

La clé du grand succès de Transformer dans le domaine de l’apprentissage profond est le mécanisme d’attention. Le mécanisme d'attention permet aux modèles basés sur Transformer de se concentrer sur les parties pertinentes pour la séquence d'entrée, permettant ainsi une meilleure compréhension du contexte. Cependant, l'inconvénient du mécanisme d'attention est que la charge de calcul est élevée, qui augmente quadratiquement avec la taille d'entrée, ce qui rend difficile pour le Transformer de gérer des textes très longs.
Il y a quelque temps, l'émergence de Mamba a brisé cette situation, qui peut atteindre une expansion linéaire à mesure que la longueur du contexte augmente. Avec la sortie de Mamba, ces modèles d'espace d'état (SSM) peuvent déjà égaler, voire surpasser Transformer à petite et moyenne échelle, tout en conservant une évolutivité linéaire avec la longueur de séquence, ce qui confère à Mamba des caractéristiques de déploiement favorables.
En termes simples, Mamba introduit d'abord un mécanisme de sélection simple mais efficace, qui peut reparamétrer SSM en fonction de l'entrée, permettant au modèle de conserver indéfiniment les informations nécessaires tout en filtrant les informations non pertinentes et les données associées.
Récemment, un article intitulé "The Mamba in the Llama: Distilling and Accelerating Hybrid Models" prouve qu'en réutilisant les poids de la couche d'attention, les grands transformateurs peuvent être distillés en grands RNN linéaires hybrides, avec juste un minimum de calculs supplémentaires. tout en conservant l'essentiel de sa qualité de fabrication.
Le modèle hybride résultant, qui contient un quart de la couche d'attention, atteint des performances comparables à celles du Transformer d'origine dans le benchmark de chat et surpasse en utilisant les données du benchmark de chat et des benchmarks généraux. formé à partir de zéro par des milliards de jetons. De plus, l’étude propose un algorithme de décodage spéculatif sensible au matériel qui accélère l’inférence pour les modèles Mamba et hybrides.

Adresse papier : https://arxiv.org/pdf/2408.15237
Le modèle le plus performant de cette étude est celui de Llama3-8B-Instruct Distilled , il a atteint un taux de victoire contrôlé en longueur de 29,61 sur AlpacaEval 2 par rapport à GPT-4 et un taux de victoire de 7,35 sur MT-Bench, surpassant le meilleur modèle RNN linéaire ajusté en fonction des instructions.
Méthodes
La distillation des connaissances (KD) est une technique de compression de modèle utilisée pour transférer les connaissances d'un grand modèle (modèle d'enseignant) à un modèle plus petit (modèle d'élève). ), qui vise à entraîner le réseau d’étudiants à imiter le comportement du réseau d’enseignants. La recherche vise à distiller le Transformer afin que ses performances soient comparables au modèle de langage original.
Cette étude propose une méthode de distillation en plusieurs étapes qui combine distillation progressive, réglage fin supervisé et optimisation des préférences directionnelles. Par rapport à la distillation ordinaire, cette méthode peut obtenir de meilleurs résultats de perplexité et d'évaluation en aval.
L'étude suppose que la plupart des connaissances du Transformer sont conservées dans la couche MLP transférée du modèle d'origine et se concentre sur les étapes de réglage fin et d'alignement du LLM distillé. Durant cette phase, la couche MLP reste figée et la couche Mamba est entraînée.
Cette étude estime qu'il existe des liens naturels entre le RNN linéaire et le mécanisme d'attention. La formule d'attention peut être linéarisée en supprimant softmax :
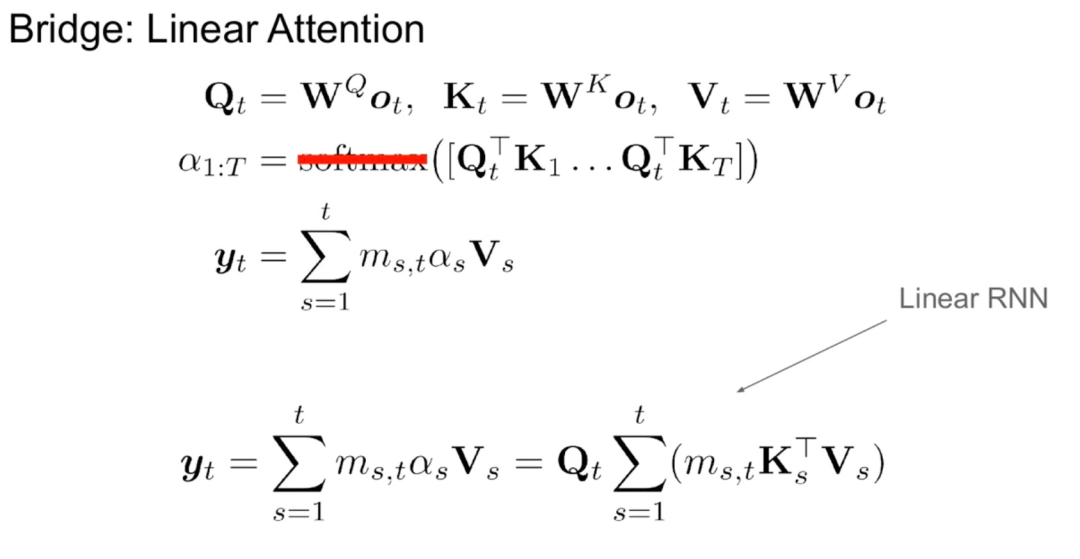
Mais linéariser l'attention entraînera une dégradation des capacités du modèle. Pour concevoir un RNN linéaire distillé efficace, cette étude se rapproche le plus possible du paramétrage original du transformateur tout en étendant la capacité du RNN linéaire de manière efficace. Cette étude ne tente pas de faire en sorte que le nouveau modèle capture la fonction d’attention originale précise, mais utilise plutôt une forme linéarisée comme point de départ pour la distillation.
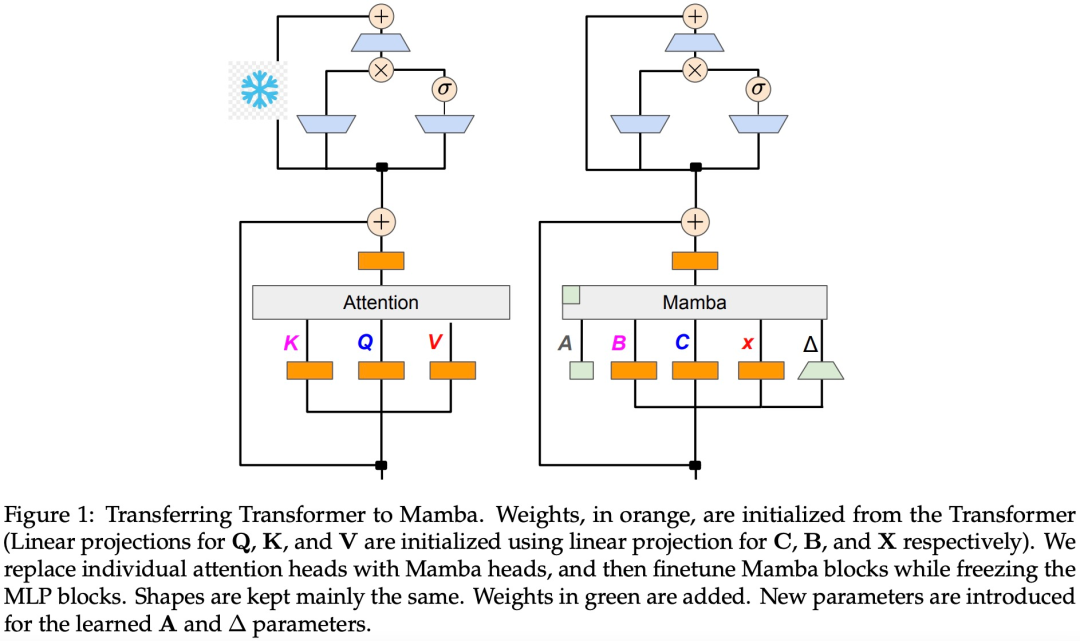
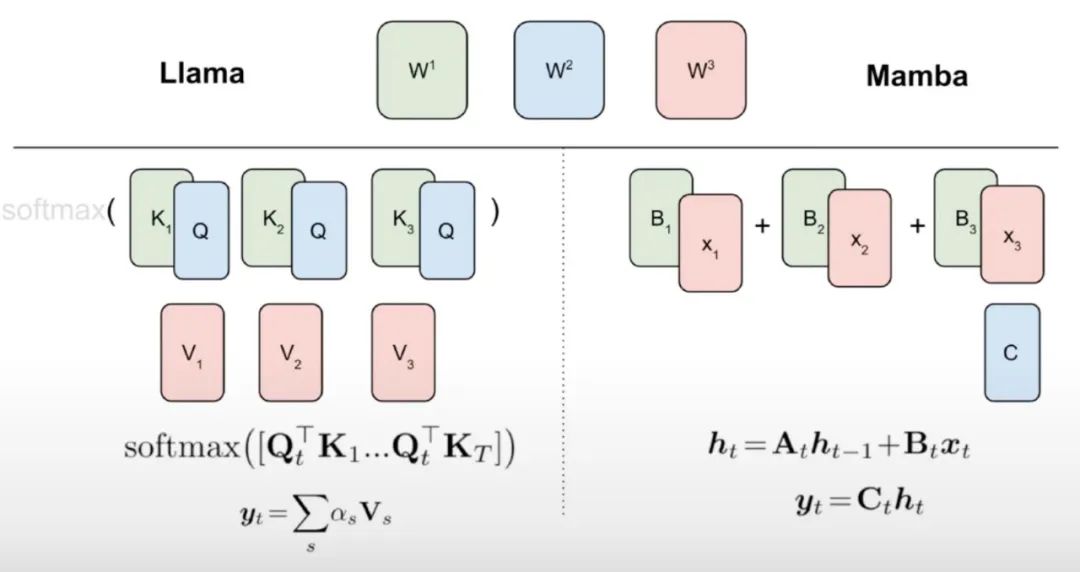
Comme le montre l'algorithme 1, cette étude alimente les têtes standards Q, K, V du mécanisme d'attention directement dans la discrétisation Mamba, puis applique le RNN linéaire résultant. Cela peut être considéré comme l'utilisation d'une attention linéaire pour une initialisation grossière et permet au modèle d'apprendre des interactions plus riches grâce à des états cachés étendus.

Cette étude remplace directement la tête d'attention du Transformer par une couche RNN linéaire affinée, gardant la couche Transformer MLP inchangée et ne les entraînant pas. Cette approche doit également gérer d'autres composants, tels que l'attention aux requêtes groupées qui partagent les clés et les valeurs entre les têtes. L'équipe de recherche a noté que cette architecture, contrairement à celles utilisées dans de nombreux systèmes Mamba, permet à cette initialisation de remplacer tous les blocs d'attention par des blocs RNN linéaires.
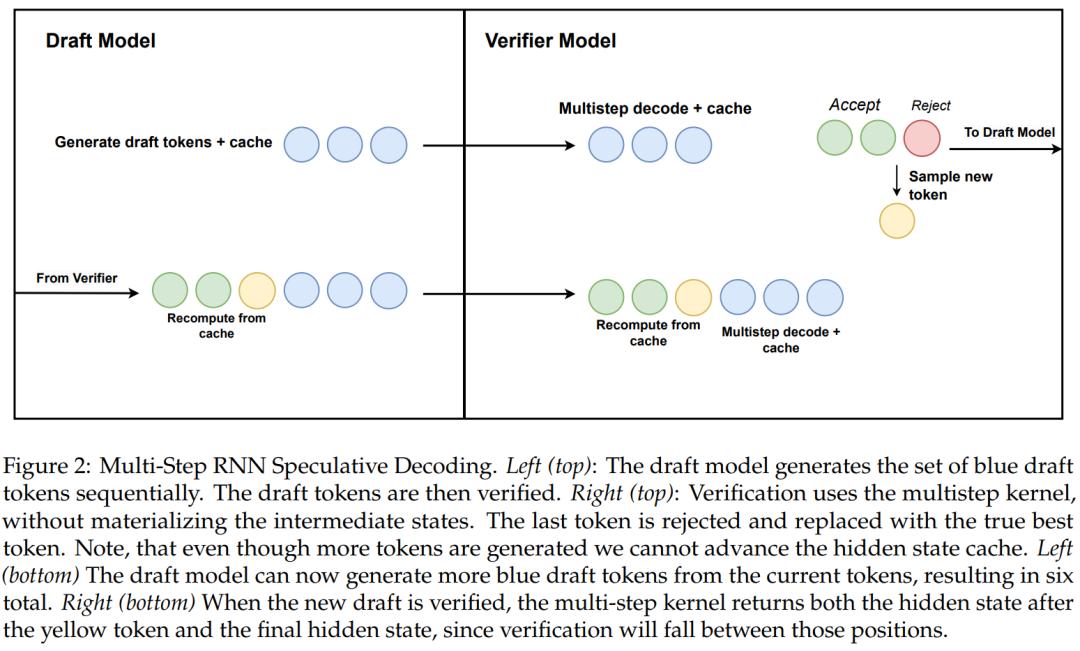
La recherche propose également un nouvel algorithme pour le décodage spéculatif RNN linéaire utilisant la génération multi-étapes sensible au matériel.
L'algorithme 2 et la figure 2 montrent l'algorithme complet. Cette approche conserve uniquement un état caché RNN dans le cache à des fins de vérification et le fait progresser paresseusement en fonction du succès du noyau en plusieurs étapes. Puisque le modèle de distillation contient des couches de transformateur, cette étude étend également le décodage spéculatif à une architecture hybride Attention/RNN. Dans cette configuration, la couche RNN effectue une vérification selon l'algorithme 2, tandis que la couche Transformer effectue uniquement une vérification parallèle.

Pour vérifier l'efficacité de cette méthode, l'étude a utilisé Mamba 7B et Mamba 2.8B comme modèles cibles pour la spéculation. Les résultats sont présentés dans le tableau 1.
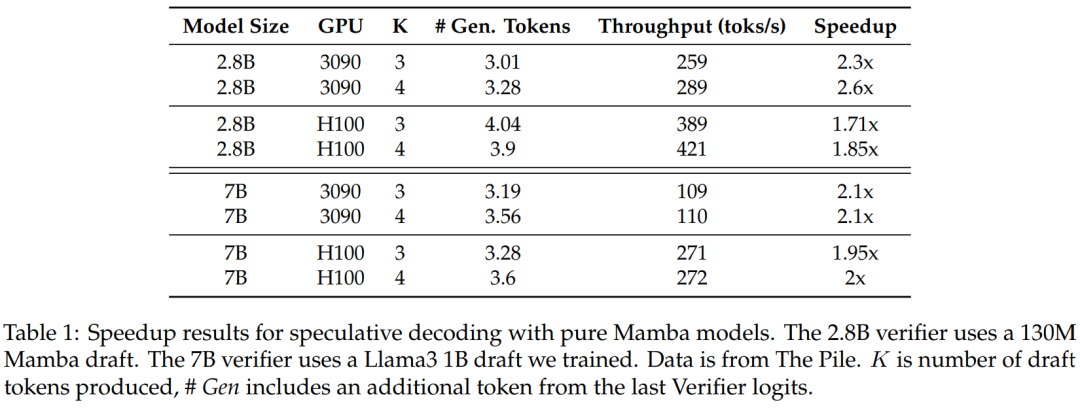
La figure 3 montre les caractéristiques de performances du noyau multi-étapes lui-même.
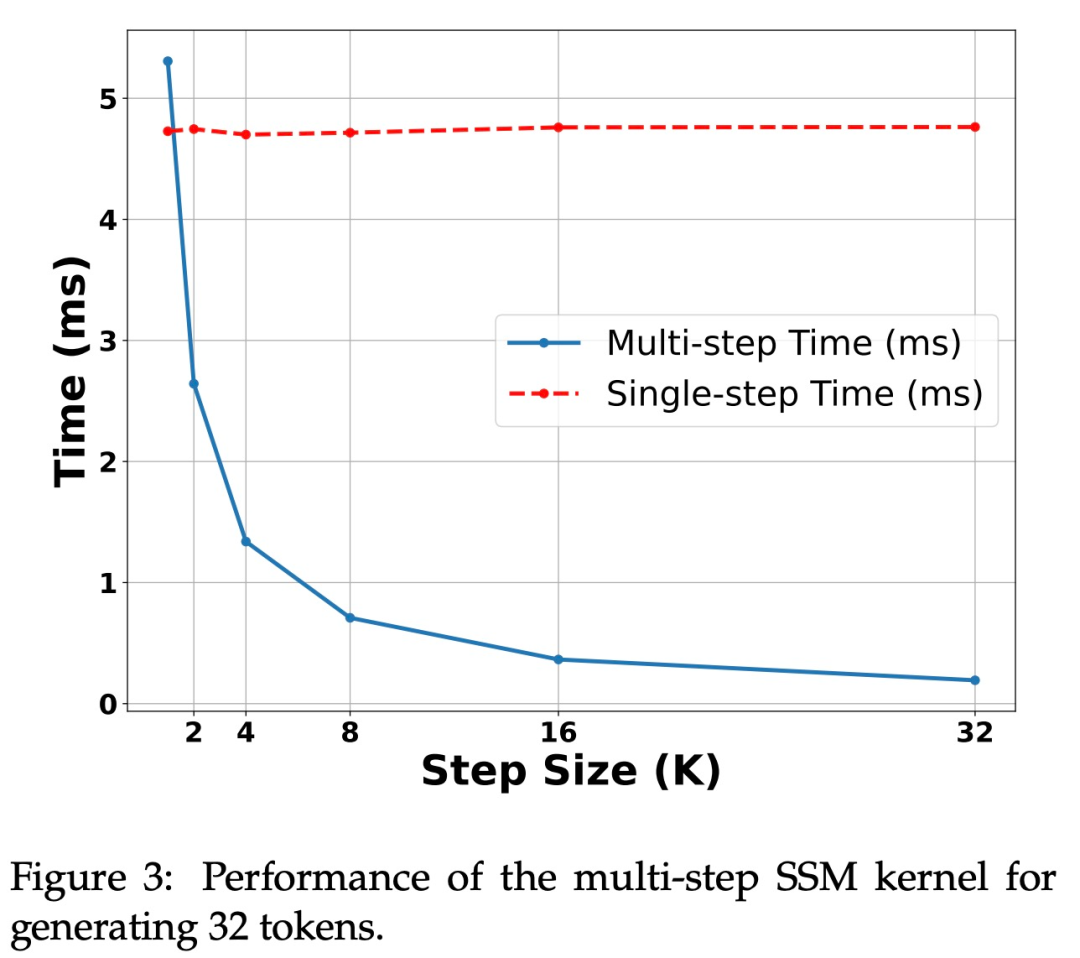
Accélération sur GPU H100. L'algorithme proposé dans cette étude montre de solides performances sur le GPU Ampere, comme le montre le tableau 1 ci-dessus. Mais le GPU H100 présente d’énormes défis. Cela est principalement dû au fait que les opérations GEMM sont trop rapides, ce qui rend plus visible la surcharge causée par les opérations de mise en cache et de recalcul. En effet, une simple implémentation de l'algorithme étudié (utilisant plusieurs appels de noyau différents) a permis d'obtenir une accélération considérable sur le GPU 3090, mais aucune accélération du tout sur le H100.
Expériences et résultats
Cette étude utilise deux modèles de chat LLM pour les expériences : Zephyr-7B est affiné sur la base du modèle Mistral 7B et Llama- 3 Instruct 8B. Pour le modèle RNN linéaire, cette étude utilise une version hybride de Mamba et Mamba2 avec des couches d'attention de 50 %, 25 %, 12,5 % et 0 % respectivement, et appelle 0 % un modèle Mamba pur. Mamba2 est une variante architecturale de Mamba conçue principalement pour les architectures GPU récentes.
Évaluation sur le Chat Benchmark
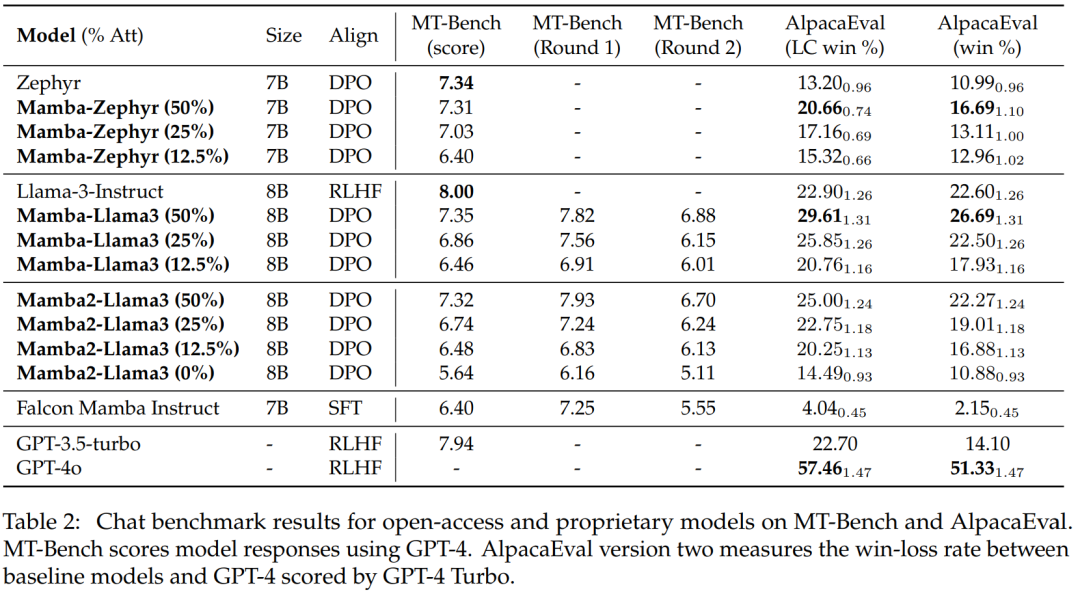
Le tableau 2 montre les performances du modèle sur le Chat Benchmark. Le principal modèle comparé est le grand modèle Transformer. Les résultats montrent :
Le modèle hybride distillé Mamba (50 %) obtient des scores similaires au modèle d'enseignant dans le benchmark MT, et est légèrement meilleur que le modèle d'enseignant dans le benchmark AlpacaEval en termes de taux de victoire LC et taux de victoire global.
Les performances du Mamba hybride distillé (25% et 12,5%) sont légèrement inférieures à celles du modèle enseignant sur le benchmark MT, mais même avec plus de paramètres dans AlpcaaEval, il surpasse toujours certains gros Transformers.
La précision du modèle Mamba pur distillé (0 %) diminue considérablement.
Il convient de noter que le modèle hybride distillé est plus performant que le Falcon Mamba, qui est formé à partir de zéro en utilisant plus de 5T de jetons.
Évaluation générale de référence
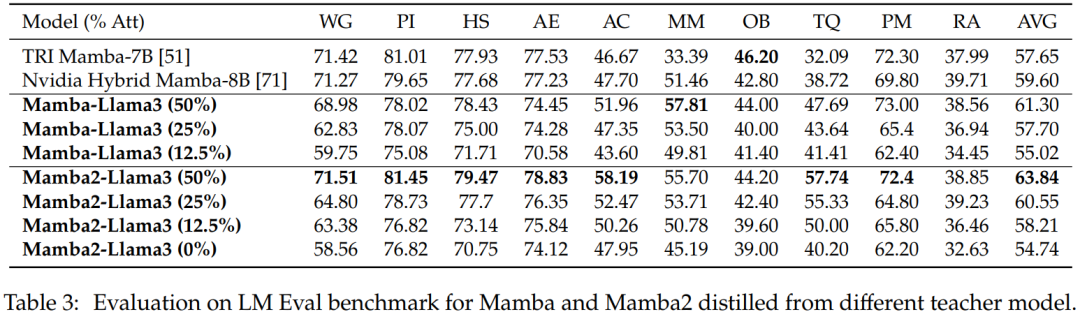
Évaluation sur échantillon zéro. Le tableau 3 montre les performances zéro tir de Mamba et Mamba2 distillées à partir de différents modèles d'enseignants sur le benchmark LM Eval. Les modèles hybrides Mamba-Llama3 et Mamba2-Llama3 distillés à partir de Llama-3 Instruct 8B ont obtenu de meilleurs résultats que les modèles open source TRI Mamba et Nvidia Mamba formés à partir de zéro.
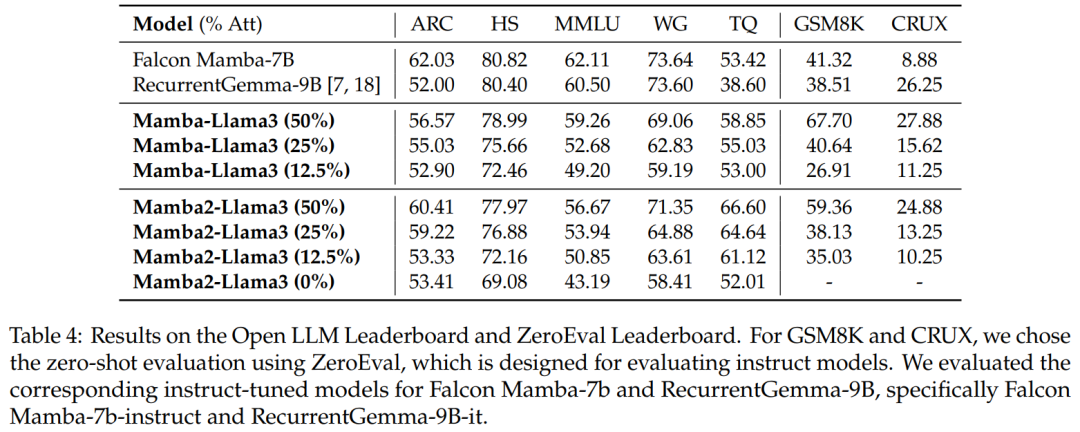
Évaluation de référence. Le tableau 4 montre que les performances du modèle hybride distillé correspondent au meilleur modèle RNN linéaire open source sur Open LLM Leaderboard, tout en surpassant le modèle d'instruction open source correspondant dans GSM8K et CRUX.
Décodage spéculatif hybride
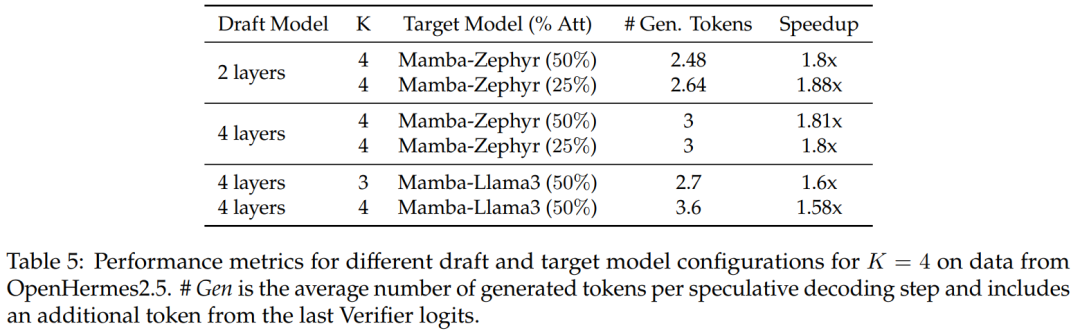
Pour les modèles de distillation à 50 % et 25 %, par rapport à la ligne de base non spéculative, cette étude Atteint une accélération de plus de 1,8x sur Zephyr-Hybrid.
Les expériences montrent également que le modèle de brouillon à 4 couches formé dans cette étude atteint un taux de réception plus élevé, mais en raison de l'augmentation de la taille du modèle de brouillon, la surcharge supplémentaire devient également plus importante. Dans les travaux ultérieurs, cette recherche se concentrera sur la réduction de ces projets de modèles.
Comparaison avec d'autres méthodes de distillation : Le tableau 6 (à gauche) compare la perplexité des différentes variantes de modèles. L’étude a effectué une distillation au cours d’une époque en utilisant Ultrachat comme invite de départ et a comparé la perplexité. Il s’avère que supprimer davantage de couches aggrave la situation. L'étude a également comparé la méthode de distillation aux lignes de base précédentes et a révélé que la nouvelle méthode montrait une dégradation plus faible, tandis que le modèle Distill Hyena avait été formé sur l'ensemble de données WikiText à l'aide d'un modèle beaucoup plus petit et montrait un degré de confusion de dégradation plus important.
표 6(오른쪽)을 보면 SFT나 DPO만 사용하면 그다지 개선되지 않는 반면, SFT + DPO를 사용하면 가장 좋은 점수를 얻을 수 있음을 알 수 있습니다.
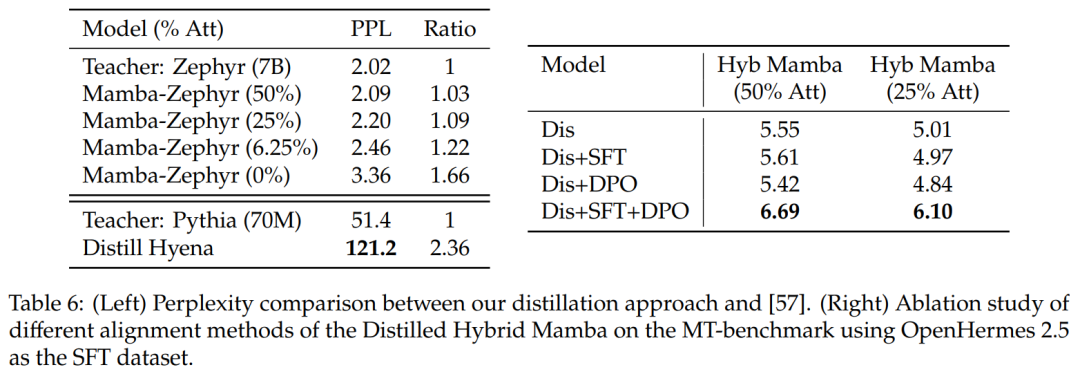
표 7에서는 여러 가지 모델에 대한 절제 연구를 비교합니다. 표 7(왼쪽)은 다양한 초기화를 사용한 증류 결과를 보여주고, 표 7(오른쪽)은 Mamba를 사용한 점진적 증류 및 인터리빙 Attention 레이어에서 더 작은 이득을 보여줍니다.
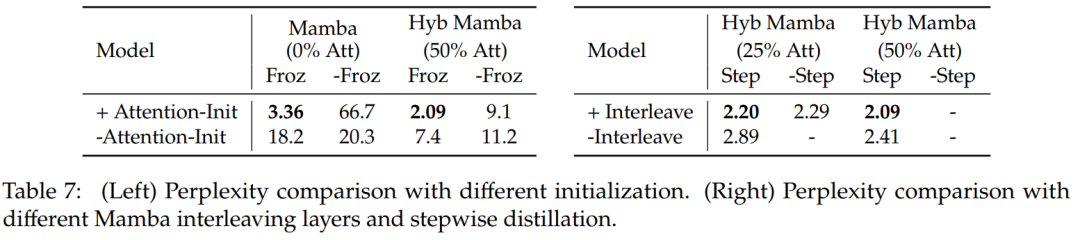
표 8은 두 가지 초기화 방법을 사용하는 하이브리드 모델의 성능을 비교합니다. 결과는 어텐션 가중치의 초기화가 중요하다는 것을 확인시켜줍니다.

표 9는 Mamba 블록이 있는 모델과 없는 모델의 성능을 비교합니다. Mamba 블록이 있는 모델은 Mamba 블록이 없는 모델보다 훨씬 더 나은 성능을 발휘합니다. 이는 Mamba 레이어를 추가하는 것이 중요하며, 성능 향상이 단지 남아 있는 Attention 메커니즘 때문만은 아니라는 점을 확인시켜 줍니다.

관심 있는 독자는 논문 원문을 읽고 연구 내용에 대해 자세히 알아볼 수 있습니다.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment accéder au lecteur D avec cmd
Comment accéder au lecteur D avec cmd
 Quels sont les outils de vérification de code statique ?
Quels sont les outils de vérification de code statique ?
 Dernier classement des échanges de devises numériques
Dernier classement des échanges de devises numériques
 La signification du titre en HTML
La signification du titre en HTML
 Introduction à la signification de += en langage C
Introduction à la signification de += en langage C
 Quels sont les logiciels bureautiques
Quels sont les logiciels bureautiques
 Que signifie pdf ?
Que signifie pdf ?
 Solution d'erreur de paramètre 0x80070057
Solution d'erreur de paramètre 0x80070057








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



