

Web Scraping un Go

Premiers pas
Tout d'abord, nous devons avoir installé Go, instructions pour télécharger et installer Go.
Nous créons un nouveau dossier pour le projet, passons au répertoire et exécutons la commande suivante :
go mod init scraper
? La commande go mod init est utilisée pour initialiser un nouveau module Go dans le répertoire où il est exécuté et crée un fichier go.mod pour suivre les dépendances du code. Gestion des dépendances
Installons maintenant Colibri :
go get github.com/gonzxlez/colibri
? Colibri est un package Go qui nous permet d'explorer et d'extraire des données structurées sur le Web à l'aide d'un ensemble de règles définies en JSON. Référentiel
Règles d'extraction
Nous définissons les règles que colibri utilisera pour extraire les données dont nous avons besoin. Documentation
Nous allons faire une requête HTTP à l'URL https://pkg.go.dev/search?q=xpath qui contient les résultats d'une requête pour les packages Go liés à XPath dans les packages Go.
À l'aide des outils de développement inclus dans notre navigateur Web, nous pouvons inspecter la structure HTML de la page. Quels sont les outils de développement de navigateur ?
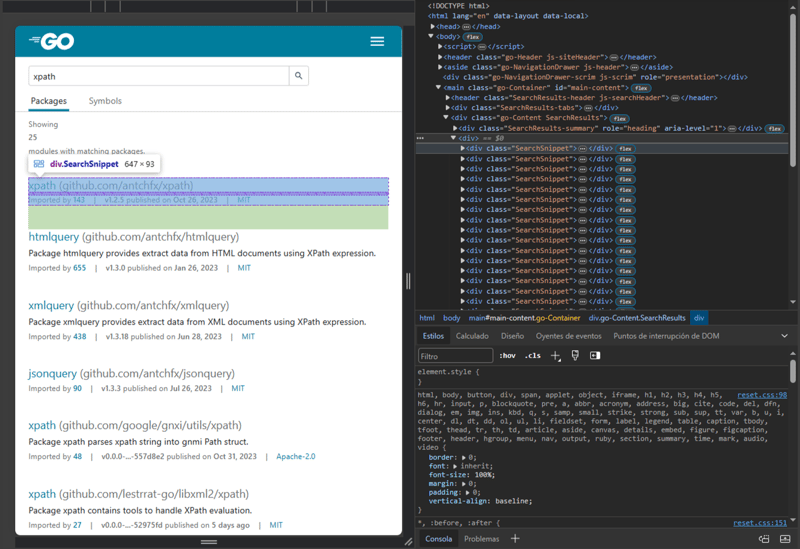
<div class="SearchSnippet">
<div class="SearchSnippet-headerContainer">
<h2>
<a href="/github.com/antchfx/xpath" data-gtmc="search result" data-gtmv="0" data-test-id="snippet-title">
xpath
<span class="SearchSnippet-header-path">(github.com/antchfx/xpath)</span>
</a>
</h2>
</div>
<div class="SearchSnippet-infoLabel">
<a href="/github.com/antchfx/xpath?tab=importedby" aria-label="Go to Imported By">
<span class="go-textSubtle">Imported by </span><strong>143</strong>
</a>
<span class="go-textSubtle">|</span>
<span class="go-textSubtle">
<strong>v1.2.5</strong> published on <span data-test-id="snippet-published"><strong>Oct 26, 2023</strong></span>
</span>
<span class="go-textSubtle">|</span>
<span data-test-id="snippet-license">
<a href="/github.com/antchfx/xpath?tab=licenses" aria-label="Go to Licenses">
MIT
</a>
</span>
</div>
</div>
Fragment de la structure HTML qui représente un résultat de la requête.
Ensuite nous avons besoin d'un sélecteur « packages » qui trouvera tous les éléments div dans le HTML avec la classe SearchSnippet, à partir de ces éléments un sélecteur « name” prendra le texte de l'élément a à l'intérieur d'un élément h2 et un sélecteur « path" prendra la valeur de l'attribut href de l'élément a au sein d'un h2 élément . Autrement dit, « name » prendra le nom du package Go et « path » le chemin du package :)
{
"method": "GET",
"url": "https://pkg.go.dev/search?q=xpath",
"timeout": 10000,
"selectors": {
"packages": {
"expr": "div.SearchSnippet",
"all": true,
"type": "css",
"selectors": {
"name": "//h2/a/text()",
"path": "//h2/a/@href"
}
}
}
}
- méthode : précise la méthode HTTP (GET, POST, PUT, ...).
- url : URL de la requête.
- timeout : délai d'expiration en millisecondes pour la requête HTTP.
-
sélecteurs : sélecteurs.
-
« packages » : est le nom du sélecteur.
- expr : expression du sélecteur.
- all: précise que tous les éléments correspondant à l'expression doivent être trouvés.
- type : le type de l'expression, dans ce cas un sélecteur CSS.
-
sélecteurs : sélecteurs imbriqués.
- « nom » et « chemin » sont les noms des sélecteurs et leurs valeurs sont des expressions, dans ce cas des expressions XPath.
-
« packages » : est le nom du sélecteur.
Coder en Go
Nous sommes prêts à créer un fichier scraper.go, à importer les packages nécessaires et à définir la fonction principale :
package main
import (
"encoding/json"
"fmt"
"github.com/gonzxlez/colibri"
"github.com/gonzxlez/colibri/webextractor"
)
var rawRules = `{
"method": "GET",
"url": "https://pkg.go.dev/search?q=xpath",
"timeout": 10000,
"selectors": {
"packages": {
"expr": "div.SearchSnippet",
"all": true,
"type": "css",
"selectors": {
"name": "//h2/a/text()",
"path": "//h2/a/@href"
}
}
}
}`
func main() {
we, err := webextractor.New()
if err != nil {
panic(err)
}
var rules colibri.Rules
err = json.Unmarshal([]byte(rawRules), &rules)
if err != nil {
panic(err)
}
output, err := we.Extract(&rules)
if err != nil {
panic(err)
}
fmt.Println("URL:", output.Response.URL())
fmt.Println("Status code:", output.Response.StatusCode())
fmt.Println("Content-Type", output.Response.Header().Get("Content-Type"))
fmt.Println("Data:", output.Data)
}
? WebExtractor sont des interfaces par défaut pour Colibri prêtes à commencer à explorer ou à extraire des données sur le Web.
En utilisant la fonction New de webextractor, nous générons une structure Colibri avec ce qui est nécessaire pour commencer l'extraction des données.
Ensuite, nous convertissons nos règles en JSON en structure Rules et appelons la méthode Extract en envoyant les règles sous forme d'arguments.
Nous obtenons la sortie et l'URL de la réponse HTTP, le code d'état HTTP, le type de contenu de la réponse et les données extraites avec les sélecteurs sont imprimés à l'écran. Voir la documentation sur la structure de sortie.
Nous exécutons la commande suivante :
go mod tidy
? La commande go mod Tidy garantit que les dépendances du go.mod correspondent au code source du module.
Enfin nous compilons et exécutons notre code en Go avec la commande :
go run scraper.go
Conclusion
Dans cet article, nous avons appris comment effectuer du Web Scraping dans Go à l'aide du package Colibri, en définissant des règles d'extraction avec les sélecteurs CSS et XPath. Colibri apparaît comme un outil pour ceux qui cherchent à automatiser la collecte de données Web dans Go. Son approche basée sur des règles et sa facilité d'utilisation en font une option attrayante pour les développeurs de tous niveaux d'expérience.
En bref, Web Scraping in Go est une technique puissante et polyvalente qui peut être utilisée pour extraire des informations d'un large éventail de sites Web. Il est important de souligner que le Web Scraping doit être effectué de manière éthique, en respectant les termes et conditions des sites Web et en évitant de surcharger leurs serveurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1676
1676
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Golang vs Python: performance et évolutivité
Apr 19, 2025 am 12:18 AM
Golang vs Python: performance et évolutivité
Apr 19, 2025 am 12:18 AM
Golang est meilleur que Python en termes de performances et d'évolutivité. 1) Les caractéristiques de type compilation de Golang et le modèle de concurrence efficace le font bien fonctionner dans des scénarios de concurrence élevés. 2) Python, en tant que langue interprétée, s'exécute lentement, mais peut optimiser les performances via des outils tels que Cython.
 Golang et C: concurrence vs vitesse brute
Apr 21, 2025 am 12:16 AM
Golang et C: concurrence vs vitesse brute
Apr 21, 2025 am 12:16 AM
Golang est meilleur que C en concurrence, tandis que C est meilleur que Golang en vitesse brute. 1) Golang obtient une concurrence efficace par le goroutine et le canal, ce qui convient à la gestion d'un grand nombre de tâches simultanées. 2) C Grâce à l'optimisation du compilateur et à la bibliothèque standard, il offre des performances élevées près du matériel, adaptées aux applications qui nécessitent une optimisation extrême.
 Partage avec Go: un guide du débutant
Apr 26, 2025 am 12:21 AM
Partage avec Go: un guide du débutant
Apr 26, 2025 am 12:21 AM
GOISIDEALFORBEGINNERNERS et combinant pour pourcloudandNetWorkServicesDuetOtssimplicity, Efficiency, andCurrencyFeatures.1) InstallgofromTheofficialwebsiteandverifywith'goversion'..2)
 Golang vs C: Performance et comparaison de la vitesse
Apr 21, 2025 am 12:13 AM
Golang vs C: Performance et comparaison de la vitesse
Apr 21, 2025 am 12:13 AM
Golang convient au développement rapide et aux scénarios simultanés, et C convient aux scénarios où des performances extrêmes et un contrôle de bas niveau sont nécessaires. 1) Golang améliore les performances grâce à des mécanismes de collecte et de concurrence des ordures, et convient au développement de services Web à haute concurrence. 2) C réalise les performances ultimes grâce à la gestion manuelle de la mémoire et à l'optimisation du compilateur, et convient au développement du système intégré.
 Golang vs Python: différences et similitudes clés
Apr 17, 2025 am 12:15 AM
Golang vs Python: différences et similitudes clés
Apr 17, 2025 am 12:15 AM
Golang et Python ont chacun leurs propres avantages: Golang convient aux performances élevées et à la programmation simultanée, tandis que Python convient à la science des données et au développement Web. Golang est connu pour son modèle de concurrence et ses performances efficaces, tandis que Python est connu pour sa syntaxe concise et son écosystème de bibliothèque riche.
 Golang et C: les compromis en performance
Apr 17, 2025 am 12:18 AM
Golang et C: les compromis en performance
Apr 17, 2025 am 12:18 AM
Les différences de performance entre Golang et C se reflètent principalement dans la gestion de la mémoire, l'optimisation de la compilation et l'efficacité du temps d'exécution. 1) Le mécanisme de collecte des ordures de Golang est pratique mais peut affecter les performances, 2) la gestion manuelle de C et l'optimisation du compilateur sont plus efficaces dans l'informatique récursive.
 La course de performance: Golang vs C
Apr 16, 2025 am 12:07 AM
La course de performance: Golang vs C
Apr 16, 2025 am 12:07 AM
Golang et C ont chacun leurs propres avantages dans les compétitions de performance: 1) Golang convient à une concurrence élevée et à un développement rapide, et 2) C fournit des performances plus élevées et un contrôle fin. La sélection doit être basée sur les exigences du projet et la pile de technologie d'équipe.
 Golang contre Python: les avantages et les inconvénients
Apr 21, 2025 am 12:17 AM
Golang contre Python: les avantages et les inconvénients
Apr 21, 2025 am 12:17 AM
GolangisidealforBuildingsCalableSystemsDuetoitSefficiency and Concurrency, tandis que les Implicites de l'Indrecosystem et le Golang'sDesignenCourageSlecElNCORES
