Désormais, Long Context Visual Language Model (VLM) dispose d'une nouvelle solution full-stack - LongVILA, qui intègre le système, la formation de modèles et le développement d'ensembles de données.
À ce stade, il est très important de combiner la compréhension multimodale du modèle avec la capacité de contexte long. Le modèle de base qui prend en charge plus de modalités peut accepter des signaux d'entrée plus flexibles afin que les gens puissent se diversifier. façons d’interagir avec les modèles. Et un contexte plus long permet au modèle de traiter davantage d'informations, telles que de longs documents et de longues vidéos. Cette capacité fournit également les fonctionnalités nécessaires à des applications plus réelles. Cependant, le problème actuel est que certains travaux ont permis des modèles de langage visuel (VLM) à contexte long, mais généralement dans une approche simplifiée plutôt que de fournir une solution globale. La conception full-stack est cruciale pour les modèles de langage visuel à long contexte. La formation de grands modèles est généralement une tâche complexe et systématique qui nécessite une ingénierie des données et une co-conception de logiciels système. Contrairement aux LLM contenant uniquement du texte, les VLM (par exemple, LLaVA) nécessitent souvent des architectures de modèles uniques et des stratégies de formation distribuées flexibles. De plus, la modélisation de contextes longs nécessite non seulement des données de contexte longues, mais également une infrastructure capable de prendre en charge une formation en contexte long gourmande en mémoire. Par conséquent, une conception full-stack bien planifiée (couvrant le système, les données et le pipeline) est essentielle pour un VLM à contexte long. Dans cet article, des chercheurs de NVIDIA, du MIT, de l'UC Berkeley et de l'Université du Texas à Austin présentent LongVILA, une solution complète pour la formation et le déploiement de modèles de langage visuel à contexte long, y compris la conception de systèmes et la formation de modèles. construction de stratégies et d’ensembles de données.
- Adresse papier : https://arxiv.org/pdf/2408.10188
- Adresse code : https://github.com/NVlabs/VILA/blob/main/LongVILA.md
- Titre de l'article : LONGVILA : MISE À L'ÉCHELLE DES MODÈLES DE LANGAGE VISUEL À LONG-CONTEXTE POUR LES VIDÉOS LONGUES
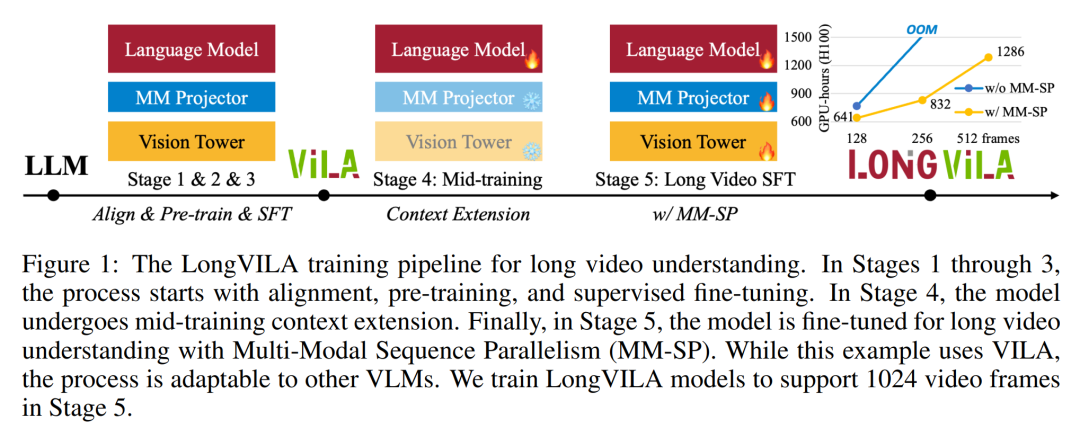
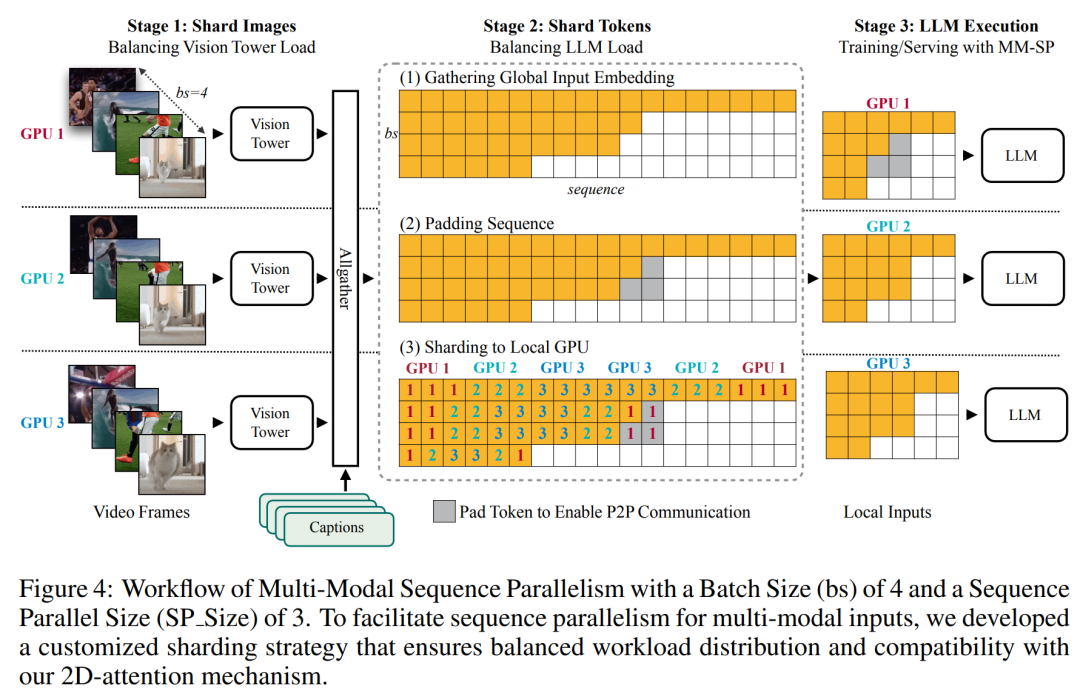
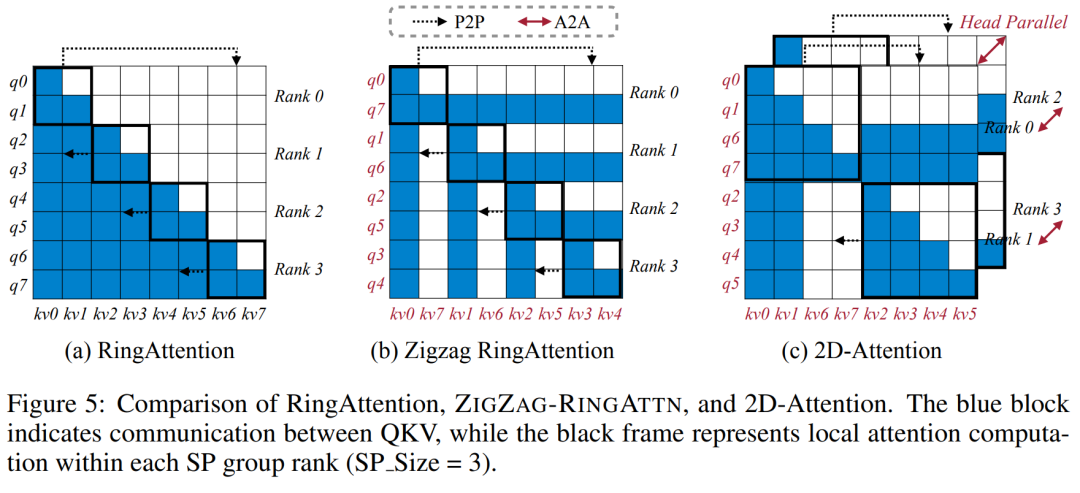
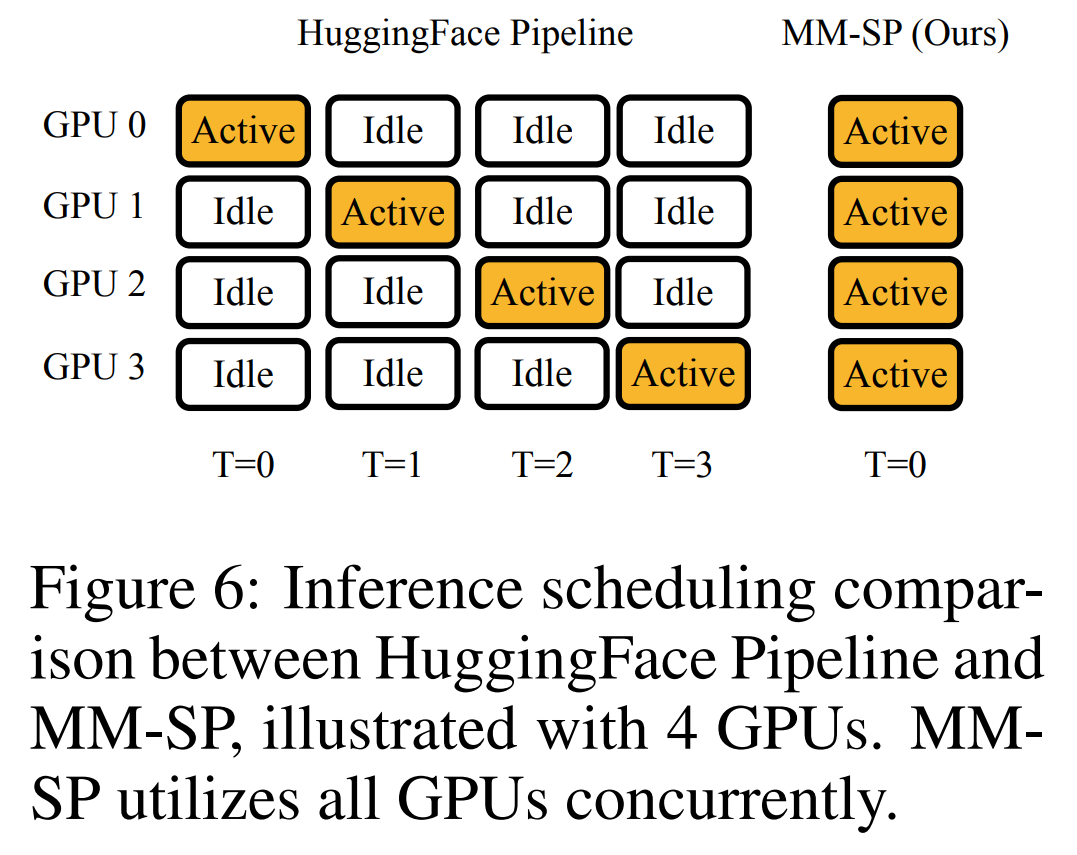
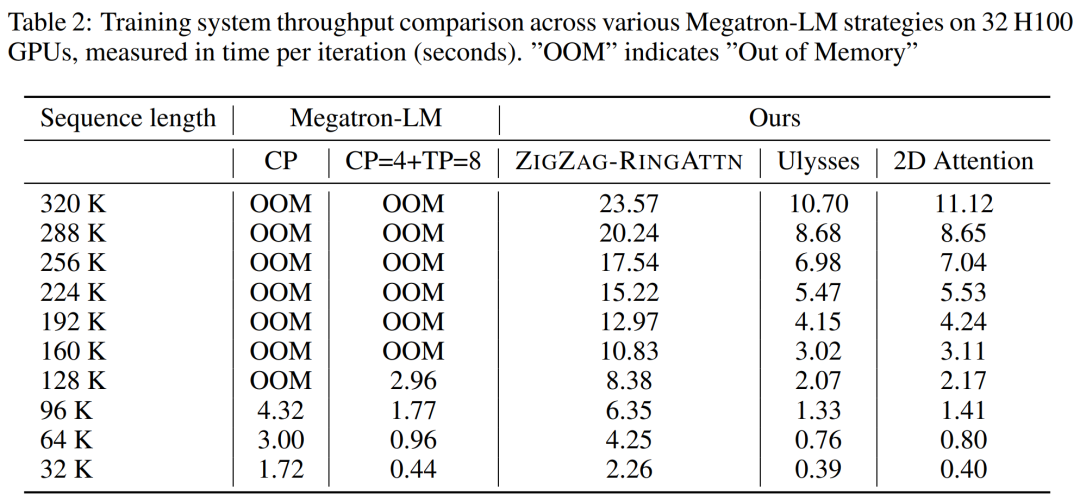
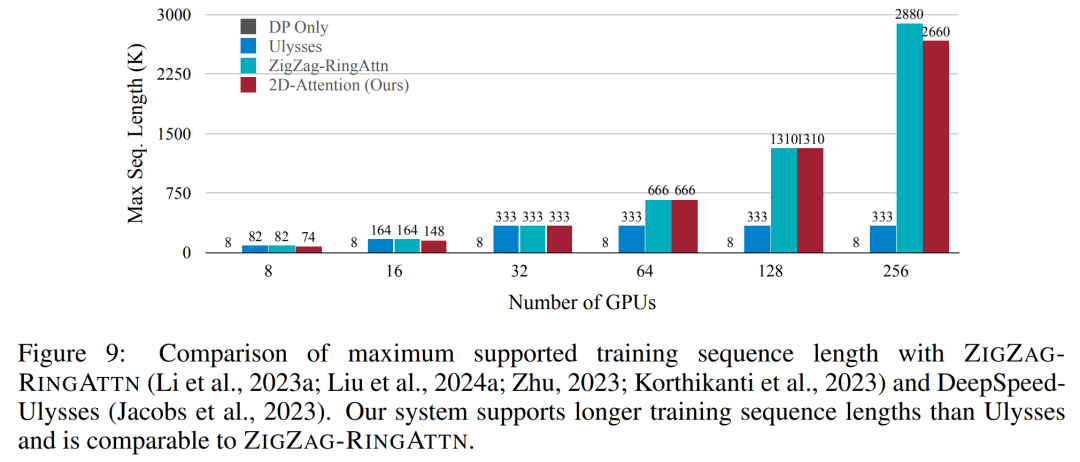
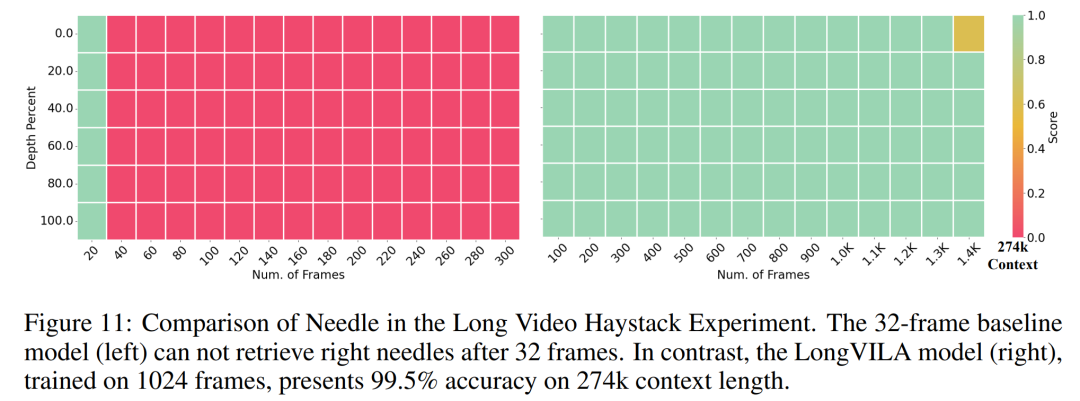
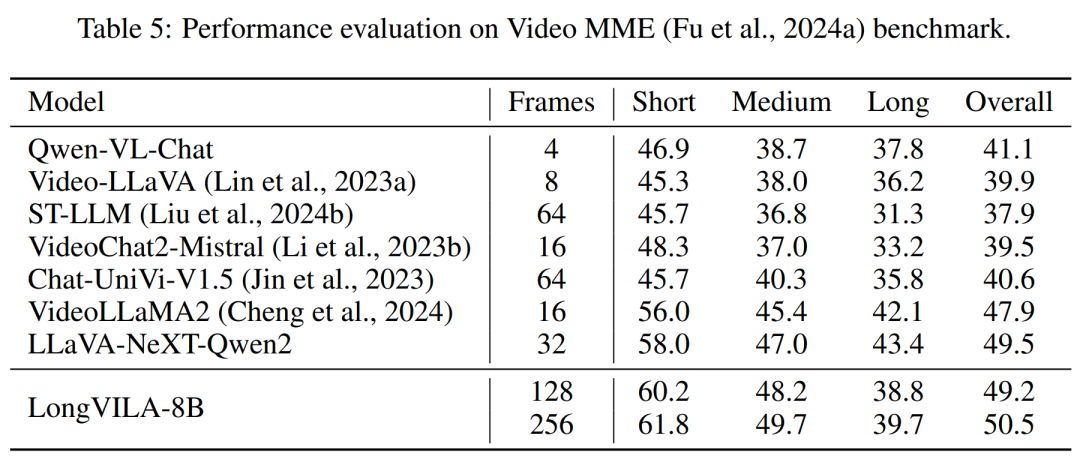
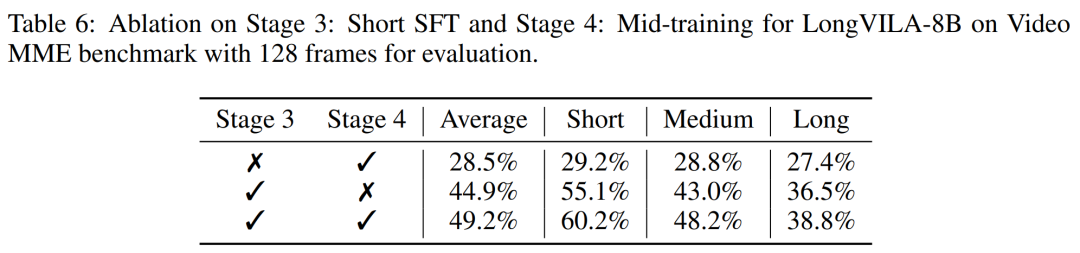
Pour l'infrastructure de formation, l'étude a établi un cadre efficace et convivial, à savoir Multimodal Sequence Parallel (MM-SP) ), qui prend en charge la mémoire d'entraînement - VLM à contexte long et dense. Pour le pipeline de formation, les chercheurs ont mis en œuvre un processus de formation en cinq étapes, comme le montre la figure 1 : à savoir (1) un alignement multimodal, (2) une pré-formation à grande échelle, (3) une formation courte. réglage fin supervisé, (4) extension contextuelle du LLM et (5) réglage fin supervisé de longue durée. À titre d'inférence, MM-SP résout le défi de l'utilisation de la mémoire cache KV, qui peut devenir un goulot d'étranglement lors du traitement de très longues séquences. En utilisant LongVILA pour augmenter le nombre d'images vidéo, les résultats expérimentaux montrent que les performances de cette étude continuent de s'améliorer sur les tâches VideoMME et de sous-titres vidéo longs (Figure 2). Le modèle LongVILA formé sur 1 024 images a atteint une précision de 99,5 % dans l'expérience aiguille dans une botte de foin de 1 400 images, ce qui équivaut à une longueur de contexte de 274 000 jetons. De plus, le système MM-SP peut étendre efficacement la longueur du contexte à 2 millions de jetons sans points de contrôle de gradient, atteignant une accélération de 2,1x à 5,7x par rapport au parallélisme de séquence en anneau et au parallélisme de contexte Megatron+ Le parallélisme Tensor atteint une accélération de 1,1x à 1,4x par rapport à Tensor. Parallèle. 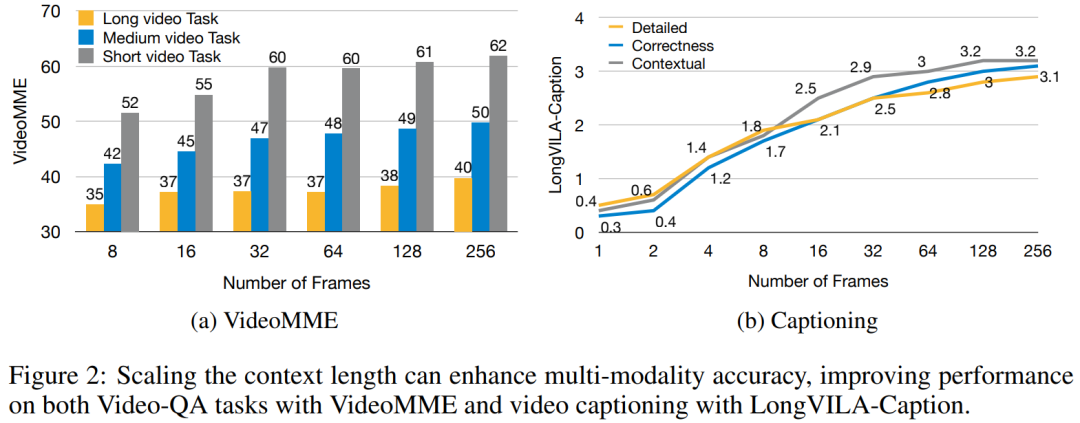 L'image ci-dessous est un exemple de la technologie LongVILA lors du traitement de longs sous-titres vidéo : Au début des sous-titres, le modèle de base à 8 images ne décrit qu'une image statique et deux voitures. En comparaison, 256 images de LongVILA représentent une voiture sur la neige, avec des vues avant, arrière et latérales du véhicule. En termes de détails, le LongVILA à 256 images représente également des gros plans du bouton d'allumage, du levier de vitesses et du combiné d'instruments, qui manquent sur le modèle de base à 8 images. Parallélisme de séquences multimodales La formation de modèles de langage visuel (VLM) à contexte long crée des besoins de mémoire importants. Par exemple, dans la longue formation vidéo de l'étape 5 de la figure 1 ci-dessous, une seule séquence contient 200 000 jetons qui génèrent 1 024 images vidéo, ce qui dépasse la capacité de mémoire d'un seul GPU. Les chercheurs ont développé un système personnalisé basé sur le parallélisme de séquence. Le parallélisme séquentiel est une technique couramment utilisée dans les systèmes de modèles de base actuels pour optimiser la formation LLM en mode texte uniquement. Cependant, les chercheurs ont constaté que les systèmes existants ne sont ni suffisamment efficaces ni suffisamment évolutifs pour gérer les charges de travail VLM à long contexte.Après avoir identifié les limites des systèmes existants, les chercheurs ont conclu qu'une approche parallèle de séquence multimodale idéale devrait donner la priorité à l'efficacité et à l'évolutivité en abordant l'hétérogénéité modale et du réseau, et que l'évolutivité ne devrait pas être limitée par le nombre de têtes d'attention. Flux de travail MM-SP. Pour relever le défi de l’hétérogénéité modale, les chercheurs proposent une stratégie de partitionnement en deux étapes pour optimiser la charge de travail informatique lors des étapes de codage d’images et de modélisation du langage. Comme le montre la figure 4 ci-dessous, la première étape distribue d'abord uniformément les images (telles que les images vidéo) entre les appareils du groupe de processus parallèles séquentiels pour obtenir un équilibrage de charge pendant l'étape d'encodage des images. Dans la deuxième étape, les chercheurs regroupent les entrées visuelles et textuelles globales pour le partitionnement au niveau des jetons. Parallélisme d'attention 2D. Afin de résoudre l’hétérogénéité des réseaux et d’atteindre l’évolutivité, les chercheurs combinent les avantages du parallélisme des séquences en anneau et du parallélisme des séquences d’Ulysse. Plus précisément, ils considèrent le parallélisme entre les dimensions de séquence ou les dimensions de la tête d'attention comme du "1D SP". La méthode évolue grâce à un calcul parallèle sur les têtes d'attention et les dimensions de la séquence, convertissant un SP 1D en une grille 2D composée de groupes indépendants de processus Ring (P2P) et Ulysses (A2A). Comme le montre le côté gauche de la figure 3 ci-dessous, afin d'obtenir un parallélisme de séquence de 8 degrés sur 2 nœuds, le chercheur a utilisé 2D-SP pour construire une grille de communication 4×2. De plus, dans la figure 5 ci-dessous, pour expliquer davantage comment ZIGZAG-RINGATTN équilibre les calculs et comment fonctionne le mécanisme d'attention 2D, les chercheurs expliquent le plan de calcul de l'attention en utilisant différentes méthodes. Par rapport à la stratégie parallèle de pipeline native de HuggingFace, le mode d'inférence de cet article est plus efficace car tous les appareils participent au calcul en même temps, accélérant ainsi le processus proportionnellement au nombre de machines, comme le montre la figure 6 ci-dessous. Dans le même temps, ce mode d'inférence est évolutif, avec une mémoire répartie uniformément entre les appareils afin d'utiliser davantage de machines pour prendre en charge des séquences plus longues. Processus de formation LongVILAComme mentionné ci-dessus, le processus de formation de LongVILA se déroule en 5 étapes. Les tâches principales de chaque étape sont les suivantes : Dans l'étape 1, seul le mappeur multimodal peut être formé et les autres mappeurs sont gelés. Au cours de l'étape 2, les chercheurs ont gelé l'encodeur visuel et formé le LLM et le mappeur multimodal. Au cours de l'étape 3, les chercheurs affinent de manière approfondie le modèle pour les instructions de données courtes après des tâches, telles que l'utilisation d'ensembles de données d'images et de courtes vidéos. Au cours de l'étape 4, les chercheurs utilisent des ensembles de données contenant uniquement du texte pour étendre la longueur du contexte du LLM de manière continue en pré-formation. Au stade 5, les chercheurs utilisent une longue supervision vidéo pour affiner et améliorer la capacité de suivre les instructions. Il convient de noter que tous les paramètres peuvent être entraînés à ce stade. Les chercheurs ont évalué la solution full-stack dans cet article sous deux aspects : le système et la modélisation. Ils présentent d’abord les résultats de formation et d’inférence, illustrant l’efficacité et l’évolutivité d’un système capable de prendre en charge la formation et l’inférence à long contexte. Nous évaluons ensuite les performances du modèle à contexte long sur les tâches de sous-titrage et de suivi d'instructions. Système de formation et d'inférenceCette étude fournit une évaluation quantitative du débit du système de formation, de la latence du système d'inférence et de la longueur maximale de séquence prise en charge. Le tableau 2 montre les résultats de débit. Comparé à ZIGZAG-RINGATTN, ce système atteint une accélération de 2,1 fois à 5,7 fois et les performances sont comparables à celles de DeepSpeed-Ulysses. Une accélération de 3,1x à 4,3x est obtenue par rapport à la mise en œuvre parallèle de séquence d'anneaux plus optimisée dans Megatron-LM CP.Cette étude évalue la longueur de séquence maximale prise en charge par un nombre fixe de GPU en augmentant progressivement la longueur de séquence de 1k à 10k jusqu'à ce qu'une erreur de mémoire insuffisante se produise. Les résultats sont résumés dans la figure 9. Lorsqu'elle est mise à l'échelle sur 256 GPU, notre méthode peut prendre en charge environ 8 fois la longueur du contexte. De plus, le système proposé atteint une mise à l'échelle de la longueur du contexte similaire à ZIGZAG-RINGATTN, prenant en charge plus de 2 millions de longueurs de contexte sur 256 GPU. Le Tableau 3 compare la longueur maximale de séquence prise en charge, et la méthode proposée dans cette étude prend en charge des séquences 2,9 fois plus longues que celles prises en charge par HuggingFace Pipeline. La figure 11 montre les résultats de la longue aiguille vidéo dans l'expérience sur la botte de foin. En revanche, le modèle LongVILA (à droite) affiche des performances améliorées sur une gamme de nombres d'images et de profondeurs. Le tableau 5 répertorie les performances de différents modèles sur le benchmark Video MME, en comparant leur efficacité sur des vidéos courtes, moyennes et longues ainsi que leurs performances globales. LongVILA-8B utilise 256 images et a un score global de 50,5. Les chercheurs ont également mené une étude d'ablation sur l'impact des étapes 3 et 4 dans le tableau 6. Le tableau 7 montre les métriques de performances du modèle LongVILA entraîné et évalué sur différents nombres de frames (8, 128 et 256). À mesure que le nombre d’images augmente, les performances du modèle s’améliorent considérablement. Plus précisément, le score moyen est passé de 2,00 à 3,26, soulignant la capacité du modèle à générer des sous-titres précis et riches sur un nombre d'images plus élevé.
L'image ci-dessous est un exemple de la technologie LongVILA lors du traitement de longs sous-titres vidéo : Au début des sous-titres, le modèle de base à 8 images ne décrit qu'une image statique et deux voitures. En comparaison, 256 images de LongVILA représentent une voiture sur la neige, avec des vues avant, arrière et latérales du véhicule. En termes de détails, le LongVILA à 256 images représente également des gros plans du bouton d'allumage, du levier de vitesses et du combiné d'instruments, qui manquent sur le modèle de base à 8 images. Parallélisme de séquences multimodales La formation de modèles de langage visuel (VLM) à contexte long crée des besoins de mémoire importants. Par exemple, dans la longue formation vidéo de l'étape 5 de la figure 1 ci-dessous, une seule séquence contient 200 000 jetons qui génèrent 1 024 images vidéo, ce qui dépasse la capacité de mémoire d'un seul GPU. Les chercheurs ont développé un système personnalisé basé sur le parallélisme de séquence. Le parallélisme séquentiel est une technique couramment utilisée dans les systèmes de modèles de base actuels pour optimiser la formation LLM en mode texte uniquement. Cependant, les chercheurs ont constaté que les systèmes existants ne sont ni suffisamment efficaces ni suffisamment évolutifs pour gérer les charges de travail VLM à long contexte.Après avoir identifié les limites des systèmes existants, les chercheurs ont conclu qu'une approche parallèle de séquence multimodale idéale devrait donner la priorité à l'efficacité et à l'évolutivité en abordant l'hétérogénéité modale et du réseau, et que l'évolutivité ne devrait pas être limitée par le nombre de têtes d'attention. Flux de travail MM-SP. Pour relever le défi de l’hétérogénéité modale, les chercheurs proposent une stratégie de partitionnement en deux étapes pour optimiser la charge de travail informatique lors des étapes de codage d’images et de modélisation du langage. Comme le montre la figure 4 ci-dessous, la première étape distribue d'abord uniformément les images (telles que les images vidéo) entre les appareils du groupe de processus parallèles séquentiels pour obtenir un équilibrage de charge pendant l'étape d'encodage des images. Dans la deuxième étape, les chercheurs regroupent les entrées visuelles et textuelles globales pour le partitionnement au niveau des jetons. Parallélisme d'attention 2D. Afin de résoudre l’hétérogénéité des réseaux et d’atteindre l’évolutivité, les chercheurs combinent les avantages du parallélisme des séquences en anneau et du parallélisme des séquences d’Ulysse. Plus précisément, ils considèrent le parallélisme entre les dimensions de séquence ou les dimensions de la tête d'attention comme du "1D SP". La méthode évolue grâce à un calcul parallèle sur les têtes d'attention et les dimensions de la séquence, convertissant un SP 1D en une grille 2D composée de groupes indépendants de processus Ring (P2P) et Ulysses (A2A). Comme le montre le côté gauche de la figure 3 ci-dessous, afin d'obtenir un parallélisme de séquence de 8 degrés sur 2 nœuds, le chercheur a utilisé 2D-SP pour construire une grille de communication 4×2. De plus, dans la figure 5 ci-dessous, pour expliquer davantage comment ZIGZAG-RINGATTN équilibre les calculs et comment fonctionne le mécanisme d'attention 2D, les chercheurs expliquent le plan de calcul de l'attention en utilisant différentes méthodes. Par rapport à la stratégie parallèle de pipeline native de HuggingFace, le mode d'inférence de cet article est plus efficace car tous les appareils participent au calcul en même temps, accélérant ainsi le processus proportionnellement au nombre de machines, comme le montre la figure 6 ci-dessous. Dans le même temps, ce mode d'inférence est évolutif, avec une mémoire répartie uniformément entre les appareils afin d'utiliser davantage de machines pour prendre en charge des séquences plus longues. Processus de formation LongVILAComme mentionné ci-dessus, le processus de formation de LongVILA se déroule en 5 étapes. Les tâches principales de chaque étape sont les suivantes : Dans l'étape 1, seul le mappeur multimodal peut être formé et les autres mappeurs sont gelés. Au cours de l'étape 2, les chercheurs ont gelé l'encodeur visuel et formé le LLM et le mappeur multimodal. Au cours de l'étape 3, les chercheurs affinent de manière approfondie le modèle pour les instructions de données courtes après des tâches, telles que l'utilisation d'ensembles de données d'images et de courtes vidéos. Au cours de l'étape 4, les chercheurs utilisent des ensembles de données contenant uniquement du texte pour étendre la longueur du contexte du LLM de manière continue en pré-formation. Au stade 5, les chercheurs utilisent une longue supervision vidéo pour affiner et améliorer la capacité de suivre les instructions. Il convient de noter que tous les paramètres peuvent être entraînés à ce stade. Les chercheurs ont évalué la solution full-stack dans cet article sous deux aspects : le système et la modélisation. Ils présentent d’abord les résultats de formation et d’inférence, illustrant l’efficacité et l’évolutivité d’un système capable de prendre en charge la formation et l’inférence à long contexte. Nous évaluons ensuite les performances du modèle à contexte long sur les tâches de sous-titrage et de suivi d'instructions. Système de formation et d'inférenceCette étude fournit une évaluation quantitative du débit du système de formation, de la latence du système d'inférence et de la longueur maximale de séquence prise en charge. Le tableau 2 montre les résultats de débit. Comparé à ZIGZAG-RINGATTN, ce système atteint une accélération de 2,1 fois à 5,7 fois et les performances sont comparables à celles de DeepSpeed-Ulysses. Une accélération de 3,1x à 4,3x est obtenue par rapport à la mise en œuvre parallèle de séquence d'anneaux plus optimisée dans Megatron-LM CP.Cette étude évalue la longueur de séquence maximale prise en charge par un nombre fixe de GPU en augmentant progressivement la longueur de séquence de 1k à 10k jusqu'à ce qu'une erreur de mémoire insuffisante se produise. Les résultats sont résumés dans la figure 9. Lorsqu'elle est mise à l'échelle sur 256 GPU, notre méthode peut prendre en charge environ 8 fois la longueur du contexte. De plus, le système proposé atteint une mise à l'échelle de la longueur du contexte similaire à ZIGZAG-RINGATTN, prenant en charge plus de 2 millions de longueurs de contexte sur 256 GPU. Le Tableau 3 compare la longueur maximale de séquence prise en charge, et la méthode proposée dans cette étude prend en charge des séquences 2,9 fois plus longues que celles prises en charge par HuggingFace Pipeline. La figure 11 montre les résultats de la longue aiguille vidéo dans l'expérience sur la botte de foin. En revanche, le modèle LongVILA (à droite) affiche des performances améliorées sur une gamme de nombres d'images et de profondeurs. Le tableau 5 répertorie les performances de différents modèles sur le benchmark Video MME, en comparant leur efficacité sur des vidéos courtes, moyennes et longues ainsi que leurs performances globales. LongVILA-8B utilise 256 images et a un score global de 50,5. Les chercheurs ont également mené une étude d'ablation sur l'impact des étapes 3 et 4 dans le tableau 6. Le tableau 7 montre les métriques de performances du modèle LongVILA entraîné et évalué sur différents nombres de frames (8, 128 et 256). À mesure que le nombre d’images augmente, les performances du modèle s’améliorent considérablement. Plus précisément, le score moyen est passé de 2,00 à 3,26, soulignant la capacité du modèle à générer des sous-titres précis et riches sur un nombre d'images plus élevé. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!






 Windows ne peut pas configurer cette connexion sans fil
Windows ne peut pas configurer cette connexion sans fil
 Pourquoi Win11 ne peut-il pas être installé ?
Pourquoi Win11 ne peut-il pas être installé ?
 Méthodes courantes en cours de mathématiques
Méthodes courantes en cours de mathématiques
 Tendance des prix du prix Eth aujourd'hui
Tendance des prix du prix Eth aujourd'hui
 Le but de memcpy en c
Le but de memcpy en c
 Utilisation de base de l'instruction insert
Utilisation de base de l'instruction insert
 La différence entre le compte de service WeChat et le compte officiel
La différence entre le compte de service WeChat et le compte officiel
 Comment changer le logiciel de langue C en chinois
Comment changer le logiciel de langue C en chinois








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



