

Bonjour à tous ! Ceci est mon premier article.
Dans cet article, je vais vous présenter comment une instruction de requête SQL est exécutée
Ci-dessous le schéma de l'architecture MySQL :
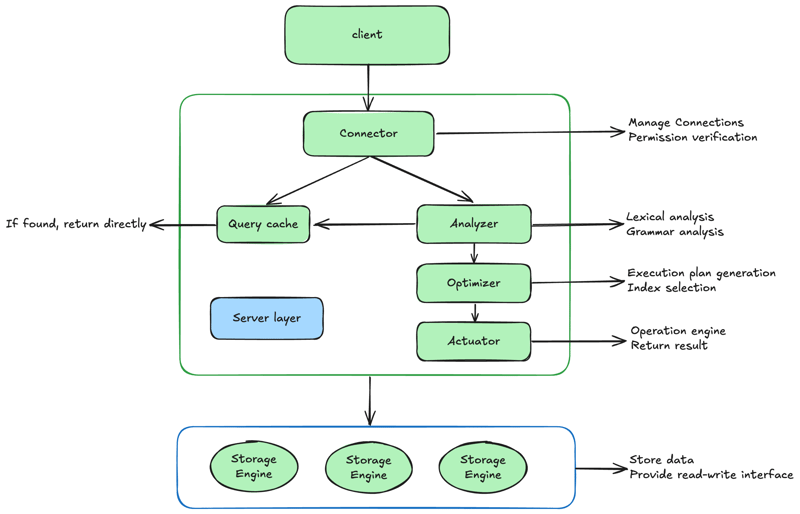
En général, MySQL peut être divisé en deux parties : le serveur et la couche moteur de stockage.
La couche serveur comprend le connecteur, le cache de requêtes, l'analyseur, l'optimiseur, l'exécuteur, etc., et contient la plupart des fonctions de base du service MySQL, ainsi que toutes les fonctions intégrées (telles que la date, l'heure, les mathématiques et le cryptage). fonctions). Toutes les fonctionnalités du moteur de stockage croisé, telles que les procédures stockées, les déclencheurs et les vues, sont implémentées au niveau de cette couche.
La couche moteur de stockage est responsable du stockage et de la récupération des données. Son architecture est basée sur des plugins, prenant en charge plusieurs moteurs de stockage tels que InnoDB, MyISAM, Memory. À partir de MySQL 5.5.5, InnoDB est devenu le moteur de stockage par défaut pour MySQL.
Vous pouvez spécifier le moteur de mémoire lors de la création d'une table en utilisant l'instruction create table avec engine=memory.
Différents moteurs de stockage partagent la même couche serveur
La première étape consiste à connecter la base de données, ce qui nécessite le connecteur. Le connecteur est responsable de l'établissement d'une connexion avec le client, de l'obtention des autorisations, ainsi que du maintien et de la gestion de la connexion. La commande de connexion est :
mysql -h$ip -P$port -u$user -p
Cette commande permet d'établir une connexion avec le serveur. Après avoir terminé la poignée de main TCP classique, le connecteur utilisera le nom d'utilisateur et le mot de passe du fournisseur pour authentifier votre identité.
Cela signifie qu'une fois la connexion établie avec succès, toute modification apportée par l'administrateur aux autorisations de l'utilisateur n'affectera pas les autorisations de la connexion existante. Seules les nouvelles connexions utiliseront les paramètres d'autorisation mis à jour.
Une fois la connexion établie, s'il n'y a aucune action ultérieure, la connexion entre dans un état inactif, qui peut être visualisé à l'aide de la commande show processlist :

Si le client reste inactif trop longtemps, le connecteur se déconnectera automatiquement. La durée est contrôlée par le paramètre wait_timeout, qui est par défaut de 8 heures.
Si la connexion est interrompue et que le client envoie une requête, il recevra un message d'erreur : Connexion perdue au serveur MySQL lors de la requête. Pour continuer, vous devez vous reconnecter puis exécuter la demande.
Dans les bases de données, une connexion persistante fait référence à une connexion dans laquelle le client maintient la même connexion pour les requêtes continues après une connexion réussie. Une connexion courte fait référence à une déconnexion après quelques requêtes et à une reconnexion pour les requêtes suivantes.
Le processus de connexion étant complexe, il est recommandé de minimiser la création de connexions pendant le développement, c'est-à-dire d'utiliser des connexions persistantes autant que possible.
Cependant, lors de l'utilisation de connexions persistantes, l'utilisation de la mémoire de MySQL peut augmenter considérablement car la mémoire temporaire utilisée lors de l'exécution est gérée au sein de l'objet de connexion. Ces ressources ne sont libérées qu'à la fin de la connexion. Si des connexions persistantes s'accumulent, cela peut entraîner une utilisation excessive de la mémoire, entraînant la fermeture forcée du système de MySQL (MOO), entraînant un redémarrage inattendu.
Solutions :
Remarque : à partir de MySQL 8.0, la fonctionnalité de cache de requêtes a été complètement supprimée car ses inconvénients l'emportent sur ses avantages.
Lorsque MySQL reçoit une requête de requête, il vérifie d'abord le cache de requête pour voir si cette requête a déjà été exécutée. Les requêtes qui ont déjà été exécutées et leurs résultats sont mis en cache en mémoire sous forme de paires clé-valeur. La clé est l'instruction de requête et la valeur est le résultat. Si la clé est trouvée dans le cache des requêtes, la valeur est renvoyée directement au client.
Si la requête n'est pas trouvée dans le cache des requêtes, le processus continue.
Pourquoi le cache de requêtes fait-il plus de mal que de bien ?
L'invalidation du cache des requêtes se produit très fréquemment. Toute mise à jour d'une table effacera tous les caches de requêtes liés à cette table, ce qui entraînera un taux de réussite du cache très faible, sauf si la table est une table de configuration statique.
MySQL fournit une méthode « à la demande » pour utiliser le cache de requêtes. En définissant le paramètre query_cache_type sur DEMAND, les instructions SQL n'utiliseront pas le cache de requêtes par défaut. Pour utiliser le cache de requêtes, vous pouvez spécifier explicitement SQL_CACHE :
mysql -h$ip -P$port -u$user -p
Si le cache de requêtes n'est pas atteint, le processus d'exécution de l'instruction commence. MySQL doit d'abord comprendre quoi faire, il analyse donc l'instruction SQL.
L'analyseur effectue d'abord une analyse lexicale. L'instruction SQL d'entrée, composée de chaînes et d'espaces, est analysée par MySQL pour identifier ce que représente chaque partie. Par exemple, select est identifié comme une instruction de requête, T comme nom de table et ID comme colonne.
Après l'analyse lexicale, une analyse syntaxique est effectuée. Sur la base des résultats de l'analyse lexicale, l'analyseur de syntaxe détermine si l'instruction SQL est conforme aux règles de syntaxe de MySQL.
S'il y a une erreur de syntaxe, un message d'erreur du type Vous avez une erreur dans votre syntaxe SQL s'affichera. Par exemple, dans la requête suivante, le mot-clé select est mal orthographié :
select SQL_CACHE * from T where ID=10;
Après l'analyse, MySQL sait ce que vous voulez faire. Ensuite, l'optimiseur détermine comment procéder.
L'optimiseur décide quel index utiliser lorsqu'une table a plusieurs index ou l'ordre des jointures de table lorsqu'une requête implique plusieurs tables. Par exemple, dans la requête suivante :
mysql> elect * from t where ID=1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1
La requête peut commencer par récupérer les valeurs de t1 ou t2. Les deux approches donnent le même résultat logique, mais leurs performances peuvent différer. Le rôle de l'optimiseur est de choisir le plan le plus efficace.
Après la phase d'optimisation, le processus passe à l'exécuteur testamentaire.
L'exécuteur commence à exécuter la requête.
Avant l'exécution, il vérifie d'abord si la connexion actuelle est autorisée à interroger la table. Dans le cas contraire, une erreur indiquant des autorisations insuffisantes est renvoyée. (Des vérifications d'autorisation sont également effectuées lors du renvoi des résultats du cache de requêtes.)
Si l'autorisation est accordée, la table est ouverte et l'exécution continue. Au cours de ce processus, l'exécuteur interagit avec le moteur de stockage en fonction de la définition du moteur de la table.
Par exemple, supposons que la table T n'ait pas d'index sur la colonne ID. Le processus d'exécution de l'exécuteur serait le suivant :
À ce stade, la requête est terminée.
Pour les tables indexées, le processus consiste à utiliser les méthodes prédéfinies du moteur pour récupérer la « première ligne correspondante » et les « lignes correspondantes suivantes » de manière itérative.
Dans le journal des requêtes lentes, le champ rows_examined indique le nombre de lignes analysées lors de l'exécution de la requête. Cette valeur s'accumule à chaque fois que l'exécuteur appelle le moteur pour récupérer une ligne de données.
Dans certains cas, un seul appel à l'exécuteur peut impliquer l'analyse de plusieurs lignes en interne au sein du moteur. Par conséquent, le nombre de lignes analysées par le moteur n'est pas nécessairement égal à rows_examined.
Merci d'avoir lu!J'espère que l'article pourra vous être utile.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles sont les méthodes de stockage des données ?
Quelles sont les méthodes de stockage des données ?
 Comment débloquer les restrictions d'autorisation Android
Comment débloquer les restrictions d'autorisation Android
 Quel logiciel est AE
Quel logiciel est AE
 Qu'est-ce qu'une procédure stockée MYSQL ?
Qu'est-ce qu'une procédure stockée MYSQL ?
 Comment vérifier les enregistrements d'appels supprimés
Comment vérifier les enregistrements d'appels supprimés
 Windows ne peut pas terminer la solution de formatage du disque dur
Windows ne peut pas terminer la solution de formatage du disque dur
 Comment acheter et vendre du Bitcoin sur la plateforme Ouyi
Comment acheter et vendre du Bitcoin sur la plateforme Ouyi
 Introduction aux logiciels de modélisation paramétrique
Introduction aux logiciels de modélisation paramétrique








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



