

Construire un agent d'échecs à l'aide de DQN

J'ai récemment essayé d'implémenter un agent d'échecs basé sur DQN.
Maintenant, quiconque sait comment fonctionnent les DQN et les échecs vous dira que c'est une idée stupide.
Et... ça l'était, mais en tant que débutant, j'ai néanmoins apprécié. Dans cet article, je partagerai les informations que j'ai apprises en travaillant là-dessus.
Comprendre l'environnement.
Avant de commencer à implémenter l'agent lui-même, j'ai dû me familiariser avec l'environnement que j'utiliserai et créer un wrapper personnalisé par-dessus afin qu'il puisse interagir avec l'agent pendant la formation.
-
J'ai utilisé l'environnement d'échecs de la bibliothèque kaggle_environments.
from kaggle_environments import make env = make("chess", debug=True)Copier après la connexionCopier après la connexion
-
J'ai également utilisé Chessnut, qui est une bibliothèque Python légère qui permet d'analyser et de valider les jeux d'échecs.
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
Copier après la connexionCopier après la connexion
Dans cet environnement, l'état de la carte est stocké au format FEN.

Il fournit un moyen compact de représenter toutes les pièces du plateau et le joueur actuellement actif. Cependant, comme j'avais prévu d'alimenter l'entrée d'un réseau de neurones, j'ai dû modifier la représentation de l'état.
Conversion de FEN au format Matrix
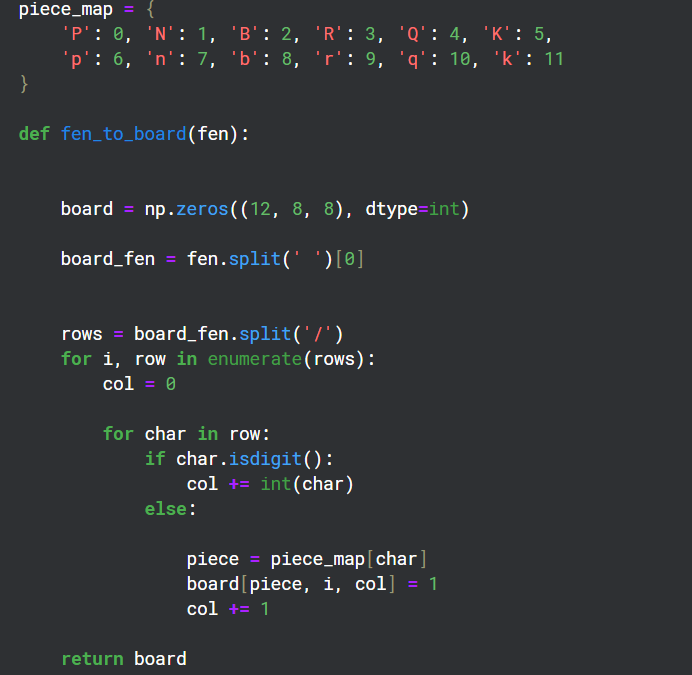
Comme il y a 12 types de pièces différents sur un plateau, j'ai créé 12 canaux de grilles 8x8 pour représenter l'état de chacun de ces types sur le plateau.
Créer un emballage pour l'environnement
class EnvCust:
def __init__(self):
self.env = make("chess", debug=True)
self.game=Game(env.state[0]['observation']['board'])
print(self.env.state[0]['observation']['board'])
self.action_space=game.get_moves();
self.obs_space=(self.env.state[0]['observation']['board'])
def get_action(self):
return Game(self.env.state[0]['observation']['board']).get_moves();
def get_obs_space(self):
return fen_to_board(self.env.state[0]['observation']['board'])
def step(self,action):
reward=0
g=Game(self.env.state[0]['observation']['board']);
if(g.board.get_piece(Game.xy2i(action[2:4]))=='q'):
reward=7
elif g.board.get_piece(Game.xy2i(action[2:4]))=='n' or g.board.get_piece(Game.xy2i(action[2:4]))=='b' or g.board.get_piece(Game.xy2i(action[2:4]))=='r':
reward=4
elif g.board.get_piece(Game.xy2i(action[2:4]))=='P':
reward=2
g=Game(self.env.state[0]['observation']['board']);
g.apply_move(action)
done=False
if(g.status==2):
done=True
reward=10
elif g.status == 1:
done = True
reward = -5
self.env.step([action,'None'])
self.action_space=list(self.get_action())
if(self.action_space==[]):
done=True
else:
self.env.step(['None',random.choice(self.action_space)])
g=Game(self.env.state[0]['observation']['board']);
if g.status==2:
reward=-10
done=True
self.action_space=list(self.get_action())
return self.env.state[0]['observation']['board'],reward,done
Le but de ce wrapper était de fournir une politique de récompense pour l'agent et une fonction étape qui est utilisée pour interagir avec l'environnement pendant la formation.
Chessnut était utile pour obtenir des informations telles que les mouvements légaux possibles dans l'état actuel du plateau et également pour reconnaître Checkmates pendant la partie.
J'ai essayé de créer une politique de récompense pour donner des points positifs pour les échecs et mats et l'élimination des pièces ennemies tandis que des points négatifs pour la perte de la partie.
Création d'un tampon de relecture
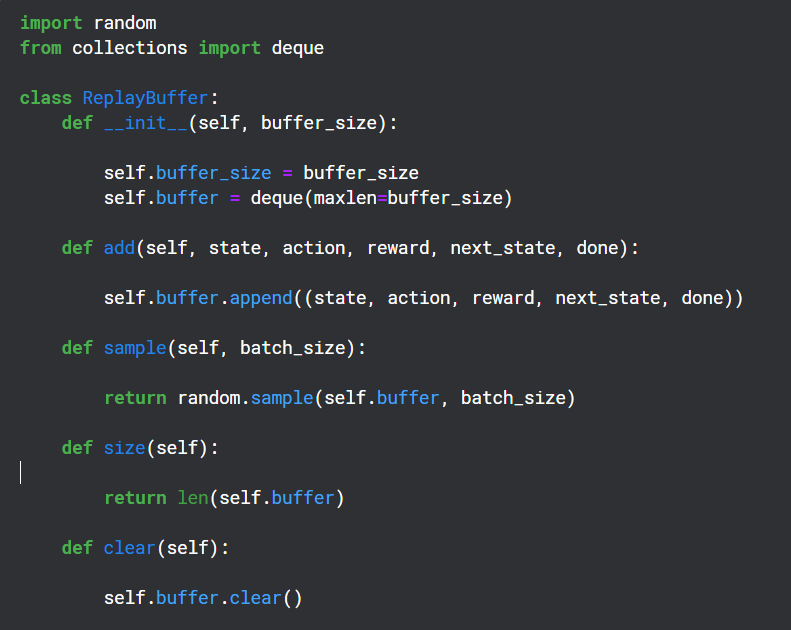
Le tampon de relecture est utilisé pendant la période d'entraînement pour enregistrer la sortie (état, action, récompense, état suivant) du réseau Q et est ensuite utilisé de manière aléatoire pour la rétropropagation du réseau cible
Fonctions auxiliaires


Chessnut renvoie une action en justice au format UCI qui ressemble à « a2a3 », mais pour interagir avec le réseau neuronal, j'ai converti chaque action en un index distinct en utilisant un modèle de base. Il y a un total de 64 carrés, j'ai donc décidé d'avoir 64*64 index uniques pour chaque mouvement.
Je sais que tous les mouvements 64*64 ne seraient pas légaux, mais je pouvais gérer la légalité en utilisant Chessnut et le modèle était assez simple.
Structure du réseau neuronal
from kaggle_environments import make
env = make("chess", debug=True)
Ce réseau neuronal utilise les couches convolutives pour prendre en compte l'entrée à 12 canaux et utilise également les index d'action valides pour filtrer la prédiction de sortie de récompense.
Implémentation de l'agent
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
Il s'agissait évidemment d'un modèle très basique qui n'avait aucune chance de bien fonctionner (et ce n'est pas le cas), mais cela m'a aidé à comprendre un peu mieux comment fonctionnent les DQN.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?
Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?
Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté lors de l'utilisation de FiddlereVerywhere pour les lectures d'homme dans le milieu lorsque vous utilisez FiddlereVerywhere ...
 Comment gérer les paramètres de requête de liste séparés par les virgules dans FastAPI?
Apr 02, 2025 am 06:51 AM
Comment gérer les paramètres de requête de liste séparés par les virgules dans FastAPI?
Apr 02, 2025 am 06:51 AM
Fastapi ...
 Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Utilisation de Python dans Linux Terminal ...
 Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?
Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?
Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans les 10 heures? Si vous n'avez que 10 heures pour enseigner à l'informatique novice des connaissances en programmation, que choisissez-vous d'enseigner ...
 La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
À propos de Pythonasyncio ...
 Comment obtenir des données d'information en contournant le mécanisme anti-frawler d'Investing.com?
Apr 02, 2025 am 07:03 AM
Comment obtenir des données d'information en contournant le mécanisme anti-frawler d'Investing.com?
Apr 02, 2025 am 07:03 AM
Comprendre la stratégie anti-rampe d'investissement.com, Beaucoup de gens essaient souvent de ramper les données d'actualités sur Investing.com (https://cn.investing.com/news/latest-news) ...
 Python 3.6 Chargement du fichier de cornichon MODULENOTFOUNDERROR: Que dois-je faire si je charge le fichier de cornichon '__builtin__'?
Apr 02, 2025 am 06:27 AM
Python 3.6 Chargement du fichier de cornichon MODULENOTFOUNDERROR: Que dois-je faire si je charge le fichier de cornichon '__builtin__'?
Apr 02, 2025 am 06:27 AM
Chargement du fichier de cornichon dans Python 3.6 Erreur d'environnement: modulenotFounonError: NomoduLenamed ...
 Quelle est la raison pour laquelle les fichiers de pipeline ne peuvent pas être écrits lors de l'utilisation du robot Scapy?
Apr 02, 2025 am 06:45 AM
Quelle est la raison pour laquelle les fichiers de pipeline ne peuvent pas être écrits lors de l'utilisation du robot Scapy?
Apr 02, 2025 am 06:45 AM
Discussion sur les raisons pour lesquelles les fichiers de pipelines ne peuvent pas être écrits lors de l'utilisation de robots scapisnels lors de l'apprentissage et de l'utilisation de Crawlers scapides pour un stockage de données persistant, vous pouvez rencontrer des fichiers de pipeline ...
