La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous avez un excellent travail que vous souhaitez partager, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Les auteurs de cet article sont des enseignants et des étudiants de l'Institut d'intelligence multi-agents et incarnée du laboratoire de Pengcheng, de l'Université des sciences du Sud et Technologie et Université Sun Yat-sen L'équipe comprend le professeur Lin Liang (directeur de l'institut, jeune chercheur national émérite, membre de l'IEEE), le professeur Zheng Feng, le professeur Liang Xiaodan, Wang Zhiqiang (Université des sciences et technologies du Sud), Zheng Hao (Université des sciences et technologies du Sud), Nie Yunshuang (CUHK), Xu Wenjun (Pengcheng) ), Ye Hua (Pengcheng), etc. L'équipe du professeur Lin Liang du laboratoire Pengcheng s'engage à construire des plates-formes de base générales telles que des plates-formes de collaboration multi-agents et de formation par simulation et de grands modèles multimodaux incarnés par la collaboration dans le cloud pour répondre aux besoins d'applications majeurs tels que l'Internet industriel et la gouvernance et les services sociaux. . Depuis cette année, l'intelligence incarnée est devenue un domaine brûlant dans le monde universitaire et industriel, avec des produits et des résultats connexes qui émergent sans cesse. Aujourd'hui, l'Institut d'intelligence multi-agents et incorporée du Laboratoire de Pengcheng (ci-après dénommé Institut Pengcheng Embodied), en collaboration avec l'Université des sciences et technologies du Sud et l'Université Sun Yat-sen, a officiellement publié et mis en open source ses dernières réalisations académiques dans le domaine de intelligence incarnée - L'ensemble de données incarnées à grande échelle ARIO (All Robots) In One vise à résoudre les problèmes d'acquisition de données actuellement rencontrés dans le domaine de l'intelligence incarnée. 
Titre de l'article : Tous les robots en un : un nouvel ensemble de données standard et unifié pour les agents incorporés polyvalents et à usage général
Lien de l'article : http://arxiv.org/abs/2408.10899
Page d'accueil du projet : https://imaei.github.io/project_pages/ario/
Lien du site Web du Pengcheng Laboratory Embodiment Institute : https://imaei.github.io/
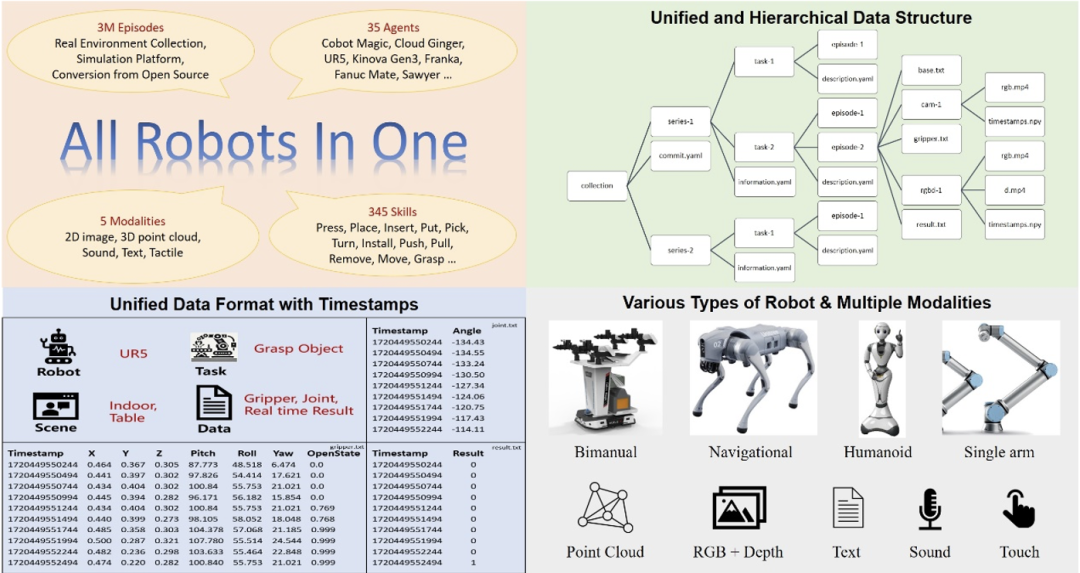
En tant que cerveau du robot incarné, la clé pour améliorer les performances du grand modèle incarné est d'obtenir des big data incarnés de haute qualité. Contrairement aux données textuelles ou images utilisées dans les grands modèles linguistiques ou les grands modèles visuels, les données incorporées ne peuvent pas être obtenues directement à partir du contenu massif d'Internet, mais doivent être collectées via des opérations robotiques réelles ou générées par des plates-formes de simulation avancées. collecte de données incorporées Cela nécessite beaucoup de temps et d'argent, et est difficile à réaliser à grande échelle. Dans le même temps, les ensembles de données open source actuels présentent également de nombreuses lacunes. Comme le montre le tableau ci-dessus, le volume de données de JD ManiData, ManiWAV et RH20T n'est pas important et la plate-forme matérielle du robot utilisée pour DROID. Les données sont relativement uniques. Bien qu'une grande quantité de données ait été obtenue, les modalités des données sensorielles ne sont pas assez riches, et les formats de données entre les sous-ensembles de données ne sont pas uniformes et la qualité est également inégale. beaucoup de temps pour filtrer et traiter les données avant de les utiliser, ce qui rend difficile la satisfaction des besoins de formation efficace et ciblée de modèles intelligents incorporés dans des scénarios complexes. En comparaison, l'ensemble de données ARIO publié cette fois contient des données sensorielles dans 5 modalités : 2D, 3D, texte, toucher et son, couvrant deux grandes catégories : opération et navigation Les tâches comprennent à la fois des données de simulation et des données de scène réelles, et contiennent une variété de matériel robotique, qui est très riche. Bien que l'échelle des données atteigne trois millions, elle garantit également un format unifié des données. Il s'agit actuellement d'un ensemble de données open source qui atteint simultanément une haute qualité, une diversité et une grande échelle dans le domaine de l'intelligence incorporée. Pour l'ensemble de données de l'intelligence incarnée, étant donné que les robots ont de nombreuses formes, telles que monobras, double bras, humanoïde, à quatre pattes, etc., et que les méthodes de perception et de contrôle sont également différentes, certains le sont contrôlés par des angles d'articulation, et certains sont pilotés par les coordonnées du corps ou de la pose finale, de sorte que les données incorporées elles-mêmes sont beaucoup plus complexes que de simples données d'image et de texte, et de nombreux paramètres de contrôle doivent être enregistrés. Et s'il n'y a pas de format unifié, lorsque plusieurs types de données robotiques sont regroupées, beaucoup d'énergie sera dépensée en prétraitement supplémentaire. Par conséquent, l'Institut d'incarnation du laboratoire de Pengcheng a d'abord conçu un ensemble de normes de format pour les mégadonnées incorporées. Cette norme peut enregistrer diverses formes de paramètres de contrôle du robot, a une structure claire de forme d'organisation des données et peut également l'être. compatible avec des capteurs avec différentes fréquences d'images et enregistre les horodatages correspondants pour répondre aux exigences précises du grand modèle intelligent incorporé pour la détection et le contrôle du timing. La figure ci-dessous montre la conception globale de l'ensemble de données ARIO. O Figure 1. Conception de l'ensemble de données ARIO
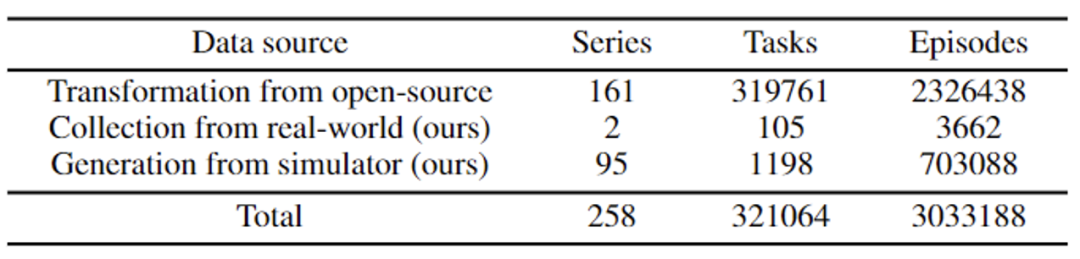
Ensemble de données Ario, avec un total de 258 séquences de scènes, 32 1064 tâches et 3,03 millions d'échantillons. Les données d'ARIO proviennent de trois sources principales. L'une est une collecte de personnes réelles en organisant des scènes et des tâches dans des environnements réels ; l'autre est basée sur des moteurs de simulation tels que MuJoCo et Habitat
pour concevoir des scènes virtuelles et des modèles d'objets et piloter le tout. modèle de robot via le moteur de simulation.La troisième étape consiste à analyser et à traiter un par un les ensembles de données incorporés actuellement open source et à les convertir en données conformes à la norme de format ARIO. Ce qui suit montre la composition spécifique de l'ensemble de données ARIO, ainsi que les processus et exemples provenant des 3 sources.
Il est difficile d'obtenir des données robotiques de haute qualité, mais elles sont incroyablement précieuses. Basé sur le robot à double bras maître-esclave Cobot Magic, le laboratoire Pengcheng a conçu plus de 30 tâches, dont 3 niveaux de difficulté de fonctionnement : simple - moyen - difficile, et en ajoutant des objets interférents, en changeant aléatoirement les positions des objets et des robots, et changer la disposition L'environnement et d'autres méthodes ont été utilisés pour augmenter la diversité des échantillons, et finalement plus de 3 000 données de trajectoire contenant 3 caméras RGBD ont été obtenues. Des exemples de collecte pour différentes tâches et des vidéos de collecte sont présentés ci-dessous.
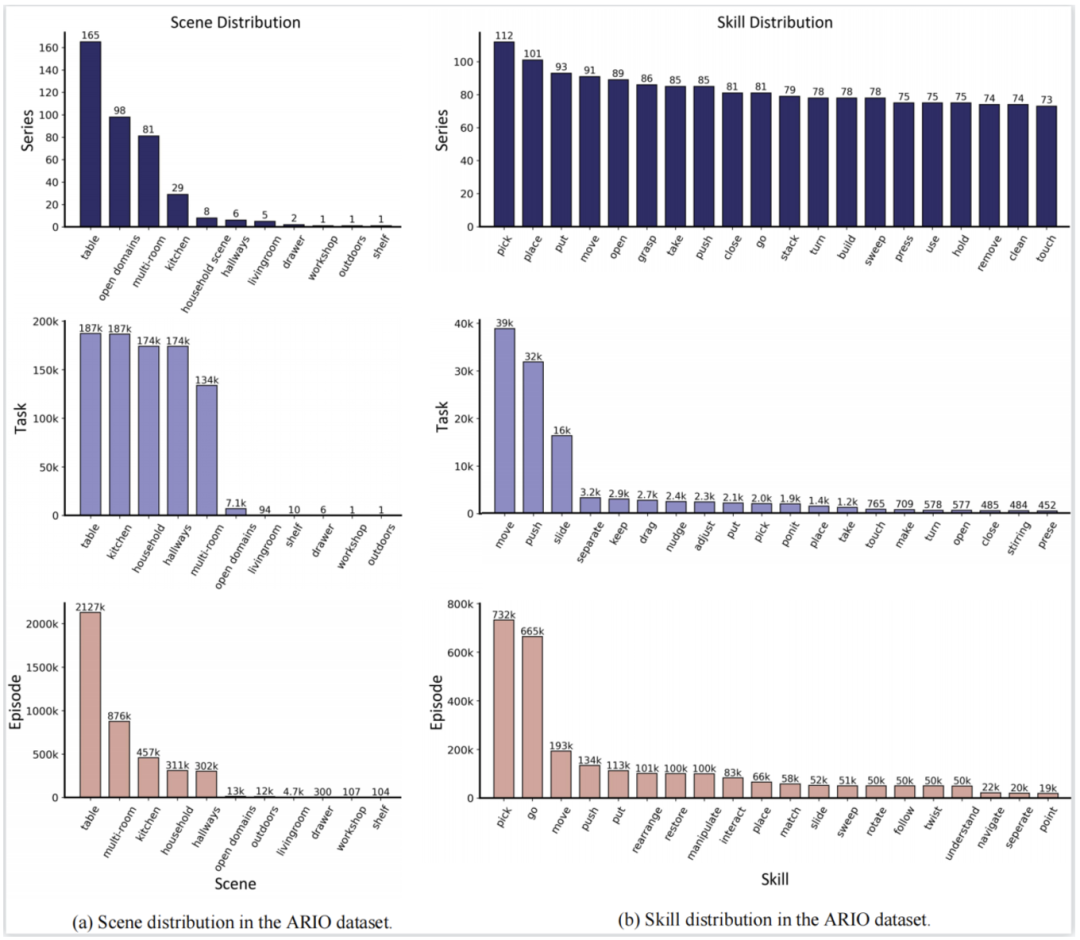
O Figure 3. Exemple de collecte de données du robot Ario Real Vidéo d'exemple de données de collecte de Kimneys robotiques COBOT MAGIC Exemple d'acquisition de données de simulation basée sur MUJOCO Vidéo Exemple de vidéo de génération de données de simulation basée sur la plateforme Vidéo d'exemple de données convertie à partir du RH20T grâce à ARIO La conception au format unifié des données facilite l'analyse statistique de leur composition. La figure ci-dessous montre les statistiques de répartition des scènes ARIO (figure a) et des compétences (figure b) des trois niveaux de série, de tâche et d'épisode. On peut constater que la plupart des données incorporées se concentrent actuellement sur des scènes et des compétences dans la vie intérieure et les environnements domestiques. En plus des scénarios et des compétences, les données ARIO peuvent également effectuer des analyses statistiques du point de vue du robot lui-même et découvrir certaines des tendances de développement actuelles de l'industrie de la robotique. L'ensemble de données ARIO fournit des données statistiques sur la forme du robot, les objets en mouvement, les variables de contrôle physique, les types de capteurs et les emplacements d'installation, le nombre de capteurs visuels, la proportion de méthodes de contrôle, la proportion de méthodes de collecte de données et la proportion du nombre. de degrés de liberté du bras robotique, correspondant aux figures a-i ci-dessous. Prenons l'exemple de la figure a ci-dessous. Nous pouvons constater que la plupart des données actuelles proviennent de robots à un seul bras. Il existe très peu de données open source pour les robots humanoïdes, et elles proviennent principalement de collections réelles. et génération de simulation du laboratoire Pengcheng.
Article original et page d'accueil du projet.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!





 Exemple d'acquisition de données de simulation basée sur MUJOCO Vidéo
Exemple d'acquisition de données de simulation basée sur MUJOCO Vidéo  Exemple de vidéo de génération de données de simulation basée sur la plateforme
Exemple de vidéo de génération de données de simulation basée sur la plateforme  Vidéo d'exemple de données convertie à partir du RH20T
Vidéo d'exemple de données convertie à partir du RH20T  grâce à ARIO La conception au format unifié des données facilite l'analyse statistique de leur composition. La figure ci-dessous montre les statistiques de répartition des scènes ARIO (figure a) et des compétences (figure b) des trois niveaux de série, de tâche et d'épisode. On peut constater que la plupart des données incorporées se concentrent actuellement sur des scènes et des compétences dans la vie intérieure et les environnements domestiques.
grâce à ARIO La conception au format unifié des données facilite l'analyse statistique de leur composition. La figure ci-dessous montre les statistiques de répartition des scènes ARIO (figure a) et des compétences (figure b) des trois niveaux de série, de tâche et d'épisode. On peut constater que la plupart des données incorporées se concentrent actuellement sur des scènes et des compétences dans la vie intérieure et les environnements domestiques. 
 Les performances des micro-ordinateurs dépendent principalement de
Les performances des micro-ordinateurs dépendent principalement de
 moyens visibles
moyens visibles
 Où est le bouton d'impression ?
Où est le bouton d'impression ?
 Échec de la routine d'initialisation de la bibliothèque de liens dynamiques
Échec de la routine d'initialisation de la bibliothèque de liens dynamiques
 Quel logiciel est premier
Quel logiciel est premier
 Comment faire défiler les images en ppt
Comment faire défiler les images en ppt
 nième enfant
nième enfant
 Pourquoi les mots après avoir tapé le mot disparaissent-ils ?
Pourquoi les mots après avoir tapé le mot disparaissent-ils ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



