

Il est difficile d'affirmer qu'Atlassian JIRA est l'une des solutions de suivi des problèmes et de gestion de projet les plus populaires. Vous pouvez l'aimer, vous pouvez le détester, mais si vous avez été embauché en tant qu'ingénieur logiciel pour une entreprise, il y a de fortes chances de rencontrer JIRA.
Si le projet sur lequel vous travaillez est très actif, il peut y avoir des milliers de tickets JIRA de différents types. Si vous dirigez une équipe d'ingénieurs, vous pouvez être intéressé par des outils analytiques qui peuvent vous aider à comprendre ce qui se passe dans le projet à partir des données stockées dans JIRA. JIRA intègre certaines fonctionnalités de reporting, ainsi que des plugins tiers. Mais la plupart d’entre eux sont assez basiques. Par exemple, il est difficile de trouver des outils de « prévision » assez flexibles.
Plus le projet est volumineux, moins vous êtes satisfait des outils de reporting intégrés. À un moment donné, vous finirez par utiliser une API pour extraire, manipuler et visualiser les données. Au cours des 15 dernières années d'utilisation de JIRA, j'ai vu des dizaines de scripts et services de ce type dans divers langages de programmation autour de ce domaine.
De nombreuses tâches quotidiennes peuvent nécessiter une analyse de données ponctuelle, donc rédiger des services à chaque fois n'est pas rentable. Vous pouvez traiter JIRA comme une source de données et utiliser une ceinture d'outils d'analyse de données typique. Par exemple, vous pouvez utiliser Jupyter, récupérer la liste des bogues récents du projet, préparer une liste de « fonctionnalités » (attributs précieux pour l'analyse), utiliser des pandas pour calculer les statistiques et essayer de prévoir les tendances à l'aide de scikit-learn. Dans cet article, je voudrais expliquer comment procéder.
Ici, nous parlerons de la version cloud de JIRA. Mais si vous utilisez une version auto-hébergée, les concepts principaux sont quasiment les mêmes.
Tout d'abord, nous devons créer une clé secrète pour accéder à JIRA via l'API REST. Pour cela, rendez-vous dans la gestion des profils - https://id.atlassian.com/manage-profile/profile-and-visibility Si vous sélectionnez l'onglet "Sécurité", vous trouverez le lien "Créer et gérer les tokens API" :
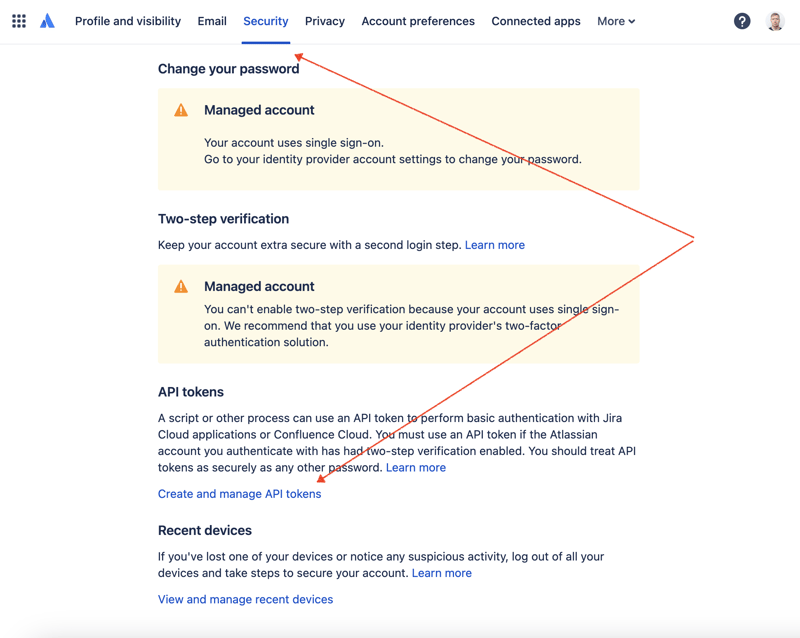
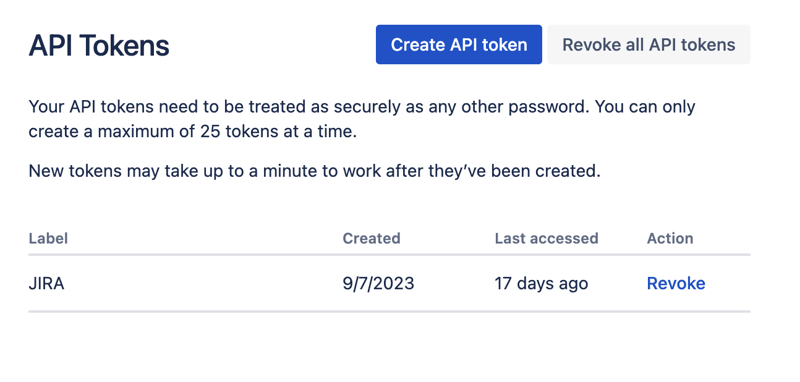
Créez un nouveau jeton API ici et stockez-le en toute sécurité. Nous utiliserons ce jeton plus tard.
L'un des moyens les plus pratiques de jouer avec des ensembles de données est d'utiliser Jupyter. Si vous n'êtes pas familier avec cet outil, ne vous inquiétez pas. Je vais montrer comment l'utiliser pour résoudre notre problème. Pour les expériences locales, j'aime utiliser DataSpell de JetBrains, mais il existe des services disponibles en ligne et gratuitement. L'un des services les plus connus des data scientists est Kaggle. Cependant, leurs notebooks ne vous permettent pas d'établir des connexions externes pour accéder à JIRA via l'API. Un autre service très populaire est Colab de Google. Il vous permet d'établir des connexions à distance et d'installer des modules Python supplémentaires.
JIRA dispose d'une API REST assez simple à utiliser. Vous pouvez effectuer des appels API en utilisant votre méthode préférée pour effectuer des requêtes HTTP et analyser la réponse manuellement. Cependant, nous utiliserons à cet effet un module jira excellent et très populaire.
Combinons toutes les parties pour trouver la solution.
Accédez à l'interface Google Colab et créez un nouveau bloc-notes. Après la création du notebook, nous devons stocker les informations d'identification JIRA précédemment obtenues sous forme de « secrets ». Cliquez sur l'icône « Clé » dans la barre d'outils de gauche pour ouvrir la boîte de dialogue appropriée et ajoutez deux « secrets » portant les noms suivants : JIRA_USER et JIRA_PASSWORD. En bas de l'écran, vous pouvez voir comment accéder à ces "secrets" :
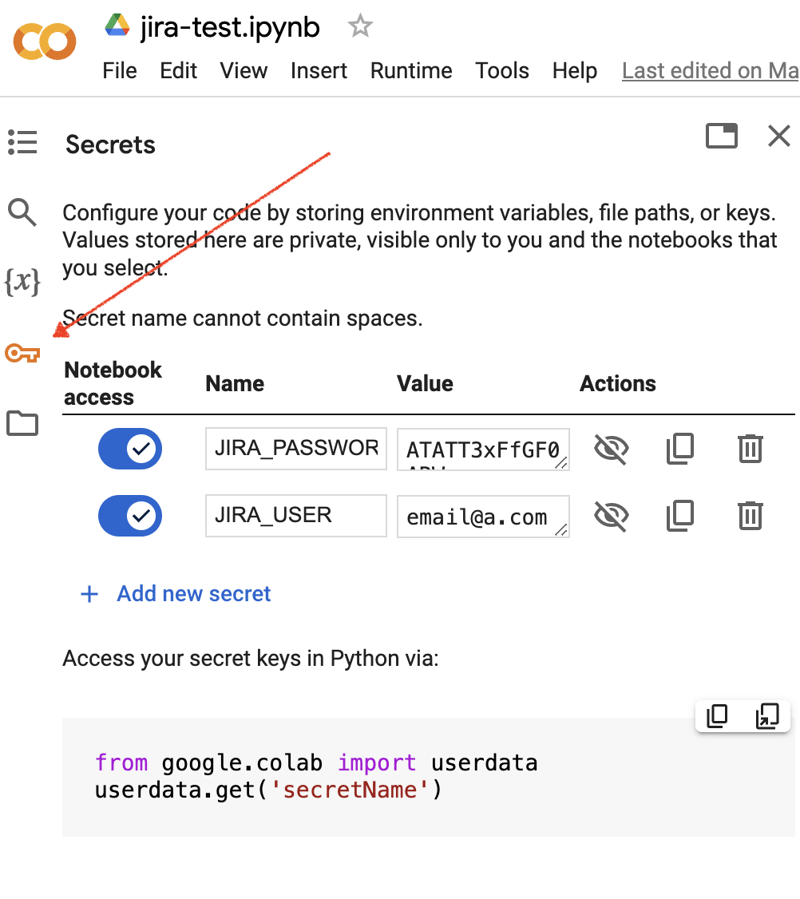
La prochaine étape consiste à installer un module Python supplémentaire pour l'intégration JIRA. Nous pouvons le faire en exécutant la commande shell dans la portée de la cellule du notebook :
!pip install jira
Le résultat devrait ressembler à ceci :
Collecting jira
Downloading jira-3.8.0-py3-none-any.whl (77 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.5/77.5 kB 1.3 MB/s eta 0:00:00
Requirement already satisfied: defusedxml in /usr/local/lib/python3.10/dist-packages (from jira) (0.7.1)
...
Installing collected packages: requests-toolbelt, jira
Successfully installed jira-3.8.0 requests-toolbelt-1.0.0
Nous devons récupérer les "secrets"/identifiants :
from google.colab import userdata
JIRA_URL = 'https://******.atlassian.net'
JIRA_USER = userdata.get('JIRA_USER')
JIRA_PASSWORD = userdata.get('JIRA_PASSWORD')
Et validez la connexion au Cloud JIRA :
from jira import JIRA jira = JIRA(JIRA_URL, basic_auth=(JIRA_USER, JIRA_PASSWORD)) projects = jira.projects() projects
Si la connexion est correcte et que les identifiants sont valides, vous devriez voir une liste non vide de vos projets :
[<JIRA Project: key='PROJ1', name='Name here..', id='10234'>, <JIRA Project: key='PROJ2', name='Friendly name..', id='10020'>, <JIRA Project: key='PROJ3', name='One more project', id='10045'>, ...
Nous pouvons donc nous connecter et récupérer des données depuis JIRA. L'étape suivante consiste à récupérer des données pour les analyser avec les pandas. Essayons de récupérer la liste des problèmes résolus au cours des dernières semaines pour un projet :
JIRA_FILTER = 19762
issues = jira.search_issues(
f'filter={JIRA_FILTER}',
maxResults=False,
fields='summary,issuetype,assignee,reporter,aggregatetimespent',
)
Nous devons transformer l'ensemble de données en bloc de données pandas :
import pandas as pd
df = pd.DataFrame([{
'key': issue.key,
'assignee': issue.fields.assignee and issue.fields.assignee.displayName or issue.fields.reporter.displayName,
'time': issue.fields.aggregatetimespent,
'summary': issue.fields.summary,
} for issue in issues])
df.set_index('key', inplace=True)
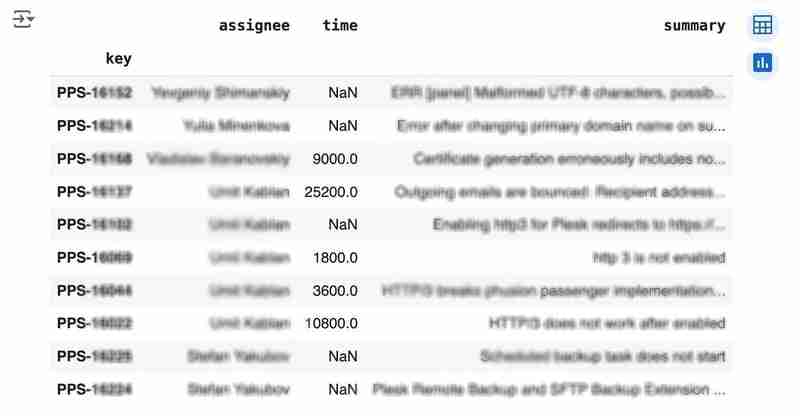
df
Le résultat peut ressembler à ce qui suit :
We would like to analyze how much time it usually takes to solve the issue. People are not ideal, so sometimes they forget to log the work. It brings a headache if you try to analyze such data using JIRA built-in tools. But it's not a problem for us to make some adjustments using pandas. For example, we can transform the "time" field from seconds into hours and replace the absent values with the median value (beware, dropna can be more suitable if there are a lot of gaps):
df['time'].fillna(df['time'].median(), inplace=True) df['time'] = df['time'] / 3600
We can easily visualize the distribution to find out anomalies:
df['time'].plot.bar(xlabel='', xticks=[])
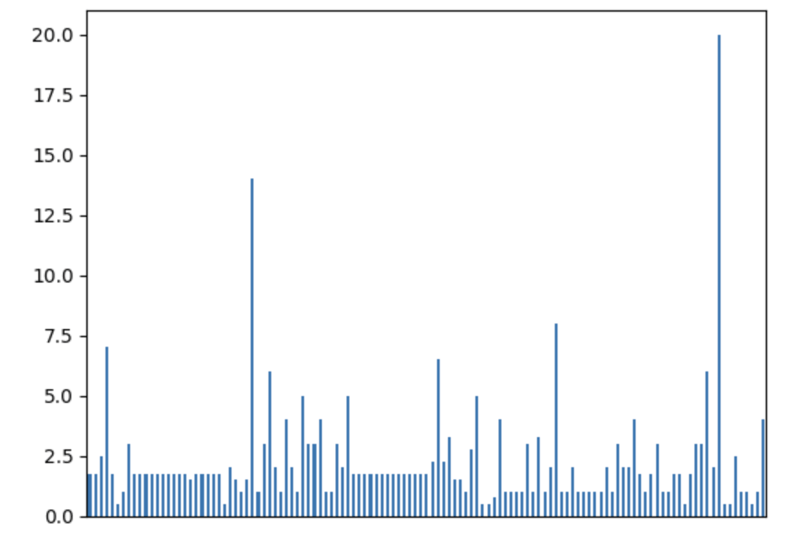
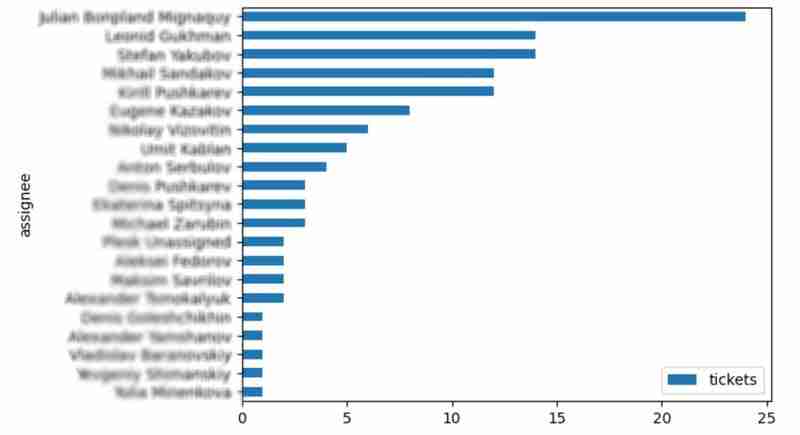
It is also interesting to see the distribution of solved problems by the assignee:
top_solvers = df.groupby('assignee').count()[['time']]
top_solvers.rename(columns={'time': 'tickets'}, inplace=True)
top_solvers.sort_values('tickets', ascending=False, inplace=True)
top_solvers.plot.barh().invert_yaxis()
It may look like the following:
Let's try to predict the amount of time required to finish all open issues. Of course, we can do it without machine learning by using simple approximation and the average time to resolve the issue. So the predicted amount of required time is the number of open issues multiplied by the average time to resolve one. For example, the median time to solve one issue is 2 hours, and we have 9 open issues, so the time required to solve them all is 18 hours (approximation). It's a good enough forecast, but we might know the speed of solving depends on the product, team, and other attributes of the issue. If we want to improve the prediction, we can utilize machine learning to solve this task.
The high-level approach looks the following:
For the first step, we will use a dataset of tickets for the last 30 weeks. Some parts here are simplified for illustrative purposes. In real life, the amount of data for learning should be big enough to make a useful model (e.g., in our case, we need thousands of issues to be analyzed).
issues = jira.search_issues(
f'project = PPS AND status IN (Resolved) AND created >= -30w',
maxResults=False,
fields='summary,issuetype,customfield_10718,customfield_10674,aggregatetimespent',
)
closed_tickets = pd.DataFrame([{
'key': issue.key,
'team': issue.fields.customfield_10718,
'product': issue.fields.customfield_10674,
'time': issue.fields.aggregatetimespent,
} for issue in issues])
closed_tickets.set_index('key', inplace=True)
closed_tickets['time'].fillna(closed_tickets['time'].median(), inplace=True)
closed_tickets
In my case, it's something around 800 tickets and only two fields for "learning": "team" and "product."
The next step is to obtain our target dataset. Why do I do it so early? I want to clean up and do "feature engineering" in one shot for both datasets. Otherwise, the mismatch between the structures can cause problems.
issues = jira.search_issues(
f'project = PPS AND status IN (Open, Reopened)',
maxResults=False,
fields='summary,issuetype,customfield_10718,customfield_10674',
)
open_tickets = pd.DataFrame([{
'key': issue.key,
'team': issue.fields.customfield_10718,
'product': issue.fields.customfield_10674,
} for issue in issues])
open_tickets.set_index('key', inplace=True)
open_tickets
Please notice we have no "time" column here because we want to predict it. Let's nullify it and combine both datasets to prepare the "features."
open_tickets['time'] = 0 tickets = pd.concat([closed_tickets, open_tickets]) tickets
Columns "team" and "product" contain string values. One of the ways of dealing with that is to transform each value into separate fields with boolean flags.
products = pd.get_dummies(tickets['product'], prefix='product')
tickets = pd.concat([tickets, products], axis=1)
tickets.drop('product', axis=1, inplace=True)
teams = pd.get_dummies(tickets['team'], prefix='team')
tickets = pd.concat([tickets, teams], axis=1)
tickets.drop('team', axis=1, inplace=True)
tickets
The result may look like the following:
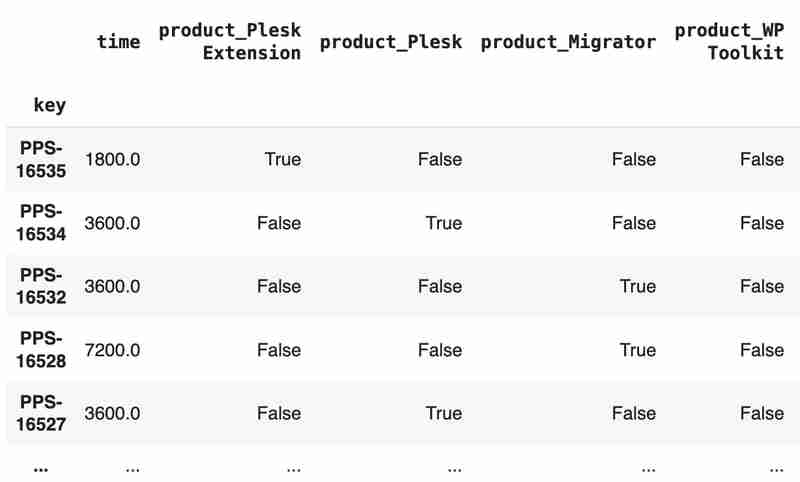
After the combined dataset preparation, we can split it back into two parts:
closed_tickets = tickets[:len(closed_tickets)] open_tickets = tickets[len(closed_tickets):][:]
Now it's time to train our model:
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeRegressor features = closed_tickets.drop(['time'], axis=1) labels = closed_tickets['time'] features_train, features_val, labels_train, labels_val = train_test_split(features, labels, test_size=0.2) model = DecisionTreeRegressor() model.fit(features_train, labels_train) model.score(features_val, labels_val)
And the final step is to use our model to make a prediction:
open_tickets['time'] = model.predict(open_tickets.drop('time', axis=1, errors='ignore'))
open_tickets['time'].sum() / 3600
The final output, in my case, is 25 hours, which is higher than our initial rough estimation. This was a basic example. However, by using ML tools, you can significantly expand your abilities to analyze JIRA data.
Sometimes, JIRA built-in tools and plugins are not sufficient for effective analysis. Moreover, many 3rd party plugins are rather expensive, costing thousands of dollars per year, and you will still struggle to make them work the way you want. However, you can easily utilize well-known data analysis tools by fetching necessary information via JIRA API and go beyond these limitations. I spent so many hours playing with various JIRA plugins in attempts to create good reports for projects, but they often missed some important parts. Building a tool or a full-featured service on top of JIRA API also often looks like overkill. That's why typical data analysis and ML tools like Jupiter, pandas, matplotlib, scikit-learn, and others may work better here.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment échanger des pièces VV
Comment échanger des pièces VV
 L'ordinateur portable n'a soudainement plus d'option WLAN
L'ordinateur portable n'a soudainement plus d'option WLAN
 Utilisation de l'ordinateur Alibaba Cloud
Utilisation de l'ordinateur Alibaba Cloud
 Qu'est-ce que la carte de contrôle d'accès NFC
Qu'est-ce que la carte de contrôle d'accès NFC
 Quels serveurs y a-t-il sur le Web ?
Quels serveurs y a-t-il sur le Web ?
 Méthode de mise en œuvre de la fonction VUE page suivante
Méthode de mise en œuvre de la fonction VUE page suivante
 Codes hexadécimaux de couleur courants
Codes hexadécimaux de couleur courants
 mi-téléchargement
mi-téléchargement








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



