


(Cet article a été initialement publié par Ampere Computing)
Votre application s'exécute sur une nouvelle instance ou serveur cloud (ou SUT, système testé), vous trouvez des problèmes de performances, ou vous souhaitez assurer des performances optimales sous les ressources système disponibles. Cet article traite de certaines questions de base que vous devriez poser et des moyens d'y répondre.
Prérequis: Comprenez votre machine virtuelle ou votre serveur
Vous devez connaître les ressources du système disponibles avant de démarrer un dépannage ou effectuer un exercice d'analyse des performances. Les performances au niveau du système se résument généralement à quatre composants et à leurs interactions - CPU, mémoire, réseau et disque. Voir également l'excellent article de Brendan Gregg "Linux Performance Analysis: 60000 millisecond Quick Result Guide", un excellent point de départ pour évaluer rapidement les problèmes de performance.
Cet article explique comment comprendre les problèmes de performance plus profondément.
Confirmer le type CPU
Exécutez la commande $lscpu, qui affichera le type de processeur, la fréquence du processeur, le nombre de cœurs et d'autres informations liées au CPU:
<code>ampere@colo1:~$ lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 160
On-line CPU(s) list: 0-159
Thread(s) per core: 1
Core(s) per socket: 80
Socket(s): 2
NUMA node(s): 2
Vendor ID: ARM
Model: 1
Model name: Neoverse-N1
Stepping: r3p1
CPU max MHz: 3000.0000
CPU min MHz: 1000.0000
BogoMIPS: 50.00
L1d cache: 10 MiB
L1i cache: 10 MiB
L2 cache: 160 MiB
NUMA node0 CPU(s): 0-79
NUMA node1 CPU(s): 80-159
Vulnerability Itlb multibit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Mitigation; CSV2, BHB
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid
asimdrdm lrcpc dcpop asimddp ssbs </code>Confirmer la configuration de la mémoire
Exécutez la commande $free, qui fournira des informations sur la mémoire physique et la quantité totale de mémoire d'échange (y compris une ventilation de l'utilisation de la mémoire). Exécutez le benchmark multichase pour déterminer la latence, la bande passante de mémoire et le chargement de latence par exemple / SUT:
<code>ampere@colo1:~$ free
total used free shared buff/cache available
Mem: 130256992 3422844 120742736 4208 6091412 125852984
Swap: 8388604 0 8388604
</code>Évaluer les capacités du réseau
Exécutez la commande $ethtool, qui fournira des informations sur les paramètres du matériel de la carte NIC. Il est également utilisé pour contrôler les pilotes de périphérique réseau et les paramètres matériels. Si vous exécutez une charge de travail dans un modèle client-serveur, il est préférable de comprendre la bande passante et la latence entre le client et le serveur. Pour déterminer la bande passante, un simple test IPERF3 est suffisant et pour la latence, un test de ping simple peut fournir cette valeur. Dans les paramètres du client-serveur, il est également recommandé de maintenir le nombre de sauts de réseau au minimum. Traceroute est une commande de diagnostic réseau qui affiche le routage et mesure le retard de transmission des paquets à travers le réseau:
<code>ampere@colo1:~$ ethtool -i enp1s0np0 driver: mlx5_core version: 5.7-1.0.2 firmware-version: 16.32.1010 (RCP0000000001) expansion-rom-version: bus-info: 0000:01:00.0 supports-statistics: yes supports-test: yes supports-eeprom-access: no supports-register-dump: no supports-priv-flags: yes> </code>
Comprendre l'infrastructure de stockage
Avant de commencer à exécuter une charge de travail, il est crucial de comprendre les fonctionnalités du disque. Comprendre le débit et la latence des systèmes de disque et de fichiers vous aideront à planifier et à concevoir efficacement vos charges de travail. Les E / S flexibles (ou "FIO") sont un outil idéal pour déterminer ces valeurs.
Entrez maintenant dans les dix premières questions
L'une des principales composantes du coût total de possession est le processeur. Par conséquent, il vaut la peine de comprendre l'efficacité de l'utilisation du processeur. Un CPU inactif signifie généralement qu'il existe des dépendances externes, comme l'attente de l'accès au disque ou au réseau. Il est toujours recommandé de surveiller l'utilisation du processeur et de vérifier que l'utilisation du noyau est uniforme.
L'image suivante montre un exemple de sortie de la commande $top -1.

Les CPU modernes utilisent l'état P pour ajuster la fréquence et la tension de leur fonctionnement pour réduire la consommation d'énergie du CPU lorsque des fréquences plus élevées ne sont pas nécessaires. C'est ce qu'on appelle la tension dynamique et l'échelle de fréquence (DVFS) et est gérée par le système d'exploitation. Dans Linux, l'état P est géré par le sous-système CPUFREQ, qui utilise différents algorithmes (appelés régulateurs) pour déterminer la fréquence de l'exécution du CPU. En général, pour les applications sensibles à la performance, il est préférable de vous assurer d'utiliser un régulateur de performances, et la commande suivante utilise l'utilitaire CPUPOWER pour y parvenir. N'oubliez pas que l'utilisation de la fréquence du CPU devrait s'exécuter dépend de la charge de travail:
<code>ampere@colo1:~$ lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 160
On-line CPU(s) list: 0-159
Thread(s) per core: 1
Core(s) per socket: 80
Socket(s): 2
NUMA node(s): 2
Vendor ID: ARM
Model: 1
Model name: Neoverse-N1
Stepping: r3p1
CPU max MHz: 3000.0000
CPU min MHz: 1000.0000
BogoMIPS: 50.00
L1d cache: 10 MiB
L1i cache: 10 MiB
L2 cache: 160 MiB
NUMA node0 CPU(s): 0-79
NUMA node1 CPU(s): 80-159
Vulnerability Itlb multibit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Mitigation; CSV2, BHB
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid
asimdrdm lrcpc dcpop asimddp ssbs </code>Pour vérifier la fréquence du CPU lors de l'exécution de l'application, exécutez la commande suivante:
<code>ampere@colo1:~$ free
total used free shared buff/cache available
Mem: 130256992 3422844 120742736 4208 6091412 125852984
Swap: 8388604 0 8388604
</code>Parfois, il est nécessaire de savoir si le pourcentage de temps de CPU est consommé dans l'espace utilisateur ou en temps privilégié (c'est-à-dire l'espace du noyau). Le temps de noyau plus élevé peut être raisonnable pour certaines catégories de charges de travail (telles que les charges de travail de liaison du réseau), mais peut également indiquer un problème.
Le haut de l'application Linux peut être utilisé pour savoir combien de temps le temps de l'utilisateur et du noyau est consommé, comme indiqué ci-dessous.
mpstat - Vérifiez les statistiques de chaque processeur et vérifiez les processeurs Hotspot / animés individuels. Il s'agit d'un outil de statistiques multiprocesseurs qui rapporte des statistiques pour chaque CPU (Option -P)

Pour identifier l'utilisation du processeur pour chaque CPU et afficher le rapport temps / temps de base,% USR,% SYS et% IDLE sont les valeurs clés. Ces valeurs clés peuvent également aider à identifier les processeurs "hotspots" qui peuvent être causés par des applications unique ou des mappages d'interruption.
Lorsque vous gérez le serveur, vous devrez peut-être installer une nouvelle application, ou vous remarquerez peut-être que l'application a commencé à ralentir. Pour gérer les ressources système et comprendre la mémoire système et l'utilisation de la mémoire système que le système a installé, la commande $free est un outil précieux. $vmstat est également un outil précieux pour surveiller l'utilisation de la mémoire, surtout si vous échangez activement de la mémoire avec une mémoire virtuelle.
free. La commande Linux free affiche des statistiques de mémoire et d'échange.

affiche la mémoire totale, la mémoire utilisée et la mémoire disponible du système. Une colonne importante est la valeur disponible, qui montre la mémoire disponible pour l'application et doit être échangée. Il considère également la mémoire qui ne peut pas être recyclée immédiatement.
vmstat. Cette commande fournit une vue de haut niveau de la mémoire du système, de la santé, y compris des statistiques de mémoire et de pagination actuellement disponibles.
$vmstat affiche la mémoire active échangée (pagination).

Ces commandes impriment un résumé de l'état actuel. La colonne par défaut est des kilo-great, qui sont:
Si SI et non nul, le système est sous pression de mémoire et échange de la mémoire sur le périphérique d'échange.
Pour comprendre suffisamment de bande passante de mémoire, obtenez d'abord la valeur "maximum de bande passante". La valeur "maximum de bande passante" peut être trouvée de la manière suivante:
Cette valeur représente la bande passante maximale théorique du système, également connu sous le nom de "taux d'éclatement". Vous pouvez désormais exécuter des références Multichase ou Bandwidth sur votre système et vérifier ces valeurs.
Remarque: Le taux de rafale s'est avéré non durable et les valeurs implémentées peuvent être légèrement inférieures aux valeurs calculées.
Lors de l'exécution d'une charge de travail sur un serveur, dans le cadre du réglage des performances ou du dépannage, vous pouvez savoir quel noyau CPU un processus particulier est actuellement planifié et comment l'utilisation des ressources des processus fonctionnant sur ce noyau CPU. La première étape consiste à trouver le processus en cours d'exécution sur le noyau du CPU. Cela peut être fait en utilisant HTOP. Les valeurs du CPU ne sont pas reflétées dans l'affichage par défaut de HTOP. Pour obtenir la valeur centrale du CPU, démarrez $htop à partir de la ligne de commande, appuyez sur f2 , accédez aux colonnes et ajoutez le processeur sous les colonnes disponibles. L'ID "CPU" actuellement utilisé par chaque processus apparaîtra sous la colonne "CPU".
comment configurer $htop pour afficher le processeur / noyau:

Afficher le noyau 4-6 La commande $htop pour atteindre la valeur maximale (le nombre de noyau htop commence à "1" au lieu de "0"):

$mpstat Commande pour vérifier les cœurs sélectionnés des statistiques:

Une fois que vous avez identifié le noyau du CPU, vous pouvez exécuter la commande $mpstat pour vérifier les statistiques de chaque CPU et vérifier les processeurs Hotspot / occupés individuels. Il s'agit d'un outil de statistiques multiprocesseurs qui signale les statistiques pour chaque processeur (ou noyau). Pour plus d'informations sur $mpstat, consultez le "comment puis-je passer du temps dans mon application par rapport au temps du noyau?"
Les goulots d'étranglement du réseau peuvent se produire avant même de saturer d'autres ressources sur le serveur. Ce problème est découvert lors de l'exécution de charges de travail dans le modèle client-serveur. La première chose que vous devez faire est de déterminer à quoi ressemble votre réseau. La latence et la bande passante entre les clients et les serveurs sont particulièrement importantes. Des outils comme IPERF3, Ping et Traceroute sont des outils simples qui peuvent vous aider à déterminer les limites de votre réseau. Une fois que les limitations du réseau ont été identifiées, des outils comme $dstat et $nicstat peuvent vous aider à surveiller l'utilisation du réseau et à identifier les goulots d'étranglement du système en raison du réseau.
dstat. Cette commande est utilisée pour surveiller les ressources système, y compris les statistiques du processeur, les statistiques du disque, les statistiques du réseau, les statistiques de pagination et les statistiques système. Pour surveiller l'utilisation du réseau, utilisez l'option -N.

Cette commande fournira le débit des paquets reçus et envoyés par le système.
nicstat. Cette commande imprime les statistiques d'interface réseau, y compris le débit et l'utilisation.

Les colonnes incluent:
Comme les réseaux, les disques peuvent également être la raison de mauvaises performances d'application. Lors de la mesure des performances du disque, nous examinons les mesures suivantes:
Une bonne règle est que lorsque vous sélectionnez un serveur / instance pour votre application, vous devez d'abord comparer les performances d'E / S du disque afin que vous puissiez obtenir un pic ou une "limite supérieure" des performances du disque et être en mesure de déterminer le disque si la performance répond aux besoins de la demande. Les E / S flexibles sont un outil idéal pour déterminer ces valeurs.
Une fois le Une fois l'application en cours d'exécution, vous pouvez utiliser $iostat et $dstat pour surveiller l'utilisation des ressources du disque en temps réel.
iostat affiche des statistiques d'E / S pour chaque disque, fournissant des mesures pour la caractérisation, l'utilisation et la saturation de la charge de travail.

La première sortie de ligne affiche un résumé du système, y compris la version du noyau, le nom d'hôte, l'architecture de données et le nombre de processeurs. La deuxième ligne montre le résumé du CPU du système depuis le démarrage.
Pour chaque périphérique de disque affiché dans la ligne suivante, il affiche les détails de base dans la colonne:
dstat sont utilisées pour surveiller les ressources du système, y compris les statistiques du processeur, les statistiques du disque, les statistiques du réseau, les statistiques de pagination et les statistiques système. Pour surveiller l'utilisation du disque, utilisez l'option -D. Cette option affiche le nombre total d'opérations de lecture (lecture) et d'écriture (écrite) sur le disque.
L'image suivante montre des charges de travail à forte intensité d'écriture.

L'accès à la mémoire non cohérente (NUMA) est une conception de mémoire de l'ordinateur pour le multiprocessement, où le temps d'accès à la mémoire dépend de l'emplacement de la mémoire par rapport au processeur. Sous NUMA, un processeur peut accéder à sa propre mémoire locale plus rapidement que la mémoire non locale (mémoire locale d'un autre processeur ou mémoire partagée entre les processeurs). Les avantages de NUMA sont limités aux charges de travail, en particulier sur les serveurs, où les données sont souvent étroitement liées à certaines tâches ou utilisateurs.
sur les systèmes NUMA, plus la distance entre le processeur et sa banque de mémoire est élevée, plus le processeur accédera lent à cette banque de mémoire. Pour les applications sensibles à la performance, le système d'exploitation du système doit allouer la mémoire de la banque de mémoire la plus proche. Pour surveiller l'allocation de mémoire d'un système ou d'un processus en temps réel, $numastat est un excellent outil.
numastat fournit des statistiques pour les systèmes d'accès à la mémoire non cohérents (NUMA). Ces systèmes sont généralement des systèmes avec plusieurs emplacements CPU.

Le système d'exploitation Linux essaie d'allouer la mémoire au nœud NUMA le plus proche, et $numastat affiche des statistiques actuelles pour l'allocation de mémoire.
numa_miss et numa_foreign affichent les deux allocations de mémoire non sur le nœud numa préféré. Idéalement, les valeurs de numa_miss et numa_foreign doivent être réduites au minimum, car des valeurs plus élevées peuvent entraîner une mauvaise performance des E / S de mémoire.
La commande $numastat -p <process></process> peut également être utilisée pour afficher la distribution NUMA d'un processus.
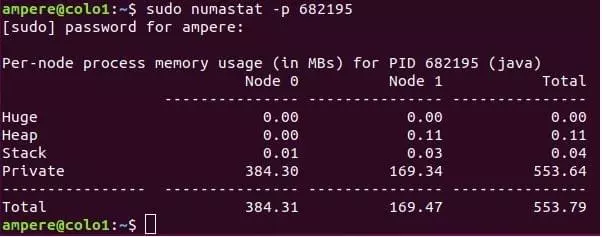
Lors de l'exécution d'une application sur un système / instance, vous serez intéressé à comprendre ce que fait l'application et les ressources utilisées par l'application sur le CPU. $pidstat est un outil de ligne de commande qui surveille chaque processus individuel exécuté sur le système.
pidstat Les principaux utilisateurs du processeur seront décomposés en temps utilisateur et en temps système.
Cet outil Linux décompose l'utilisation du processeur par processus ou thread, y compris le temps de l'utilisateur et le temps du système. Cette commande peut également signaler les statistiques IO pour l'option de processus (-d).

$pidstat -p peut également être exécuté pour collecter des données sur un processus spécifique.

Veuillez contacter notre équipe de vente experte pour des partenariats ou apprendre à accéder au système AMPERE via notre programme d'accès aux développeurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



