
 interface Web
js tutoriel
Principaux KPI de développement logiciel que vous devriez suivre en 5
interface Web
js tutoriel
Principaux KPI de développement logiciel que vous devriez suivre en 5
Principaux KPI de développement logiciel que vous devriez suivre en 5

Gérer une équipe de développement logiciel n'est pas une mince affaire. Jusqu'à ce qu'il mène le projet à la ligne d'arrivée, un chef de projet d'ingénierie ne peut pas prendre de répit. C'est la raison pour laquelle les responsables de l'ingénierie logicielle recherchent des moyens d'améliorer les performances de leurs projets ainsi que de leurs équipes. Et c'est exactement là que des choses comme Kpi entrent en jeu sous le déguisement de Dieu.
Alors, qu’est-ce qu’un KPI ?
Les KPI sont comme le tracker de fitness de votre équipe : ils vous aident à voir où les choses fonctionnent bien et où vous devrez peut-être serrer les vis. Mais avec des millions de KPI, lesquels devriez-vous réellement vous soucier ? Décomposons le top 15 qui vous fera ressembler à un chef d'équipe de logiciels Rockstar et quelques-uns que vous voudrez peut-être abandonner.
Pourquoi s’embêter avec les KPI ?
Les KPI sont plus que de simples chiffres sur un écran : ils constituent votre feuille de route pour une meilleure prise de décision. En suivant les bonnes mesures, vous pouvez identifier les domaines dans lesquels votre équipe excelle et ceux qui peuvent être améliorés. C'est comme avoir une boule de cristal qui vous aide à prédire les délais d'un projet, les besoins en ressources et les obstacles potentiels.
Principaux KPI de développement logiciel à suivre en 2025
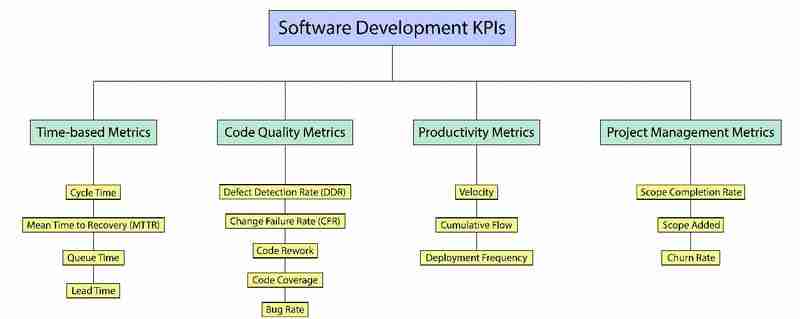
1.Temps de cycle : le compteur de vitesse de votre équipe !
Imaginez que vous participez à une course, mais au lieu que des voitures roulent sur une piste, votre équipe court pour accomplir des tâches dans un sprint.
La question est : à quelle vitesse peuvent-ils passer de la ligne de départ (« à faire ») à la ligne d'arrivée (« fait ») ?
C'est là qu'intervient le Cycle Time : c'est le chronomètre qui vous indique à quelle vitesse votre équipe parvient à accomplir les tâches.

Le Cycle Time est une question de vitesse, mais il ne s'agit pas seulement d'aller vite pour le plaisir.
Il s'agit d'efficacité et de savoir où se produisent les ralentissements. En moyenne, les équipes les plus performantes ont un temps de cycle d'environ 1,8 à 3,4 jours par tâche.
Si cela prend plus de temps, il est peut-être temps de regarder sous le capot et de voir ce qui cause le retard : il s'agit peut-être d'un goulot d'étranglement dans le processus, d'un trop grand nombre de tâches multitâches ou tout simplement d'une vieille dette technique.
Décomposons-le avec un exemple :
Supposons que votre équipe travaille sur une nouvelle fonctionnalité pour une application mobile. La tâche passe du retard à « en cours » lundi matin. Votre équipe de développement commence à coder, tester et envoyer des commits, et mercredi après-midi, la tâche est terminée et marquée « terminée ». C'est un temps de cycle de 3 jours.
Maintenant, disons qu'une autre tâche rencontre un problème : peut-être que la révision du code prend une éternité, ou qu'il y a une dépendance qui retarde les choses. Si cette tâche s'éternise pendant 7 ou 10 jours, c'est le signe que quelque chose ne va pas.
C'est ici que la magie opère : en suivant la durée du cycle, vous pouvez repérer des modèles.

Peut-être que votre équipe est très rapide sur certaines tâches mais enlisée sur d'autres. Grâce à ces informations, vous pouvez plonger dans les détails et comprendre comment rationaliser le processus. C'est peut-être aussi simple que de peaufiner le processus de révision du code ou de hiérarchiser les tâches différemment.
Le but ? Pour réduire le temps de cycle, afin que votre équipe accomplisse systématiquement des tâches comme des pros.
Et lorsque cela se produit, vous n'allez pas seulement vite, vous avancez intelligemment.

- ### Couverture du code : contrôle qualité de votre code
Quand il s'agit de code, il ne s'agit pas d'en écrire une tonne, il s'agit de s'assurer que ce que vous écrivez fonctionne réellement. C'est là que la couverture du code entre en jeu.
Considérez la couverture du code comme un bilan de santé de votre code.

Il vous indique la quantité de votre base de code qui est testée, afin que vous sachiez que vous détectez ces bugs sournois avant qu'ils ne deviennent un problème.
Dans le monde du développement logiciel, une bonne référence pour la couverture du code se situe autour de 70 à 80 %. Si vous y parvenez, vous vous en sortez plutôt bien.
Mais rappelez-vous que la perfection n'est pas l'objectif ici : une couverture à 100 %, c'est comme essayer d'attraper chaque grain de sable sur une plage.

Au lieu de cela, veillez à ce que les parties critiques de votre code soient couvertes.
Mettons les choses en perspective avec un exemple simple :
Imaginez que vous créez une nouvelle fonctionnalité pour un site de commerce électronique : disons qu'il s'agit d'un panier d'achat.

Vous avez écrit du code qui ajoute des articles au panier, calcule les totaux et traite les paiements. Maintenant, vous voulez vous assurer que tout cela fonctionne avant que les clients ne commencent à l'utiliser.
Vous rédigez des tests pour chaque partie :
Ajout d'articles au panier -- Vous testez pour voir si les articles sont ajoutés correctement.
Calcul des totaux - Vous vérifiez que les calculs sont corrects lorsque quelqu'un ajoute plusieurs éléments.
Traitement des paiements - Vous testez la passerelle de paiement pour vous assurer que les transactions se déroulent sans problème.
Si vos tests couvrent tous ces scénarios et qu'ils s'exécutent sans erreurs, vous disposez d'une solide couverture de code. Mais si vous ne testez pas le processus de paiement (peut-être parce qu'il est complexe ou prend plus de temps), vous laissez une partie critique de votre code non testée, ce qui revient à laisser votre porte ouverte la nuit.
En gardant un œil sur la couverture du code, vous vous assurez que la majeure partie de votre code est testée, ce qui réduit le risque que des bugs se faufilent en production. Il s'agit de détecter les problèmes le plus tôt possible, afin qu'ils ne se transforment pas en plaintes de clients plus tard.
3. Refonte du code : la roue de développement Hamster ?

Imaginez ceci : votre équipe de développement continue de réécrire les mêmes morceaux de code encore et encore. Au lieu de sprinter vers le progrès, ils sont coincés sur une roue de hamster, tournant en rond sans réellement avancer. C'est Code Rework en action, et c'est le signe que quelque chose ne va pas.
Idéalement, votre équipe devrait passer plus de temps à créer de nouvelles fonctionnalités et moins de temps à refaire ce qui a déjà été fait. Trop de refonte du code peut nuire à la productivité.
En fait, des études montrent que des retouches fréquentes peuvent consommer jusqu'à 40 % du temps d'un développeur - un temps qui pourrait être mieux consacré à l'innovation.
4. Taux d'échec des modifications (CFR) : le Bug-O-Meter ?

Considérez le taux d'échec des modifications (CFR) comme le « bug-o-meter » de votre équipe de développement. Il mesure la fréquence à laquelle vos modifications de code finissent par casser des éléments. Un CFR élevé, c'est comme avoir un bateau qui fuit : vous videz constamment de l'eau (corrigez des bugs) au lieu de naviguer en douceur (créez de nouvelles fonctionnalités intéressantes).
Dans un monde idéal, chaque modification que vous apportez à la base de code fonctionnerait parfaitement. Mais en réalité, les choses se cassent. Selon le rapport Accelerate State of DevOps, la moyenne du secteur pour le CFR est d'environ 16 à 30 %, ce qui signifie que sur 10 changements, 1 à 3 peuvent provoquer un problème. Si votre CFR dépasse ce chiffre, c'est le signe que votre code a besoin de plus d'attention avant de passer en production.

Exemple rapide :
Disons que votre équipe déploie une nouvelle fonctionnalité et qu'immédiatement les utilisateurs commencent à signaler des plantages. Vous fouillez dans les données et réalisez que 40 % de vos déploiements récents ont entraîné des problèmes. Aie! Ce CFR élevé signifie que votre équipe passera plus de temps à lutter contre les bugs et moins de temps à innover.
Le but ? Réduisez votre CFR en améliorant les tests et les révisions de code, afin que vous puissiez passer plus de temps à créer la prochaine grande nouveauté et moins de temps à réparer ce qui a déjà été expédié.
5. Taux de détection des défauts (DDR) : le tableau de bord de détection des bogues ?

Le taux de détection des défauts (DDR) est comme votre tableau de bord de détection des bogues - il vous indique le nombre de bogues que vous avez détectés avant que le code ne se répande par rapport au nombre de bogues qui passent après le lancement. Plus votre DDR est élevé, meilleur est votre jeu de test. Mais si d'autres bugs vous échappent et apparaissent en production, il est temps d'affiner vos outils de test.
Un bon DDR montre que votre processus de test est solide, visant généralement 85 % ou plus des bogues détectés avant la sortie. Si votre DDR est faible, c'est comme rater un tas de signaux d'alarme, pour le découvrir plus tard lorsque les utilisateurs commencent à se plaindre.
Exemple rapide :
Imaginez que vous publiez une nouvelle mise à jour de l'application. Lors des tests, vous détectez 8 bugs, mais après le lancement, les utilisateurs en signalent 5 autres. Cela vous donne un DDR de 8/13, soit environ 62 %. Pas génial. Cela signifie que vos tests ont manqué près de 40 % des bogues, ce qui indique clairement qu'il est temps de renforcer vos vérifications préalables à la publication.
Pour augmenter votre DDR, envisagez d'améliorer les tests automatisés, d'effectuer des révisions de code plus approfondies ou même d'effectuer davantage de tests d'acceptation des utilisateurs avant le grand lancement. Plus votre DDR est bon, plus vos utilisateurs sont satisfaits --- et moins de moments « uh-oh » après le lancement !
6. Taux de bugs : les signaux d'alarme dans votre code ?

Le taux de bugs mesure la fréquence à laquelle ces bugs embêtants apparaissent dans votre code. Un taux de bugs élevé peut être un gros signal d’alarme, signalant que le code est soit sorti précipitamment, soit écrit par quelqu’un qui apprend encore les ficelles du métier. Les données du secteur suggèrent que les équipes expérimentées visent généralement moins de 10 bogues pour 1 000 lignes de code.
Exemple rapide :
Votre équipe lance une nouvelle fonctionnalité, et en quelques heures, 15 bugs sont signalés. Si vous voyez régulièrement ce genre de chose, c'est le signe que les révisions ou les tests de code nécessitent plus d'attention --- ou que vos développeurs pourraient avoir besoin de plus de temps pour bien faire les choses.
7. Temps moyen de récupération (MTTR) : The Comeback Kid ?️
Le MTTR dépend de la rapidité avec laquelle votre équipe peut se remettre sur pied après une panne du système.

C'est votre chronomètre de reprise après sinistre, qui montre à quelle vitesse vous pouvez rebondir après un désastre. Idéalement, vous voulez un MTTR faible --- pensez à quelques minutes, pas à des heures.
Exemple rapide :
Votre site Web plante à 14h00 et votre équipe le remet en ligne à 14h15. Cela représente un MTTR de 15 minutes. S'il faut généralement une heure à votre équipe pour récupérer, il est peut-être temps d'affiner votre plan de réponse aux incidents.
8. Vitesse : le compteur de vitesse Sprint ?♂️

La vélocité mesure la quantité de travail effectué par votre équipe au cours d'un sprint. C'est votre indicateur de productivité, mais n'oubliez pas : ce n'est pas toujours la même chose entre les différentes équipes. Ce qui est important, c'est de suivre l'évolution de votre vitesse au fil du temps, et pas seulement de comparer des chiffres.
Exemple rapide :
Dernier sprint, votre équipe a réalisé 50 story points. Ce sprint, ils ont terminé 55. Une vitesse plus élevée pourrait signifier que votre équipe se met dans le bon sens --- ou cela pourrait signifier qu'elle a assumé des tâches plus faciles. Gardez un œil sur la cohérence ici.
9. Flux cumulé : le rapport de trafic pour les tâches ?
Le flux cumulatif vous montre où les tâches s'accumulent dans votre flux de travail.

Considérez-le comme un rapport de trafic pour votre projet : si les tâches restent trop longtemps bloquées dans une étape, vous vous retrouvez face à un goulot d'étranglement.
Exemple rapide :
Vous remarquez qu'un certain nombre de tâches traînent en "révision de code" tandis que d'autres se déroulent sans problème. Cela peut signifier que vous avez besoin de plus d'évaluateurs ou de critères mieux définis pour faire avancer les choses.
10. Fréquence de déploiement : le code prend la route ?️

La fréquence de déploiement suit la fréquence à laquelle votre équipe met le code en production. Des déploiements plus fréquents signifient généralement que votre équipe est agile et adaptable --- assurez-vous simplement de ne pas sacrifier la qualité au profit de la rapidité.
Exemple rapide :
Votre équipe déploie des mises à jour deux fois par semaine. C'est bien si ces mises à jour sont solides, mais si chaque déploiement entraîne des bugs, il est peut-être temps de revenir en arrière et de se concentrer sur la qualité.
11. Temps d'attente : La salle d'attente ?️

Le temps d'attente mesure la durée pendant laquelle les tâches restent en attente, par exemple lorsqu'elles sont bloquées dans la pile « à faire ». De longs temps d'attente peuvent signaler des inefficacités dans votre processus, comme un nombre insuffisant de membres de l'équipe gérant trop de tâches.
Exemple rapide :
Si les tâches attendent pendant des jours l'approbation du contrôle qualité, c'est le signe que soit l'équipe d'assurance qualité a besoin d'aide, soit que les critères pour faire avancer les tâches doivent être rationalisés.
12. Taux d’achèvement du périmètre : pouvez-vous terminer ce que vous avez commencé ? ?

Le taux d'achèvement du périmètre vous indique la part du travail que votre équipe prévoyait de faire est réellement effectuée. Si votre équipe laisse régulièrement des tâches inachevées, cela peut signifier qu'elle a les yeux plus gros que le ventre.
Exemple rapide :
Votre équipe avait prévu d'accomplir 20 tâches ce sprint, mais n'en a terminé que 15. Un faible taux d'achèvement comme celui-ci peut indiquer que votre équipe doit se fixer des objectifs plus réalistes ou mieux gérer son temps.
13. Portée ajoutée : Le fluage sournois ?

Portée ajoutée : suit la fréquence à laquelle de nouvelles tâches sont ajoutées après le démarrage d'un sprint. Un taux élevé ici peut être le signe d'une mauvaise planification ou, pire encore, d'une dérive de la portée --- lorsque les objectifs de votre projet continuent de s'étendre sans ajuster les délais ou les ressources.
Exemple rapide :
Vous démarrez un sprint avec 10 tâches, mais à la fin, vous en avez ajouté 5 de plus. Cela représente une augmentation de 50 % de la portée, ce qui peut signifier que votre équipe n'évalue pas suffisamment le travail lors de la planification.
14. Délai : le temps presse ⏰
Le délai d'exécution mesure le temps total écoulé entre la création d'une tâche et son achèvement. C'est comme le parcours complet de l'idée à l'exécution. Un délai de livraison plus court signifie généralement que votre équipe est efficace, tandis qu'un délai plus long peut signaler des retards ou des goulots d'étranglement dans votre processus.
Exemple rapide :
Une demande de fonctionnalité arrive et il faut deux semaines pour passer du concept au déploiement. Si des tâches similaires prenaient auparavant une semaine, il est temps d'enquêter sur ce qui ralentit les choses --il y a peut-être des retards d'approbation ou trop de transferts entre les équipes.
Lisez également : Délai de mise en œuvre des modifications : une analyse approfondie des métriques DORA et de leur impact sur la livraison de logiciels
15. Taux de désabonnement : faites tourner vos roues ?

Churn Rate suit la fréquence à laquelle votre code est réécrit ou modifié de manière significative peu de temps après son écriture. Un taux de désabonnement élevé peut être le signe que votre approche initiale n'était pas tout à fait correcte ou que les exigences changent trop.
Exemple rapide :
Votre équipe écrit une fonctionnalité, et en une semaine, elle doit en réécrire la moitié car la mise en œuvre initiale n'a pas répondu aux besoins. Si cela continue, c'est le signe qu'il faut consacrer plus de temps à la planification ou que les exigences doivent être plus claires dès le départ.
Quels KPI devez-vous surveiller ? Les indicateurs indispensables pour votre liste de contrôle de réussite ?

Vous vous demandez quels KPI méritent votre attention ? Concentrez-vous sur ceux qui vous donnent une image complète des performances et des progrès de votre équipe. Attention :
Efficacité du codage : avec quelle rapidité et fluidité votre code découle de "Hé, j'ai écrit ceci !" à "Wow, ça marche!"
Mesures de collaboration : dans quelle mesure votre équipe joue de manière synchronisée --- comme un groupe bien répété ou une équipe de nage synchronisée.
Mesures de prévisibilité : avec quelle précision vous pouvez prévoir les résultats du projet, rendant vos prévisions aussi fiables qu'une application météo (mais plus précises !).
Mesures de fiabilité : la solidité de votre code et la capacité de vos tests à détecter ces bogues sournois avant qu'ils ne deviennent des obstacles.
Ces KPI vous aident à éviter les surprises et à maintenir vos projets sur la bonne voie. Considérez-les comme les éléments essentiels de votre boîte à outils de réussite : pas de superflu, juste les bonnes choses !
Pour conclure : les métriques DORA du Middleware - Votre BFF de suivi des KPI ! ?
Voici donc la vérité : les KPI ne sont pas que des chiffres : ils sont votre arme secrète pour une prise de décision intelligente. Il vous aide à naviguer dans les méandres de votre productivité en ingénierie comme un pro. Et lorsque vous ajoutez les métriques DORA de Middleware à l’ensemble, vous obtenez une équipe imbattable. Le middleware élimine les incertitudes en suivant sans effort les métriques DORA telles que la fréquence de déploiement, le délai d'exécution, le taux d'échec des modifications et le temps moyen de récupération.
C'est comme avoir un acolyte personnel qui garde un œil sur vos KPI et s'assure que vous êtes toujours sur la bonne voie. Avec Middleware, vous ne vous contentez pas de réagir aux problèmes : vous les anticipez et orientez votre développement logiciel vers le succès. Consultez notre dépôt open source !
 middlewarehq
/
intergiciel
middlewarehq
/
intergiciel
 middlewarehq
/
intergiciel
middlewarehq
/
intergiciel
✨ Plateforme de métriques DORA open source pour les équipes d'ingénierie ✨

Gestion de l'ingénierie open source qui libère le potentiel des développeurs





Rejoignez notre communauté Open Source
Présentation
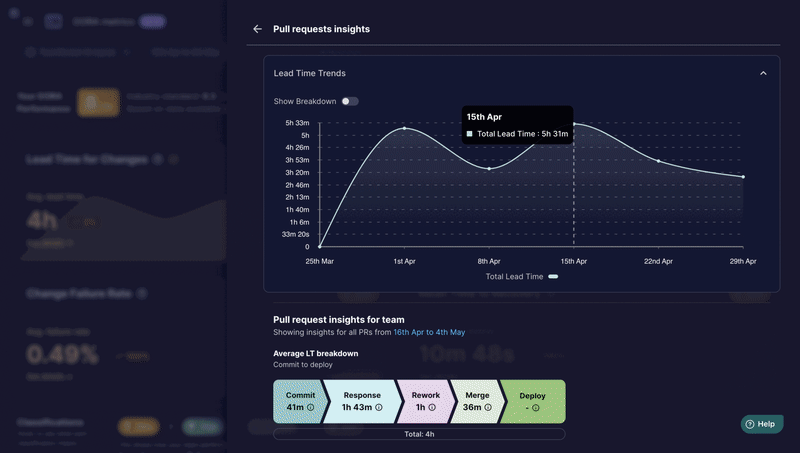
Middleware est un outil open source conçu pour aider les responsables de l'ingénierie à mesurer et analyser l'efficacité de leurs équipes à l'aide des métriques DORA. Les métriques DORA sont un ensemble de quatre valeurs clés qui fournissent des informations sur les performances de livraison de logiciels et l'efficacité opérationnelle.
Ils sont :
- Fréquence de déploiement : fréquence des déploiements de code en production ou dans un environnement opérationnel.
- Délai d'exécution des modifications : le temps nécessaire pour qu'un engagement soit mis en production.
- Mean Time to Restore : le temps nécessaire pour restaurer le service après un incident ou une panne.
- Taux d'échec des modifications : pourcentage de déploiements qui entraînent des échecs ou nécessitent une correction.
Table des matières
-
Intergiciel - Open Source
- Caractéristiques
-
Démarrage rapide
- Installation du middleware
- Dépannage
-
Configuration du développeur
- Utiliser Gitpod
- Utiliser Docker
- Configuration manuelle
- Utilisation
- Comment nous calculons DORA
- Feuille de route
- Consignes de contribution
- …
FAQ
- ### Qu'est-ce qu'un KPI de développement logiciel ?
Un KPI (Key Performance Indicator) de développement logiciel est une valeur mesurable utilisée pour évaluer l'efficacité et l'efficience des processus de développement, y compris des mesures telles que la qualité du code, la fréquence de déploiement et les délais. Les KPI aident à évaluer les progrès vers des objectifs spécifiques et à améliorer les performances globales.
- ### Quels outils dois-je utiliser pour suivre les KPI ?
Pour suivre les KPI, y compris les métriques DORA, utilisez Middleware pour un suivi complet des performances, ainsi que Jira pour la gestion de projet et GitHub pour des informations sur le code.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Remplacer les caractères de chaîne en javascript
Mar 11, 2025 am 12:07 AM
Remplacer les caractères de chaîne en javascript
Mar 11, 2025 am 12:07 AM
Remplacer les caractères de chaîne en javascript
 jQuery Vérifiez si la date est valide
Mar 01, 2025 am 08:51 AM
jQuery Vérifiez si la date est valide
Mar 01, 2025 am 08:51 AM
jQuery Vérifiez si la date est valide
 jQuery obtient un rembourrage / marge d'élément
Mar 01, 2025 am 08:53 AM
jQuery obtient un rembourrage / marge d'élément
Mar 01, 2025 am 08:53 AM
jQuery obtient un rembourrage / marge d'élément

 10 vaut la peine de vérifier les plugins jQuery
Mar 01, 2025 am 01:29 AM
10 vaut la peine de vérifier les plugins jQuery
Mar 01, 2025 am 01:29 AM
10 vaut la peine de vérifier les plugins jQuery
 Http débogage avec le nœud et le http-console
Mar 01, 2025 am 01:37 AM
Http débogage avec le nœud et le http-console
Mar 01, 2025 am 01:37 AM
Http débogage avec le nœud et le http-console
 Tutoriel de configuration de l'API de recherche Google personnalisé
Mar 04, 2025 am 01:06 AM
Tutoriel de configuration de l'API de recherche Google personnalisé
Mar 04, 2025 am 01:06 AM
Tutoriel de configuration de l'API de recherche Google personnalisé
 jQuery Ajouter une barre de défilement à div
Mar 01, 2025 am 01:30 AM
jQuery Ajouter une barre de défilement à div
Mar 01, 2025 am 01:30 AM
jQuery Ajouter une barre de défilement à div
