

Qui ne voudrait pas de réponses instantanées à partir de ses documents ? C'est exactement ce que font les chatbots RAG : combiner la récupération avec la génération d'IA pour des réponses rapides et précises !
Dans ce guide, je vais vous montrer comment créer un chatbot en utilisant la Retrieval-Augmented Generation (RAG) avec LangChain et Streamlit. Ce chatbot extraira les informations pertinentes d'une base de connaissances et utilisera un modèle de langage pour générer des réponses.
Je vous guiderai à travers chaque étape, en vous proposant plusieurs options de génération de réponses, que vous utilisiez OpenAI, Gemini ou Fireworks, garantissant ainsi une flexibilité et solution rentable.
RAG est une méthode qui combine la récupération et la génération pour fournir des réponses de chatbot plus précises et plus contextuelles. Le processus de récupération extrait les documents pertinents d'une base de connaissances, tandis que le processus de génération utilise un modèle linguistique pour créer une réponse cohérente basée sur le contenu récupéré. Cela garantit que votre chatbot peut répondre aux questions en utilisant les données les plus récentes, même si le modèle de langage lui-même n'a pas été spécifiquement formé sur ces informations.
Imaginez que vous ayez un assistant personnel qui ne connaît pas toujours la réponse à vos questions. Ainsi, lorsque vous posez une question, ils parcourent des livres et trouvent des informations pertinentes (récupération), puis ils résument ces informations et vous les racontent dans leurs propres mots (génération). C’est essentiellement ainsi que fonctionne RAG, combinant le meilleur des deux mondes.
Dans un organigramme, le processus RAG ressemblera un peu à ceci :
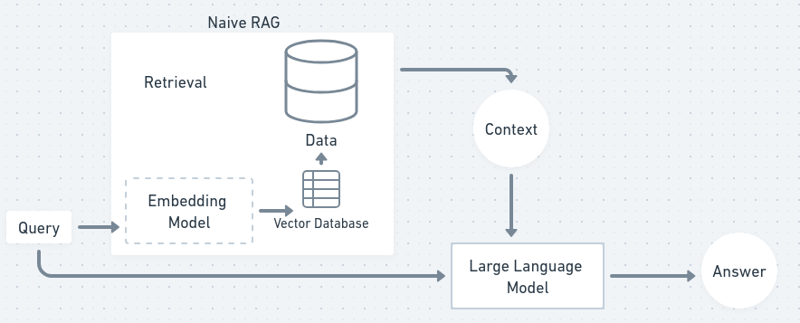
Maintenant, commençons et procurez-vous notre propre chatbot !
Nous utiliserons principalement Python dans ce TUTO, si vous êtes responsable JS vous pouvez suivre les explications et parcourir la documentation de langchain js.
Tout d'abord, nous devons configurer notre environnement de projet. Cela inclut la création d'un répertoire de projet, l'installation de dépendances et la configuration de clés API pour différents modèles de langage.
Commencez par créer un dossier de projet et un environnement virtuel :
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
Ensuite, créez un fichier exigences.txt pour lister toutes les dépendances nécessaires :
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
Maintenant, installez ces dépendances :
pip install -r requirements.txt
Nous utiliserons OpenAI, Gemini ou Fireworks pour la génération de réponses du chatbot. Vous pouvez choisir n’importe lequel d’entre eux en fonction de vos préférences.
Ne vous inquiétez pas si vous expérimentez, Fireworks fournit gratuitement 1 $ de clés API, et le modèle gemini-1.5-flash est également gratuit dans une certaine mesure !
Configurez un fichier .env pour stocker les clés API de votre modèle préféré :
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
Assurez-vous de vous inscrire à ces services et d'obtenir vos clés API. Gemini et Fireworks proposent des niveaux gratuits, tandis que OpenAI facture en fonction de l'utilisation.
Pour donner du contexte au chatbot, nous devrons traiter les documents et les diviser en morceaux gérables. Ceci est important car les textes volumineux doivent être décomposés pour l'intégration et l'indexation.
Créez un nouveau script Python appelé document_processor.py pour gérer le traitement des documents :
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
Ce script charge un fichier texte et le divise en morceaux plus petits d'environ 1 000 caractères avec un léger chevauchement pour garantir qu'aucun contexte n'est perdu entre les morceaux. Une fois traités, les documents sont prêts à être intégrés et indexés.
Maintenant que nos documents sont fragmentés, l'étape suivante consiste à les convertir en intégrations (représentations numériques du texte) et à les indexer pour une récupération rapide. (car les machines comprennent plus facilement les chiffres que les mots)
Créez un autre script appelé embedding_indexer.py :
pip install -r requirements.txt
Dans ce script, les intégrations sont créées à l'aide d'un modèle Hugging Face (all-MiniLM-L6-v2). Nous stockons ensuite ces intégrations dans un FAISS vectorstore, ce qui nous permet de récupérer rapidement des morceaux de texte similaires en fonction d'une requête.
Voici la partie passionnante : combiner la récupération et la génération de langage ! Vous allez maintenant créer une chaîne RAG qui récupère les morceaux pertinents du vectorstore et génère une réponse à l'aide d'un modèle de langage. (vectorstore est une base de données dans laquelle nous stockons nos données converties en nombres sous forme de vecteurs)
Créons le fichier rag_chain.py :
# Uncomment your API key # OPENAI_API_KEY=your_openai_api_key_here # GEMINI_API_KEY=your_gemini_api_key_here # FIREWORKS_API_KEY=your_fireworks_api_key_here
Ici, nous vous donnons le choix entre OpenAI, Gemini ou Fireworks en fonction de la clé API que vous fournissez. La chaîne RAG récupérera les 3 documents les plus pertinents et utilisera le modèle de langage pour générer une réponse.
Vous pouvez basculer entre les modèles en fonction de votre budget ou de vos préférences d'utilisation : Gemini et Fireworks sont gratuits, tandis que OpenAI facture en fonction de l'utilisation.
Maintenant, nous allons créer une interface de chatbot simple pour prendre en compte les entrées des utilisateurs et générer des réponses à l'aide de notre chaîne RAG.
Créez un nouveau fichier appelé chatbot.py :
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
Ce script crée une interface de chatbot en ligne de commande qui écoute en permanence les entrées de l'utilisateur, les traite via la chaîne RAG et renvoie la réponse générée.
Il est temps de rendre votre chatbot encore plus convivial en créant une interface Web à l'aide de Streamlit. Cela permettra aux utilisateurs d'interagir avec votre chatbot via un navigateur.
Créer app.py :
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
Pour exécuter votre application Streamlit, utilisez simplement :
pip install -r requirements.txt
Cela lancera une interface Web où vous pourrez télécharger un fichier texte, poser des questions et recevoir des réponses du chatbot.
Pour de meilleures performances, vous pouvez expérimenter la taille des morceaux et le chevauchement lors de la division du texte. Les morceaux plus gros fournissent plus de contexte, mais les morceaux plus petits peuvent accélérer la récupération. Vous pouvez également utiliser la mise en cache Streamlit pour éviter de répéter des opérations coûteuses comme la génération d'intégrations.
Si vous souhaitez optimiser les coûts, vous pouvez basculer entre OpenAI, Gemini ou Fireworks en fonction de la complexité de la requête : utilisez OpenAI pour les questions complexes et Gemini ou Fireworks pour les plus simples afin de réduire les coûts.
Félicitations ! Vous avez créé avec succès votre propre chatbot basé sur RAG. Désormais, les possibilités sont infinies :
Le voyage commence ici, et le potentiel est illimité !
Vous pouvez suivre mon travail sur GitHub. N'hésitez pas à me contacter : mes DM sont toujours ouverts sur X et LinkedIn.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quel est le symbole du droit d'auteur
Quel est le symbole du droit d'auteur
 Yiouoky est-il un logiciel légal ?
Yiouoky est-il un logiciel légal ?
 Explication détaillée de la configuration de nginx
Explication détaillée de la configuration de nginx
 La relation entre la bande passante et la vitesse du réseau
La relation entre la bande passante et la vitesse du réseau
 La différence entre serveur et hôte cloud
La différence entre serveur et hôte cloud
 Quels sont les systèmes de correction d'erreurs de noms de domaine ?
Quels sont les systèmes de correction d'erreurs de noms de domaine ?
 Le taux d'inflation a-t-il un impact sur les monnaies numériques ?
Le taux d'inflation a-t-il un impact sur les monnaies numériques ?
 Comment se connecter à la base de données en utilisant VB
Comment se connecter à la base de données en utilisant VB








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



