

Alors que l'IA continue de façonner notre façon de travailler et d'interagir avec la technologie, de nombreuses entreprises recherchent des moyens d'exploiter leurs propres données au sein d'applications intelligentes. Si vous avez utilisé des outils comme ChatGPT ou Azure OpenAI, vous savez déjà comment l'IA générative peut améliorer les processus et améliorer l'expérience utilisateur. Cependant, pour des réponses réellement personnalisées et pertinentes, vos applications doivent intégrer vos données propriétaires.
C'est là qu'intervient la génération de récupération augmentée (RAG), fournissant une approche structurée pour intégrer la récupération de données avec des réponses basées sur l'IA. Avec des frameworks comme LlamaIndex, vous pouvez facilement intégrer cette fonctionnalité dans vos solutions, libérant ainsi tout le potentiel de vos données d'entreprise.
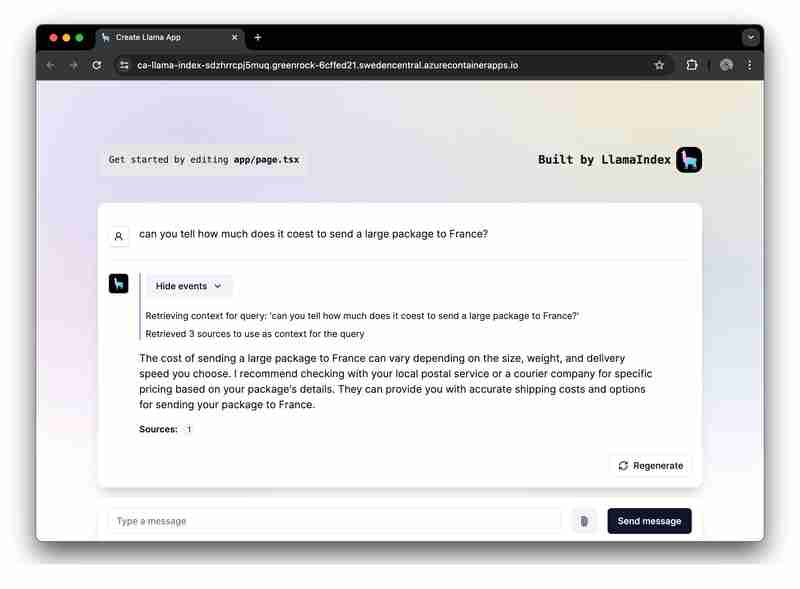
Vous souhaitez exécuter et explorer rapidement l'application ? Cliquez ici.
Retrieval-Augmented Generation (RAG) est un cadre de réseau neuronal qui améliore la génération de texte IA en incluant un composant de récupération pour accéder aux informations pertinentes et intégrer vos propres données. Il se compose de deux parties principales :
Le récupérateur trouve les documents pertinents et le générateur les utilise pour créer des réponses plus précises et informatives. Cette combinaison permet au modèle RAG d'exploiter efficacement les connaissances externes, améliorant ainsi la qualité et la pertinence du texte généré.
Pour implémenter un système RAG à l'aide de LlamaIndex, suivez ces étapes générales :
Pour un exemple pratique, nous avons fourni un exemple d'application pour démontrer une implémentation complète de RAG à l'aide d'Azure OpenAI.
Nous allons maintenant nous concentrer sur la création d'une application RAG à l'aide de LlamaIndex.ts (l'implémentation TypeScipt de LlamaIndex) et Azure OpenAI, et la déployer en tant qu'applications Web sans serveur sur Azure Container Apps.
Vous trouverez le projet de démarrage sur GitHub. Nous vous recommandons de créer ce modèle afin de pouvoir le modifier librement en cas de besoin :

L'application de projet de démarrage est construite sur la base de l'architecture suivante :

어떤 리소스가 배포되는지에 대한 자세한 내용은 모든 샘플에 포함된 infra 폴더를 확인하세요.
샘플 애플리케이션에는 두 가지 워크플로에 대한 논리가 포함되어 있습니다.
데이터 수집: 데이터를 가져와 벡터화하고 검색 색인을 생성합니다. PDF나 Word 파일과 같은 파일을 더 추가하려면 여기에서 추가해야 합니다.
npm run generate
프롬프트 요청 제공: 앱은 사용자 프롬프트를 수신하여 Azure OpenAI로 보내고, 벡터 인덱스를 검색기로 사용하여 이러한 프롬프트를 보강합니다.
샘플을 실행하기 전에 필요한 Azure 리소스를 프로비저닝했는지 확인하세요.
GitHub Codespace에서 GitHub 템플릿을 실행하려면
을 클릭하세요.
Codespaces 인스턴스의 터미널에서 Azure 계정에 로그인합니다.
azd auth login
단일 명령을 사용하여 샘플 애플리케이션을 Azure에 프로비저닝, 패키지 및 배포합니다.
azd up
애플리케이션을 로컬에서 실행하고 사용해 보려면 npm 종속성을 설치하고 앱을 실행하세요.
npm install npm run dev
앱은 Codespaces 인스턴스의 포트 3000 또는 브라우저의 http://localhost:3000에서 실행됩니다.
이 가이드에서는 Microsoft Azure에 배포된 LlamaIndex.ts 및 Azure OpenAI를 사용하여 서버리스 RAG(Retrieval-Augmented Generation) 애플리케이션을 구축하는 방법을 보여주었습니다. 이 가이드를 따르면 Azure의 인프라와 LlamaIndex의 기능을 활용하여 데이터를 기반으로 상황에 맞게 풍부한 응답을 제공하는 강력한 AI 애플리케이션을 만들 수 있습니다.
이 시작 애플리케이션으로 여러분이 무엇을 구축할지 기대됩니다. 최신 업데이트와 기능을 받으려면 자유롭게 포크하고 GitHub 저장소에 좋아요를 누르세요.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre les K8 et Docker
La différence entre les K8 et Docker
 Comment utiliser le stockage local
Comment utiliser le stockage local
 Comment défendre les serveurs cloud contre les attaques DDoS
Comment défendre les serveurs cloud contre les attaques DDoS
 Comment réparer la passerelle par défaut de l'ordinateur n'est pas disponible
Comment réparer la passerelle par défaut de l'ordinateur n'est pas disponible
 Analyse comparative de vscode et visual studio
Analyse comparative de vscode et visual studio
 Que signifie Linux df -h ?
Que signifie Linux df -h ?
 Comment trader sur Binance
Comment trader sur Binance
 webstorm a été remplacé par la version chinoise
webstorm a été remplacé par la version chinoise








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



