

Allez sync.WaitGroup et le problème d'alignement
Oct 22, 2024 pm 12:49 PM这篇文章是关于 Go 中处理并发的系列文章的一部分:
- Gosync.Mutex:正常和饥饿模式
- Gosync.WaitGroup 和对齐问题(我们在这里)
- Gosync.Pool 及其背后的机制
- Gosync.Cond,最被忽视的同步机制
- Gosync.Map:适合正确工作的正确工具
- Go Singleflight 融入您的代码,而不是您的数据库
WaitGroup 基本上是一种等待多个 goroutine 完成其工作的方法。
每个同步原语都有自己的一系列问题,这个也不例外。我们将重点关注 WaitGroup 的对齐问题,这就是它的内部结构在不同版本中发生变化的原因。
本文基于 Go 1.23。如果后续有任何变化,请随时通过 X(@func25) 告诉我。
什么是sync.WaitGroup?
如果您已经熟悉sync.WaitGroup,请随意跳过。
让我们先深入探讨这个问题,想象一下您手上有一项艰巨的工作,因此您决定将其分解为可以同时运行且彼此不依赖的较小任务。
为了解决这个问题,我们使用 goroutine,因为它们让这些较小的任务同时运行:
func main() {
for i := 0; i < 10; i++ {
go func(i int) {
fmt.Println("Task", i)
}(i)
}
fmt.Println("Done")
}
// Output:
// Done
但是事情是这样的,很有可能主协程在其他协程完成工作之前完成并退出。
当我们分出许多 goroutine 来做他们的事情时,我们希望跟踪它们,以便主 goroutine 不会在其他人完成之前完成并退出。这就是 WaitGroup 发挥作用的地方。每次我们的一个 goroutine 完成其任务时,它都会让 WaitGroup 知道。
一旦所有 goroutine 都签入为“完成”,主 goroutine 就知道可以安全完成,并且一切都会整齐地结束。
func main() {
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func(i int) {
defer wg.Done()
fmt.Println("Task", i)
}(i)
}
wg.Wait()
fmt.Println("Done")
}
// Output:
// Task 0
// Task 1
// Task 2
// Task 3
// Task 4
// Task 5
// Task 6
// Task 7
// Task 8
// Task 9
// Done
所以,通常是这样的:
- 添加 goroutine:在启动 goroutine 之前,您需要告诉 WaitGroup 需要多少个 goroutine。您可以使用 WaitGroup.Add(n) 来执行此操作,其中 n 是您计划运行的 goroutine 数量。
- Goroutines running:每个 Goroutine 都会开始执行它的任务。完成后,它应该通过调用 WaitGroup.Done() 来让 WaitGroup 知道,以将计数器减一。
- 等待所有 goroutine:在主 goroutine 中,即不执行繁重工作的 goroutine,您调用 WaitGroup.Wait()。这会暂停主 goroutine,直到 WaitGroup 中的计数器达到零。简单来说,它会等待所有其他 goroutine 完成并发出完成信号。
通常,你会看到在启动 goroutine 时使用 WaitGroup.Add(1):
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
...
}()
}
这两种方法在技术上都很好,但是使用 wg.Add(1) 会对性能造成很小的影响。尽管如此,与使用 wg.Add(n).
相比,它更不容易出错“为什么 wg.Add(n) 被认为容易出错?”
重点是,如果循环的逻辑发生变化,就像有人添加了跳过某些迭代的 continue 语句,事情可能会变得混乱:
wg.Add(10)
for i := 0; i < 10; i++ {
if someCondition(i) {
continue
}
go func() {
defer wg.Done()
...
}()
}
在这个例子中,我们在循环之前使用 wg.Add(n) ,假设循环总是恰好启动 n 个 goroutine。
但是如果这个假设不成立,比如跳过一些迭代,你的程序可能会陷入等待从未启动的 goroutine 的状态。老实说,这种错误追踪起来确实很痛苦。
这种情况下,wg.Add(1) 更合适。它可能会带来一点点性能开销,但它比处理人为错误开销要好得多。
人们在使用sync.WaitGroup时还常犯一个非常常见的错误:
for i := 0; i < 10; i++ {
go func() {
wg.Add(1)
defer wg.Done()
...
}()
}
归根结底,wg.Add(1) 正在内部 goroutine 中调用。这可能是一个问题,因为 Goroutine 可能在主 Goroutine 已经调用 wg.Wait() 之后开始运行。
这可能会导致各种计时问题。另外,如果您注意到,上面的所有示例都使用 defer 和 wg.Done()。它确实应该与 defer 一起使用,以避免多个返回路径或恐慌恢复的问题,确保它总是被调用并且不会无限期地阻止调用者。
这应该涵盖所有基础知识。
sync.WaitGroup 是什么样子的?
我们首先查看sync.WaitGroup的源代码。您会在sync.Mutex 中注意到类似的模式。
再次强调,如果您不熟悉互斥锁的工作原理,我强烈建议您先查看这篇文章:Go Sync Mutex:正常模式和饥饿模式。
type WaitGroup struct {
noCopy noCopy
state atomic.Uint64
sema uint32
}
type noCopy struct{}
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
在 Go 中,只需将结构分配给另一个变量即可轻松复制结构。但有些结构,例如 WaitGroup,确实不应该被复制。
Copying a WaitGroup can mess things up because the internal state that tracks the goroutines and their synchronization can get out of sync between the copies. If you've read the mutex post, you'll get the idea, imagine what could go wrong if we copied the internal state of a mutex.
The same kind of issues can happen with WaitGroup.
noCopy
The noCopy struct is included in WaitGroup as a way to help prevent copying mistakes, not by throwing errors, but by serving as a warning. It was contributed by Aliaksandr Valialkin, CTO of VictoriaMetrics, and was introduced in change #22015.
The noCopy struct doesn't actually affect how your program runs. Instead, it acts as a marker that tools like go vet can pick up on to detect when a struct has been copied in a way that it shouldn't be.
type noCopy struct{}
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
Its structure is super simple:
- It has no fields, so it doesn't take up any meaningful space in memory.
- It has two methods, Lock and Unlock, which do nothing (no-op). These methods are there just to work with the -copylocks checker in the go vet tool.
When you run go vet on your code, it checks to see if any structs with a noCopy field, like WaitGroup, have been copied in a way that could cause issues.
It will throw an error to let you know there might be a problem. This gives you a heads-up to fix it before it turns into a bug:
func main() {
var a sync.WaitGroup
b := a
fmt.Println(a, b)
}
// go vet:
// assignment copies lock value to b: sync.WaitGroup contains sync.noCopy
// call of fmt.Println copies lock value: sync.WaitGroup contains sync.noCopy
// call of fmt.Println copies lock value: sync.WaitGroup contains sync.noCopy
In this case, go vet will warn you about 3 different spots where the copying happens. You can try it yourself at: Go Playground.
Note that it's purely a safeguard for when we're writing and testing our code, we can still run it like normal.
Internal State
The state of a WaitGroup is stored in an atomic.Uint64 variable. You might have guessed this if you've read the mutex post, there are several things packed into this single value.

Here's how it breaks down:
- Counter (high 32 bits): This part keeps track of the number of goroutines the WaitGroup is waiting for. When you call wg.Add() with a positive value, it bumps up this counter, and when you call wg.Done(), it decreases the counter by one.
- Waiter (low 32 bits): This tracks the number of goroutines currently waiting for that counter (the high 32 bits) to hit zero. Every time you call wg.Wait(), it increases this "waiter" count. Once the counter reaches zero, it releases all the goroutines that were waiting.
Then there's the final field, sema uint32, which is an internal semaphore managed by the Go runtime.
when a goroutine calls wg.Wait() and the counter isn't zero, it increases the waiter count and then blocks by calling runtime_Semacquire(&wg.sema). This function call puts the goroutine to sleep until it gets woken up by a corresponding runtime_Semrelease(&wg.sema) call.
We'll dive deeper into this in another article, but for now, I want to focus on the alignment issues.
Alignment Problem
I know, talking about history might seem dull, especially when you just want to get to the point. But trust me, knowing the past is the best way to understand where we are now.
Let's take a quick look at how WaitGroup has evolved over several Go versions:
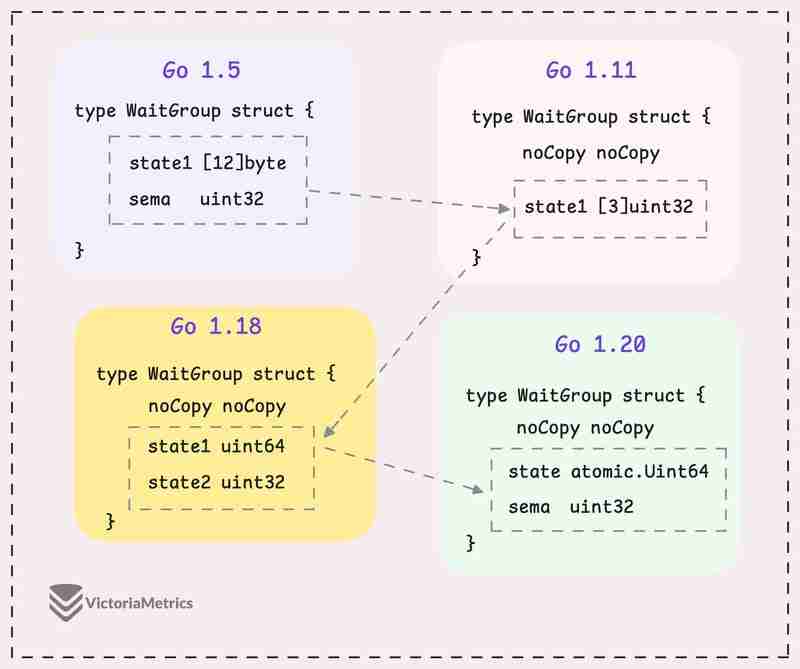
I can tell you, the core of WaitGroup (the counter, waiter, and semaphore) hasn't really changed across different Go versions. However, the way these elements are structured has been modified many times.
When we talk about alignment, we're referring to the need for data types to be stored at specific memory addresses to allow for efficient access.
For example, on a 64-bit system, a 64-bit value like uint64 should ideally be stored at a memory address that's a multiple of 8 bytes. The reason is, the CPU can grab aligned data in one go, but if the data isn't aligned, it might take multiple operations to access it.
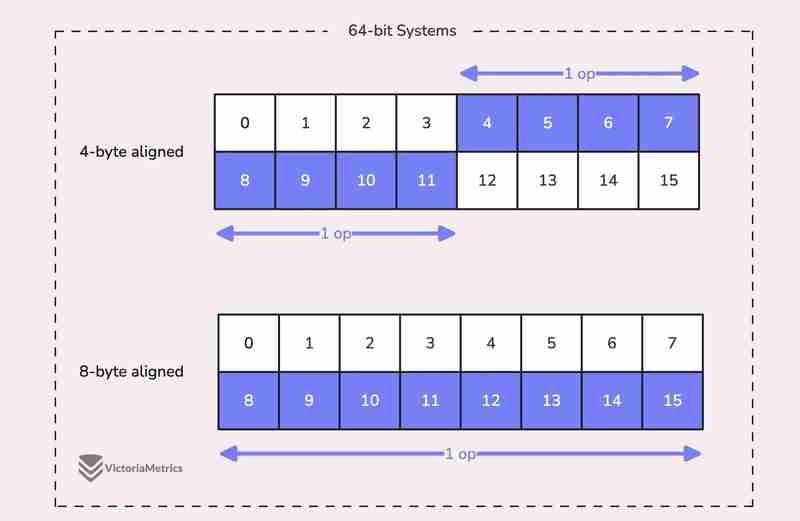
Now, here's where things get tricky:
On 32-bit architectures, the compiler doesn't guarantee that 64-bit values will be aligned on an 8-byte boundary. Instead, they might only be aligned on a 4-byte boundary.
This becomes a problem when we use the atomic package to perform operations on the state variable. The atomic package specifically notes:
"On ARM, 386, and 32-bit MIPS, it is the caller's responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically via the primitive atomic functions." - atomic package note
What this means is that if we don't align the state uint64 variable to an 8-byte boundary on these 32-bit architectures, it could cause the program to crash.
So, what's the fix? Let's take a look at how this has been handled across different versions.
Go 1.5: state1 [12]byte
I'd recommend taking a moment to guess the underlying logic of this solution as you read the code below, then we'll walk through it together.
type WaitGroup struct {
state1 [12]byte
sema uint32
}
func (wg *WaitGroup) state() *uint64 {
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1))
} else {
return (*uint64)(unsafe.Pointer(&wg.state1[4]))
}
}
Instead of directly using a uint64 for state, WaitGroup sets aside 12 bytes in an array (state1 [12]byte). This might seem like more than you'd need, but there's a reason behind it.
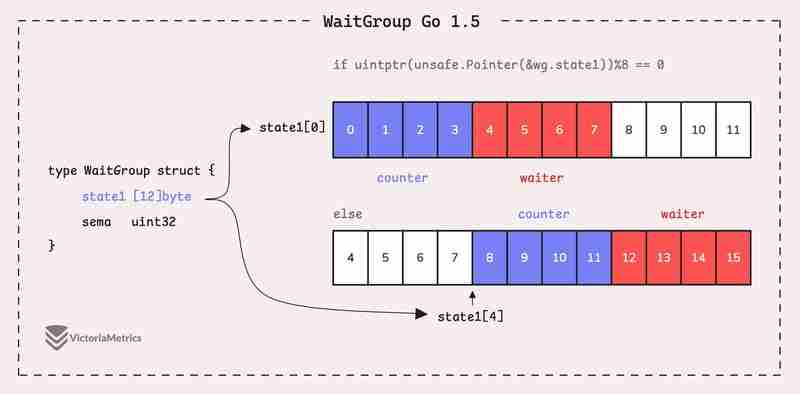
The purpose of using 12 bytes is to ensure there's enough room to find an 8-byte segment that's properly aligned.
The full post is available here: https://victoriametrics.com/blog/go-sync-waitgroup/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Article chaud

Outils chauds Tags

Article chaud

Tags d'article chaud

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 GO Language Pack Import: Quelle est la différence entre le soulignement et sans soulignement?
Mar 03, 2025 pm 05:17 PM
GO Language Pack Import: Quelle est la différence entre le soulignement et sans soulignement?
Mar 03, 2025 pm 05:17 PM
GO Language Pack Import: Quelle est la différence entre le soulignement et sans soulignement?
 Comment écrire des objets et des talons simulés pour les tests en Go?
Mar 10, 2025 pm 05:38 PM
Comment écrire des objets et des talons simulés pour les tests en Go?
Mar 10, 2025 pm 05:38 PM
Comment écrire des objets et des talons simulés pour les tests en Go?
 Comment mettre en œuvre le transfert d'informations à court terme entre les pages du cadre Beego?
Mar 03, 2025 pm 05:22 PM
Comment mettre en œuvre le transfert d'informations à court terme entre les pages du cadre Beego?
Mar 03, 2025 pm 05:22 PM
Comment mettre en œuvre le transfert d'informations à court terme entre les pages du cadre Beego?
 Comment puis-je définir des contraintes de type personnalisé pour les génériques en Go?
Mar 10, 2025 pm 03:20 PM
Comment puis-je définir des contraintes de type personnalisé pour les génériques en Go?
Mar 10, 2025 pm 03:20 PM
Comment puis-je définir des contraintes de type personnalisé pour les génériques en Go?
 Comment puis-je utiliser des outils de traçage pour comprendre le flux d'exécution de mes applications GO?
Mar 10, 2025 pm 05:36 PM
Comment puis-je utiliser des outils de traçage pour comprendre le flux d'exécution de mes applications GO?
Mar 10, 2025 pm 05:36 PM
Comment puis-je utiliser des outils de traçage pour comprendre le flux d'exécution de mes applications GO?
 Comment puis-je utiliser des liners et des outils d'analyse statique pour améliorer la qualité et la maintenabilité de mon code GO?
Mar 10, 2025 pm 05:38 PM
Comment puis-je utiliser des liners et des outils d'analyse statique pour améliorer la qualité et la maintenabilité de mon code GO?
Mar 10, 2025 pm 05:38 PM
Comment puis-je utiliser des liners et des outils d'analyse statique pour améliorer la qualité et la maintenabilité de mon code GO?
 Comment écrire des fichiers dans GO Language de manière pratique?
Mar 03, 2025 pm 05:15 PM
Comment écrire des fichiers dans GO Language de manière pratique?
Mar 03, 2025 pm 05:15 PM
Comment écrire des fichiers dans GO Language de manière pratique?
 Comment convertir la liste des résultats de la requête MySQL en une tranche de structure personnalisée dans le langage Go?
Mar 03, 2025 pm 05:18 PM
Comment convertir la liste des résultats de la requête MySQL en une tranche de structure personnalisée dans le langage Go?
Mar 03, 2025 pm 05:18 PM
Comment convertir la liste des résultats de la requête MySQL en une tranche de structure personnalisée dans le langage Go?
