

Des données au déploiement

DataWhisper : Maîtriser le cycle de vie des projets DL
Auteur : Abdellah Hallou (LinkedIn, Twitter)
Bienvenue dans le guide de démarrage du projet Deep Learning ! Ce didacticiel constitue une ressource complète pour tous ceux qui souhaitent se plonger dans le monde passionnant du deep learning. Que vous soyez débutant ou développeur expérimenté, ce guide vous guidera tout au long du processus de construction d'un projet de deep learning du début à la fin.
Table des matières
- Ce que vous apprendrez
- Qui devrait suivre ce tutoriel
- Besoin d'aide ou avez des questions ?
- Commençons !
- Importations et chargement de l'ensemble de données
- Structure de l'ensemble de données
- Analyse exploratoire des données (EDA)
- Prétraiter les données
- Construire le modèle
- Évaluer la précision
- Enregistrer et exporter le modèle
- Faire des pronostics
-
Déploiement
- Créer un nouveau projet Flutter
- Configuration de la caméra
- Création de l'écran de la caméra
- Intégration du téléchargement d'images
- Reconnaissance d'objets avec TensorFlow Lite
- Exécuter le modèle sur des images
- Affichage des résultats dans une boîte de dialogue
- Création de l'interface utilisateur
Ce que vous apprendrez
Dans ce tutoriel, vous apprendrez les étapes essentielles à la création et au déploiement d'un modèle de deep-learning dans une application mobile. Nous aborderons les sujets suivants :
Préparation des données : nous explorerons diverses méthodes de prétraitement des données afin de garantir un ensemble de données robuste et fiable pour la formation.
Création de modèle : Vous découvrirez comment concevoir et construire votre modèle CNN.
Formation du modèle : nous approfondirons le processus de formation de votre modèle d'apprentissage profond à l'aide de TensorFlow.
Déploiement dans une application mobile : Une fois votre modèle entraîné, nous vous guiderons à travers les étapes pour l'intégrer dans une application mobile à l'aide de TensorFlow Lite. Vous comprendrez comment faire des prédictions en déplacement !
Qui devrait suivre ce tutoriel
Ce tutoriel convient aux développeurs débutants et intermédiaires ayant une compréhension de base des concepts d'apprentissage profond et de la programmation Python. Que vous soyez un data scientist, un passionné d'apprentissage automatique ou un développeur d'applications mobiles, ce guide vous fournira les connaissances nécessaires pour lancer votre projet d'apprentissage profond.
Besoin d'aide ou avez des questions ?
Si vous rencontrez des problèmes, avez des questions ou avez besoin de précisions supplémentaires en suivant ce tutoriel, n'hésitez pas à créer un problème GitHub dans ce référentiel From-Data-to-Deployment. Je serai plus qu'heureux de vous aider et de vous fournir les conseils nécessaires.
Pour créer un ticket, cliquez sur l'onglet "Problèmes" en haut de la page de ce référentiel et cliquez sur le bouton "Nouveau numéro". Veuillez fournir autant de contexte et de détails que possible sur le problème auquel vous êtes confronté ou la question que vous vous posez. Cela m'aidera à mieux comprendre votre préoccupation et à vous fournir une réponse rapide et précise.
Vos commentaires sont précieux et peuvent également contribuer à améliorer ce didacticiel pour les autres utilisateurs. N'hésitez donc pas à nous contacter si vous avez besoin d'aide. Apprenons et grandissons ensemble !
Commençons !
Pour commencer, assurez-vous que les dépendances et bibliothèques requises sont installées. Le didacticiel est divisé en sections faciles à suivre, chacune couvrant un aspect spécifique du flux de travail du projet d'apprentissage profond. N'hésitez pas à accéder aux sections qui vous intéressent le plus ou à suivre du début à la fin.
Êtes-vous prêt ?
Importations et chargement de l'ensemble de données
Commençons les importations nécessaires pour notre code. Nous utiliserons l'ensemble de données Fashion Mnist dans ce tutoriel.
# Import the necessary libraries from __future__ import print_function import keras from google.colab import drive import os import numpy as np from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization from keras.layers import Conv2D, MaxPooling2D from keras.wrappers.scikit_learn import KerasClassifier from keras import backend as K from sklearn.model_selection import GridSearchCV import tensorflow as tf from keras.utils.vis_utils import plot_model import matplotlib.pyplot as plt
Structure de l'ensemble de données
Dans tout projet de deep learning, la compréhension des données est cruciale. Avant de plonger dans la création et la formation de modèles, commençons par charger les données et obtenir des informations sur leur structure, leurs variables et leurs caractéristiques globales.
# Load the Fashion MNIST dataset fashion_mnist = tf.keras.datasets.fashion_mnist (x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
Analyse exploratoire des données (EDA)
Maintenant que les données sont chargées, effectuons une analyse exploratoire des données pour mieux comprendre leurs caractéristiques.
print("Shape of the training data : ",x_train.shape)
print("Shape of the testing data : ",x_test.shape)
Shape of the training data : (60000, 28, 28) Shape of the testing data : (10000, 28, 28)
L'ensemble de données Fashion MNIST contient 70 000 images en niveaux de gris réparties en 10 catégories. Les images montrent des vêtements individuels en basse résolution (28 x 28 pixels), comme on le voit ici :

60 000 images sont utilisées pour entraîner le réseau et 10 000 images pour évaluer avec quelle précision le réseau a appris à classer les images.
# Printing unique values in training data
unique_labels = np.unique(y_train, axis=0)
print("Unique labels in training data:", unique_labels)
Unique labels in training data: [0 1 2 3 4 5 6 7 8 9]
Les étiquettes sont un tableau d'entiers, allant de 0 à 9. Ceux-ci correspondent à la classe de vêtements que l'image représente :
| Étiquette | Classe R |
| - |-|
| 0 | T-shirt/haut|
| 1 | Pantalon|
| 2 |Pull|
| 3 |Robe|
| 4 |Manteau|
| 5 |Sandale|
| 6 |Chemise|
| 7 |Basket |
| 8 |Sac|
| 9 | Bottine |
Étant donné que les noms de classes ne sont pas inclus dans l'ensemble de données, stockez-les ici pour les utiliser plus tard lors du traçage des images :
# Numeric labels
numeric_labels = np.sort(np.unique(y_train, axis=0))
# String labels
string_labels = np.array(['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'])
# Mapping numeric labels to string labels
numeric_to_string = dict(zip(numeric_labels, string_labels))
print("Numeric to String Label Mapping:")
print(numeric_to_string)
Numeric to String Label Mapping:
{0: 'T-shirt/top', 1: 'Trouser', 2: 'Pullover', 3: 'Dress', 4: 'Coat', 5: 'Sandal', 6: 'Shirt', 7: 'Sneaker', 8: 'Bag', 9: 'Ankle boot'}
Prétraiter les données
Les données doivent être prétraitées avant de former le réseau.
Nous commençons par définir le nombre de classes dans notre ensemble de données (qui est de 10 dans ce cas) et les dimensions des images d'entrée (28x28 pixels).
# Import the necessary libraries from __future__ import print_function import keras from google.colab import drive import os import numpy as np from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization from keras.layers import Conv2D, MaxPooling2D from keras.wrappers.scikit_learn import KerasClassifier from keras import backend as K from sklearn.model_selection import GridSearchCV import tensorflow as tf from keras.utils.vis_utils import plot_model import matplotlib.pyplot as plt
Cette partie est chargée de remodeler les données de l'image d'entrée pour qu'elles correspondent au format attendu pour le modèle de réseau neuronal. Le format dépend du backend utilisé (par exemple, TensorFlow ou Theano). Dans cet extrait, nous vérifions le format des données d'image à l'aide de K.image_data_format() et appliquons le remodelage approprié en fonction du résultat.
# Load the Fashion MNIST dataset fashion_mnist = tf.keras.datasets.fashion_mnist (x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
Les valeurs de pixels des images dans les données sont comprises entre 0 et 255.
Mettez ces valeurs à l'échelle dans une plage de 0 à 1 avant de les transmettre au modèle CNN.
print("Shape of the training data : ",x_train.shape)
print("Shape of the testing data : ",x_test.shape)
Convertissez les étiquettes de classe (représentées sous forme d'entiers) en un format de matrice de classe binaire, requis pour les problèmes de classification multi-classes.
Shape of the training data : (60000, 28, 28) Shape of the testing data : (10000, 28, 28)
Construire le modèle
Dans cette étape, nous définissons et construisons un modèle de réseau neuronal convolutif (CNN) pour la classification d'images. L'architecture du modèle se compose de plusieurs couches telles que des couches convolutives, de pooling, d'abandon et denses. La fonction build_model prend le nombre de classes, les données de formation et de test en entrée et renvoie l'historique de formation et le modèle construit.
# Printing unique values in training data
unique_labels = np.unique(y_train, axis=0)
print("Unique labels in training data:", unique_labels)
Unique labels in training data: [0 1 2 3 4 5 6 7 8 9]
# Numeric labels
numeric_labels = np.sort(np.unique(y_train, axis=0))
# String labels
string_labels = np.array(['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'])
# Mapping numeric labels to string labels
numeric_to_string = dict(zip(numeric_labels, string_labels))
print("Numeric to String Label Mapping:")
print(numeric_to_string)
Évaluer la précision
Pour évaluer les performances du modèle entraîné, nous l'évaluons sur les données de test. La méthode d'évaluation est utilisée pour calculer la perte et la précision du test. Ces métriques sont ensuite imprimées sur la console.
Numeric to String Label Mapping:
{0: 'T-shirt/top', 1: 'Trouser', 2: 'Pullover', 3: 'Dress', 4: 'Coat', 5: 'Sandal', 6: 'Shirt', 7: 'Sneaker', 8: 'Bag', 9: 'Ankle boot'}

num_classes = 10 # input image dimensions img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
Enregistrer et exporter le modèle
Après avoir entraîné le modèle, nous l'enregistrons au format de fichier Hierarchical Data Format (HDF5) en utilisant la méthode save. Le modèle est ensuite exporté vers Google Drive en appelant la fonction move_to_drive. De plus, le modèle est converti au format TensorFlow Lite à l'aide de la fonction h52tflite, et le modèle TFLite résultant est également enregistré dans Google Drive. Les chemins du modèle enregistré et du modèle TFLite sont renvoyés.
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
Faire des prédictions
Pour visualiser les prédictions du modèle, nous sélectionnons un ensemble aléatoire d'images de test. Le modèle prédit les étiquettes de classe pour ces images à l'aide de la méthode prédire. Les étiquettes prédites sont ensuite comparées aux étiquettes de vérité terrain pour afficher les images avec leurs étiquettes prédites correspondantes à l'aide de matplotlib.
# convert class vectors to binary class matrices y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes)

pour plus d'informations sur le modèle, consultez ces ressources :
- https://www.tensorflow.org/tutorials/keras/classification
- https://github.com/cmasch/zalando-fashion-mnist/tree/master
Déploiement
Créer un nouveau projet Flutter
Avant de créer un nouveau projet Flutter, assurez-vous que le SDK Flutter et les autres exigences liées au développement de l'application Flutter sont correctement installés : https://docs.flutter.dev/get-started/install/windows
Une fois le projet mis en place, nous implémenterons l'interface utilisateur pour permettre aux utilisateurs de prendre des photos ou de télécharger des images depuis la galerie et d'effectuer une reconnaissance d'objets à l'aide du modèle TensorFlow Lite exporté.
Tout d’abord, nous devons installer ces packages :
- caméra : 0.10.4
- image_picker :
- tflite : ^1.1.2
Pour cela copiez l'extrait de code suivant et collez-le dans le fichier pubspec.yaml du projet :
# Import the necessary libraries from __future__ import print_function import keras from google.colab import drive import os import numpy as np from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization from keras.layers import Conv2D, MaxPooling2D from keras.wrappers.scikit_learn import KerasClassifier from keras import backend as K from sklearn.model_selection import GridSearchCV import tensorflow as tf from keras.utils.vis_utils import plot_model import matplotlib.pyplot as plt
Importez les packages nécessaires dans le fichier main.dart du projet
# Load the Fashion MNIST dataset fashion_mnist = tf.keras.datasets.fashion_mnist (x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
Configuration de la caméra
Pour activer la fonctionnalité de la caméra, nous utiliserons le package caméra. Tout d’abord, importez les packages nécessaires et instanciez le contrôleur de caméra. Utilisez la fonction availableCameras() pour obtenir une liste des caméras disponibles. Dans ce tutoriel, nous utiliserons la première caméra de la liste.
print("Shape of the training data : ",x_train.shape)
print("Shape of the testing data : ",x_test.shape)
Création de l'écran de la caméra
Créez un nouveau StatefulWidget appelé CameraScreen qui gérera l'aperçu de la caméra et la fonctionnalité de capture d'image. Dans la méthode initState(), initialisez le contrôleur de la caméra et définissez le préréglage de résolution. De plus, implémentez la méthode _takePicture(), qui capture une image à l'aide du contrôleur de la caméra.
Shape of the training data : (60000, 28, 28) Shape of the testing data : (10000, 28, 28)
Intégration du téléchargement d'images
Pour permettre aux utilisateurs de télécharger des images depuis la galerie, importez le package image_picker. Implémentez la méthode _pickImage(), qui utilise la classe ImagePicker pour sélectionner une image dans la galerie. Une fois qu'une image est sélectionnée, elle peut être traitée à l'aide de la méthode _processImage().
# Printing unique values in training data
unique_labels = np.unique(y_train, axis=0)
print("Unique labels in training data:", unique_labels)
Reconnaissance d'objets avec TensorFlow Lite
Pour effectuer la reconnaissance d'objets, nous utiliserons TensorFlow Lite. Commencez par importer le package tflite. Dans la méthode _initTensorFlow(), chargez le modèle TensorFlow Lite et les étiquettes à partir des ressources. Vous pouvez spécifier les chemins d'accès aux fichiers de modèle et d'étiquette et ajuster les paramètres tels que le nombre de threads et l'utilisation des délégués GPU.
# Import the necessary libraries from __future__ import print_function import keras from google.colab import drive import os import numpy as np from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization from keras.layers import Conv2D, MaxPooling2D from keras.wrappers.scikit_learn import KerasClassifier from keras import backend as K from sklearn.model_selection import GridSearchCV import tensorflow as tf from keras.utils.vis_utils import plot_model import matplotlib.pyplot as plt
Exécuter le modèle sur des images
Implémentez la méthode _objectRecognition(), qui prend un chemin de fichier image en entrée et exécute le modèle TensorFlow Lite sur l'image. La méthode renvoie le label de l'objet reconnu.
# Load the Fashion MNIST dataset fashion_mnist = tf.keras.datasets.fashion_mnist (x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
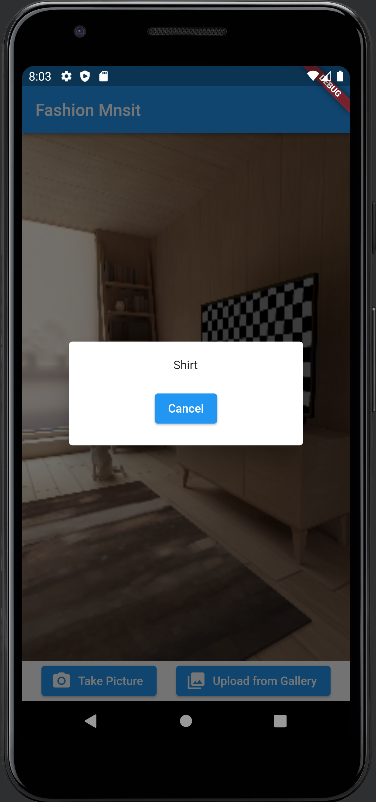
Affichage des résultats dans une boîte de dialogue
Lorsqu'une image est traitée, affichez le résultat dans une boîte de dialogue à l'aide de la méthode showDialog(). Personnalisez la boîte de dialogue pour afficher l'étiquette de l'objet reconnu et proposez une option d'annulation.
print("Shape of the training data : ",x_train.shape)
print("Shape of the testing data : ",x_test.shape)
Construire l'interface utilisateur
Shape of the training data : (60000, 28, 28) Shape of the testing data : (10000, 28, 28)

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 Python vs C: courbes d'apprentissage et facilité d'utilisation
Apr 19, 2025 am 12:20 AM
Python vs C: courbes d'apprentissage et facilité d'utilisation
Apr 19, 2025 am 12:20 AM
Python est plus facile à apprendre et à utiliser, tandis que C est plus puissant mais complexe. 1. La syntaxe Python est concise et adaptée aux débutants. Le typage dynamique et la gestion automatique de la mémoire le rendent facile à utiliser, mais peuvent entraîner des erreurs d'exécution. 2.C fournit des fonctionnalités de contrôle de bas niveau et avancées, adaptées aux applications haute performance, mais a un seuil d'apprentissage élevé et nécessite une gestion manuelle de la mémoire et de la sécurité.
 Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Pour maximiser l'efficacité de l'apprentissage de Python dans un temps limité, vous pouvez utiliser les modules DateTime, Time et Schedule de Python. 1. Le module DateTime est utilisé pour enregistrer et planifier le temps d'apprentissage. 2. Le module de temps aide à définir l'étude et le temps de repos. 3. Le module de planification organise automatiquement des tâches d'apprentissage hebdomadaires.
 Python vs. C: Explorer les performances et l'efficacité
Apr 18, 2025 am 12:20 AM
Python vs. C: Explorer les performances et l'efficacité
Apr 18, 2025 am 12:20 AM
Python est meilleur que C dans l'efficacité du développement, mais C est plus élevé dans les performances d'exécution. 1. La syntaxe concise de Python et les bibliothèques riches améliorent l'efficacité du développement. Les caractéristiques de type compilation et le contrôle du matériel de CC améliorent les performances d'exécution. Lorsque vous faites un choix, vous devez peser la vitesse de développement et l'efficacité de l'exécution en fonction des besoins du projet.
 Quelle partie fait partie de la bibliothèque standard Python: listes ou tableaux?
Apr 27, 2025 am 12:03 AM
Quelle partie fait partie de la bibliothèque standard Python: listes ou tableaux?
Apr 27, 2025 am 12:03 AM
PythonlistSaReparmentofthestandardLibrary, tandis que les coloccules de colocède, tandis que les colocculations pour la base de la Parlementaire, des coloments de forage polyvalent, tandis que la fonctionnalité de la fonctionnalité nettement adressée.
 Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python excelle dans l'automatisation, les scripts et la gestion des tâches. 1) Automatisation: La sauvegarde du fichier est réalisée via des bibliothèques standard telles que le système d'exploitation et la fermeture. 2) Écriture de script: utilisez la bibliothèque PSUTIL pour surveiller les ressources système. 3) Gestion des tâches: utilisez la bibliothèque de planification pour planifier les tâches. La facilité d'utilisation de Python et la prise en charge de la bibliothèque riche en font l'outil préféré dans ces domaines.
 Apprendre Python: 2 heures d'étude quotidienne est-elle suffisante?
Apr 18, 2025 am 12:22 AM
Apprendre Python: 2 heures d'étude quotidienne est-elle suffisante?
Apr 18, 2025 am 12:22 AM
Est-ce suffisant pour apprendre Python pendant deux heures par jour? Cela dépend de vos objectifs et de vos méthodes d'apprentissage. 1) Élaborer un plan d'apprentissage clair, 2) Sélectionnez les ressources et méthodes d'apprentissage appropriées, 3) la pratique et l'examen et la consolidation de la pratique pratique et de l'examen et de la consolidation, et vous pouvez progressivement maîtriser les connaissances de base et les fonctions avancées de Python au cours de cette période.
 Python vs C: Comprendre les principales différences
Apr 21, 2025 am 12:18 AM
Python vs C: Comprendre les principales différences
Apr 21, 2025 am 12:18 AM
Python et C ont chacun leurs propres avantages, et le choix doit être basé sur les exigences du projet. 1) Python convient au développement rapide et au traitement des données en raison de sa syntaxe concise et de son typage dynamique. 2) C convient à des performances élevées et à une programmation système en raison de son typage statique et de sa gestion de la mémoire manuelle.
