

De nombreux projets d’IA lancés avec promesse ne parviennent pas à mettre les voiles. Cela n'est généralement pas dû à la qualité des modèles d'apprentissage automatique (ML). Une mauvaise mise en œuvre et une mauvaise intégration du système font couler 90 % des projets. Les organisations peuvent sauvegarder leurs efforts en matière d’IA. Ils doivent adopter des pratiques MLOps adéquates et choisir le bon ensemble d’outils. Cet article traite des pratiques et des outils MLOps qui peuvent sauver des projets d'IA en ruine et stimuler les projets robustes, doublant potentiellement la vitesse de lancement des projets.

De nombreux projets d'IA lancés avec des promesses échouent. mettre les voiles. Cela n'est généralement pas dû à la qualité des modèles d'apprentissage automatique (ML). Une mauvaise mise en œuvre et une mauvaise intégration du système font couler 90 % des projets. Les organisations peuvent sauvegarder leurs efforts en matière d’IA. Ils doivent adopter des pratiques MLOps adéquates et choisir le bon ensemble d’outils. Cet article traite des pratiques et des outils MLOps qui peuvent sauver des projets d'IA en voie de disparition et stimuler les projets robustes, doublant potentiellement la vitesse de lancement des projets.
MLOps est un mélange de développement d'applications d'apprentissage automatique ( Dev) et activités opérationnelles (Ops). Il s'agit d'un ensemble de pratiques qui permettent d'automatiser et de rationaliser le déploiement de modèles ML. En conséquence, l'ensemble du cycle de vie du ML devient standardisé.
MLOps est complexe. Cela nécessite une harmonie entre la gestion des données, le développement de modèles et les opérations. Cela peut également nécessiter des changements technologiques et culturels au sein d’une organisation. S'il est adopté sans problème, MLOps permet aux professionnels d'automatiser des tâches fastidieuses, telles que l'étiquetage des données, et de rendre les processus de déploiement transparents. Il permet de garantir que les données du projet sont sécurisées et conformes aux lois sur la confidentialité des données.
Les organisations améliorent et font évoluer leurs systèmes ML grâce aux pratiques MLOps. Cela rend la collaboration entre les data scientists et les ingénieurs plus efficace et favorise l'innovation.
Les professionnels du MLOps transforment les défis commerciaux bruts en objectifs d'apprentissage automatique rationalisés et mesurables. Ils conçoivent et gèrent des pipelines de ML, garantissant des tests approfondis et une responsabilité tout au long du cycle de vie d'un projet d'IA.
Dans la phase initiale d'un projet d'IA appelée découverte de cas d'utilisation, les scientifiques des données travaillent avec les entreprises pour définir le problème. Ils le traduisent en un énoncé de problème de ML et fixent des objectifs et des KPI clairs.
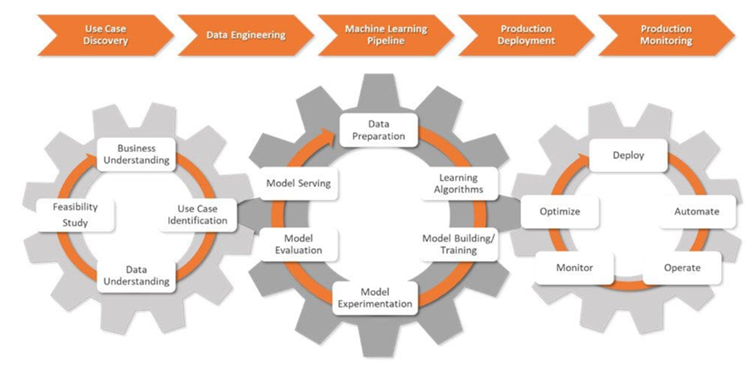
Ensuite, les data scientists font équipe avec les ingénieurs de données. Ils rassemblent des données provenant de diverses sources, puis nettoient, traitent et valident ces données.
Lorsque les données sont prêtes pour la modélisation, les data scientists conçoivent et déploient des pipelines de ML robustes, intégrés aux processus CI/CD. Ces pipelines prennent en charge les tests et l'expérimentation et aident à suivre les données, la traçabilité des modèles et les KPI associés dans toutes les expériences.
Lors de la étape de déploiement en production, les modèles de ML sont déployés dans l'environnement choisi : cloud, sur site ou hybride. .
Les data scientists surveillent les modèles et l'infrastructure, à l'aide de mesures clés pour repérer les changements dans les données ou les performances du modèle. Lorsqu'ils détectent des changements, ils mettent à jour les algorithmes, les données et les hyperparamètres, créant ainsi de nouvelles versions des pipelines ML. Ils gèrent également la mémoire et les ressources informatiques pour garantir l'évolutivité et le bon fonctionnement des modèles.
Imaginez un data scientist développant une application d'IA pour améliorer le processus de conception de produits d'un client. Cette solution accélérera la phase de prototypage en fournissant des alternatives de conception générées par l'IA et basées sur des paramètres spécifiés.
Les data scientists exécutent diverses tâches, de la conception du cadre à la surveillance du modèle d'IA en temps réel. Ils ont besoin des bons outils et de savoir comment les utiliser à chaque étape.
Au cœur d'une solution d'IA précise et adaptable se trouvent les bases de données vectorielles et ces outils clés pour améliorer les performances des LLM :
Guardrails est un package Python open source qui aide les data scientists à ajouter des contrôles de structure, de type et de qualité aux sorties LLM. Il gère automatiquement les erreurs et prend des mesures, comme réinterroger le LLM, si la validation échoue. Il applique également des garanties sur la structure et les types de sortie, tels que JSON.
Les data scientists ont besoin d'un outil pour indexer, rechercher et analyser efficacement de grands ensembles de données. C'est là qu'intervient LlamaIndex. Le framework offre des fonctionnalités puissantes pour gérer et extraire des informations à partir de vastes référentiels d'informations.
Le framework DUST permet de créer et de déployer des applications basées sur LLM sans code d'exécution. . Il facilite l'introspection des résultats du modèle, prend en charge les améliorations de conception itératives et suit les différentes versions de solutions.
Les data scientists expérimentent pour mieux comprendre et améliorer les modèles ML au fil du temps. Ils ont besoin d'outils pour mettre en place un système qui améliore la précision et l'efficacité des modèles sur la base de résultats réels.
MLflow est une centrale open source, utile pour superviser l'ensemble du cycle de vie du ML. Il fournit des fonctionnalités telles que le suivi des expériences, la gestion des versions de modèles et des capacités de déploiement. Cette suite permet aux data scientists d'enregistrer et de comparer les expériences, de surveiller les métriques et d'organiser les modèles et les artefacts de ML.
Comet ML est une plate-forme permettant de suivre, de comparer, d'expliquer et d'optimiser les modèles et les artefacts de ML. expériences. Les data scientists peuvent utiliser Comet ML avec Scikit-learn, PyTorch, TensorFlow ou HuggingFace : cela fournira des informations permettant d'améliorer les modèles de ML.
Amazon SageMaker couvre l'ensemble du cycle de vie de l'apprentissage automatique. Il permet d'étiqueter et de préparer les données, ainsi que de créer, former et déployer des modèles ML complexes. Grâce à cet outil, les data scientists déploient et mettent à l'échelle rapidement des modèles dans divers environnements.
Microsoft Azure ML est une plate-forme basée sur le cloud qui permet de rationaliser les flux de travail d'apprentissage automatique. Il prend en charge des frameworks tels que TensorFlow et PyTorch et peut également s'intégrer à d'autres services Azure. Cet outil aide les data scientists dans le suivi des expériences, la gestion des modèles et le déploiement.
DVC (data version control) est un outil open source destiné à gérer de grands ensembles de données et des expériences d'apprentissage automatique. Cet outil rend les flux de travail de science des données plus agiles, reproductibles et collaboratifs. DVC fonctionne avec les systèmes de contrôle de version existants tels que Git, simplifiant ainsi la manière dont les scientifiques des données suivent les modifications et partagent les progrès sur des projets d'IA complexes.
Besoin des scientifiques des données flux de travail optimisés pour obtenir des processus plus fluides et plus efficaces sur les projets d’IA. Les outils suivants peuvent vous aider :
Prefect est un outil open source moderne que les data scientists utilisent pour surveiller et orchestrer les flux de travail. Léger et flexible, il dispose d'options pour gérer les pipelines ML (Prefect Orion UI et Prefect Cloud).
Metaflow est un outil puissant pour gérer les flux de travail. Il est destiné à la science des données et à l’apprentissage automatique. Cela facilite la concentration sur le développement de modèles sans les tracas des complexités MLOps.
Kedro est un outil basé sur Python qui aide les data scientists à garder un projet reproductible, modulaire et facile à maintenir. Il applique les principes clés du génie logiciel à l’apprentissage automatique (modularité, séparation des préoccupations et versionnage). Cela aide les data scientists à créer des projets efficaces et évolutifs.
Les workflows ML nécessitent une gestion précise des données et l'intégrité du pipeline. Avec les bons outils, les data scientists restent maîtres de ces tâches et gèrent en toute confiance même les défis liés aux données les plus complexes.
Pachyderm aide les data scientists à automatiser la transformation des données et offre des fonctionnalités robustes pour la gestion des versions, le lignage et les pipelines de bout en bout des données. Ces fonctionnalités peuvent fonctionner de manière transparente sur Kubernetes. Pachyderm prend en charge l'intégration avec différents types de données : images, journaux, vidéos, CSV et plusieurs langages (Python, R, SQL et C/C). Il s'adapte pour gérer des pétaoctets de données et des milliers de tâches.
LakeFS est un outil open source conçu pour l'évolutivité. Il ajoute un contrôle de version de type Git au stockage d'objets et prend en charge le contrôle de version des données à l'échelle de l'exaoctet. Cet outil est idéal pour gérer de vastes lacs de données. Les data scientists utilisent cet outil pour gérer les lacs de données avec la même facilité qu'ils manipulent le code.
Les data scientists se concentrent sur le développement de modèles plus fiables. et des solutions de ML équitables. Ils testent des modèles pour minimiser les biais. Les bons outils les aident à évaluer les mesures clés, telles que la précision et l'AUC, à prendre en charge l'analyse des erreurs et la comparaison des versions, à documenter les processus et à s'intégrer de manière transparente dans les pipelines ML.
Deepchecks est un package Python qui les aide avec des modèles ML et la validation des données. Il facilite également les contrôles des performances des modèles, l'intégrité des données et les inadéquations de distribution.
Truera est une plate-forme moderne d'intelligence des modèles qui aide les data scientists à accroître la confiance et la transparence dans les modèles de ML. Grâce à cet outil, ils peuvent comprendre le comportement du modèle, identifier les problèmes et réduire les biais. Truera fournit des fonctionnalités pour le débogage des modèles, l'explicabilité et l'évaluation de l'équité.
Kolena est une plate-forme qui améliore l'alignement et la confiance des équipes grâce à des tests et un débogage rigoureux. Il fournit un environnement en ligne pour enregistrer les résultats et les informations. Il se concentre sur les tests unitaires et la validation du ML à grande échelle, ce qui est essentiel pour garantir des performances cohérentes des modèles dans différents scénarios.
Les data scientists ont besoin d'outils fiables pour déployer efficacement des modèles ML et fournir des prédictions de manière fiable. Les outils suivants les aident à réaliser des opérations de ML fluides et évolutives :
BentoML est une plateforme ouverte qui aide les data scientists à gérer les opérations de ML en production. Il permet de rationaliser le packaging des modèles et d'optimiser les charges de travail de service pour plus d'efficacité. Il permet également d'accélérer la configuration, le déploiement et la surveillance des services de prédiction.
Kubeflow simplifie le déploiement de modèles ML sur Kubernetes (localement, sur site ou dans le cloud). Avec cet outil, l’ensemble du processus devient simple, portable et évolutif. Il prend en charge tout, de la préparation des données à la diffusion de prédictions.
Les plates-formes MLOps de bout en bout sont essentielles pour optimiser le cycle de vie du machine learning, offrant une approche rationalisée au développement, au déploiement et à la gestion efficace des modèles ML. Voici quelques plates-formes leaders dans ce domaine :
Amazon SageMaker offre une interface complète qui aide les data scientists à gérer l'ensemble du cycle de vie du ML. Il rationalise le prétraitement des données, la formation des modèles et l'expérimentation, améliorant ainsi la collaboration entre les scientifiques des données. Avec des fonctionnalités telles que des algorithmes intégrés, le réglage automatisé des modèles et une intégration étroite avec les services AWS, SageMaker est un choix de premier ordre pour développer et déployer des solutions d'apprentissage automatique évolutives.
La plateforme Microsoft Azure ML crée un environnement collaboratif qui prend en charge divers langages et frameworks de programmation. Il permet aux data scientists d'utiliser des modèles prédéfinis, d'automatiser les tâches de ML et de s'intégrer de manière transparente à d'autres services Azure, ce qui en fait un choix efficace et évolutif pour les projets de ML basés sur le cloud.
Google Cloud Vertex AI fournit un environnement transparent pour le développement automatisé de modèles avec AutoML et l'entraînement de modèles personnalisés à l'aide de frameworks populaires. Les outils intégrés et l'accès facile aux services Google Cloud font de Vertex AI la solution idéale pour simplifier le processus de ML, en aidant les équipes de science des données à créer et à déployer des modèles sans effort et à grande échelle.
MLOps n'est pas juste un autre battage médiatique. Il s’agit d’un domaine important qui aide les professionnels à former et à analyser de gros volumes de données plus rapidement, plus précisément et plus facilement. Nous ne pouvons qu'imaginer comment cela évoluera au cours des dix prochaines années, mais il est clair que l'IA, le big data et l'automatisation commencent tout juste à prendre de l'ampleur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction à l'utilisation de la fonction stickline
Introduction à l'utilisation de la fonction stickline
 Que fait Python ?
Que fait Python ?
 Comment utiliser l'éditeur d'atomes
Comment utiliser l'éditeur d'atomes
 Étapes WeChat
Étapes WeChat
 qu'est-ce que la programmation Python
qu'est-ce que la programmation Python
 Les performances des micro-ordinateurs dépendent principalement de
Les performances des micro-ordinateurs dépendent principalement de
 Quel échange est EDX ?
Quel échange est EDX ?
 Quelles sont les commandes de nettoyage de disque ?
Quelles sont les commandes de nettoyage de disque ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



