Achetez-moi un café☕
*Mémos :
-
Mon article explique le problème de gradient de disparition, le problème de gradient explosif et le problème de ReLU mourant.
-
Mon article explique les couches dans PyTorch.
-
Mon article explique les fonctions d'activation dans PyTorch.
-
Mon article explique les fonctions de perte dans PyTorch.
-
Mon article explique les optimiseurs dans PyTorch.

*Le surajustement et le sous-ajustement peuvent être détectés par la méthode Holdout ou la validation croisée (K-Fold Cross-Validation). *La validation croisée est meilleure.
Surapprentissage :
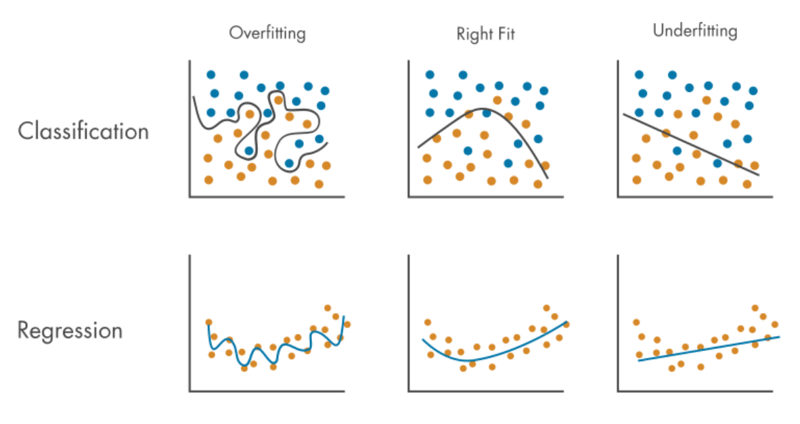
- C'est le problème qu'un modèle peut faire beaucoup plus de prédictions précises pour les données de train mais un peu pour les nouvelles données (y compris les données de test), de sorte que le modèle s'adapte bien plus aux données de train qu'aux nouvelles données.
- se produit parce que :
- Les données d'entraînement sont petites (pas suffisantes), le modèle ne peut donc apprendre qu'un petit nombre de modèles.
- Les données du train sont déséquilibrées (biaisées) et contiennent beaucoup de données spécifiques (limitées), similaires ou identiques, mais pas beaucoup de données diverses, de sorte que le modèle ne peut apprendre qu'un petit nombre de modèles.
- Les données du train contiennent beaucoup de bruit (données bruyantes), donc le modèle apprend beaucoup les modèles de bruit mais pas les modèles de données normales. *Bruit(données bruyantes) signifie des valeurs aberrantes, des anomalies ou des données parfois dupliquées.
- le temps d'entraînement est trop long avec un trop grand nombre d'époques.
- le modèle est trop complexe.
- peut être atténué par :
- données de train plus grandes.
- avoir beaucoup de données diverses.
- réduire le bruit.
- mélange de l'ensemble de données.
- arrêter l'entraînement plus tôt.
- Apprentissage en ensemble.
- Régularisation pour réduire la complexité du modèle :
*Mémos :
- Il y a un abandon (régularisation). *Mon message explique la couche Dropout.
- Il existe une régularisation L1 également appelée norme L1 ou régression Lasso.
- Il existe une régularisation L2 également appelée norme L2 ou régression Ridge.
-
Mon message explique linalg.norm().
-
Mon message explique linalg.vector_norm().
-
Mon message explique linalg.matrix_norm().
Sous-ajustement :
- Le problème est qu'un modèle ne peut pas faire de prédictions précises à la fois pour les données de train et les nouvelles données (y compris les données de test), de sorte que le modèle ne s'adapte pas à la fois aux données de train et aux nouvelles données.
- se produit parce que :
- le modèle est trop simple (pas assez complexe).
- le temps de formation est trop court avec un trop petit nombre d'époques.
- Une régularisation excessive (régularisation Dropout, L1 et L2) est appliquée.
- peut être atténué par :
- Complexité croissante du modèle.
- Augmenter le temps d'entraînement avec un plus grand nombre d'époques.
- Régularisation décroissante.
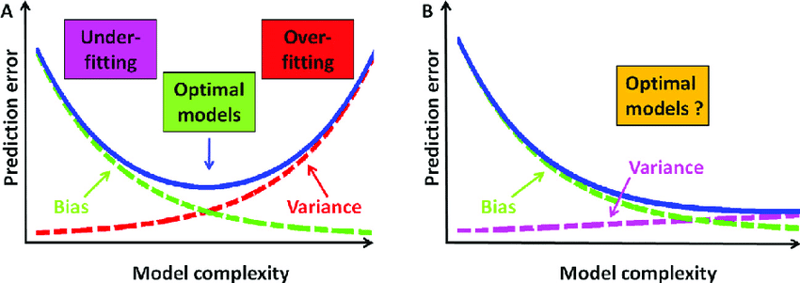
Le surajustement et le sous-ajustement sont des compromis :
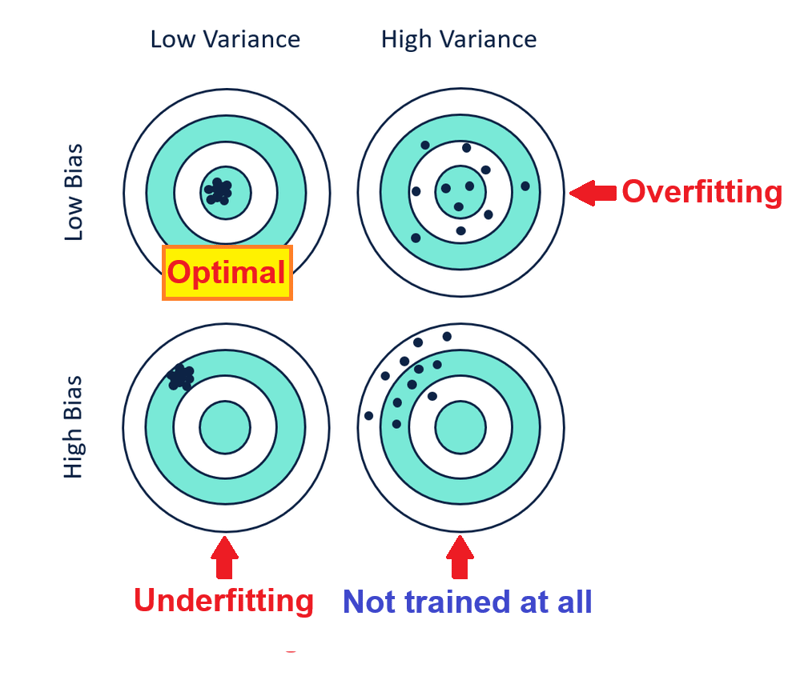
Trop d'atténuation du surapprentissage (5., 6. et 7.) conduit à un sous-apprentissage avec un biais élevé et une faible variance tandis qu'une atténuation trop importante du sous-apprentissage ( 1., 2. et 3.) conduit à un surapprentissage avec un faible biais et une variance élevée, leur atténuation doit donc être équilibrée comme indiqué ci-dessous :
*Mémos :
- Vous pouvez également dire Le biais et la variance sont un compromis car la réduction du biais augmente la variance tandis que la réduction de la variance augmente le biais, ils doivent donc être équilibrés. *L'augmentation de la complexité du modèle réduit les biais mais augmente la variance, tandis que la réduction de la complexité du modèle réduit la variance mais augmente les biais.
- Un biais faible signifie une grande précision, tandis qu'un biais élevé signifie une faible précision.
- Une faible variance signifie une haute précision tandis qu'une variance élevée signifie une faible précision.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


 python emballé dans un fichier exécutable
python emballé dans un fichier exécutable
 Comment installer des bibliothèques tierces dans sublime
Comment installer des bibliothèques tierces dans sublime
 Introduction aux attributs des balises d'article
Introduction aux attributs des balises d'article
 Comment définir la transparence en CSS
Comment définir la transparence en CSS
 Comment utiliser Python pour la boucle
Comment utiliser Python pour la boucle
 Comment utiliser le stockage cloud
Comment utiliser le stockage cloud
 Comment modifier les autorisations du dossier 777
Comment modifier les autorisations du dossier 777
 Comment résoudre le problème de l'impossibilité d'ouvrir le gestionnaire de périphériques
Comment résoudre le problème de l'impossibilité d'ouvrir le gestionnaire de périphériques








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



