

Dans cet article, nous explorerons deux méthodes pour supprimer les éléments en double d'une pile en Java. Nous comparerons une approche simple avec des boucles imbriquées et une méthode plus efficace utilisant un HashSet. L'objectif est de démontrer comment optimiser la suppression des doublons et d'évaluer les performances de chaque approche.
Écrivez un programme Java pour supprimer l'élément en double de la pile.
Entrée
Stack<Integer> data = initData(10L);
Sortie
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
Pour supprimer les doublons d'une pile donnée, nous avons 2 approches −
Ci-dessous, le programme Java construit d'abord une pile aléatoire, puis en crée une copie pour une utilisation ultérieure −
private static Stack initData(Long size) {
Stack stack = new Stack < > ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack < Integer > manualCloneStack(Stack < Integer > stack) {
Stack < Integer > newStack = new Stack < > ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}initData aide à créer une pile avec une taille spécifiée et des éléments aléatoires allant de 1 à 100.
manualCloneStack aide à générer des données en copiant les données d'une autre pile, en les utilisant pour comparer les performances entre les deux idées.
Voici l'étape pour supprimer les doublons d'une pile donnée en utilisant l'approche Naïve −
Vous trouverez ci-dessous le programme Java permettant de supprimer les doublons d'une pile donnée en utilisant l'approche Naïve −
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack < > ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}Pour l'approche Naive, nous utilisons
<code>while (!stack.isEmpty())</code>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">resultStack.contains(element)</pre><div class="contentsignin">Copier après la connexion</div></div>
pour vérifier si l'élément est déjà présent.Voici l'étape pour supprimer les doublons d'une pile donnée en utilisant une approche optimisée −
Vous trouverez ci-dessous le programme Java permettant de supprimer les doublons d'une pile donnée à l'aide de HashSet −
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start));
return tempStack;
}Pour une approche optimisée, nous utilisons
<code>Set<Integer> seen</code>
Vous trouverez ci-dessous l'étape pour supprimer les doublons d'une pile donnée en utilisant les deux approches mentionnées ci-dessus -
Vous trouverez ci-dessous le programme Java qui supprime les éléments en double d'une pile en utilisant les deux approches mentionnées ci-dessus −
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack<Integer> initData(Long size) {
Stack<Integer> stack = new Stack<>();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack<Integer> cloneStack(Stack<Integer> stack) {
Stack<Integer> newStack = new Stack<>();
newStack.addAll(stack);
return newStack;
}
public static Stack<Integer> idea1(Stack<Integer> stack) {
long start = System.nanoTime();
Stack<Integer> resultStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack<Integer> data1 = initData(10L);
Stack<Integer> data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " + idea1(data1));
System.out.println("Unique elements using idea2: " + idea2(data2));
}
}Sortie
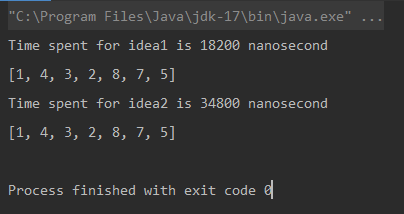
* L'unité de mesure est la nanoseconde.
public static void main(String[] args) {
Stack<Integer> data1 = initData(<number of stack size want to test>);
Stack<Integer> data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}| Method | 100 elements | 1000 elements |
10000 elements |
100000 elements |
1000000 elements |
| Idea 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Idea 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
As observed, the time running for Idea 2 is shorter than for Idea 1 because the complexity of Idea 1 is O(n²), while the complexity of Idea 2 is O(n). So, when the number of stacks increases, the time spent on calculations also increases based on it.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



