo4j import GraphDatabase
import pandas as pd
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def create_category_food_relationship_query(product_data_df):
"""
Used to create relationship between category and products
:param product_data_df: dataframe - data
:return: query_list: list - cypher queries
"""
query = """MATCH (c:Category {name: '%s'}), (p:Product {name: '%s'}) CREATE (c)-[:CATEGORY_CONTAINS_PRODUCT]->(p)"""
query_list = []
for idx, row in product_data_df.iterrows():
query_list.append(query % (row['Category'], row['Product Name']))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CATEGORY - FOOD RELATIONSHIP
query_list = create_category_food_relationship_query(product_data_df)
execute_bulk_query(query_list)
- En utilisant la requête MATCH pour faire correspondre les nœuds déjà créés, nous établissons des relations entre eux.
Visualiser les nœuds créés
Passez la souris sur l'icône ouvrir et cliquez sur navigateur neo4j pour visualiser les nœuds que nous avons créés.
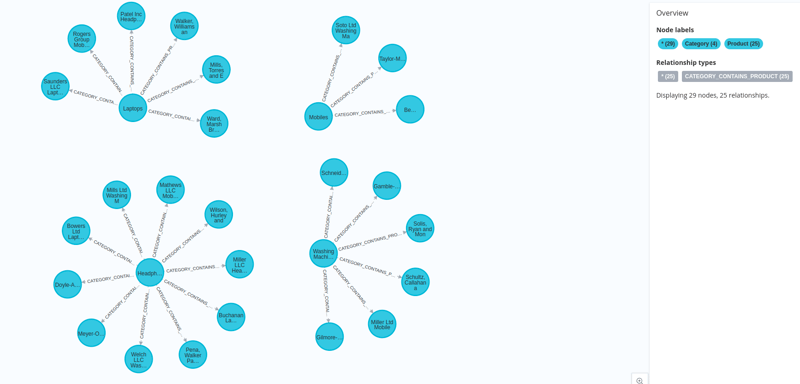
Et nos données sont chargées dans neo4j avec leurs intégrations.
Dans les prochains blogs, nous verrons comment créer un moteur de requête graphique en utilisant Python et utiliser les données récupérées pour effectuer une génération augmentée.
J'espère que cela vous aidera... À bientôt !!!
LinkedIn - https://www.linkedin.com/in/praveenr2998/
Github - https://github.com/praveenr2998/Creating-Lightweight-RAG-Systems-With-Graphs/tree/main/push_data_to_db
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Python vs C: courbes d'apprentissage et facilité d'utilisation
Apr 19, 2025 am 12:20 AM
Python vs C: courbes d'apprentissage et facilité d'utilisation
Apr 19, 2025 am 12:20 AM
Python est plus facile à apprendre et à utiliser, tandis que C est plus puissant mais complexe. 1. La syntaxe Python est concise et adaptée aux débutants. Le typage dynamique et la gestion automatique de la mémoire le rendent facile à utiliser, mais peuvent entraîner des erreurs d'exécution. 2.C fournit des fonctionnalités de contrôle de bas niveau et avancées, adaptées aux applications haute performance, mais a un seuil d'apprentissage élevé et nécessite une gestion manuelle de la mémoire et de la sécurité.
 Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Pour maximiser l'efficacité de l'apprentissage de Python dans un temps limité, vous pouvez utiliser les modules DateTime, Time et Schedule de Python. 1. Le module DateTime est utilisé pour enregistrer et planifier le temps d'apprentissage. 2. Le module de temps aide à définir l'étude et le temps de repos. 3. Le module de planification organise automatiquement des tâches d'apprentissage hebdomadaires.
 Python vs. C: Explorer les performances et l'efficacité
Apr 18, 2025 am 12:20 AM
Python vs. C: Explorer les performances et l'efficacité
Apr 18, 2025 am 12:20 AM
Python est meilleur que C dans l'efficacité du développement, mais C est plus élevé dans les performances d'exécution. 1. La syntaxe concise de Python et les bibliothèques riches améliorent l'efficacité du développement. Les caractéristiques de type compilation et le contrôle du matériel de CC améliorent les performances d'exécution. Lorsque vous faites un choix, vous devez peser la vitesse de développement et l'efficacité de l'exécution en fonction des besoins du projet.
 Apprendre Python: 2 heures d'étude quotidienne est-elle suffisante?
Apr 18, 2025 am 12:22 AM
Apprendre Python: 2 heures d'étude quotidienne est-elle suffisante?
Apr 18, 2025 am 12:22 AM
Est-ce suffisant pour apprendre Python pendant deux heures par jour? Cela dépend de vos objectifs et de vos méthodes d'apprentissage. 1) Élaborer un plan d'apprentissage clair, 2) Sélectionnez les ressources et méthodes d'apprentissage appropriées, 3) la pratique et l'examen et la consolidation de la pratique pratique et de l'examen et de la consolidation, et vous pouvez progressivement maîtriser les connaissances de base et les fonctions avancées de Python au cours de cette période.
 Python vs C: Comprendre les principales différences
Apr 21, 2025 am 12:18 AM
Python vs C: Comprendre les principales différences
Apr 21, 2025 am 12:18 AM
Python et C ont chacun leurs propres avantages, et le choix doit être basé sur les exigences du projet. 1) Python convient au développement rapide et au traitement des données en raison de sa syntaxe concise et de son typage dynamique. 2) C convient à des performances élevées et à une programmation système en raison de son typage statique et de sa gestion de la mémoire manuelle.
 Quelle partie fait partie de la bibliothèque standard Python: listes ou tableaux?
Apr 27, 2025 am 12:03 AM
Quelle partie fait partie de la bibliothèque standard Python: listes ou tableaux?
Apr 27, 2025 am 12:03 AM
PythonlistSaReparmentofthestandardLibrary, tandis que les coloccules de colocède, tandis que les colocculations pour la base de la Parlementaire, des coloments de forage polyvalent, tandis que la fonctionnalité de la fonctionnalité nettement adressée.
 Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python excelle dans l'automatisation, les scripts et la gestion des tâches. 1) Automatisation: La sauvegarde du fichier est réalisée via des bibliothèques standard telles que le système d'exploitation et la fermeture. 2) Écriture de script: utilisez la bibliothèque PSUTIL pour surveiller les ressources système. 3) Gestion des tâches: utilisez la bibliothèque de planification pour planifier les tâches. La facilité d'utilisation de Python et la prise en charge de la bibliothèque riche en font l'outil préféré dans ces domaines.
 Python pour le développement Web: applications clés
Apr 18, 2025 am 12:20 AM
Python pour le développement Web: applications clés
Apr 18, 2025 am 12:20 AM
Les applications clés de Python dans le développement Web incluent l'utilisation des cadres Django et Flask, le développement de l'API, l'analyse et la visualisation des données, l'apprentissage automatique et l'IA et l'optimisation des performances. 1. Framework Django et Flask: Django convient au développement rapide d'applications complexes, et Flask convient aux projets petits ou hautement personnalisés. 2. Développement de l'API: Utilisez Flask ou DjangorestFramework pour construire RestulAPI. 3. Analyse et visualisation des données: utilisez Python pour traiter les données et les afficher via l'interface Web. 4. Apprentissage automatique et AI: Python est utilisé pour créer des applications Web intelligentes. 5. Optimisation des performances: optimisée par la programmation, la mise en cache et le code asynchrones
