


编辑| ScienceAI
近日,上海交通大学、上海AI Lab、中国移动等机构的联合研究团队,在arXiv 预印平台发布文章《Towards Evaluating and Building Versatile Large Language Models for Medicine》,从数据、测评、模型多个角度全面分析讨论了临床医学大语言模型应用。
文中所涉及的所有数据和代码、模型均已开源。

概览
近年来,大型语言模型(LLM)取得了显着的进展,并在医疗领域取得了一定成果。这些模型在医学多项选择问答(MCQA)基准测试中展现出高效的能力,并且 UMLS 等专业考试中达到或超过专家水平。
然而,LLM 距离实际临床场景中的应用仍然有相当长的距离。其主要问题,集中在模型在处理基本医学知识方面的不足,如在解读 ICD 编码、预测临床程序以及解析电子健康记录(EHR)数据方面的误差。
这些问题指向了一个关键:当前的评估基准主要关注于医学考试选择题,而不能充分反映 LLM 在真实临床情景中的应用。
本研究提出了一项新的评估基准MedS-Bench,该基准不仅包括多项选择题,还涵盖了临床报告摘要、治疗建议、诊断和命名实体识别等11 项高级临床任务。
研究团队通过此基准对多个主流的医疗模型进行了评估,发现即便是使用了few-shot prompting,最先进模型,例如,GPT-4,Claude 等,在处理这些复杂的临床任务时也面临困难。
为解决这一问题,受到Super-NaturalInstructions 的启发,研究团队构建了首个全面的医学指令微调数据集MedS-Ins,该数据集整合了来自考试、临床文本、学术论文、医学知识库及日常对话的58 个生物医学文本数据集,包含超过1350 万个样本,涵盖了122 个临床任务。
在此基础上,研究团队对开源医学语言模型进行指令调整,探索了 in-context learning 环境下的模型效果。
该工作中开发的医学大语言模型——MMedIns-Llama 3,在多种临床任务中的表现超过了现有的领先闭源模型,如 GPT-4 和 Claude-3.5。 MedS-Ins 的构建极大的促进了医学大语言模型在实际临床场景的中的能力,使其应用范围远超在线聊天或多项选择问答的限制。
相信这一进展不仅推动了医学语言模型的发展,也为未来临床实践中的人工智能应用提供了新的可能性。
测试基准数据集(MedS-Bench)
为了评估各种LLM 在临床应用中的能力,研究团队开发了MedS -Bench,这是一个超越传统选择题的综合性医学基准。如下图所示,MedS-Bench 源自 39 个现有数据集,覆盖 11 个类别,总共包含 52 个任务。
在 MedS-Bench 中,数据被重新格式化为指令微调的结构。此外,每条任务都配有人工标注的任务定义。涉及的11 个类别分别是:选择题解答(MCQA)、文本摘要(Text Summarization)、信息提取(Information Extraction)、解释与推理(Explanation and Rationale)、命名实体识别(NER) 、诊断(Diagnosis)、治疗计划规划(Treatment Planning)、临床结果预测(Clinical Outcome Prediction)、文本分类(Text Classification)、事实验证(Fact Verification)和自然语言推理(NLI)。
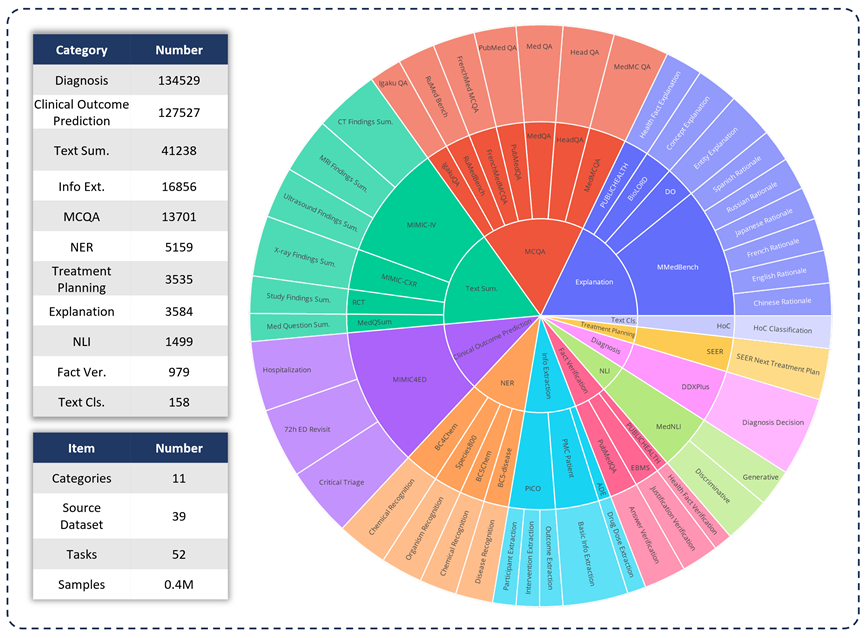
除了定义这些任务类别,研究团队还对 MedS-Bench 文本长度进行了详细的统计,并区分了 LLM 处理不同任务所需的能力,如下表所示。LLM 处理任务所需的能力被分为两类:(i)根据模型内部知识进行推理;(ii) 从提供的上下文中检索事实。
广义上讲,前者涉及的任务需要从大规模预训练中获取编码在模型权重中的知识,而后者涉及的任务则需要从所提供的上下文中提取信息,如总结或信息提取。如表 1 所示,总共有八类任务要求模型从模型中调用知识,而其余三类任务则要求从给定上下文中检索事实。
表 1:所用测试任务的详细统计信息。

指令微调数据集(MedS-Ins)
此外,研究团队还开源了指令微调数据集 MedS-Ins。该数据集覆盖 5 个不同的文本源和 19 个任务类别,共计 122 个不同的临床任务。下图总结了 MedS-Ins的构造流程以及统计信息。
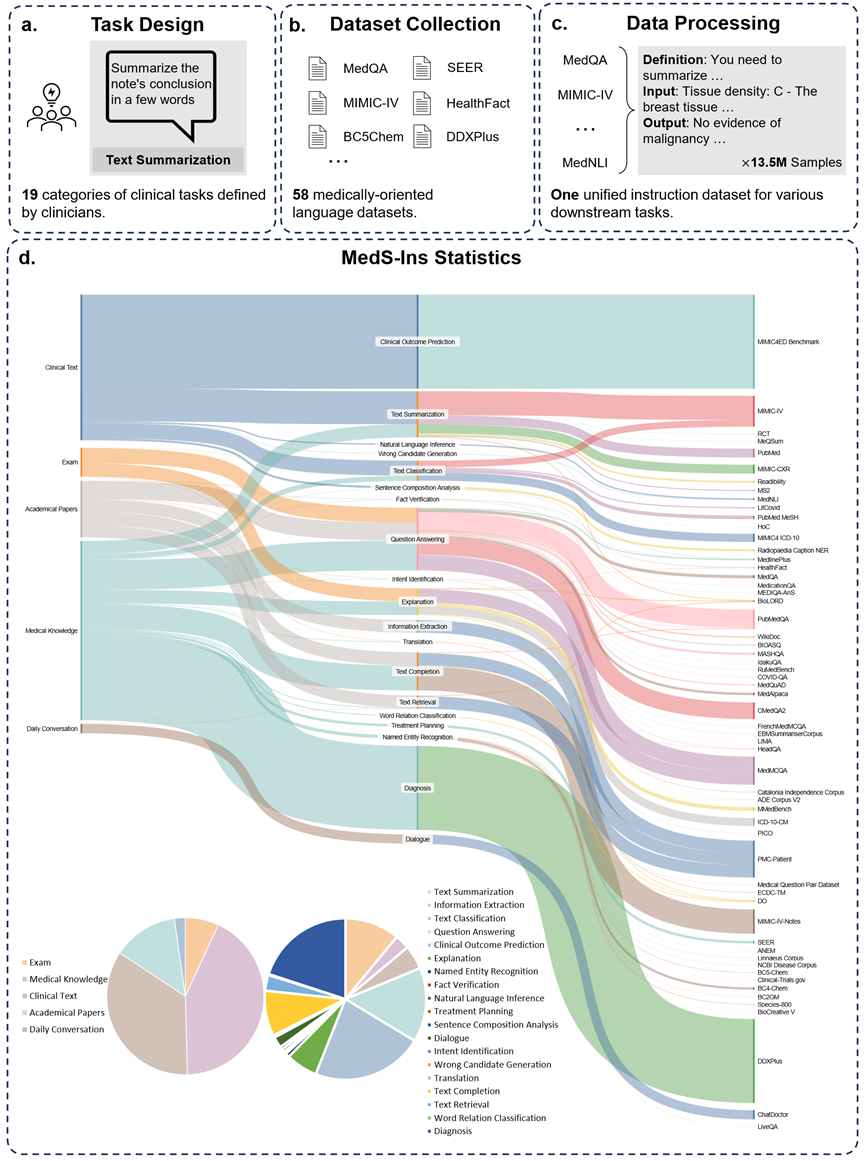
文本源
本文提出的指令微调数据集由五个不同来源的样本组成:考试、临床文本、学术论文、医学知识库和日常对话。
考试:该类别包含来自不同国家医学考试试题的数据。它涵盖了从基本医学常识到复杂临床手续广泛的医学知识。考试题目是了解和评估医学教育水平的重要手段,然而值得注意的是,考试的高度标准化往往导致其案例与真实世界的临床任务相比过于简化。数据集中 7% 的数据来自考试。
临床文本:该类别文本在常规临床实践中产生,包括医院和临床中心的诊断、治疗和预防过程。这类文本包括电子健康记录 (EHR)、放射报告、化验结果、随访指导和用药建议等。这些文本是疾病诊断和患者管理所不可或缺的,因此准确的分析和理解对于 LLM 的有效临床应用至关重要。数据集中 35% 的数据来自临床文本。
学术论文:该类别数据来源于医学研究论文,涵盖了医学研究领域的最新发现和进展。由于学术论文便于获取和结构化组织,从学术论文中提取数据相对简单。这些数据有助于模型掌握最前沿的医学研究信息,引导模型更好地理解当代医学的发展。数据集中有 13% 的数据来自学术论文。
医学知识库:该类别数据由组织良好的综合医学知识组成,包括医学百科全书、知识图谱和医学术语词汇表。这些数据构成了医学知识库的核心,为医学教育和 LLM 在临床实践中的应用提供了支持。数据集中 43% 的数据来自医学知识。
日常对话:该类别数据指的是医生与患者之间产生的日常咨询、主要来源于在线平台和其他互动场景。这些数据反映了医务人员与患者之间的真实互动、在了解患者需求、提升整体医疗服务体验方面发挥着至关重要的作用。数据集中有 2% 的数据来自日常对话。
任务种类
除了对文本涉及领域进行分类外,研究团队对 MedS-Ins 中样本的任务类别进行进一步细分:确定了 19 个任务类别,每个类别都代表了医学大语言模型应具备的关键能力。通过构建该指令微调数据集并相应地微调模型,使大语言模型具备处理医疗应用所需的多种能力,具体如图 2 所示。
MedS-Ins 中的 19 个任务类别包括但不限于 MedS-Bench 基准中的 11 个类别。额外的任务类别涵盖了医学领域所必需的一系列语言和分析任务,包括意图识别、翻译、单词关系分类、文本检索、句子成分分析、错误候选词生成、对话和文本补齐,而 MCQA 则扩展为一般的问答。任务类别的多样性——从普通问答和对话到各种下游临床任务,保证了对医疗应用的全面理解。
量化对比
研究团队广泛地测试了现存六大主流模型(MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4 and Claude-3.5)在每种任务类型上的表现,首先讨论各种现有 LLM 的性能,然后与提出的最终模型 MMedIns-Llama 3 进行比较。在本文中,所有结果都是使用 3-shot Prompt 得出的。除了在 MCQA 任务中使用了 zero-shot Prompt,以便与之前的研究保持一致。由于 GPT-4 和 Claude 3.5 等闭源模型会产生费用,受限于成本,实验中仅对每个任务抽样 50-100 个测试用例,全面的测试量化结果如表 2-8 所示。
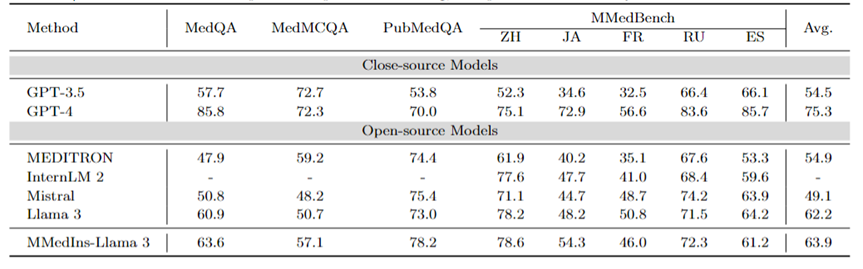
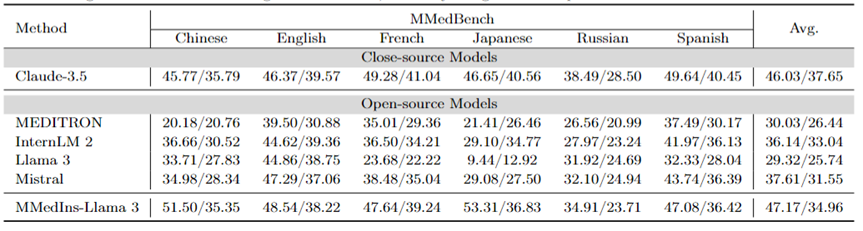
多语种多选题问答:表 2 以「Accuracy」展示了在广泛使用的 MCQA 基准上的评估结果。在这些多选题问答数据集上,现有的大语言模型都表现出了非常高的准确率,例如,在 MedQA 上,GPT-4 可以达到 85.8 分,几乎可以与人类专家相媲美,而 Llama 3 也能以 60.9 分通过考试。同样,在英语以外的语言方面,LLM 在 MMedBench 上的多选准确率也表现出优异的成绩。
结果表明,由于多选题在现有研究中已被广泛考虑,不同的 LLM 可能已针对此类任务进行了专门优化,从而获得了较高的性能。因此,有必要建立一个更全面的基准、 以进一步推动 LLM 向临床应用发展。
表2:选择题上的量化结果,各项指标以选择准确率ACC进行衡量。
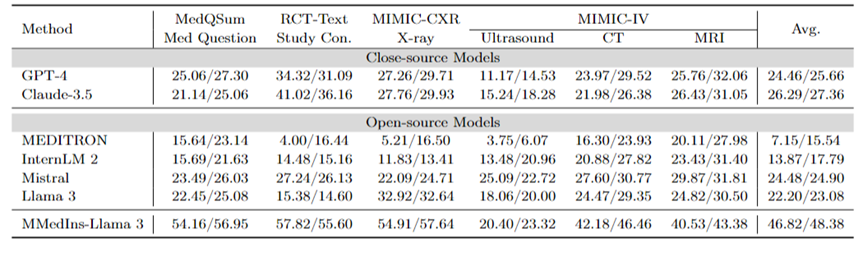
文本总结:表 3 以 「BLEU/ROUGE 」分数的形式报告了不同语言模型在文本总结任务上的性能。测试覆盖了多种报告类型,包括 X 光、CT、MRI、超声波和其他医疗问题。实验结果表明,GPT-4 和 Claude-3.5 等闭源大语言模型的表现优于所有开源大语言模型。
在开源模型中,Mistral 的结果最好,BLEU/ROUGE 分别为 24.48/24.90,Llama 3 紧随其后,为 22.20/23.08。
本文提出的 MMedIns-Llama 3 是在特定医疗教学数据集(MedS-Ins)上训练出来的,其表现明显优于其他模型,包括先进的闭源模型 GPT-4 和 Claude-3.5,平均得分达到 46.82/48.38。
表 3:文本总结任务上的量化结果。
信息抽取:表 4 以「Accuracy」展示了不同模型信息提取的性能。InternLM 2 在这项任务中表现优异,平均得分为 81.58,GPT-4 和 Claude-3.5 等闭源模型的平均得分分别为 77.49 分和 78.86 分,优于所有其他开源模型。
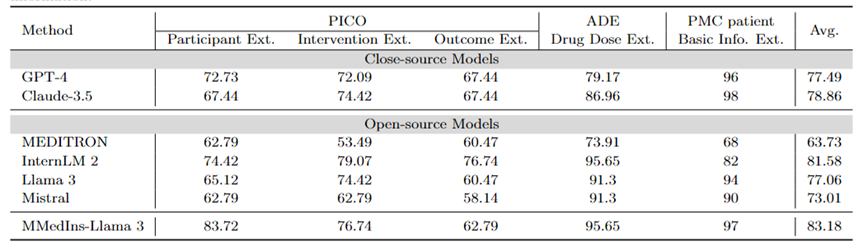
对单个任务结果的分析表明,与专业的医疗数据相比,大多数大语言模型在提取病人基本信息等不太复杂的医疗信息方面表现更好。例如,在从 PMC 患者中提取基本信息方面,大多数大语言模型的得分都在 90 分以上,其中 Claude-3.5 的得分最高,达到 98.02 分。相比之下,PICO 中临床结果提取任务的表现相对较差。本文提出的模型 MMedIns-Llama 3 整体表现最佳,平均得分 83.18,超过 InternLM 2 模型 1.6 分。
表 4:信息提取任务上的量化结果,各项指标以准确度(ACC)进行衡量。「Ext.」表示Extraction,「Info.」表示 Information。
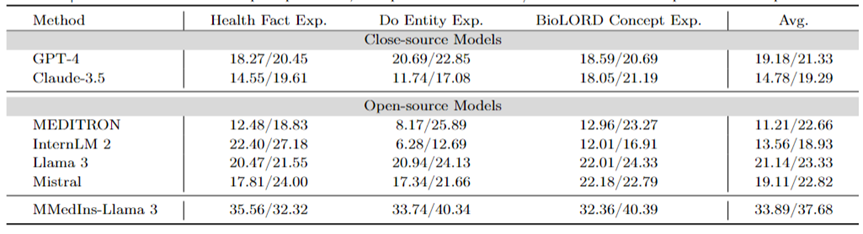
医学概念解释:表 5 以 「BLEU/ROUGE 」分数的形式展示了不同模型医学概念解释能力,GPT-4,Llama 3和Mistral 在这项任务中表现良好。
相反,Claude-3.5、InternLM 2 和 MEDITRON 的得分相对较低。MEDITRON 的表现相对较差可能是由于其训练语料更侧重于学术论文和指南,因此在对于医学概念解释方面能力有所欠缺。
最终模型 MMedIns-Llama 3 在所有概念解释任务中的表现都明显优于其他模型。
表 5:医学概念解释上的量化结果,各项指标以 BLEU-1/ROUGE-1 进行衡量;「Exp.」表示 Explanation。
归因分析(Rationale):表 6 以 「BLEU/ROUGE 」分数的形式评估了各个模型在归因分析任务上的性能,使用 MMedBench 数据集对六种语言的各种模型的推理能力进行了比较。
在测试的模型中,闭源模型 Claude-3.5 表现出最强的性能,平均得分为 46.03/37.65。这种优异的表现可能是因为该任务与生成 COT 相似,而后者在许多通用 LLM 中均得到了特别增强。
在开源模型中,Mistral 和 InternLM 2 表现出了相当的性能,平均得分分别为 37.61/31.55 和 30.03/26.44。值得注意的是,GPT-4 被排除在本次评估之外,因为 MMedBench 数据集的归因分析部分主要使用 GPT-4 来生成构建,这可能会引入测试偏差,从而导致不公平的比较。
与概念解释任务上的表现一致,最终模型 MMedIns-Llama 3 也展现了最佳的整体性能,所有语言上的平均得分为 47.17/34.96。这种优异的表现可能是因为选用的基础语言模型(MMed-Llama 3)最初是为多语言开发的。因此,即使指令调整没有明确针对多语言数据,最终模型在多种语言中的表现仍然优于其他模型。
表 6:归因分析(Rationale)上的量化结果,各项指标以 BLEU-1/ROUGE-1 进行衡量。此处没有 GPT-4 是因为原始数据基于 GPT-4 生成结果构造,存在公平性偏倚,故未比较 GPT-4。
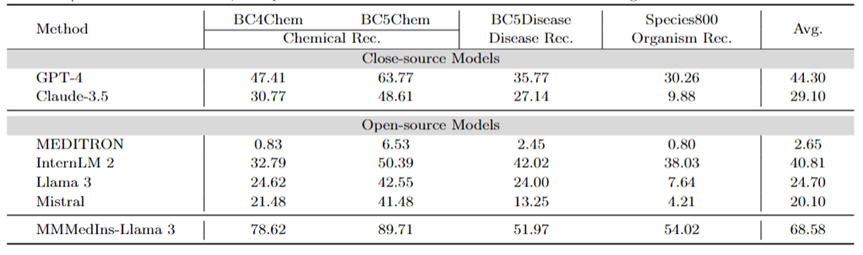
医学实体抽取(NER):表 7 以「F1」分数的形式测试了现有的 6 个模型在 NER 任务上的表现。GPT-4 是唯一一个在命名实体识别 (NER) 各项任务中均表现优异的模型,平均 F1 分数为 44.30 。
它在 BC5Chem 化学实体识别任务中表现尤为出色,得分为 63.77。InternLM 2 则紧随其后,平均 F1 分数为 40.81,在 BC5Chem 和 BC5Disease 任务中均表现出色。Llama 3 和 Mistral 的平均 F1 分数则分别为 24.70 和 20.10,表现中等。MEDITRON 未针对 NER 任务进行优化,在此领域的效果差强人意。MMedIns-Llama 3 的表现则明显优于所有其他模型,平均 F1 得分为68.58。
表 7:NER 任务上的量化结果,各项指标以F1-score进行衡量;「Rec.」代表「recognition」
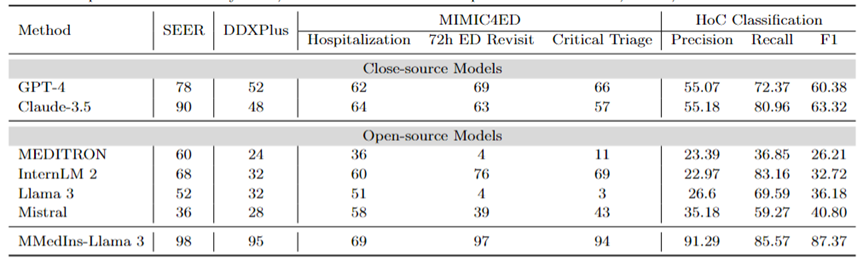
诊断、治疗推荐、和临床结果预测:表 8 使用 DDXPlus 数据集作为诊断基准、SEER 数据集作为治疗推荐基准和 MIMIC4ED 数据作为临床结果预测任务基准来评估诊断、治疗推荐和临床结果预测三大任务的模型表现,结果以准确度来衡量,如表 8 所示。
在此,使用可以使用准确度指标来评估生成预测是因为这些数据集每一个都将原始问题简化为一个闭集上的选择问题。具体而言,DDXPlus 使用预定义的疾病列表,模型必须根据提供的患者背景从中选择一个疾病。在 SEER 中,治疗建议则被分为了八个高级类别,而在 MIMIC4ED 中,最终的临床结果决策是始终是二值的(True or False)。
总体而言,开源 LLM 在这些任务中的表现不如闭源 LLM,在某些情况下,它们无法提供有意义的预测。例如,Llama 3 在预测 Critical Triage 方面表现不佳。对于 DDXPlus 诊断任务而言,InternLM 2 和 Llama 3 的表现略好一些,准确度为 32。然而,GPT-4 和 Claude-3.5 等闭源模型表现出明显更好的性能。例如,Claude-3.5在SEER上准确度可以达到为90,而GPT-4则在 DDXPlus 的诊断方面的准确度上更高,得分为 52,突显出了开源和闭源 LLM 之间的巨大差距。
Malgré ces résultats, ces scores ne sont toujours pas suffisamment fiables pour une utilisation clinique. En revanche, MMedIns-Llama 3 a montré une précision supérieure dans les tâches d'aide à la décision clinique, telles que 98 sur SEER, 95 sur DDXPlus, et une précision moyenne de 86,67 sur les tâches de prédiction des résultats cliniques (hospitalisation, moyenne de 72 heures de visite à l'urgence et scores de triage critique). ).
Classification de texte : Le tableau 8 montre également l'évaluation de la tâche de classification multi-étiquettes HoC et rapporte les scores de macro-précision, de macro-rappel et de macro-F1. Pour ce type de tâche, toutes les étiquettes candidates sont saisies dans le modèle de langage sous la forme d'une liste, et le modèle est invité à sélectionner la réponse correspondante, plusieurs choix étant autorisés. Les mesures de précision sont ensuite calculées sur la base du résultat de sélection finale du modèle.
GPT-4 et Claude-3.5 fonctionnent bien dans cette tâche. Le score Macro-F1 de GPT-4 est de 60,38, et Claude-3.5 est encore meilleur, atteignant 63,32. Les deux modèles présentent de fortes capacités de rappel, en particulier Claude-3.5, qui possède un macro-rappel de 80,96. Mistral s'est plutôt bien comporté avec un score Macro-F1 de 40,8, équilibrant précision et rappel.
En revanche, les performances globales de Llama 3 et InternLM 2 sont médiocres, avec des scores Macro-F1 de 36,18 et 32,72 respectivement. Ces modèles (en particulier InternLM 2) présentent un rappel élevé mais une précision médiocre, ce qui entraîne de faibles scores Macro-F1.
MEDITRON se classe au dernier rang dans cette tâche avec un score Macro-F1 de 26,21. MMedIns-Llama 3 surpasse considérablement tous les autres modèles, obtenant les scores les plus élevés dans toutes les mesures, avec une macro-précision de 91,29, un macro-rappel de 85,57 et un score Macro-F1 de 87,37. Ces résultats mettent en évidence la capacité de MMedIns-Llama 3 à classer avec précision du texte, ce qui en fait le modèle le plus efficace pour ce type de tâche complexe.
Tableau 8 : Résultats sur quatre catégories de tâches : planification du traitement (SEER), diagnostic (DDXPlus), prédiction des résultats cliniques (MIMIC4ED) et classification de texte (Classification HoC). Les résultats des trois premières tâches sont basés sur l'exactitude et les résultats de la classification de texte sont basés sur la précision, le rappel et le score F1.
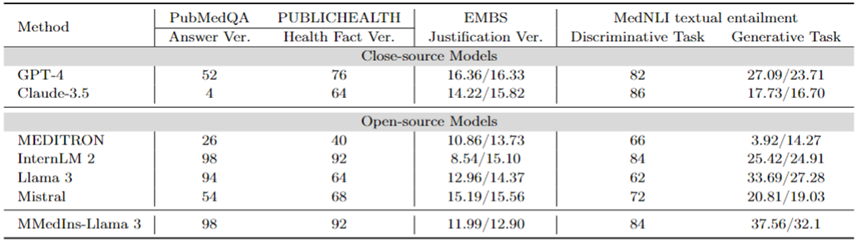
Correction des faits : Le tableau 9 montre les résultats de l'évaluation du modèle sur la tâche de vérification des faits. Pour la validation des réponses PubMedQA et la validation HealthFact, LLM doit sélectionner une réponse dans la liste de candidats fournie, la précision est donc utilisée comme mesure d'évaluation.
En revanche, en raison de la validation de la justification EBMS, la tâche consiste à générer un texte de forme libre, en utilisant les scores BLEU-1 et ROUGE-1 pour évaluer les performances. InternLM 2 a atteint la plus grande précision dans la validation des réponses PubMedQA et la validation HealthFact, avec des scores de 98 et 92 respectivement.
Dans le benchmark EBMS, GPT-4 affiche les performances les plus fortes, avec des scores BLEU-1/ROUGE-1 de 16,36/16,33 respectivement. Claude-3.5 arrive juste derrière avec des scores de 14,22/15,82, mais ses résultats sont médiocres lors de la validation des réponses PubMedQA.
Llama 3 a une précision de 94 et 64 respectivement sur PubMedQA et HealthFact Verification, et un score BLEU-1/ROUGE-1 de 12,96/14,37. MMedIns-Llama 3 continue de surpasser les modèles existants, obtenant le score de précision le plus élevé sur la tâche de vérification des réponses PubMedQA avec InternLM 2, tandis que dans EMBS, MMedIns-Llama 3 atteint 11,99/12,90 en BLEU-1 et ROUGE-1. légèrement en retard sur GPT-4.
Implication de textes médicaux (NLI) : Le tableau 9 montre également les résultats de l'évaluation sur l'implication de textes médicaux (NLI), principalement MedNLI. Il existe deux méthodes de test, l'une est une tâche discriminante (sélection de la bonne réponse dans une liste de candidats), mesurée par l'exactitude, et l'autre est une tâche de génération (génération de réponses sous forme de texte libre), mesurée par la métrique BLEU/ROUGE.
InternLM 2 a le score le plus élevé parmi les LLM open source avec un score de 84. Pour le LLM à source fermée, GPT-4 et Claude-3.5 affichent des scores relativement élevés avec des précisions de 82 et 86 respectivement. Dans la tâche de génération, Llama 3 présente la plus grande cohérence avec la vérité terrain, avec des scores BLEU et ROUGE de 33,69/27,28. Mistral et Llama 3 ont réalisé des performances moyennes. GPT-4 suit de près avec des scores de 27,09/23,71, tandis que Claude-3,5 ne réussit pas bien dans la tâche de génération.
MMedIns-Llama 3 a la plus grande précision dans la tâche de discrimination avec un score de 84, mais est légèrement derrière Claude-3,5. MMedIns-Llama 3 est également performant dans la tâche de génération, avec un score BLEU/ROUGE de 37,56/32,17, ce qui est nettement meilleur que les autres modèles.
Tableau 9 : Résultats quantitatifs sur les tâches de vérification des faits et d'implication de texte. Les résultats sont mesurés par précision (ACC) et BLEU/ROUGE dans le tableau est l'abréviation de « vérification ».
En général, l'équipe de recherche a évalué six modèles traditionnels dans diverses dimensions de tâches. Les résultats de la recherche montrent que les LLM traditionnels actuels sont encore assez fragiles lorsqu'il s'agit de tâches cliniques. ce qui produira de graves déficits de performance dans des scénarios cliniques divers et complexes.
Dans le même temps, les résultats expérimentaux montrent également qu'en ajoutant davantage de textes de tâches cliniques à l'ensemble de données d'instructions pour renforcer la correspondance entre le LLM et l'application clinique réelle, les performances du LLM peuvent être considérablement améliorées.
Méthode de collecte de données et processus de formation
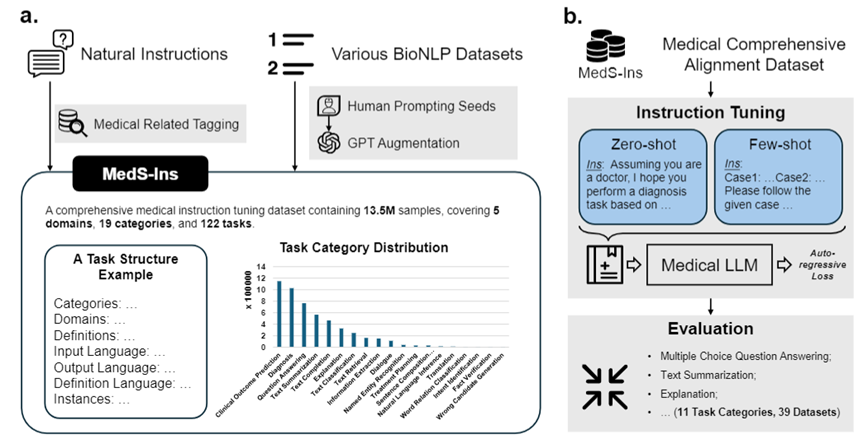
Cette section présentera le processus de formation en détail, comme le montre la figure 3b. La méthode spécifique est la même que celle des travaux précédents MMedLM et PMC-LLaMA, qui peuvent tous deux injecter les connaissances médicales correspondantes dans le modèle grâce à une formation autorégressive supplémentaire sur des corpus médicaux, les rendant ainsi plus performants dans différentes tâches en aval.
Plus précisément, l'équipe de recherche a commencé avec un modèle de base LLM multilingue (MMed-Llama 3) et l'a ensuite formé à l'aide des données de réglage fin des instructions de MedS-Ins.
Les données pour le réglage fin de l'instruction impliquent principalement deux aspects :
Données d'instruction naturelles filtrées médicalement : Premièrement, à partir des instructions surnaturelles, le plus grand ensemble de données d'instruction dans le champ naturel Filtrez les tâches liées à la médecine. Étant donné que Super-NaturalInstructions se concentre davantage sur différentes tâches de traitement du langage naturel dans des domaines généraux, la granularité de la classification du domaine médical est relativement grossière.
Tout d'abord, toutes les instructions des catégories « Soins de santé » et « Médecine » ont été extraites, puis des étiquettes de domaine plus détaillées y ont été ajoutées manuellement tandis que les catégories de tâches sont restées inchangées. En outre, de nombreux ensembles de données de réglage fin des instructions organisées dans un domaine général couvrent également certaines données médicales, telles que LIMA et ShareGPT.
Afin de filtrer la partie médicale de ces données, l'équipe de recherche a utilisé InsTag pour effectuer une classification grossière du domaine de chaque instruction. Plus précisément, InsTag est un LLM conçu pour étiqueter différents échantillons d'instructions. Étant donné une requête d'instruction, il analysera à quel domaine et à quelle tâche appartient l'instruction et, sur cette base, filtrera les échantillons étiquetés comme médicaux, médicaux ou biomédicaux.
Enfin, en filtrant l'ensemble des données d'instructions dans le domaine général, 37 tâches ont été collectées, avec un total de 75 373 échantillons.
Conseils pour construire des ensembles de données BioNLP existants : Il existe de nombreux excellents ensembles de données sur l'analyse de texte dans des scénarios cliniques parmi les ensembles de données existants. Cependant, étant donné que la plupart des ensembles de données sont collectés à des fins différentes, ils ne peuvent pas être directement utilisés pour former de grands modèles linguistiques. Cependant, ces tâches médicales de PNL existantes peuvent être intégrées à l’adaptation des instructions en les convertissant dans un format pouvant être utilisé pour entraîner des modèles génératifs.
Plus précisément, l’équipe de recherche a pris MIMIC-IV-Note comme exemple. MIMIC-IV-Note fournit des rapports structurés de haute qualité contenant à la fois des résultats et des conclusions, et la génération de résultats jusqu'à des conclusions est considérée comme une tâche classique de résumé de texte clinique. Écrivez d'abord manuellement des invites pour définir la tâche, par exemple : « Compte tenu des résultats détaillés du diagnostic par imagerie échographique, résumez les résultats en quelques mots. » Compte tenu de la diversité des besoins d'ajustement de l'instruction, l'équipe de recherche a demandé à 5 personnes d'utiliser indépendamment 3 méthodes différentes. invite à décrire une certaine tâche.
Cela a abouti à 15 invites de texte libres par tâche, garantissant une sémantique similaire mais une formulation et un formatage aussi diversifiés que possible. Ensuite, inspirées de l'auto-instruction, ces instructions écrites manuellement sont utilisées comme instructions de départ et il est demandé à GPT-4 de les réécrire en fonction de celles-ci pour obtenir des instructions plus diversifiées.
Grâce au processus ci-dessus, 85 tâches supplémentaires ont été présentées dans un format unifié de questions et réponses gratuites, et combinées aux données filtrées, un total de 13,5 millions d'échantillons de haute qualité ont été obtenus, couvrant 122 tâches, appelées MedS-Ins, et grâce à un peaufinage des instructions, un nouveau LLM médical de taille 8B a été formé, et les résultats ont montré que cette méthode améliorait considérablement la performance des tâches cliniques.
Dans le peaufinage de l'instruction, l'équipe de recherche s'est concentrée sur deux formes d'instruction :
Invite à échantillon nul : Ici, l'instruction de la tâche contient des descriptions sémantiques de la tâche comme invite, obligeant ainsi le modèle à répondre directement à la question en fonction de ses connaissances internes du modèle. Dans les MedS-Ins collectés, le contenu de « définition » de chaque tâche peut naturellement être utilisé comme entrée d'instruction de point zéro. Comme diverses définitions de tâches médicales sont couvertes, le modèle devrait apprendre la compréhension sémantique de diverses descriptions de tâches.
Astuce en quelques étapes : Ici, les instructions contiennent un petit nombre d'exemples qui permettent au modèle d'apprendre les exigences approximatives de la tâche à partir du contexte. De telles instructions peuvent être obtenues en échantillonnant simplement au hasard d'autres cas de l'ensemble de formation pour la même tâche et en les organisant à l'aide du modèle simple suivant :
Case1 : Entrée : {CASE1_INPUT}, Sortie : {CASE1_OUTPUT} ... CaseN : Entrée : {CASEN_INPUT}, Sortie : {CASEN_OUTPUT} {INSTRUCTION} Veuillez tirer les leçons des quelques cas pour voyez quel contenu vous devez produire. Entrée : {INPUT}
Discussion
Dans l'ensemble, cet article apporte plusieurs contributions importantes :
Benchmark d'évaluation complète - MedS-Bench
Le développement du LLM médical repose fortement sur des tests de référence de questions-réponses à choix multiples (MCQA). Cependant, ce cadre d'évaluation étroit ignore les véritables capacités du LLM dans une variété de scénarios cliniques complexes.
Par conséquent, dans ce travail, l'équipe de recherche présente MedS-Bench, un benchmark complet conçu pour évaluer les performances des LLM fermés et open source dans une variété de tâches cliniques, y compris celles qui nécessitent des données de modèles Tâche consistant à rappeler des faits à partir d'un corpus pré-entraîné ou à faire des inférences à partir d'un contexte donné.
Les résultats montrent que même si les LLM existants fonctionnent bien sur les critères MCQA, ils ont du mal à s'aligner sur la pratique clinique, en particulier dans des tâches telles que la recommandation et l'explication du traitement. Cette découverte met en évidence la nécessité de développer davantage de grands modèles de langage médical adaptés à un plus large éventail de scénarios cliniques et médicaux.
Ensemble complet de données d'ajustement des instructions - MedS-Ins
L'équipe de recherche a obtenu de manière approfondie des données de l'ensemble de données BioNLP existant et a converti ces échantillons dans un format unifié, à Parallèlement, une stratégie d'incitation semi-automatique a été utilisée pour construire et développer MedS-Ins, un nouvel ensemble de données d'ajustement des ordonnances médicales. Les travaux antérieurs sur les ensembles de données de réglage précis de l'enseignement se sont principalement concentrés sur la construction de paires questions-réponses à partir de conversations quotidiennes, d'examens ou de documents universitaires, ignorant souvent le texte généré à partir de la pratique clinique réelle.
En revanche, MedS-Ins intègre une gamme plus large de ressources de textes médicaux, dont 5 grandes zones de texte et 19 catégories de tâches. Cette analyse systématique de la composition des données facilite la compréhension des utilisateurs des limites des applications cliniques du LLM.
Modèle médical de grand langage - MMedIns-Llama 3
En termes de modèle, l'équipe de recherche l'a prouvé en effectuant une formation de mise au point de l'instruction sur MedS-Ins , il peut améliorer considérablement l'alignement du LLM médical open source avec les besoins cliniques.
Il convient de souligner que le modèle final MMedIns-Llama 3 est davantage un modèle de « preuve de concept ». Il utilise une échelle de paramètres moyenne de 8B. Le modèle final montre une compréhension approfondie de divers. tâches cliniques. et peut s'adapter de manière flexible à une variété de scénarios médicaux grâce à zéro ou à un petit nombre d'instructions sans avoir besoin d'une formation supplémentaire spécifique à la tâche.
Les résultats montrent que MMedIns-Llama 3 surpasse les LLM existants, notamment GPT-4, Claude-3.5, etc., dans des types de tâches cliniques spécifiques.
Limites existantes
Ici, l'équipe de recherche souhaite également souligner les limites de cet article et les améliorations futures possibles.
Tout d'abord, MedS-Bench ne couvre actuellement que 11 tâches cliniques, ce qui ne couvre pas entièrement la complexité de tous les scénarios cliniques. En outre, même si six LLM traditionnels ont été évalués, certains des derniers LLM manquaient toujours à l'analyse. Afin de remédier à ces limites, l'équipe de recherche prévoit de publier un classement médical LLM en même temps que cet article est publié, visant à encourager davantage de chercheurs à élargir et à améliorer continuellement le référentiel d'évaluation complet du LLM médical. En incluant davantage de catégories de tâches provenant de différentes sources de texte dans le processus d'évaluation, on espère acquérir une compréhension plus approfondie du développement et des limites d'utilisation des LLM en médecine.
Deuxièmement, bien que MedS-Ins couvre désormais un large éventail de tâches médicales, il est encore incomplet et manque de quelques scénarios médicaux pratiques. Pour résoudre ce problème, l’équipe de recherche a ouvert toutes les données et ressources collectées sur GitHub. J'espère sincèrement que davantage de cliniciens ou de chercheurs pourront travailler ensemble pour maintenir et élargir cet ensemble de données d'ajustement des instructions, similaire aux instructions surnaturelles dans le domaine général. L'équipe de recherche a fourni des instructions de téléchargement détaillées sur la page GitHub et remerciera par écrit tous les contributeurs qui ont participé à la mise à jour de l'ensemble de données lors de la mise à jour itérative de l'article.
Troisièmement, l'équipe de recherche prévoit d'ajouter plus de langues à MedS-Bench et MedS-Ins pour soutenir le développement de LLM médicaux multilingues plus puissants. Actuellement, ces ressources sont principalement centrées sur l'anglais, bien que certaines tâches multilingues soient incluses dans MedS-Bench et MedS-Ins. L’étendre à un plus large éventail de langues serait une orientation future prometteuse afin de garantir que les progrès récents en matière d’IA médicale puissent bénéficier équitablement à une région plus large et plus diversifiée.
Enfin, l'équipe de recherche a rendu tous les codes, données et processus d'évaluation open source. On espère que ce travail conduira au développement de LLM médicaux afin de se concentrer davantage sur la manière d’intégrer ces puissants modèles de langage à des applications cliniques réelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment flasher le téléphone Xiaomi
Comment flasher le téléphone Xiaomi
 Comment centrer un div en CSS
Comment centrer un div en CSS
 Comment ouvrir un fichier rar
Comment ouvrir un fichier rar
 Méthodes de lecture et d'écriture de fichiers Java DBF
Méthodes de lecture et d'écriture de fichiers Java DBF
 Comment résoudre le problème de l'absence du fichier msxml6.dll
Comment résoudre le problème de l'absence du fichier msxml6.dll
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées
 Numéro de téléphone mobile virtuel pour recevoir le code de vérification
Numéro de téléphone mobile virtuel pour recevoir le code de vérification
 album photo dynamique
album photo dynamique








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



