

Publié à l'origine sur le blog Streamlit par Liz Acosta
Vous vous souvenez à quel point c'était cool de jouer avec un générateur d'images IA pour la première fois ? Ces vingt millions de doigts et ces images cauchemardesques de mangeurs de spaghettis étaient plus qu'amusantes, elles révélaient par inadvertance que oups ! Les modèles d’IA sont aussi intelligents que nous. Comme nous, ils ont aussi du mal à dessiner les mains.

Les modèles d’IA sont rapidement devenus plus sophistiqués, mais ils sont désormais très nombreux. Et – encore une fois – comme nous, certains d’entre eux sont meilleurs que d’autres dans certaines tâches. Prenez la génération de texte, par exemple. Même si Llama, Gemma et Mistral sont tous des LLM, certains d'entre eux sont meilleurs dans la génération de code tandis que d'autres sont meilleurs dans le brainstorming, le codage ou l'écriture créative. Ils offrent différents avantages en fonction de l'invite, il peut donc être judicieux d'inclure plusieurs modèles dans votre application d'IA.
Mais comment intégrer tous ces modèles dans votre application sans dupliquer le code ? Comment rendre votre utilisation de l’IA plus modulaire et donc plus facile à maintenir et à faire évoluer ? C'est là qu'une API peut offrir un ensemble standardisé d'instructions pour communiquer entre différentes technologies.
Dans cet article de blog, nous verrons comment utiliser Replicate avec Streamlit pour créer une application qui vous permet de configurer et d'inviter différents LLM avec un seul appel d'API. Et ne vous inquiétez pas – quand je dis « application », je ne parle pas de devoir démarrer tout un serveur Flask, de configurer fastidieusement vos itinéraires ou de vous soucier du CSS. Streamlit a ce qu'il vous faut ?
Lisez la suite pour apprendre :
Vous n’avez pas envie de lire ? Voici d'autres façons d'explorer cette démo :
Replicate est une plate-forme qui permet aux développeurs de déployer, d'affiner et d'accéder à des modèles d'IA open source via une CLI, une API ou un SDK. La plate-forme facilite l'intégration par programmation des capacités d'IA dans les applications logicielles.
Lorsqu'ils sont utilisés ensemble, Replicate vous permet de développer des applications multimodales capables d'accepter des entrées et de générer des sorties dans différents formats, qu'il s'agisse de texte, d'image, de parole ou de vidéo.
Streamlit est un framework Python open source permettant de créer des applications hautement interactives, en seulement quelques lignes de code. Streamlit s'intègre à tous les derniers outils d'IA générative, tels que n'importe quel LLM, base de données vectorielles ou divers frameworks d'IA comme LangChain, LlamaIndex ou Weights & Biases. Les éléments de chat de Streamlit facilitent particulièrement l'interaction avec l'IA afin que vous puissiez créer des chatbots qui « parlent à vos données ».
Combiné à une plateforme comme Replicate, Streamlit vous permet de créer des applications d'IA génératives sans aucune surcharge de conception d'application.
? Pour en savoir plus sur la manière dont Streamlit vous incite à progresser, consultez cet article de blog.
Pour en savoir plus sur Streamlit, consultez le guide 101.
Mais ne me croyez pas sur parole. Essayez l'application vous-même ou regardez une vidéo et voyez ce que vous en pensez.
Dans cette démo, vous lancerez une application de chatbot Streamlit avec Replicate. L'application utilise une seule API pour accéder à trois LLM différents et ajuster des paramètres tels que la température et le top-p. Ces paramètres influencent le caractère aléatoire et la diversité du texte généré par l'IA, ainsi que la méthode par laquelle les jetons sont sélectionnés.
? Qu'est-ce que la température du modèle ? La température contrôle la façon dont le modèle sélectionne les jetons. Une température plus basse rend le modèle plus conservateur, privilégiant les mots courants et « sûrs ». À l'inverse, une température plus élevée encourage le modèle à prendre plus de risques en sélectionnant des jetons moins probables, ce qui entraîne des résultats plus créatifs.
? Qu'est-ce que top-p ? Également connu sous le nom d'« échantillonnage de noyau » : il s'agit d'une autre méthode d'ajustement du caractère aléatoire. Cela fonctionne en considérant un ensemble plus large de jetons à mesure que la valeur top-p augmente. Une valeur top-p plus élevée conduit à l'échantillonnage d'une gamme plus diversifiée de jetons, produisant des sorties plus variées.
? Pour en savoir plus sur les clés API, consultez l'article de blog ici.
Configuration locale
Configuration des espaces de codes GitHub
À partir du dépôt Cookbook sur GitHub, créez un nouvel espace de code en sélectionnant l'option Codespaces à partir du bouton Code
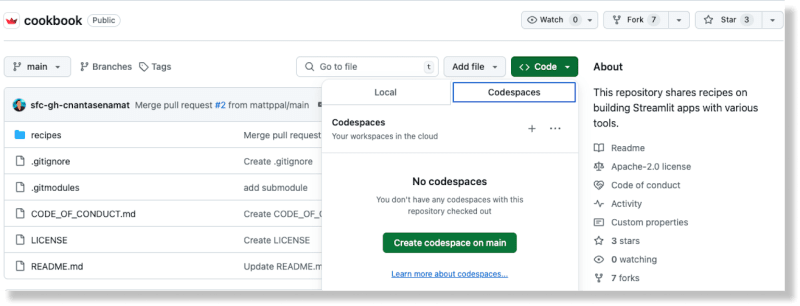
Une fois l'espace de code généré, ajoutez votre clé API Replicate au fichier Recipes/replicate/.streamlit/secrets_template.toml
Mettez à jour le nom de fichier de secrets_template.toml vers secrets.toml
(Pour en savoir plus sur la gestion des secrets dans Streamlit, reportez-vous à la documentation ici.)
À partir du répertoire racine du livre de recettes, changez de répertoire dans la recette Répliquer : cd recettes/replicate
Installez les dépendances : pip install -r conditions.txt
Ajoutez le code suivant au fichier :
import replicate
import toml
import os
# Read the secrets from the secrets.toml file
with open(".streamlit/secrets.toml", "r") as f:
secrets = toml.load(f)
# Create an environment variable for the Replicate API token
os.environ['REPLICATE_API_TOKEN'] = secrets["REPLICATE_API_TOKEN"]
# Run a model
for event in replicate.stream("meta/meta-llama-3-8b",
input={"prompt": "What is Streamlit?"},):
print(str(event), end="")
Exécutez le script : python replique_hello_world.py
Vous devriez voir une impression du texte généré par le modèle.
Pour en savoir plus sur les modèles Replicate et leur fonctionnement, vous pouvez vous référer à leur documentation ici. À la base, un « modèle » de réplication fait référence à un programme logiciel formé, packagé et publié qui accepte les entrées et renvoie les sorties.
Dans ce cas particulier, le modèle est meta/meta-llama-3-8b et l'entrée est "prompt": "Qu'est-ce que Streamlit ?". Lorsque vous exécutez le script, un appel est effectué au point de terminaison Replicate et le texte imprimé est la sortie renvoyée par le modèle via Replicate.
Pour exécuter l'application de démonstration, utilisez la CLI Streamlit : streamlit run streamlit_app.py.
L'exécution de cette commande déploie l'application sur un port sur localhost. Lorsque vous accédez à cet emplacement, vous devriez voir une application Streamlit en cours d'exécution.
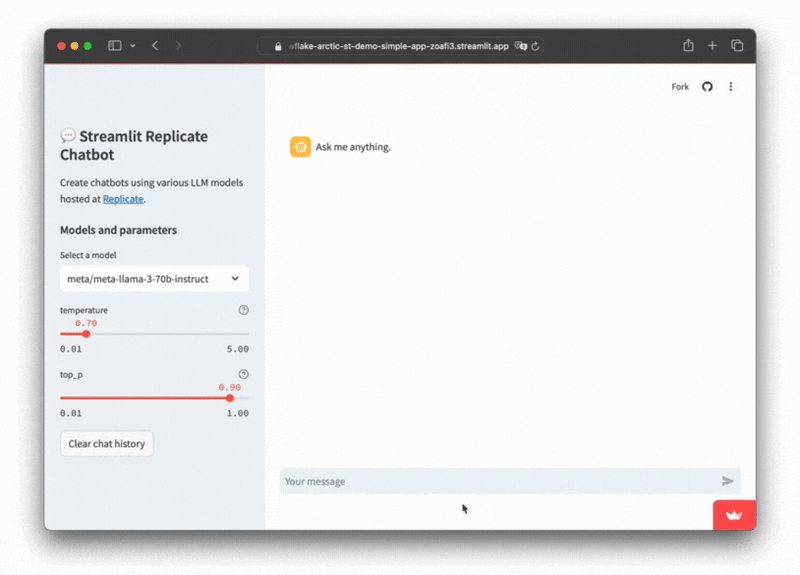
Vous pouvez utiliser cette application pour demander différents LLM via Répliquer et produire du texte génératif en fonction des configurations que vous fournissez.
L'utilisation de Replicate signifie que vous pouvez lancer plusieurs LLM open source avec une seule API, ce qui contribue à simplifier l'intégration de l'IA dans les flux logiciels modernes.
Ceci est accompli dans le bloc de code suivant :
for event in replicate.stream(model,
input={"prompt": prompt_str,
"prompt_template": r"{prompt}",
"temperature": temperature,
"top_p": top_p,}):
yield str(event)
Les configurations du modèle, de la température et du top p sont fournies par l'utilisateur via les widgets de saisie de Streamlit. Les éléments de chat de Streamlit facilitent l'intégration des fonctionnalités de chatbot dans votre application. Le meilleur, c'est que vous n'avez pas besoin de connaître JavaScript ou CSS pour implémenter et styliser ces composants – Streamlit fournit tout cela dès la sortie de la boîte.
Replicate fournit un point de terminaison API pour rechercher des modèles publics. Vous pouvez également explorer les modèles présentés et les cas d’utilisation sur leur site Web. Cela facilite la recherche du modèle adapté à vos besoins spécifiques.
Différents modèles ont des caractéristiques de performance différentes. Utilisez le modèle approprié en fonction de vos besoins de précision et de rapidité.
Les données de sortie de Replicate ne sont disponibles que pendant une heure. Utilisez des webhooks pour enregistrer les données sur votre propre stockage. Vous pouvez également configurer des webhooks pour gérer les réponses asynchrones des modèles. Ceci est crucial pour créer des applications évolutives.
Tirez parti du streaming lorsque cela est possible. Certains modèles prennent en charge le streaming, vous permettant d'obtenir des résultats partiels au fur et à mesure de leur génération. C'est idéal pour les applications en temps réel.
L'utilisation d'URL d'images offre des performances améliorées par rapport à l'utilisation d'images téléchargées codées en base 64.
Avec Streamlit, des mois et des mois de travail de conception d'applications sont rationalisés en quelques lignes de Python seulement. C’est le cadre idéal pour présenter vos dernières inventions en matière d’IA.
Lancez-vous rapidement avec d'autres recettes d'IA dans le livre de recettes Streamlit. (Et n'oubliez pas de nous montrer ce que vous construisez sur le forum !)
Bon streamlit-ing ! ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Qu'est-ce qu'un lecteur optique
Qu'est-ce qu'un lecteur optique
 Méthode de définition de l'espace HTML
Méthode de définition de l'espace HTML
 Comment configurer la redirection de nom de domaine
Comment configurer la redirection de nom de domaine
 Qu'est-ce qui est mis en évidence dans jquery
Qu'est-ce qui est mis en évidence dans jquery
 Quelle est la raison pour laquelle le réseau ne peut pas être connecté ?
Quelle est la raison pour laquelle le réseau ne peut pas être connecté ?
 Comment configurer la passerelle par défaut
Comment configurer la passerelle par défaut
 Utilisation de la fonction d'écriture
Utilisation de la fonction d'écriture
 git pull extrait le code
git pull extrait le code
 Les performances des micro-ordinateurs dépendent principalement de
Les performances des micro-ordinateurs dépendent principalement de








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



