

Dify est une plateforme SaaS open source permettant de créer des flux de travail LLM en ligne. J'utilise l'API pour créer une expérience d'IA conversationnelle sur mon application. J'avais du mal à obtenir des flux TTS comme réponse API et à les lire. Ici, je montre comment traiter les flux audio et les lire correctement.
J'utilise le point de terminaison de l'API https://api.dify.ai/v1/chat-messages pour le chat textuel. Il renvoie les données audio dans le même flux que la réponse textuelle si nous avons activé la fonctionnalité Text to Speech dans nos applications Dify.
Appuyez sur le bouton AJOUTER UNE FONCTION et ajoutez la fonction Texte à la parole.
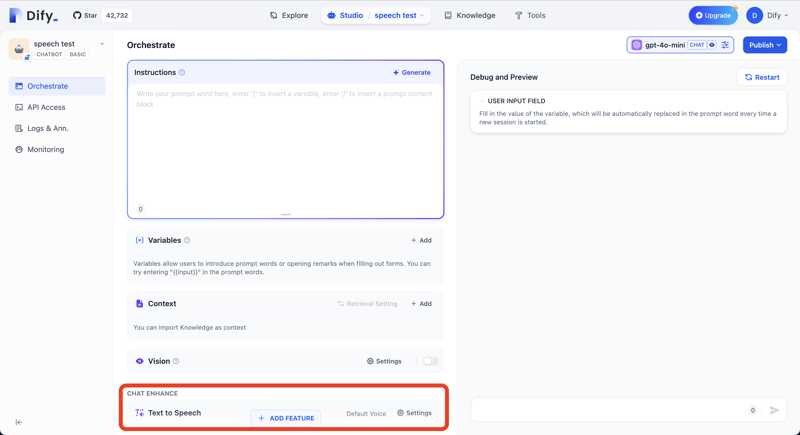
Vous pouvez vérifier la réponse de l'API avec la commande curl suivante.
curl -X POST 'https://api.dify.ai/v1/chat-messages' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": []
}'
Je fais une démonstration en TypeScript / JavaScript mais vous pouvez appliquer la même logique à votre langage de programmation.
Tout d'abord, comprenons quel type de données Dify utilise pour les flux.
Dify utilise le format de données texte suivant. C'est comme les lignes JSON mais ce n'est pas exactement la même chose.
data: {"event": "workflow_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "50100b30-e458-4632-ad7d-8dd383823376", "workflow_id": "debdb4fa-dcab-4233-9413-fd6d17b9e36a", "sequence_number": 334, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123"}, "created_at": 1724478014}}
data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": null, "created_at": 1724478013, "extras": {}}}
data: {"event": "node_finished", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "process_data": null, "outputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "status": "succeeded", "error": null, "elapsed_time": 0.001423838548362255, "execution_metadata": null, "created_at": 1724478013, "finished_at": 1724478013, "files": []}}
data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "89ed58ab-6157-499b-81b2-92b1336969a5", "node_id": "llm", "node_type": "llm", "title": "LLM", "index": 2, "predecessor_node_id": "1721365917005", "inputs": null, "created_at": 1724478013, "extras": {}}}
...
Dans la réponse, Dify envoie la réponse textuelle et les données audio.
Exemple de ligne de réponse de texte
data: {"event": "message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "answer": "MP"}
Exemple de ligne de données audio
data: {"event": "tts_message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "audio": "//PkxABhvDm0DVp4ACUUfvWc1CFlh0tR9Oh7LxzHRsGBuGx155x3JqTJiwKKZf8wIcxpMzJU0h4zhgyQwwwIsgWQMAALQMkanBTjfCPgZwFsDOGGIYJoJoJoJoPQPQLYEgAOwM4SMXMW8TcNWGrEPEME0HoIQTg0DQNA0C5k7IOLeJuDnDVi5nWyJwgghAagQwTQQgJAGrDVibiFhqw1YR8HOEjBUA5AcgagQwTQTQQgJAAtgLYKsQ8hZc0PV7OrE4SgQgFIAsAQAwA6H0Uv4t4m4m49Yt4uYOQHIBkAyAqAkAuB0Mm6UeKxDGRrIODkByBqBNBCA1ARwHIEgBVg5wkY41W2GgdEVDFBNe+HicQw0ydk7HrHrIWXM62d48ePNfCkNATcTcNWGrCRhqxDxcwMYBwBkByCGC4EILgoJTQUDeW8W8TcTchZ1qBWIYchOBbBCA1AhgSMJGGrFzLmh6fL+LeBkAyAZAcgSAXAhB0Kxnj4YDkJwXA6FAzwj8IIJoJoPQXA6EPOcg4R8FOBnCRljRAwlwoh4EUwLhFTCVA+MR0R8wyxOhgAwwDgJjBUABMM0hMxBgnTPtMrMBEEcwJQCzIXIdMZMG821DmjDKHJAwLDKHRMQsJkwbwVRoFs//PkxEx5dDnwAZ7wANHgEUFJHGCUCQp3LWCQQYGAATI5QzwHBJF4UFktpfATT2l0goAGNADLOU64HAMCQCK50szABAIkDS2/j8gl6l6Di7QgBEiAfMEADBnyZBgeAWCMK4xvBbhoRZj1M+ktsNMTrMNcHEwHQEzAjAHMGQAQwRQZTBHALMGMDkzhh2jGhLtMgsMMwfhOzCnGLMMcKgwOw8pqHMoGtvdDzos0AIAiXIsBAmGsRFtYcBABmB0AUYjQfhhDAfjoCrETAGArMOAJ4iAAMCMFkwXwh5fffuhpYMhyP2bl3MVAJQrSYQDsna7G2+fx/GvyAwUQbTAdAFCAHVKyIAduTXHZZXDjNS57/VeVJ5+JBJ+0kATkCSells8/NBt/2/5Dj1s+chDBYSINutNS9FQwDwBWHjgASKRgAAJOyYC4Ao0CMNAKBgB6KK1hYBkAAHROM9mLsknb8avTcB0MerV6jl7llE70egOerRh9WcP/FoHqtVsO/In2f+G2tsdnH+L/KSSvBQB4OATam27Yi4jiBgBFOpq15bTQU6k1G4LoWo1mMAwDQwlBEzEnKsMkA7c5JYuTOzK2MvAbEysSPTM+dOOn1XEzGgIzXzmPODVvs1cyNTJxQ9MsAWwy//PkxDlz7DIMAd7gAek5EwnjcjX9QVN1N0czFyijQKOmMi4IYw8RvzFvCHMHYBQwdQlTRxVNvm8ycGjLYlMTAQ=="}
Nous pouvons distinguer les lignes JSON de données audio en vérifiant la propriété de l'événement. Audio JSON a tts_message comme valeur. Le binaire audio mp3 est stocké dans la propriété audio des JSON au format base64.
Le premier problème que nous rencontrons lorsque nous lisons de l'audio TTS en temps réel est que les lignes JSON sont divisées en paquets et que chaque paquet ne contient pas de données JSON valides telles quelles.
Exemple de paquet coupé en deux
euimRrhsPMZiMAl+BqSZMDmIkQEcDb/8+TEtHm8MhwA3p/p8dA0CCpAxwMMPABoYMIWwUDG6BRmiYZg2G6gRidGanOm5i5iaIYmfkH8Z/FmEopqJGZKXihYEIRxCKYKtlQuMvPjPQIwUVFFECDRnRCYEimGmA6cji41yQMImMEmhaHrVKpCxo2OYx6Q5RcJKAKkah4X6MckHEqdwKgHGHltDUjCy46HMgTCpwodAM8KijREwSSEk5hB4gRGFfC0ouYoeDiYtNREDgKQsTT6EI4egmMMBxpQZmoUJmAAg6YPDmQISgSECAZQOLfAUEQAG/dgxAVkxfFHGorEHB4CS+Yugwk2gq8akIwMsZIuIzUSrCAGm1iBnoYA8lcoYSlaIJ5RjCblwbsh8sB3skA7Gcx3zmSOKnXNJO6ObKklhuYjlVL1dSMhgwVJtFzMeWFufNKy3ODmCExBTUUzLjEwMKqqqqqqqqqqqqqqqqqqCIEWFIAA4DAWKkMDDIBA4lBqGDdmZwzAkGJFoYiwEV0IQOQHg1AATJiUM6F0z2fDE6PMvlc6DhTMJ+MNH4xWwzBwKMMCgHAwwUFQwjGEgMgovgIBMIMECYxYSDKAwSoMOBC4Ez682pEZIB8kBuiawZEaSnFAjIEwSFRxGUJIXMGRMmfNCPApcKL/8+TEiVdEKlJm5pM9gz0MyScwo04BgqjEFh489MGKVw=="}
Le paquet commence au milieu d'une ligne JSON. Nous devons combiner plusieurs paquets pour obtenir des lignes JSON valides.
Le deuxième problème est que le bloc de données audio dans un JSON n'est pas une donnée audio valide. Les données sont coupées au milieu d'images mp3.
Pour gérer les données divisées en JSON et mp3, nous devons procéder de manière intelligente. Le déroulement du processus est le suivant :
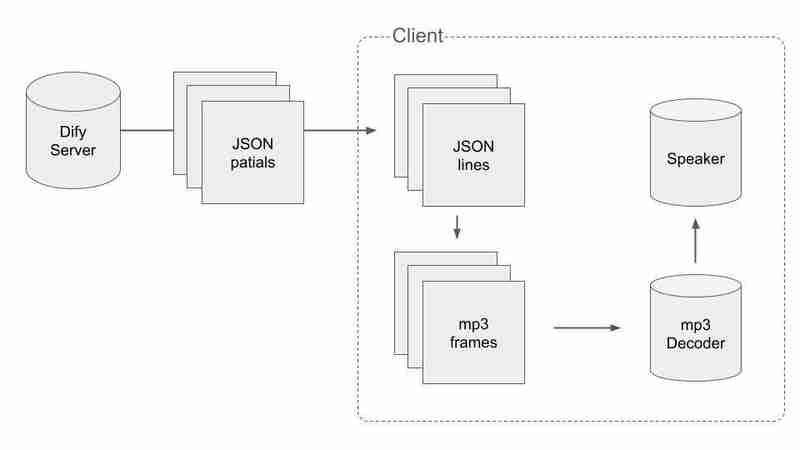
Tout d'abord, nous devons obtenir des données JSON valides et les diviser en JSON lors de la réception des paquets. Lorsque nous obtenons un paquet avec n à la fin, nous pouvons dire que la concaténation des paquets reçus jusqu'à présent n'est pas coupée au milieu. Le pseudo code est comme ça.
let packets = []
stream.on('data', (bytes) => {
const text = bytes.toString()
packets.push(text)
if (text.endsWith('\n')) {
// Extract audio data from the packets.
const audioChunks = extractAudioChunks(packets.join(''))
// Clear the packet array
packets = []
}
})
Deuxièmement, nous devons diviser les morceaux audio en images mp3. Nous concaténons les morceaux audio dans un binaire et y trouvons chaque image mp3.
const mp3Frames = []
const binaryToProcess = Buffer.concat([...audioChunks])
let frameStartIndex = 0
for (let i = 0; i < binaryToProcess.length; i += 1) {
const currentByte = binaryToProcess[i]
const nextByte = binaryToProcess[i + 1]
// MP3 frame header always starts with eleven 1 bits. Checking 2 bytes.
// It is a beginning of mp3 frame if current byte is 0xff and the beginning of the next byte is 111.
// MP3 Spacification
// http://www.mp3-tech.org/programmer/frame_header.html
if (currentByte === 0xff && (nextByte & 0b11100000) === 0b11100000) {
mp3Frames.push(binaryToProcess.subarray(frameStartIndex, i))
frameStartIndex = i
}
}
Ce n'est pas la mise en œuvre complète du fractionnement en images mp3. Dans le processus réel, nous devons considérer les cas où nous avons des octets restants lorsque nous extrayons des images mp3 du binaire audio et utilisons le reste comme début des octets audio dans l'itération suivante. Veuillez consulter mon dépôt Github pour la mise en œuvre complète.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Windows ne peut pas se connecter à la solution wifi
Windows ne peut pas se connecter à la solution wifi
 Comment vérifier l'adresse du serveur FTP
Comment vérifier l'adresse du serveur FTP
 Que faire si la désérialisation php échoue
Que faire si la désérialisation php échoue
 Plateforme formelle de trading de devises numériques
Plateforme formelle de trading de devises numériques
 jquery valider
jquery valider
 Quelles sont les différences entre le pool de threads Spring et le pool de threads JDK ?
Quelles sont les différences entre le pool de threads Spring et le pool de threads JDK ?
 Le serveur est introuvable sur la solution informatique
Le serveur est introuvable sur la solution informatique
 Comment télécharger Binance
Comment télécharger Binance








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



