
 développement back-end
Tutoriel Python
Analyser mon score Oura Sleep - est-ce AI ou simplement mathématiques?
développement back-end
Tutoriel Python
Analyser mon score Oura Sleep - est-ce AI ou simplement mathématiques?
Analyser mon score Oura Sleep - est-ce AI ou simplement mathématiques?

Aujourd'hui, je me suis plongé dans les données du score de sommeil de notre anneau Oura, invitant une question cruciale: ce problème nécessite-t-il une IA, ou une formule simple suffira-t-elle?

Le suivi des activités et la bague Oura
Je suis un amateur de santé basé sur les données, en utilisant des trackers de fitness comme Fitbit et Garmin. Cependant, pour l'usure quotidienne, je préfère la bague Oura pour sa conception discrète. Le suivi du sommeil est une caractéristique clé, ce qui rend son score de sommeil digne d'enquête. (Pour ceux qui ne sont pas familiers, le score de sommeil de Oura est détaillé sur leur blog.)
Le score de sommeil énigmatique
Un inconvénient de Oura est ses idées de murs payantes. La version gratuite affiche uniquement le score de sommeil, contrairement aux tableaux de bord complets de Fitbit et Garmin. Cela soulève la question: qu'est-ce qui rend ce score de sommeil si spécial, et l'abonnement en vaut-il la peine?
L'hypothèse: corrélations simples
Mon hypothèse initiale, en tant que data scientist, était simple: une durée plus élevée du sommeil profond et une plus grande fréquence cardiaque moyenne sont en corrélation avec de meilleurs scores de sommeil. Cela pourrait-il être aussi simple? Découvrons.
Acquisition et traitement des données
J'ai accédé à mes données Oura via leur API de développeur, récupérant les données du sommeil et les enregistrant en tant que fichier JSON.
def get_data(type):
url = 'https://api.ouraring.com/v2/usercollection/' + type
params={
'start_date': '2021-11-01',
'end_date': '2025-01-01'
}
headers = {
'Authorization': 'Bearer ' + auth_token
}
response = requests.request('GET', url, headers=headers, params=params)
return response.json()["data"]
data = get_data("sleep")
with open('oura_data_sleep.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)Ces données ont ensuite été indexées dans Elasticsearch pour une requête facile. La structure JSON a simplifié ce processus, ne nécessitant aucun mappage ou nettoyage supplémentaire de données.
client = Elasticsearch(
cloud_id=ELASTIC_CLOUD_ID,
api_key=ELASTIC_API_KEY
)
index_name = 'oura-history-sleep'
# ... (Elasticsearch index creation and data loading code) ...L'expérience: requêtes simples
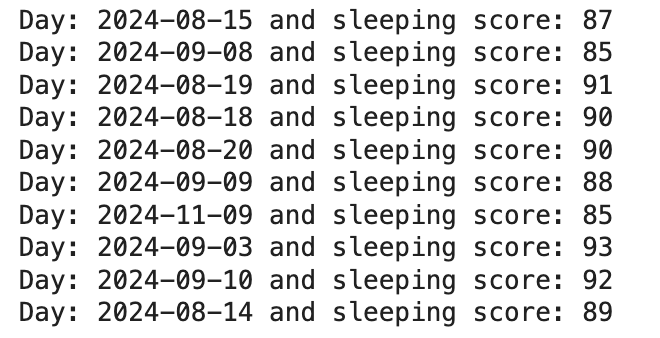
Mon expérience a impliqué des requêtes simples pour tester mon hypothèse. J'ai trié les premiers jours par un score de sommeil le plus élevé:
response = client.search(index = index_name, sort="readiness.score:desc") # ... (Code to print day and sleep score) ...

L'examen de ces jours à haut score a révélé des schémas cohérents dans le sommeil profond et la fréquence cardiaque. Ensuite, j'ai construit un filtrage de requête Elasticsearch pour un sommeil profond sur 1,5 heure et une fréquence cardiaque sous 60 bpm, triée par sommeil REM:
query = {
"range" : {
"deep_sleep_duration" : {
"gte" : 1.5*3600
}
},
"range" : {
"average_heart_rate":{
"lte" : 60
}
}
}
response = client.search(index = index_name, query=query, sort="rem_sleep_duration:desc") 
Les résultats sont fortement corrélés avec les jours initiaux à score élevé. Bien qu'il ne soit pas parfait, cela démontre le pouvoir prédictif d'une formule simple. D'autres visualisations kibana (illustrées ci-dessous) renforcent cette connexion.
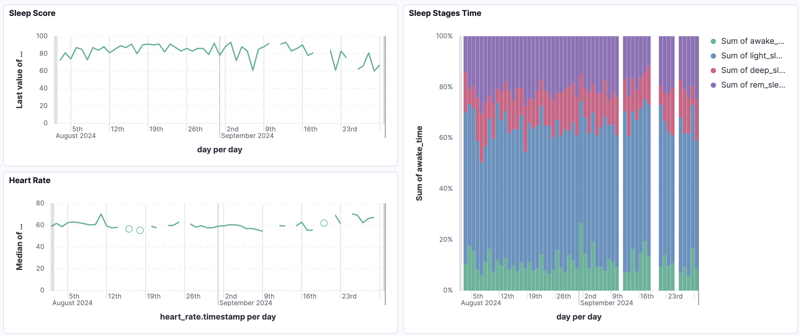
La signification
Dans le battage médiatique entourant l'IA, il est facile d'oublier des solutions plus simples. Ce score de sommeil, souvent présenté comme une réussite complexe de l'IA, est essentiellement basé sur une formule simple. Cela met en évidence l'importance de comprendre lorsque des méthodes plus simples sont suffisantes - conduisant à des résultats plus précis, rentables et facilement interprétables. Cela souligne la valeur durable des principes fondamentaux de la science des données et de la modélisation intuitive. Bien que la technologie avancée soit impressionnante, savoir quand pas l'utiliser est tout aussi crucial.
Voir le carnet de code complet ici.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Solution aux problèmes d'autorisation Lors de la visualisation de la version Python dans Linux Terminal Lorsque vous essayez d'afficher la version Python dans Linux Terminal, entrez Python ...
 Comment copier efficacement la colonne entière d'une dataframe dans une autre dataframe avec différentes structures dans Python?
Apr 01, 2025 pm 11:15 PM
Comment copier efficacement la colonne entière d'une dataframe dans une autre dataframe avec différentes structures dans Python?
Apr 01, 2025 pm 11:15 PM
Lorsque vous utilisez la bibliothèque Pandas de Python, comment copier des colonnes entières entre deux frames de données avec différentes structures est un problème courant. Supposons que nous ayons deux dats ...
 Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?
Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?
Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans les 10 heures? Si vous n'avez que 10 heures pour enseigner à l'informatique novice des connaissances en programmation, que choisissez-vous d'enseigner ...
 Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?
Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?
Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté lors de l'utilisation de FiddlereVerywhere pour les lectures d'homme dans le milieu lorsque vous utilisez FiddlereVerywhere ...
 Que sont les expressions régulières?
Mar 20, 2025 pm 06:25 PM
Que sont les expressions régulières?
Mar 20, 2025 pm 06:25 PM
Les expressions régulières sont des outils puissants pour la correspondance des motifs et la manipulation du texte dans la programmation, améliorant l'efficacité du traitement de texte sur diverses applications.
 Quelles sont les bibliothèques Python populaires et leurs utilisations?
Mar 21, 2025 pm 06:46 PM
Quelles sont les bibliothèques Python populaires et leurs utilisations?
Mar 21, 2025 pm 06:46 PM
L'article traite des bibliothèques Python populaires comme Numpy, Pandas, Matplotlib, Scikit-Learn, Tensorflow, Django, Flask et Demandes, détaillant leurs utilisations dans le calcul scientifique, l'analyse des données, la visualisation, l'apprentissage automatique, le développement Web et H et H
 Comment Uvicorn écoute-t-il en permanence les demandes HTTP sans servir_forever ()?
Apr 01, 2025 pm 10:51 PM
Comment Uvicorn écoute-t-il en permanence les demandes HTTP sans servir_forever ()?
Apr 01, 2025 pm 10:51 PM
Comment Uvicorn écoute-t-il en permanence les demandes HTTP? Uvicorn est un serveur Web léger basé sur ASGI. L'une de ses fonctions principales est d'écouter les demandes HTTP et de procéder ...
 Comment créer dynamiquement un objet via une chaîne et appeler ses méthodes dans Python?
Apr 01, 2025 pm 11:18 PM
Comment créer dynamiquement un objet via une chaîne et appeler ses méthodes dans Python?
Apr 01, 2025 pm 11:18 PM
Dans Python, comment créer dynamiquement un objet via une chaîne et appeler ses méthodes? Il s'agit d'une exigence de programmation courante, surtout si elle doit être configurée ou exécutée ...
