

J'ai écrit un script Python qui traduit la logique métier d'extraction de données PDF en code fonctionnel.
Le script a été testé sur 71 pages de fichiers PDF de déclaration de dépositaire couvrant une période de 10 mois (de janvier à octobre 2024). Le traitement des fichiers PDF a pris environ 4 secondes, soit beaucoup plus rapidement que de le faire manuellement.
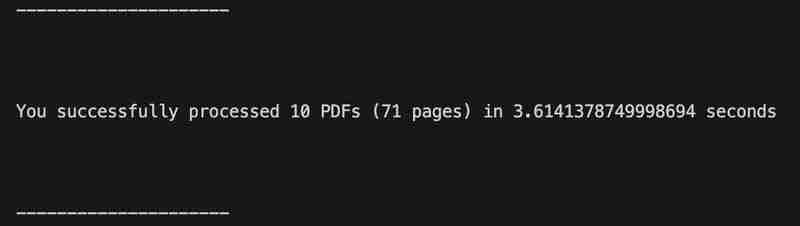
D'après ce que je vois, le résultat semble correct et le code n'a rencontré aucune erreur.
Des instantanés des trois sorties CSV sont présentés ci-dessous. Notez que les données sensibles ont été grisées.
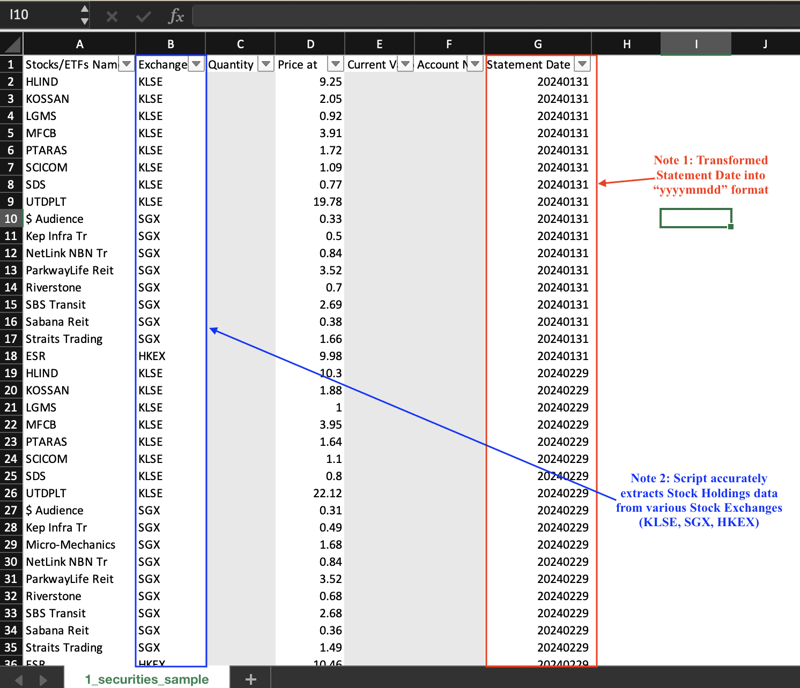
Aperçu 1 : avoirs en actions
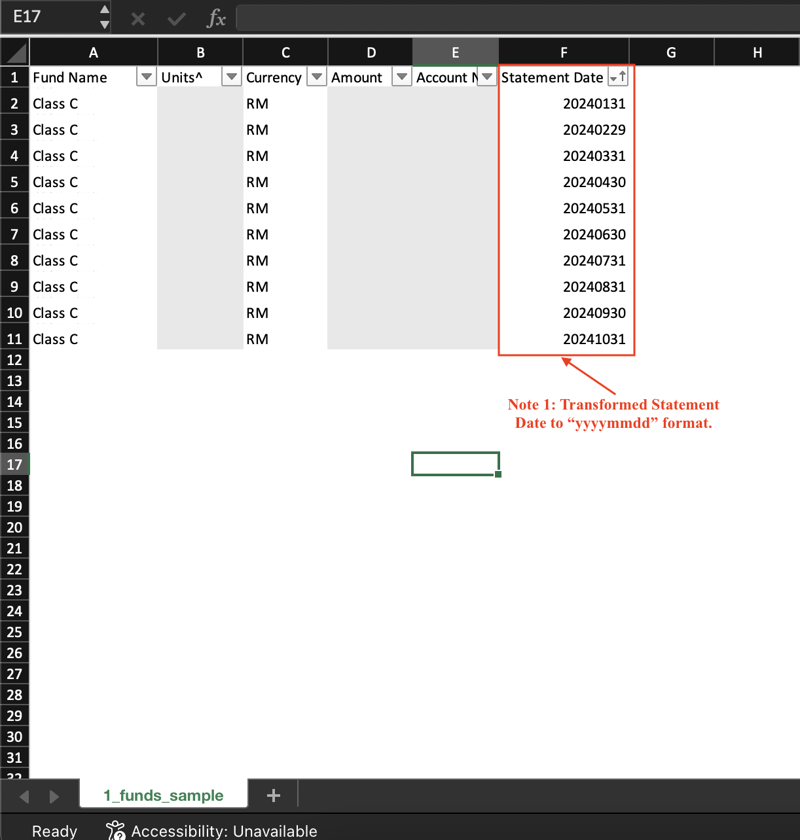
Aperçu 2 : avoirs du fonds
Aperçu 3 : Avoirs en espèces

Ce flux de travail montre les grandes étapes que j'ai suivies pour générer les fichiers CSV.

Maintenant, je vais expliquer plus en détail comment j'ai traduit la logique métier en code en Python.
J'ai utilisé la fonction open() de pdfplomber.
# Open the PDF file with pdfplumber.open(file_path) as pdf:
file_path est une variable déclarée qui indique à pdfplombier quel fichier ouvrir.
La fonction extract_tables() effectue le gros travail d'extraction de toutes les tables de chaque page.
Bien que je ne sois pas vraiment familier avec la logique sous-jacente, je pense que la fonction a fait du plutôt bon travail. Par exemple, les deux instantanés ci-dessous montrent le tableau extrait par rapport à l'original (du PDF)
Instantané A : sortie du terminal VS Code

Instantané B : Tableau en PDF

J'ai ensuite dû étiqueter de manière unique chaque table, afin de pouvoir "sélectionner" des données dans des tables spécifiques plus tard.
L'option idéale était d'utiliser le titre de chaque tableau. Cependant, déterminer les coordonnées du titre dépassait mes capacités.
Pour contourner le problème, j'ai identifié chaque table en concaténant les en-têtes des trois premières colonnes. Par exemple, le tableau Stock Holdings dans Snapshot B est intitulé Stocks/ETFsnNameExchangeQuantity.
⚠️Cette approche présente un sérieux inconvénient : les trois premiers noms d'en-tête ne rendent pas toutes les tables suffisamment uniques. Heureusement, cela n'impacte que les tables non pertinentes.
Les valeurs spécifiques dont j'avais besoin - Numéro de compte et Date du relevé - étaient des sous-chaînes dans la page 1 de chaque PDF.
Par exemple, « Numéro de compte M1234567 » contient le numéro de compte « M1234567 ».

J'ai utilisé la bibliothèque re de Python et j'ai demandé à ChatGPT de suggérer des expressions régulières appropriées ("regex"). L'expression régulière divise chaque chaîne en deux groupes, avec les données souhaitées dans le deuxième groupe.
Regex pour les chaînes de date de relevé et de numéro de compte
# Open the PDF file with pdfplumber.open(file_path) as pdf:
J'ai ensuite transformé la date du relevé au format "aaaammjj". Cela facilite l'interrogation et le tri des données.
regex_date=r'Statement for \b([A-Za-z]{3}-\d{4})\b'
regex_acc_no=r'Account Number ([A-Za-z]\d{7})'
match_date est une variable déclarée lorsqu'une chaîne correspondant à l'expression régulière est trouvée.
Les travaux difficiles - l'extraction des points de données pertinents - étaient pratiquement terminés à ce stade.
Ensuite, j'ai utilisé la fonction DataFrame() de pandas pour créer des données tabulaires basées sur la sortie de l'Étape 2 et de l'Étape 3. J'ai également utilisé cette fonction pour supprimer les colonnes et les lignes inutiles.
Le résultat final peut ensuite être facilement écrit dans un CSV ou stocké dans une base de données.
J'ai utilisé la fonction write_to_csv() de Python pour écrire chaque trame de données dans un fichier CSV.
if match_date:
# Convert string to a mmm-yyyy date
date_obj=datetime.strptime(match_date.group(1),"%b-%Y")
# Get last day of the month
last_day=calendar.monthrange(date_obj.year,date_obj.month[1]
# Replace day with last day of month
last_day_of_month=date_obj.replace(day=last_day)
statement_date=last_day_of_month.strftime("%Y%m%d")
df_cash_selected est la trame de données Cash Holdings tandis que file_cash_holdings est le nom de fichier du CSV Cash Holdings.
➡️ J'écrirai les données dans une base de données appropriée une fois que j'aurai acquis un certain savoir-faire en matière de bases de données.
Un script fonctionnel est désormais en place pour extraire les données du tableau et du texte du PDF du relevé de garde.
Avant de continuer, je vais exécuter quelques tests pour voir si le script fonctionne comme prévu.
--Fin
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Raisons pour lesquelles la page d'accueil ne peut pas être modifiée
Raisons pour lesquelles la page d'accueil ne peut pas être modifiée
 Comment résoudre le problème de steam_api.dll manquant
Comment résoudre le problème de steam_api.dll manquant
 Ordinateur portable avec double carte graphique
Ordinateur portable avec double carte graphique
 Comment importer un ancien téléphone dans un nouveau téléphone à partir d'un téléphone mobile Huawei
Comment importer un ancien téléphone dans un nouveau téléphone à partir d'un téléphone mobile Huawei
 qu'est-ce que le pissenlit
qu'est-ce que le pissenlit
 horodatage python
horodatage python
 Où regarder les rediffusions en direct de Douyin
Où regarder les rediffusions en direct de Douyin
 Qu'est-ce qu'un équipement terminal ?
Qu'est-ce qu'un équipement terminal ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



