

Nos sites Web actuels s'appuient généralement sur des dizaines de ressources différentes, telles qu'une collection monolithique d'images, CSS, polices, JavaScript, données JSON, etc. Cependant, le premier site Web au monde a été écrit uniquement en HTML.
JavaScript, en tant qu'excellent langage de script côté client, a joué un rôle important dans l'évolution des sites Web. À l'aide d'objets XMLHttpRequest ou XHR, JavaScript peut établir une communication entre clients et serveurs sans recharger la page.
Cependant, ce processus dynamique est remis en question par l'API Fetch. Qu’est-ce que l’API Fetch ? Comment utiliser l'API Fetch dans Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? ? Pourquoi l'API Fetch est-elle un meilleur choix ?
Commencez à obtenir des réponses à partir de cet article dès maintenant !
Dans Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ?, les requêtes HTTP sont un élément fondamental de la création d'applications Web ou de l'interaction avec des services Web. Ils permettent à un client (comme un navigateur ou une autre application) d'envoyer des données à un serveur ou de demander des données à un serveur. Ces requêtes utilisent le protocole de transfert hypertexte (HTTP), qui constitue le fondement de la communication de données sur le Web.
Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? est devenu l'une des technologies incontournables pour les tâches de web scraping et d'automatisation en raison de ses caractéristiques uniques, de son écosystème robuste et de son architecture asynchrone et non bloquante.
Pourquoi Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? est idéal pour le web scraping et l'automatisation ? Trouvons-les !
Node-fetch est un module léger qui apporte l'API Fetch à l'environnement Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ?. Cela simplifie le processus de création de requêtes HTTP et de traitement des réponses.
L'API Fetch est construite autour de Promises et est bien adaptée aux opérations asynchrones telles que la récupération de données d'un site Web, l'interaction avec une API RESTful ou l'automatisation de tâches.
L'API Fetch est une interface moderne basée sur Promise, conçue pour gérer les requêtes réseau de manière plus efficace et plus flexible que l'objet XMLHttpRequest traditionnel.
Il est pris en charge nativement dans les navigateurs contemporains, ce qui signifie qu'il n'y a pas besoin de bibliothèques ou de plugins supplémentaires. Dans ce guide, nous explorerons comment utiliser l'API Fetch pour effectuer des requêtes GET et POST, ainsi que comment gérer efficacement les réponses et les erreurs.
? Remarque : Si Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? n'est pas installé sur votre ordinateur, vous devez d'abord l'installer. Vous pouvez télécharger ici le package d'installation Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? adapté à votre système d'exploitation. La version recommandée de Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? est 18 et supérieure.
Si vous n'avez pas encore créé de projet, vous pouvez créer un nouveau projet avec la commande suivante :
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Ouvrez le fichier package.json, ajoutez le champ type et définissez-le sur module :
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Il s'agit d'une bibliothèque permettant d'utiliser l'API Fetch dans Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ?. Vous pouvez installer la bibliothèque node-fetch avec la commande suivante :
npm install node-fetch
Une fois le téléchargement terminé, nous pouvons commencer à utiliser l'API Fetch pour envoyer des requêtes réseau. Créez un nouveau fichier index.js dans le répertoire racine du projet et ajoutez le code suivant :
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));
Exécutez la commande suivante pour exécuter le code :
node index.js
Nous verrons le résultat suivant :

Comment utiliser l'API Fetch pour envoyer la requête POST ? Veuillez vous référer à la méthode suivante. Créez un nouveau fichier post.js dans le répertoire racine du projet et ajoutez le code suivant :
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));
Analysons ce code :
Exécutez la commande suivante pour exécuter le code :
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Le résultat que vous pouvez voir :

Nous devons créer un nouveau fichier réponse.js dans le répertoire racine du projet et ajouter le code suivant :
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Dans le code ci-dessus, nous remplissons d'abord une adresse URL incorrecte pour déclencher une erreur HTTP. Ensuite, nous vérifions le code d'état de la réponse résultante dans la méthode then et renvoyons une erreur si le code d'état n'est pas 200. Enfin, nous captons l'erreur dans la méthode catch et l'imprimons.
Exécutez la commande suivante pour exécuter le code :
npm install node-fetch
Une fois le code exécuté, vous verrez le résultat suivant :

Les CAPTCHA (tests de Turing publics entièrement automatisés pour distinguer les ordinateurs des humains) sont conçus pour empêcher les systèmes automatisés, comme les grattoirs Web, d'accéder aux sites Web. Ils exigent généralement que les utilisateurs prouvent qu'ils sont humains en résolvant des énigmes, en identifiant des objets dans des images ou en saisissant des caractères déformés.
De nombreux sites Web modernes utilisent des frameworks JavaScript comme React, Angular ou Vue.js pour charger du contenu de manière dynamique. Cela signifie que le contenu que vous voyez dans le navigateur est souvent affiché après le chargement de la page, ce qui rend difficile le scraping avec les méthodes traditionnelles qui reposent sur du HTML statique.
Les sites Web mettent souvent en œuvre des mesures pour détecter et bloquer les activités de scraping, l'une des méthodes les plus courantes étant le blocage des adresses IP. Cela se produit lorsque trop de requêtes sont envoyées à partir de la même adresse IP sur une courte période, ce qui amène le site Web à signaler et à bloquer cette adresse IP.
Scrapeless est l'un des meilleurs outils de scraping complets en raison de sa capacité à contourner les blocages de sites Web en temps réel, y compris le blocage IP, les défis CAPTCHA et le rendu JavaScript. Il prend en charge des fonctionnalités avancées telles que la rotation IP, la gestion des empreintes digitales TLS et la résolution CAPTCHA, ce qui le rend idéal pour le scraping Web à grande échelle.
Son intégration facile avec Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? et son taux de réussite élevé pour éviter la détection font de Scrapeless un choix fiable et efficace pour contourner les défenses anti-bots modernes, garantissant des opérations de scraping fluides et ininterrompues.
Suivez simplement quelques étapes simples, vous pouvez intégrer Scrapeless dans votre projet Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ?.
Il est temps de continuer à faire défiler ! Ce qui suit sera encore plus merveilleux !
Avant de commencer, vous devez créer un compte Scrapeless.
Nous devons accéder au tableau de bord Scrapeless, cliquer sur le menu "API Scraping" sur la gauche, puis sélectionner un service que vous souhaitez utiliser.
Ici, nous pouvons utiliser le service "Amazon"

En entrant sur la page API Amazon, nous pouvons voir que Scrapeless nous a fourni des paramètres par défaut et des exemples de code en trois langues :
Ici, nous choisissons Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? et copions l'exemple de code dans notre projet :
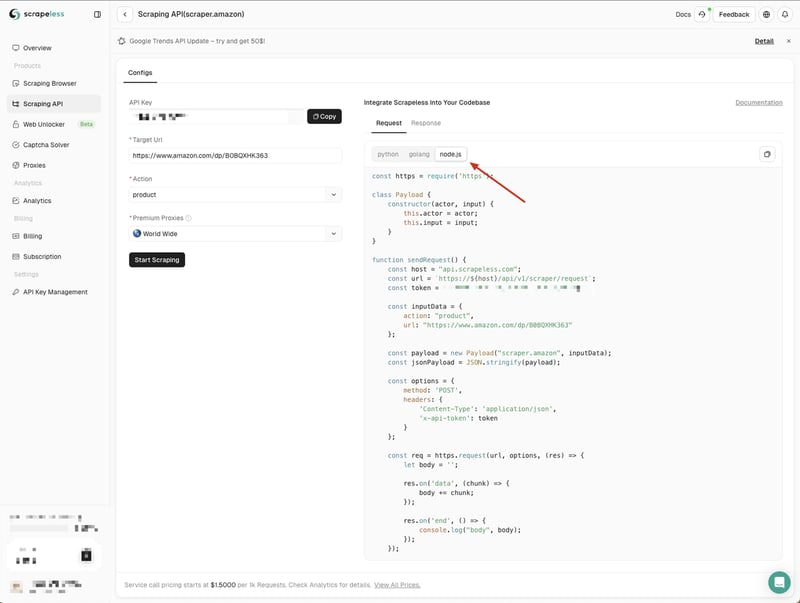
Les exemples de code Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? de Scrapeless utilisent le module http par défaut. Nous pouvons utiliser le module node-fetch pour remplacer le module http, afin de pouvoir utiliser l'API Fetch pour envoyer des requêtes réseau.
Tout d'abord, créez un fichier scraping-api-amazon.js dans notre projet, puis remplacez les exemples de code fournis par Scrapeless par les exemples de code suivants :
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Exécutez le code en exécutant la commande suivante :
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Nous verrons les résultats renvoyés par l'API Scrapeless. Ici, nous les imprimons simplement. Vous pouvez traiter les résultats renvoyés selon vos besoins.

Scrapeless fournit un service Web unlocker qui peut vous aider à contourner les mesures anti-scraping courantes, telles que le contournement CAPTCHA, le blocage IP, etc. Le service Web unlocker peut vous aider à résoudre certains problèmes d'exploration courants et à créer vos tâches d'exploration plus fluides.
Pour vérifier l'efficacité du service Web unlocker, nous pouvons d'abord utiliser la commande curl pour accéder à un site Web qui nécessite un CAPTCHA, puis utiliser le service Scrapeless Web unlocker pour accéder au même site Web et voir si le CAPTCHA peut être réussi. contourné.
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
En examinant les résultats renvoyés, nous pouvons voir que ce site Web est connecté au mécanisme de vérification Cloudflare, et nous devons saisir le code de vérification pour continuer à accéder au site Web.


Ici, nous créons un nouveau fichier web-unlocker.js. Nous devons toujours utiliser le module node-fetch pour envoyer des requêtes réseau, nous devons donc remplacer le module http dans l'exemple de code fourni par Scrapeless par le module node-fetch :
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Exécutez la commande suivante pour exécuter le script :
npm install node-fetch


Regardez ! Scrapeless Web Unlocker a réussi à contourner le code de vérification et nous pouvons voir que les résultats renvoyés contiennent le contenu de la page Web dont nous avons besoin.
Pour faciliter votre choix, Axios et Fetch API présentent les différences suivantes :
La fonctionnalité la plus notable de Node. js v21 est la stabilisation de l'API Fetch.
Pour les nouveaux projets, il est recommandé d'utiliser l'API Fetch en raison de ses fonctionnalités modernes et de sa simplicité. Cependant, si vous devez prendre en charge des navigateurs très anciens ou si vous conservez du code existant, Ajax peut toujours être nécessaire.
L'ajout de l'API Fetch dans Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? est une fonctionnalité très attendue. L'utilisation de l'API Fetch dans Comment effectuer des requêtes HTTP dans Node.js avec lAPI Node-Fetch ? peut garantir que votre travail de scraping est effectué facilement. Cependant, il est inévitable de rencontrer de graves blocages de réseau lors de l'utilisation de l'API Node Fetch.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre nohup et &
La différence entre nohup et &
 Méthodes de codage courantes
Méthodes de codage courantes
 Explication détaillée de la fonction fork Linux
Explication détaillée de la fonction fork Linux
 Quel est l'impact de la fermeture du port 445 ?
Quel est l'impact de la fermeture du port 445 ?
 Quelle est la différence entre les espaces pleine largeur et les espaces demi-largeur ?
Quelle est la différence entre les espaces pleine largeur et les espaces demi-largeur ?
 ps supprimer la zone sélectionnée
ps supprimer la zone sélectionnée
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Sinon, utilisation dans la structure de boucle Python
Sinon, utilisation dans la structure de boucle Python








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



